在Go中如何正确重试请求
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/677
我们平时在开发中肯定避不开的一个问题是如何在不可靠的网络服务中实现可靠的网络通信,其中 http 请求重试是经常用的技术。但是 Go 标准库 net/http 实际上是没有重试这个功能的,所以本篇文章主要讲解如何在 Go 中实现请求重试。
概述
一般而言,对于网络通信失败的处理分为以下几步:
- 感知错误。通过不同的错误码来识别不同的错误,在HTTP中status code可以用来识别不同类型的错误;
- 重试决策。这一步主要用来减少不必要的重试,比如HTTP的4xx的错误,通常4xx表示的是客户端的错误,这时候客户端不应该进行重试操作,或者在业务中自定义的一些错误也不应该被重试。根据这些规则的判断可以有效的减少不必要的重试次数,提升响应速度;
- 重试策略。重试策略就包含了重试间隔时间,重试次数等。如果次数不够,可能并不能有效的覆盖这个短时间故障的时间段,如果重试次数过多,或者重试间隔太小,又可能造成大量的资源(CPU、内存、线程、网络)浪费。这个我们下面再说;
- 对冲策略。对冲是指在不等待响应的情况主动发送单次调用的多个请求,然后取首个返回的回包。这个概念是 grpc 中的概念,我把它也借用过来;
- 熔断降级;如果重试之后还是不行,说明这个故障不是短时间的故障,而是长时间的故障。那么可以对服务进行熔断降级,后面的请求不再重试,这段时间做降级处理,减少没必要的请求,等服务端恢复了之后再进行请求,这方面的实现很多 go-zero 、 sentinel 、hystrix-go,也蛮有意思的;
重试策略
重试策略可以分为很多种,一方面要考虑到本次请求时长过长而影响到的业务忍受度,另一方面要考虑到重试会对下游服务产生过多的请求而带来的影响,总之就是一个trade-off的问题。
所以对于重试算法,一般是在重试之间加一个 gap 时间,感兴趣的朋友也可以去看看这篇文章。结合我们自己平时的实践加上这篇文章的算法一般可以总结出以下几条规则:
- 线性间隔(Linear Backoff):每次重试间隔时间是固定的进行重试,如每1s重试一次;
- 线性间隔+随机时间(Linear Jitter Backoff):有时候每次重试间隔时间一致可能会导致多个请求在同一时间请求,那么我们可以加入一个随机时间,在线性间隔时间的基础上波动一个百分比的时间;
- 指数间隔(Exponential Backoff):每次间隔时间是2指数型的递增,如等 3s 9s 27s后重试;
- 指数间隔+随机时间(Exponential Jitter Backoff):这个就和第二个类似了,在指数递增的基础上添加一个波动时间;
上面有两种策略都加入了扰动(jitter),目的是防止惊群问题 (Thundering Herd Problem)的发生。
In computer science, the thundering herd problem occurs when a large number of processes or threads waiting for an event are awoken when that event occurs, but only one process is able to handle the event. When the processes wake up, they will each try to handle the event, but only one will win. All processes will compete for resources, possibly freezing the computer, until the herd is calmed down again
所谓惊群问题当许多进程都在等待被同一事件唤醒的时候,当事件发生后最后只有一个进程能获得处理。其余进程又造成阻塞,这会造成上下文切换的浪费。所以加入一个随机时间来避免同一时间同时请求服务端还是很有必要的。
使用 net/http 重试所带来的问题
重试这个操作其实对于 Go 来说其实还不能直接加一个 for 循环根据次数来进行,对于 Get 请求重试的时候没有请求体,可以直接进行重试,但是对于 Post 请求来说需要把请求体放到Reader 里面,如下:
req, _ := http.NewRequest("POST", "localhost", strings.NewReader("hello"))
服务端收到请求之后就会从这个Reader中调用Read()函数去读取数据,通常情况当服务端去读取数据的时候,offset会随之改变,下一次再读的时候会从offset位置继续向后读取。所以如果直接重试,会出现读不到 Reader的情况。
我们可以先弄一个例子:
func main() {
go func() {
http.HandleFunc("/", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
time.Sleep(time.Millisecond * 20)
body, _ := ioutil.ReadAll(r.Body)
fmt.Printf("received body with length %v containing: %v\n", len(body), string(body))
w.WriteHeader(http.StatusOK)
}))
http.ListenAndServe(":8090", nil)
}()
fmt.Print("Try with bare strings.Reader\n")
retryDo(req)
}
func retryDo() {
originalBody := []byte("abcdefghigklmnopqrst")
reader := strings.NewReader(string(originalBody))
req, _ := http.NewRequest("POST", "http://localhost:8090/", reader)
client := http.Client{
Timeout: time.Millisecond * 10,
}
for {
_, err := client.Do(req)
if err != nil {
fmt.Printf("error sending the first time: %v\n", err)
}
time.Sleep(1000)
}
}
// output:
error sending the first time: Post "http://localhost:8090/": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
error sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0
error sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0
received body with length 20 containing: abcdefghigklmnopqrst
error sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0
....
