Redis 12 持久化
参考源
https://www.bilibili.com/video/BV1S54y1R7SB?spm_id_from=333.999.0.0
版本
本文章基于 Redis 6.2.6
概述
Redis 是内存数据库,即数据存储在内存。
如果不将内存中的数据保存到磁盘,一旦服务器进程退出,服务器中的数据也会消失。
这样会造成巨大的损失,所以 Redis 提供了持久化功能。
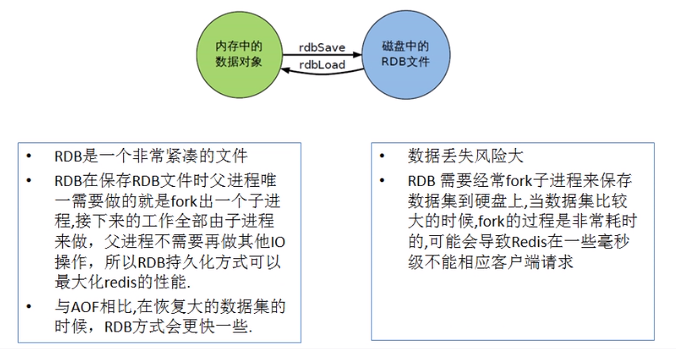
RDB
RDB,即 Redis DataBase
在指定的时间间隔内将内存中的数据集快照写入磁盘。
也就是 Snapshot 快照,恢复时是将快照文件直接读到内存里。
Redis会单独创建(fork)一个子进程来进行持久化。
会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。
整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。
如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那 RDB 方式要比 AOF 方式更加的高效。
RDB 的缺点是最后一次持久化后的数据可能丢失。
复制
Fork 的作用是复制一个与当前进程一样的进程。
新进程的所有数据(变量,环境变量,程序计数器等)数值都和原进程一致。
这是一个全新的进程,并作为原进程的子进程。
RDB 保存的是 dump.rdb 文件:
[root@sail redis]# ls
00-RELEASENOTES BUGS CONTRIBUTING deps INSTALL MANIFESTO redis.conf runtest-cluster runtest-sentinel src TLS.md
bin CONDUCT COPYING dump.rdb Makefile README.md runtest runtest-moduleapi sentinel.conf tests utils
配置
配置文件 redis.conf 中的快照配置
################################ SNAPSHOTTING ################################
# Save the DB to disk.
#
# save <seconds> <changes>
#
# Redis will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# Snapshotting can be completely disabled with a single empty string argument
