Docker 08 部署Elasticsearch
参考源
https://www.bilibili.com/video/BV1og4y1q7M4?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV1kv411q7Qc?spm_id_from=333.999.0.0
版本
本文章基于 Docker 20.10.11
部署 Elasticsearch 可以参考 Docker Hub 官方文档:https://hub.docker.com/_/elasticsearch
启动
Elasticsearch 十分耗内存,建议启动前先尽量腾出内存空间。
Elasticsearch 需要暴露的端口很多,启动时需要比较复杂的配置。
Elasticsearch 的数据一般需要放置到安全目录,这里又涉及到数据卷技术了。
详情见:Docker 12 数据卷
启动 Elasticsearch
[root@sail sail]# docker run -d --name elasticsearch01 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.6.2
Unable to find image 'elasticsearch:7.6.2' locally
7.6.2: Pulling from library/elasticsearch
ab5ef0e58194: Pull complete
c4d1ca5c8a25: Pull complete
941a3cc8e7b8: Pull complete
43ec483d9618: Pull complete
c486fd200684: Pull complete
1b960df074b2: Pull complete
1719d48d6823: Pull complete
Digest: sha256:1b09dbd93085a1e7bca34830e77d2981521a7210e11f11eda997add1c12711fa
Status: Downloaded newer image for elasticsearch:7.6.2
6eccd8a777d91764963c2464b30db78b189f5c867633255e996bae088ace6029
[root@sail sail]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6eccd8a777d9 elasticsearch:7.6.2 "/usr/local/bin/dock…" 8 seconds ago Up 7 seconds 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch01
查看 Docker 内存占用
[root@sail sail]# docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
6eccd8a777d9 elasticsearch01 0.00% 1.238GiB / 1.694GiB 73.06% 0B / 0B 292MB / 389kB 43
由此可以看出,Elasticsearch 是多么的耗内存。
启动 Elasticsearch 时建议限制其最大内存占用。
[root@sail sail]# docker run -d --name elasticsearch02 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" elasticsearch:7.6.2
e6d7fe80cf2961817bd1184b98fd320dce4d9071b80ffb78aa413f484fa498ae
[root@sail sail]# docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
e6d7fe80cf29 elasticsearch02 0.78% 379.8MiB / 1.694GiB 21.89% 0B / 0B 106MB / 733kB 44
这样 Elasticsearch 的内存占用就会小很多了。
测试验证
Linux 中可以使用
curl命令模拟网页访问。
[root@sail sail]# curl localhost:9200
{
"name" : "e6d7fe80cf29",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "MIfPING6SFGVR88knFCf6w",
"version" : {
"number" : "7.6.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
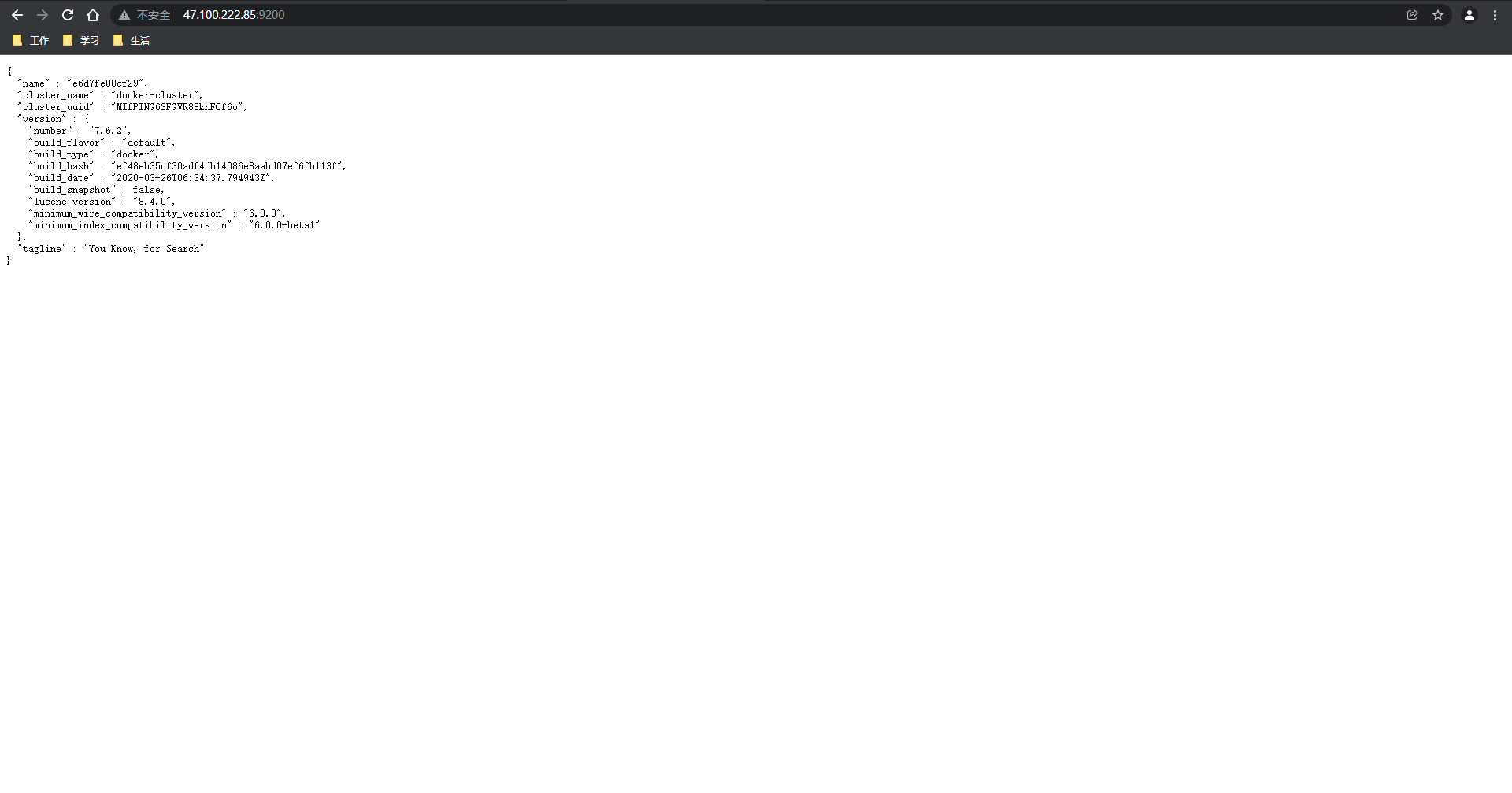
网页此内容代表 Elasticsearch 部署完成。
Docker 08 部署Elasticsearch的更多相关文章
- Docker 简单部署 ElasticSearch
https://www.cnblogs.com/jianxuanbing/p/9410800.html
- Centos8 Docker部署ElasticSearch集群
ELK部署 部署ElasticSearch集群 1.拉取镜像及批量生成配置文件 # 拉取镜像 [root@VM-24-9-centos ~]# docker pull elasticsearch:7. ...