在上面这个例子中,在客户端设值了 10ms 的超时时间。在服务端模拟请求处理超时情况,先sleep 20ms,然后再读请求数据,这样必然会超时。
当再次请求的时候,发现 client 请求的 Body 数据并不是我们预期的20个长度,而是 0,导致了 err。因此需要将Body这个Reader 进行重置,如下:
func resetBody(request *http.Request, originalBody []byte) {
request.Body = io.NopCloser(bytes.NewBuffer(originalBody))
request.GetBody = func() (io.ReadCloser, error) {
return io.NopCloser(bytes.NewBuffer(originalBody)), nil
}
}
上面这段代码中,我们使用 io.NopCloser 对请求的 Body 数据进行了重置,避免下次请求的时候出现非预期的异常。
那么相对于上面简陋的例子,还可以完善一下,加上我们上面说的 StatusCode 重试判断、重试策略、重试次数等等,可以写成这样:
func retryDo(req *http.Request, maxRetries int, timeout time.Duration,
backoffStrategy BackoffStrategy) (*http.Response, error) {
var (
originalBody []byte
err error
)
if req != nil && req.Body != nil {
originalBody, err = copyBody(req.Body)
resetBody(req, originalBody)
}
if err != nil {
return nil, err
}
AttemptLimit := maxRetries
if AttemptLimit <= 0 {
AttemptLimit = 1
}
client := http.Client{
Timeout: timeout,
}
var resp *http.Response
//重试次数
for i := 1; i <= AttemptLimit; i++ {
resp, err = client.Do(req)
if err != nil {
fmt.Printf("error sending the first time: %v\n", err)
}
// 重试 500 以上的错误码
if err == nil && resp.StatusCode < 500 {
return resp, err
}
// 如果正在重试,那么释放fd
if resp != nil {
resp.Body.Close()
}
// 重置body
if req.Body != nil {
resetBody(req, originalBody)
}
time.Sleep(backoffStrategy(i) + 1*time.Microsecond)
}
// 到这里,说明重试也没用
return resp, req.Context().Err()
}
func copyBody(src io.ReadCloser) ([]byte, error) {
b, err := ioutil.ReadAll(src)
if err != nil {
return nil, ErrReadingRequestBody
}
src.Close()
return b, nil
}
func resetBody(request *http.Request, originalBody []byte) {
request.Body = io.NopCloser(bytes.NewBuffer(originalBody))
request.GetBody = func() (io.ReadCloser, error) {
return io.NopCloser(bytes.NewBuffer(originalBody)), nil
}
}
对冲策略
上面讲的是重试的概念,那么有时候我们接口只是偶然会出问题,并且我们的下游服务并不在乎多请求几次,那么我们可以借用 grpc 里面的概念:对冲策略(Hedged requests)。