# as in following example:
#
# save ""
#
# Unless specified otherwise, by default Redis will save the DB:
# * After 3600 seconds (an hour) if at least 1 key changed
# * After 300 seconds (5 minutes) if at least 100 keys changed
# * After 60 seconds if at least 10000 keys changed
#
# You can set these explicitly by uncommenting the three following lines.
#
# save 3600 1
# save 300 100
# save 60 10000
# By default Redis will stop accepting writes if RDB snapshots are enabled
# (at least one save point) and the latest background save failed.
# This will make the user aware (in a hard way) that data is not persisting
# on disk properly, otherwise chances are that no one will notice and some
# disaster will happen.
#
# If the background saving process will start working again Redis will
# automatically allow writes again.
#
# However if you have setup your proper monitoring of the Redis server
# and persistence, you may want to disable this feature so that Redis will
# continue to work as usual even if there are problems with disk,
# permissions, and so forth.
stop-writes-on-bgsave-error yes
# Compress string objects using LZF when dump .rdb databases?
# By default compression is enabled as it's almost always a win.
# If you want to save some CPU in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
rdbcompression yes
# Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
# This makes the format more resistant to corruption but there is a performance
# hit to pay (around 10%) when saving and loading RDB files, so you can disable it
# for maximum performances.
#
# RDB files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
rdbchecksum yes
# Enables or disables full sanitation checks for ziplist and listpack etc when
# loading an RDB or RESTORE payload. This reduces the chances of a assertion or
# crash later on while processing commands.
# Options:
# no - Never perform full sanitation
# yes - Always perform full sanitation
# clients - Perform full sanitation only for user connections.
# Excludes: RDB files, RESTORE commands received from the master
# connection, and client connections which have the
# skip-sanitize-payload ACL flag.
# The default should be 'clients' but since it currently affects cluster
# resharding via MIGRATE, it is temporarily set to 'no' by default.
#
# sanitize-dump-payload no
# The filename where to dump the DB
dbfilename dump.rdb
# Remove RDB files used by replication in instances without persistence
# enabled. By default this option is disabled, however there are environments
# where for regulations or other security concerns, RDB files persisted on
# disk by masters in order to feed replicas, or stored on disk by replicas
# in order to load them for the initial synchronization, should be deleted
# ASAP. Note that this option ONLY WORKS in instances that have both AOF
# and RDB persistence disabled, otherwise is completely ignored.
#
# An alternative (and sometimes better) way to obtain the same effect is
# to use diskless replication on both master and replicas instances. However
# in the case of replicas, diskless is not always an option.
rdb-del-sync-files no
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir ./
RDB 是整合内存的压缩过的 Snapshot,RDB 的数据结构,可以配置复合的快照触发条件。
save
save 3600 1
save 300 100
save 60 10000
默认:
- 1 分钟内改了 1 万次
- 5 分钟内改了 10 次
- 15 分钟内改了 1 次
如果想禁用 RDB 持久化的策略,只要不设置任何 save 指令,或者给 save 传入一个空字符串参数也可以。
若要修改完毕需要立马生效,可以手动使用 save 命令,立马生效 。
stop-writes-on-bgsave-error
如果配置为 no,表示你不在乎数据不一致或者有其他的手段发现和控制,默认为 yes。
rbdcompression
对于存储到磁盘中的快照,可以设置是否进行压缩存储。
