week_9(异常检测)
Andrew Ng 机器学习笔记 ---By Orangestar
Week_9
This week, we will be covering anomaly detection which is widely used in fraud detection . Given a large number of data points, we may sometimes want to figure out which ones vary significantly from the average.
We will also be covering recommender systems, which are used by companies like Amazon, Netflix and Apple to recommend products to their users. Recommender systems look at patterns of activities between different users and different products to produce these recommendations. In these lessons, we introduce recommender algorithms such as the collaborative filtering algorithm and low-rank matrix factorization.
Let ‘s begin !
1. Problem Motivation
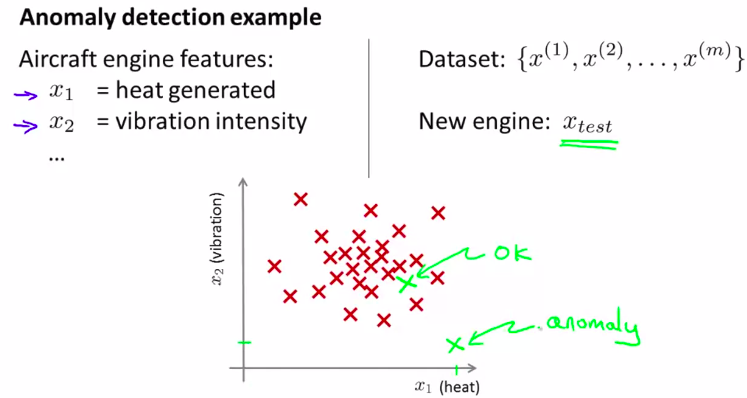
什么是异常检测?
顾名思义!检测异常。
设定一个阈值,如果检测样本低于阈值,则是异常
更正式的定义如下:
给定无标签的训练集:
如图: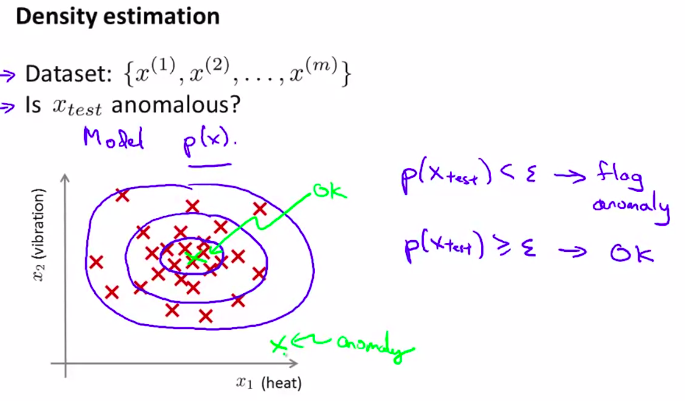
根据一些特征量来估计概率。
应用案例:
欺诈检测。工厂生产检测异常样本

2. Gaussian Distribution (高斯分布)(正态分布)
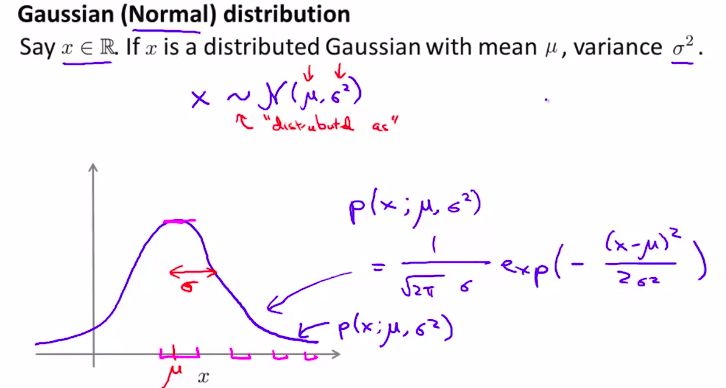
\(\sigma\) 叫做标准差,它的平方叫做方差。决定了正态分布图像的宽度
\(\mu\) 是平均值,刚好是正态分布最高点的横坐标
正态分布图像的公式是:
\(P(x; \mu, \sigma^2) = \frac1{\sqrt{2\pi}*\sigma}*exp(-\frac{(x-\mu)^2}{2\sigma^2})\)
注:面积是不变的,都是1.因为是概率函数
下面 我们来看看参数估计问题
就是将一数据集 拟合为与之相应的高斯函数
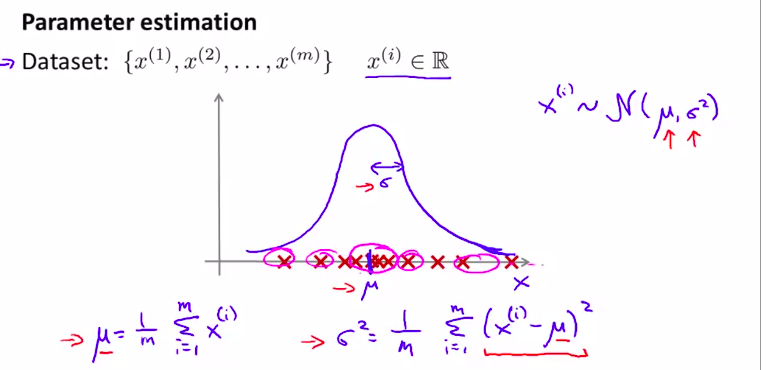
其中
\(\mu = \frac 1m\sum_{i=1}^mx^{(i)}\)
\(\sigma^2 = \frac1m\sum_{i=1}^m(x^{(i)}-\mu)^2\)
注,m有的时候也会写作 m-1,这其实影响不大,机器学习中一般用m
3. Algorithm
这节正式进入算法学习
这个常常被称为是密度估计问题