对冲是指在不等待响应的情况主动发送单次调用的多个请求,然后取首个返回的回包。对冲和重试的区别点主要在:对冲在超过指定时间没有响应就会直接发起请求,而重试则必须要服务端响应后才会发起请求。所以对冲更像是比较激进的重试策略。
使用对冲的时候需要注意一点是,因为下游服务可能会做负载均衡策略,所以要求请求的下游服务一般是要求幂等的,能够在多次并发请求中是安全的,并且是符合预期的。
对冲请求一般是用来处理“长尾”请求的,关于”长尾“请求的概念可以看这篇文章:https://segmentfault.com/a/1190000039978117
并发模式的处理
因为对冲重试加上了并发的概念,要用到 goroutine 来并发请求,所以我们可以把数据封装到 channel 里面来进行消息的异步处理。
并且由于是多个goroutine处理消息,我们需要在每个goroutine处理完毕,但是都失败的情况下返回err,不能直接由于channel等待卡住主流程,这一点十分重要。
但是由于在 Go 中是无法获取每个 goroutine 的执行结果的,我们又只关注正确处理结果,需要忽略错误,所以需要配合 WaitGroup 来实现流程控制,示例如下:
func main() {
totalSentRequests := &sync.WaitGroup{}
allRequestsBackCh := make(chan struct{})
multiplexCh := make(chan struct {
result string
retry int
})
go func() {
//所有请求完成之后会close掉allRequestsBackCh
totalSentRequests.Wait()
close(allRequestsBackCh)
}()
for i := 1; i <= 10; i++ {
totalSentRequests.Add(1)
go func() {
// 标记已经执行完
defer totalSentRequests.Done()
// 模拟耗时操作
time.Sleep(500 * time.Microsecond)
// 模拟处理成功
if random.Intn(500)%2 == 0 {
multiplexCh <- struct {
result string
retry int
}{"finsh success", i}
}
// 处理失败不关心,当然,也可以加入一个错误的channel中进一步处理
}()
}
select {
case <-multiplexCh:
fmt.Println("finish success")
case <-allRequestsBackCh:
// 到这里,说明全部的 goroutine 都执行完毕,但是都请求失败了
fmt.Println("all req finish,but all fail")
}
}
从上面这段代码看为了进行流程控制,多用了两个 channel :totalSentRequests 、allRequestsBackCh,多用了一个 goroutine 异步关停 allRequestsBackCh,才实现的流程控制,实在太过于麻烦,有新的实现方案的同学不妨和我探讨一下。
除了上面的并发请求控制的问题,对于对冲重试来说,还需要注意的是,由于请求不是串行的,所以 http.Request 的上下文会变,所以每次请求前需要 clone 一次 context,保证每个不同请求的 context 是独立的。但是每次 clone 之后 Reader 的offset位置又变了,所以我们还需要进行重新 reset:
func main() {
req, _ := http.NewRequest("POST", "localhost", strings.NewReader("hello"))
req2 := req.Clone(req.Context())
contents, _ := io.ReadAll(req.Body)
contents2, _ := io.ReadAll(req2.Body)
fmt.Printf("First read: %v\n", string(contents))
fmt.Printf("Second read: %v\n", string(contents2))
}
//output:
First read: hello
Second read:
所以结合一下上面的例子,我们可以将对冲重试的代码变为:
func retryHedged(req *http.Request, maxRetries int, timeout time.Duration,
backoffStrategy BackoffStrategy) (*http.Response, error) {
var (
originalBody []byte
err error
)
if req != nil && req.Body != nil {
originalBody, err = copyBody(req.Body)
}
if err != nil {
return nil, err
}
AttemptLimit := maxRetries
if AttemptLimit <= 0 {
AttemptLimit = 1
}
client := http.Client{
Timeout: timeout,
}
// 每次请求copy新的request
copyRequest := func() (request *http.Request) {
request = req.Clone(req.Context())
if request.Body != nil {
resetBody(request, originalBody)
}
return
}
multiplexCh := make(chan struct {
resp *http.Response
err error
retry int
})
totalSentRequests := &sync.WaitGroup{}
allRequestsBackCh := make(chan struct{})
go func() {
totalSentRequests.Wait()
close(allRequestsBackCh)
}()
var resp *http.Response
for i := 1; i <= AttemptLimit; i++ {
totalSentRequests.Add(1)
go func() {
// 标记已经执行完
defer totalSentRequests.Done()
req = copyRequest()
resp, err = client.Do(req)
if err != nil {
fmt.Printf("error sending the first time: %v\n", err)
}
// 重试 500 以上的错误码
if err == nil && resp.StatusCode < 500 {
multiplexCh <- struct {
resp *http.Response
err error
retry int
}{resp: resp, err: err, retry: i}
return
}
// 如果正在重试,那么释放fd
if resp != nil {
resp.Body.Close()
}
// 重置body
if req.Body != nil {
resetBody(req, originalBody)
}
time.Sleep(backoffStrategy(i) + 1*time.Microsecond)
}()
}
select {
case res := <-multiplexCh:
return res.resp, res.err
case <-allRequestsBackCh:
// 到这里,说明全部的 goroutine 都执行完毕,但是都请求失败了
return nil, errors.New("all req finish,but all fail")
}
}
熔断 & 降级
因为在我们使用 http 调用的时候,调用的外部服务很多时候其实并不可靠,很有可能因为外部的服务问题导致自身服务接口调用等待,从而调用时间过长,产生大量的调用积压,慢慢耗尽服务资源,最终导致服务调用雪崩的发生,所以在服务中使用熔断降级是非常有必要的一件事。
其实熔断降级的概念总体上来说,实现都差不多。核心思想就是通过全局的计数器,用来统计调用次数、成功/失败次数。通过统计的计数器来判断熔断器的开关,熔断器的状态由三种状态表示:closed、open、half open,下面借用了 sentinel 的图来表示三者的关系:
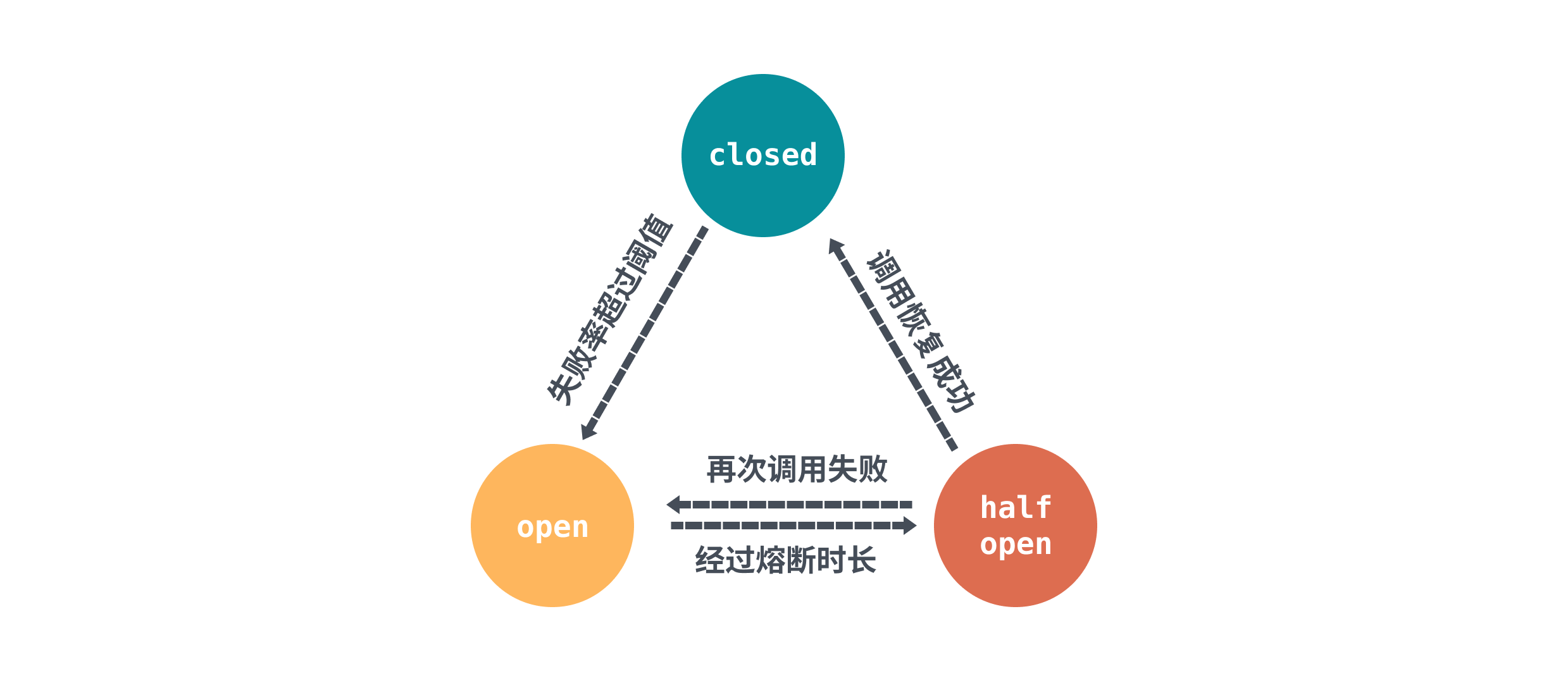
首先初始状态是closed,每次调用都会经过计数器统计总次数和成功/失败次数,然后在达到一定阈值或条件之后熔断器会切换到 open状态,发起的请求会被拒绝。