如果是的话,redis 会采用 LZF 算法进行压缩,如果你不想消耗 CPU 来进行压缩的话,可以设置为关闭此功能。
rdbchecksum
在存储快照后,还可以让 redis 使用 CRC64 算法来进行数据校验。
但是这样做会增加大约 10% 的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
默认为 yes。
触发
- 配置文件中默认的快照配置,建议多用一台机子作为备份,复制一份 dump.rdb。
- 保存配置:
- save:只管保存,其他不管,全部阻塞。
- bgsave:Redis 会在后台异步进行快照操作,快照同时还可以响应客户端请求。
- lastsave:获取最后一次成功执行快照的时间。
- 执行 flushall 命令,也会产生 dump.rdb 文件,但里面是空的,无意义 。
- 退出的时候也会产生 dump.rdb 文件。
恢复
将备份文件 dump.rdb 移动到 redis 安装目录并启动服务即可。
本地数据库存放目录:
127.0.0.1:6379> config get dir
1) "dir"
2) "/usr/local/redis"
优缺点
优点
适合大规模的数据恢复。
对数据完整性和一致性要求不高时适用。
缺点
在一定间隔时间做一次备份,所以如果 redis 意外 down 掉的话,就会丢失最后一次快照后的所有修改。
Fork 的时候,内存中的数据被克隆了一份,大致 2 倍的膨胀性需要考虑。
小结
AOF
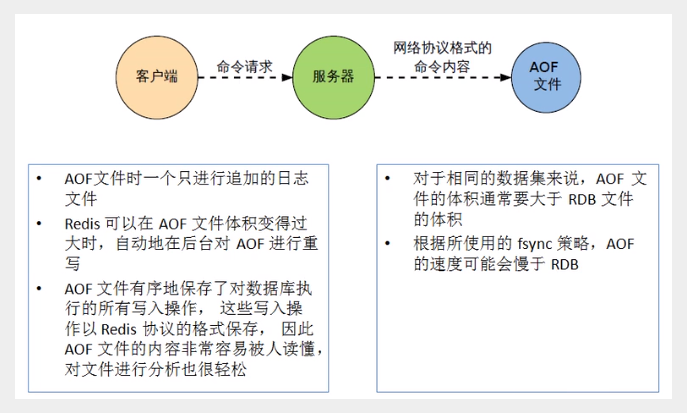
AOF,即 Append Only File
以日志的形式来记录每个写操作,将 Redis 执行过的所有指令记录下来(读操作不记录)。
只许追加文件,但不可以改写文件,Redis 启动之初会读取该文件重新构建数据。
换言之,Redis 重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
配置
AOF 保存的是 appendonly.aof 文件:
# 是否以append only模式作为持久化方式,默认使用的是rdb方式持久化,这种方式在许多应用中已经足够用了
appendonly no
# appendfilename AOF 文件名称
appendfilename "appendonly.aof"
# appendfsync aof持久化策略的配置:
# no:不执行fsync,由操作系统保证数据同步到磁盘,速度最快。
# always:每次写入都执行fsync,以保证数据同步到磁盘。
# everysec:每秒执行一次fsync,可能会导致丢失这1s数据。
appendfsync everysec
# 重写时是否可以运用Appendfsync,用默认no即可,保证数据安全性
No-appendfsync-on-rewrite
# 设置重写的基准值
Auto-aof-rewrite-min-size
# 设置重写的基准值
Auto-aof-rewrite-percentage
恢复
正常恢复
- 启动:修改配置。修改默认的 appendonly no,改为 yes。
- 复制:将有数据的 aof 文件复制一份保存到对应目录(config get dir)。
- 恢复:重启 redis 然后重新加载。
异常恢复
- 启动:修改配置。修改默认的 appendonly no,改为 yes。
- 破坏:故意破坏 appendonly.aof 文件(写一些非 Redis 命令)。
- 修复:
redis-check-aof --fix appendonly.aof进行修复。 - 恢复:重启 redis 然后重新加载。
重写
AOF 采用文件追加方式,文件会越来越大,为避免出现此种情况,新增了重写机制。
当AOF文件的大小超过所设定的阈值时,Redis 就会启动 AOF 文件的内容压缩。
只保留可以恢复数据的最小指令集,可以使用命令 bgrewriteaof。
重写原理
AOF 文件持续增长而过大时,会 Fork 出一条新进程来将文件重写(也是先写临时文件最后再 rename)。
遍历新进程的内存中数据,每条记录有一条的 set 语句。
重写 aof 文件的操作,并没有读取旧的 aof 文件,这点和快照有点类似。
触发机制
Redis 会记录上次重写时的 AOF 大小,默认配置是当 AOF 文件大小是上次 rewrite 后大小的 1 倍且文件大于 64M 时触发。
优缺点
优点
- appendfsync always:每次修改同步。同步持久化,每次发生数据变更会被立即记录到磁盘。性能较差,但数据完整性比较好。
- appendfsync everysec:每秒同步。异步操作,每秒记录 ,如果一秒内宕机,有数据丢失。
- appendfsync no:不同步。从不同步。
缺点
- 相同数据集的数据而言,AOF 文件要远大于 RDB 文件,恢复速度慢于 RDB。
- AOF 运行效率要慢于 RDB,每秒同步策略效率较好,不同步效率和 RDB 相同。
小结
总结
RDB 持久化方式能够在指定的时间间隔内对你的数据进行快照存储。
AOF 持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AO F命令以 Redis 协议追加保存每次写的操作到文件末尾,Redis 还能对 AOF 文件进行后台重写,使得 AOF 文件的体积不至于过大。
只做缓存,如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化。
同时开启两种持久化方式:
- 在这种情况下,当 redis 重启的时候会优先载入 AOF 文件来恢复原始的数据,因为在通常情况下 AOF 文件保存的数据集要比 RDB 文件保存的数据集要完整。
- RDB 的数据不实时,同时使用两者时服务器重启也只会找 AOF 文件,那要不要只使用AOF呢?作者建议不要,因为 RDB 更适合用于备份数据库(AOF 在不断变化不好备份),快速重启,而且不会有 AOF 可能潜在的 Bug,留着作为一个万一的手段。
性能建议:
- 因为 RDB 文件只用作后备用途,建议只在 Slave(从节点) 上持久化 RDB 文件,而且只要 15 分钟备份一次就够了,只保留 save 900 1 这条规则。
- 如果开启 AOF ,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只 load 自己的AOF文件就可以了,代价一是带来了持续的 IO,二是AOF rewrite 的最后将 rewrite 过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少 AOF rewrite 的频率,AOF重写的基础大小默认值 64M 太小了,可以设到 5G 以上,默认超过原大小 100% 大小重写可以改到适当的数值。
- 如果不开启 AOF ,仅靠 Master-Slave Repllcation(主从复制) 实现高可用性也可以,能省掉一大笔IO,也减少了 rewrite 时带来的系统波动。代价是如果 Master/Slave 同时挂掉,会丢失十几分钟的数据,启动脚本也要比较两个 Master/Slave 中的 RDB 文件,载入较新的那个(微博就是这种架构)。
Redis 12 持久化的更多相关文章
- redis + 主从 + 持久化 + 分片 + 集群 + spring集成
Redis是一个基于内存的数据库,其不仅读写速度快,每秒可以执行大约110000的写操作,81000的读取操作,而且其支持存储字符串,哈希结构,链表,集合丰富的数据类型.所以得到很多开发者的青睐.加之 ...
- Redis数据持久化、数据备份、数据的故障恢复
1.redis持久化的意义----redis故障恢复 在实际的生产环境中,很可能会遇到redis突然挂掉的情况,比如redis的进程死掉了.电缆被施工队挖了(支付宝例子)等等,总之一定会遇到各种奇葩的 ...
- redis的持久化相关操纵
一.redis数据持久化(数据保存在硬盘上) 1. 关系型数据库Mmysql持久化 任何增删改语句都是在硬盘上操作(安全) 断电,硬盘上数据还在 2.非关系型数据库 默认所有的增删改都是在内存中操作( ...