- Docker部署Elasticsearch集群
http://blog.sina.com.cn/s/blog_8ea8e9d50102wwik.html Docker部署Elasticsearch集群 参考文档: https://hub.docke ...
- Docker Compose部署 EFK(Elasticsearch + Fluentd + Kibana)收集日志
简述 本文用于记录如何使用Docker Compose部署 EFK(Elasticsearch + Fluentd + Kibana) 收集Docker容器日志,使用EFK,可以无侵入代码,获得灵活, ...
- 3.ElasticSearch系列之Docker本地部署
对于之前的部署方式一般用于生产环境,而对于学习而言Docker方式快速部署就好了,本示例在window10环境下进行. 1. Docker使用Elasticsearch 需要对vm.max_map_c ...
- 【linux】【elasticsearch】docker部署elasticsearch及elasticsearch-head
前言 Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎.无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进.性能最好的.功能最全的搜索引擎库.但是,Lu ...
- docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head跨域问题 + IK分词器
0. docker pull 拉取elasticsearch + elasticsearch-head 镜像 1. 启动elasticsearch Docker镜像 docker run -di ...
- Docker部署ElasticSearch以及使用
ElasticSearch笔记 1. ElasticSearch前期 1.1 聊聊ElasticSearch的简介 Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引 ...
- Centos8 部署 ElasticSearch 集群并搭建 ELK,基于Logstash同步MySQL数据到ElasticSearch
Centos8安装Docker 1.更新一下yum [root@VM-24-9-centos ~]# yum -y update 2.安装containerd.io # centos8默认使用podm ...
随机推荐
- Border性质习题与证明
KMP 第一次接触 \(border\) 都是先从 KMP 开始的吧. 思想在于先对于一个串自匹配以求出 fail 指针(也就是 border) 然后就可以在匹配其他串的时候非常自然的失配转移.在此顺 ...
- 对 Python 中 GIL 的一点理解
GIL(Global Interpreter Lock),全局解释器锁,是 CPython 为了避免在多线程环境下造成 Python 解释器内部数据的不一致而引入的一把锁,让 Python 中的多个线 ...
- 移动云使用 JuiceFS 支持 Apache HBase 增效降本的探索
作者简介: 陈海峰,移动云数据库 Apache HBase 开发人员,对 Apache HBase.RBF.Apache Spark 有浓厚兴趣. 背景 Apache HBase 是 Apache H ...
- uniapp项目vue2升级vue3简单记录
看到好多开源项目都升级了vue3,看文章说vue3性能升级很多,而且组合式api很香,遂把最近开发的自助洗车app升级下,在此记录下出现的问题. uniapp升级vue3官方指南 我是先去vue官网看 ...
- html5手册语义化标签
html5手册语义化标签: article section aside hgroup header footer nav time mark figure figcaption contextmenu ...
- 百度地图API 地图圈区域并计算坐标点是否在区域内
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 怎么理解相互独立事件?真的是没有任何关系的事件吗?《考研概率论学习之我见》 -by zobol
1.从条件概率的定义来看独立事件的定义 2.从古典概率的定义来看独立事件的定义 3.P(A|B)和P(A)的关系是什么? 4.由P(AB)=P(A)P(B)推出"独立" 5.从韦恩 ...
- BUUCTF-LSB
LSB 看到这个题目应该是LSB隐写,StegSolve打开,在红绿蓝0号上发现图片信息 然后在Analyse选择data extract Save bin保存图片即可 得到的是个二维码,解码即可.
- Operator介绍
一.Operator简介 在Kubernetes中我们经常使用Deployment.DaemonSet.Service.ConfigMap等资源,这些资源都是Kubernetes的内置资源,他们的创建 ...
- python小题目练习(六)
需求:编写一个猜数字的小游戏,随机生成1到10(包含1和10)之间的数字作为基准数,玩家每次通过键盘输入一个数字,如果输入的数字跟基准数相同,则闯关成功,否则重新输入,如果玩家输入的是-1,则表示退出 ...