熔断器规则中会配置一个熔断超时重试的时间,经过熔断超时重试时长后熔断器会将状态置为 half-open 状态。这个状态对于 sentinel 来说会发起定时探测,对于 go-zero 来说会允许通过一定比例的请求,不管是主动定时探测,还是被动通过的请求调用,只要请求的结果返回正常,那么就需要重置计数器恢复到 closed 状态。
一般而言会支持两种熔断策略:
- 错误比率:熔断时间窗口内的请求数阈值错误率大于错误率阈值,从而触发熔断。
- 平均 RT(响应时间):熔断时间窗口内的请求数阈值大于平均 RT 阈值,从而触发熔断。
比如我们使用 hystrix-go 来处理我们的服务接口的熔断,可以结合我们上面说的重试从而进一步保障我们的服务。
hystrix.ConfigureCommand("my_service", hystrix.CommandConfig{
ErrorPercentThreshold: 30,
})
_ = hystrix.Do("my_service", func() error {
req, _ := http.NewRequest("POST", "http://localhost:8090/", strings.NewReader("test"))
_, err := retryDo(req, 5, 20*time.Millisecond, ExponentialBackoff)
if err != nil {
fmt.Println("get error:%v",err)
return err
}
return nil
}, func(err error) error {
fmt.Printf("handle error:%v\n", err)
return nil
})
上面这个例子中就利用 hystrix-go 设置了最大错误百分比等于30,超过这个阈值就会进行熔断。
总结
这篇文章从接口调用出发,探究了重试的几个要点,讲解了重试的几种策略;然后在实践环节中讲解了直接使用 net/http重试会有什么问题,对于对冲策略使用 channel 加上 waitgroup 来实现并发请求控制;最后使用 hystrix-go 来对故障服务进行熔断,防止请求堆积引起资源耗尽的问题。
Reference
https://github.com/sethgrid/pester
https://juejin.cn/post/6844904105354199047
https://github.com/ma6174/blog/issues/11
https://aws.amazon.com/cn/blogs/architecture/exponential-backoff-and-jitter/
https://medium.com/@trongdan_tran/circuit-breaker-and-retry-64830e71d0f6
https://www.lixueduan.com/post/grpc/09-retry/
https://en.wikipedia.org/wiki/Thundering_herd_problem
https://go-zero.dev/cn/docs/blog/governance/breaker-algorithms/
https://sre.google/sre-book/handling-overload/#eq2101
https://sentinelguard.io/zh-cn/docs/golang/circuit-breaking.html
https://github.com/afex/hystrix-go
https://segmentfault.com/a/1190000039978117

在Go中如何正确重试请求的更多相关文章
- Web Api 中Get 和 Post 请求的多种情况分析
转自:http://www.cnblogs.com/babycool/p/3922738.html 来看看对于一般前台页面发起的get和post请求,我们在Web API中要如何来处理. 这里我使用J ...
- 在ASP.NET 5应用程序中的跨域请求功能详解
在ASP.NET 5应用程序中的跨域请求功能详解 浏览器安全阻止了一个网页中向另外一个域提交请求,这个限制叫做同域策咯(same-origin policy),这组织了一个恶意网站从另外一个网站读取敏 ...