- redis的持久化(RDB&AOF的区别)
RDB 是什么? 在指定的时间间隔内将内存中的数据集快照写入磁盘, 也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里. Redis会单独创建(fork)一个子进程来进行持久化,会 ...
- 深入理解Redis的持久化机制和原理
Redis是一种面向“key-value”类型数据的分布式NoSQL数据库系统,具有高性能.持久存储.适应高并发应用场景等优势.它虽然起步较晚,但发展却十分迅速. 近日,Redis的作者在博客中写到, ...
- Redis(7)——持久化【一文了解】
一.持久化简介 Redis 的数据 全部存储 在 内存 中,如果 突然宕机,数据就会全部丢失,因此必须有一套机制来保证 Redis 的数据不会因为故障而丢失,这种机制就是 Redis 的 持久化机制, ...
- Redis 的持久化
原文链接:https://www.changxuan.top/?p=1386 Redis 是一个非关系型的内存数据库,使用内存存储数据是它能够进行快速存取数据的原因之一. 在实际应用中,常有人提倡把 ...
- redis的持久化 与事务管理
1. redis的持久化 Redis的持久化主要分为两部分:RDB(Redis DataBase), AOF(Append Only File) 2. 什么是redis 的持久化 在指定 ...
- 删库到跑路?还得看这篇Redis数据库持久化与企业容灾备份恢复实战指南
本章目录 0x00 数据持久化 1.RDB 方式 2.AOF 方式 如何抉择 RDB OR AOF? 0x01 备份容灾 一.备份 1.手动备份redis数据库 2.迁移Redis指定db-数据库 3 ...
随机推荐
- 06vim --- gcc库的制作及使用
VIM 命令模式下的操作 保存退出 快捷键 操作 ZZ 保存退出 代码格式化 快捷键 操作 gg=G 代码的格式化 光标移动(键盘上下左右键课代替) 快捷键 操作 h 光标左移 j 光标下移 k 光标 ...
- Spring Ioc源码分析系列--Bean实例化过程(一)
Spring Ioc源码分析系列--Bean实例化过程(一) 前言 上一篇文章Spring Ioc源码分析系列--Ioc容器注册BeanPostProcessor后置处理器以及事件消息处理已经完成了对 ...
- springcloud 断路器
https://www.jb51.net/article/138572.htm 参考资料: http://www.cnblogs.com/ulysses-you/p/7281662.html http ...
- 【Golang】创建有配置参数的结构体时,可选参数应该怎么传?
写在前面的话 Golang中构建结构体的时候,需要通过可选参数方式创建,我们怎么样设计一个灵活的API来初始化结构体呢. 让我们通过如下的代码片段,一步一步说明基于可选参数模式的灵活 API 怎么设计 ...
- 技术分享 | app自动化测试(Android)--App 控件交互
原文链接 常用操作 点击操作 通常获取到元素之后,可以调用 click() 方法来实现对这个元素的点击操作.示例代码如下: python 版本 driver.find_element_by_id(&q ...
- 工作流引擎之Elsa入门系列教程之一 初始化项目并创建第一个工作流
引子 工作流(Workflow)是对工作流程及其各操作步骤之间业务规则的抽象.概括描述. 为了实现某个业务目标,需要多方参与.按预定规则提交数据时,就可以用到工作流. 通过流程引擎,我们按照流程图,编 ...
- Redis之时间轮机制(五)
一.什么是时间轮 时间轮这个技术其实出来很久了,在kafka.zookeeper等技术中都有时间轮使用的方式. 时间轮是一种高效利用线程资源进行批量化调度的一种调度模型.把大批量的调度任务全部绑定到同 ...
- WPF开发随笔收录-获取软件当前目录的坑
一.唠唠叨叨 软件开发过程中,经常需要使用到获取exe当前目录这个功能,前同事在实现这个需求时使用的是Directory.GetCurrentDirectory()这个方法,但再最近的测试中,突然发现 ...
- Mysql中的小技巧
1.where 字段名 regexp '正则表达式' 正则符号: ^ $ . [ ] * | . 表示1个任意字符 * 表示前面重复0次,或者任意次 ^ 开始 $ 结尾 [] 范围 | 或 sql示例 ...
- 基于NCF的多模块协同实例
简介 这次给大家带来的内容是基于NCF的多模块协同实例 主要讲解的内容是NCF的模块Xncf之间相互调用,相互协作的能力 这里可以把Xncf比作乐高玩具,一个Xncf就是你拥有的乐高玩具的类型,比如你 ...