- InnoDB缓冲池预加载在MySQL 5.7中的正确打开方式
InnoDB缓冲池预加载在MySQL 5.7中的正确打开方式 https://mp.weixin.qq.com/s/HGa_90XvC22anabiBF8AbQ 在这篇文章里,我将讨论在MySQL 5 ...
- 使用PHP中的curl发送请求
使用CURL发送请求的基本流程 使用CURL的PHP扩展完成一个HTTP请求的发送一般有以下几个步骤: 初始化连接句柄: 设置CURL选项: 执行并获取结果: 释放VURL连接句柄. 下面的程序片段是 ...
- 阿里高级架构师教你如何使用Spring Cloud Ribbon重试请求
在微服务调用中,一些微服务圈可能调用失败,通过再次调用以达到系统稳定性效果,本文展示如何使用Ribbon和Spring Retry进行请求再次重试调用. 在Spring Cloud中,使用load b ...
- Python的Django REST框架中的序列化及请求和返回
Python的Django REST框架中的序列化及请求和返回 序列化Serialization 1. 设置一个新的环境 在我们开始之前, 我们首先使用virtualenv要创建一个新的虚拟环境,以使 ...
- Golang中如何正确的使用sarama包操作Kafka?
Golang中如何正确的使用sarama包操作Kafka? 一.背景 在一些业务系统中,模块之间通过引入Kafka解藕,拿IM举例(图来源): 用户A给B发送消息,msg_gateway收到消息后,投 ...
- springboot 中如何正确在异步线程中使用request
起因: 有后端同事反馈在异步线程中获取了request中的参数,然后下一个请求是get请求的话,发现会偶尔出现参数丢失的问题. 示例代码: @GetMapping("/getParams&q ...
- php中ajax跨域请求---小记
php中ajax跨域请求---小记 前端时间,遇到的一个问题,情况大约是这样: 原来的写法: 前端js文件中: $.ajax({ type:'get', url:'http://wan.xxx.c ...
随机推荐
- Django序列化组件与数据批量操作与简单使用Forms组件
目录 SweetAlert前端插件 Django自带的序列化组件 批量数据操作 分页器与推导流程 Forms组件之创建 Forms组件之数据校验 Forms组件之渲染标签 Forms组件之信息展示 S ...
- 双webview模式,子窗口打不开或者无法切换
iOS 真机调试时,发现window.open 无效.可以结合plusReady里面不执行一起参考,博主在当时遇到这个问题只查询了资料,而后并没有来得及自己亲自验证以下方法的可行性.来日再遇上mui的 ...
- .net 获取IP地址的几种方式
1.获取服务器IP地址: 1) Local_Addr var Local_Addr = Request.ServerVariables.Get("Local_Addr").ToSt ...
- docker-compose 搭建 Prometheus+Grafana监控系统
有关监控选型之前有写过一篇文章: 监控系统选型,一文轻松搞定! 监控对象 Linux服务器 Docker Redis MySQL 数据采集 1).prometheus: 采集数据 2).node-ex ...
- Camunda开源流程引擎快速入门——Hello World
市场上比较有名的开源流程引擎有osworkflow.jbpm.activiti.flowable.camunda.由于jbpm.activiti.flowable这几个流程引擎出现的比较早,国内人用的 ...
- vue海康视频播放组件
海康视频插件web文档 渲染组件后,调用initPlugin函数,传入一个code数组 <template> <div :title="name" :id=&qu ...
- (数据科学学习手札138)使用sklearnex大幅加速scikit-learn运算
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,scikit-learn作为经 ...
- 让我们用Vue cli全家桶搭建项目
一般项目都会用到这几个,这里不在详细介绍概念,只是简单的使用.一.搭建cli 1.事先安装好cnpm(淘宝镜像) npm install -g cnpm --registry=https://regi ...
- SAP OLE download to excel
REPORT RSDEMO01 NO STANDARD PAGE HEADING. * this report demonstrates how to send some ABAP data to a ...
- jenkins配置自动执行sql脚本
shell脚本: bigsql="select big_version,small_version from d0mstore.db_current_version order by big ...