计算完后,下面便是计算的算法:

下面是一个例子:
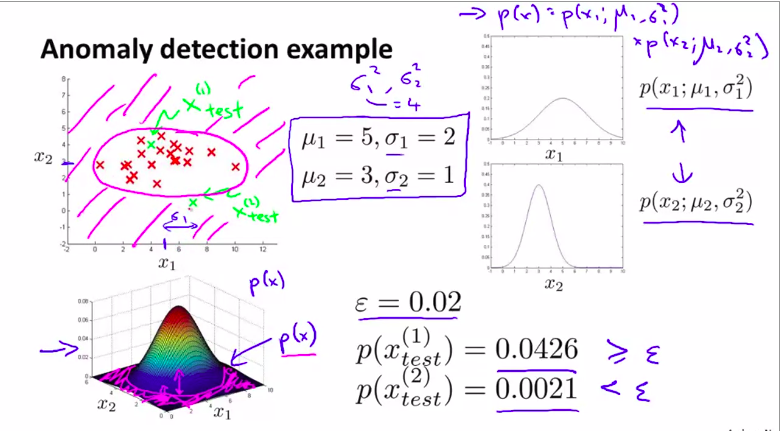
可以用数值计算来判断,也可以直接看图像!
4 . Developing and Evaluating an Anomaly Detection System
我们已经学习了如何运用算法来 实现异常检测,那么,如何来评价算法和改进算法呢?
首先,我们来看下:
---如果有一种评价系统,能够返回一个数字来描述算法的好坏的话,评价就容易多了。
----既然如此,假设我们有一些带标签的数据,有一些异常的和非异常的样本,假设(y=0就是正常,y=1则是异常)
---当然,接下来我们要定义交叉检测集和测试集。

当然,这些集需要是带标签的,这样才能来评价我们的算法的好坏。
那么,异常检测算法的推导和评价方法 如下所示:
- 对于训练集,我们将它们看做是无标签的(也就是说,将它们看做都是正常的),这就是所有的无异常的训练集。
- 但是,对于交叉验证集和测试集,这里的样本应该包含异常的样本。 也就是标签为y = 1的
这是实例:

下面是算法的总结:

但是仔细想想,我们并不可以通过由交叉验证集的成功验证次数来评估算法。所以,分类准确度并不是一个准确的算法。因为数据集是非常偏斜的!
但是\(\varepsilon\) 可以通过不停的测试,选择出在交叉验证集中最好的一个 \(\varepsilon\)
这是一个可能的评价算法:


5. Anomaly Detection vs. Supervised Learning
什么时候用监督学习?什么时候用异常检测算法?
- 异常检测:
- 有很小的正样本。或者很大数量的负样本。
- 有很多异常的类型。很难用任意一个算法来学习出这个异常。
- 监督学习:
- 很大的正样本和负样本
- 有足够的正样本来告诉算法正样本是个啥样。而且大部分和样本中的正样本很相似。
如图:
其实关键区别就是应用异常检测的时候,异常通常超级超级少。所以这时候用监督学习是很难的(学不到什么东西)。
取而代之的是我们用负样本来学习概率。
下面是异常检测和监督学习的一些应用:
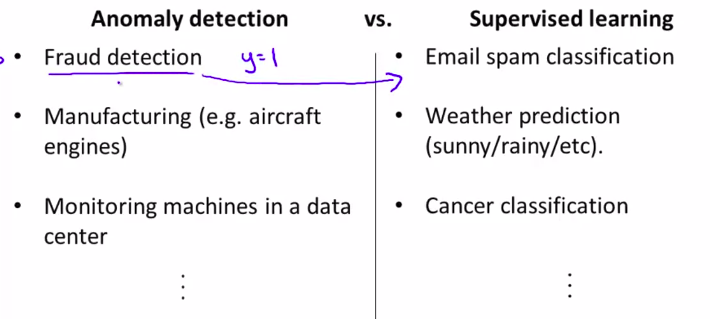
当然并不是绝对,还是要看样本的结构来确定
6. Choosing What Features to Use
对于一个异常检测算法,对它的效率影响 最大的因素之一是,你使用了什么特征变量,以此来输入异常检测的算法。那么,如何来设计或者选择特征量?
如果特征量的直方图很想高斯分布,这样我们就很乐意把这个特征量送入算法。
但是,如果不像的话,我们可以对特征量进行数学处理。使之尽可能像高斯分布
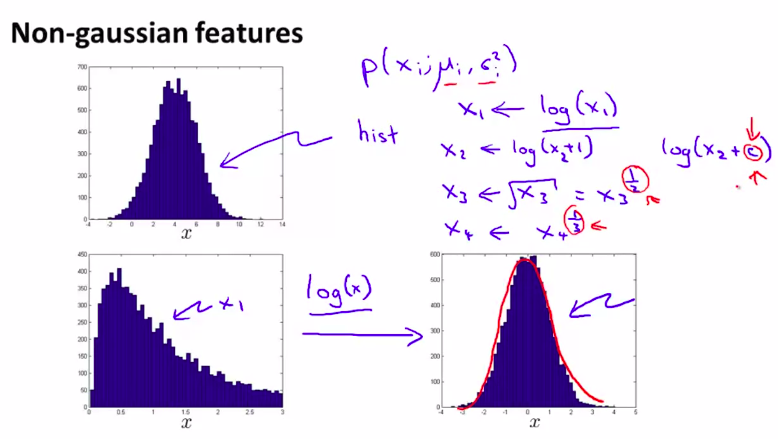
当然,这样的调整在Matlab上是非常简单的。
具体操作就不想讲了,有log,取平方根等等
接下来,如何得到异常检测算法的特征量呢?
通常用的方法是:通过一个误差分析步骤
其实和监督学习算法时候的误差分析步骤是类似的。也就是,我们先完整的训练出一个学习算法,然后在一组交叉验证集上运行算法,找出那些预测出错的样本,再看看,是否能够找到其他的特征变量,来帮助学习算法,让它在交叉验证的时候,表现的更好!
用图来表示:
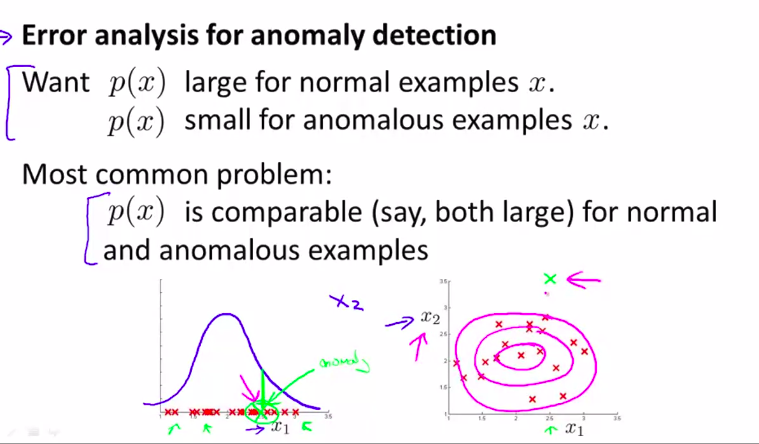
实际例子:

7. Multivariate Gaussian Distribution
一种可能的异常检测算法的衍生
奇怪的异常点:
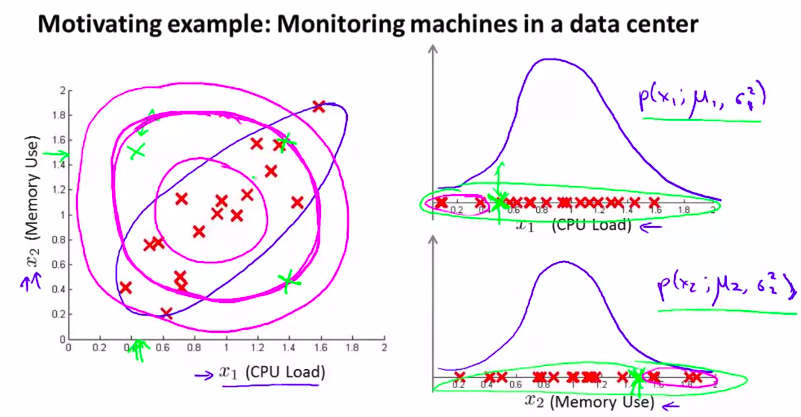
所以,为了解决这种问题,我们要开发一种改良版的异常检测算法
用到一种:多元高斯分布或者多元正态分布

例子:
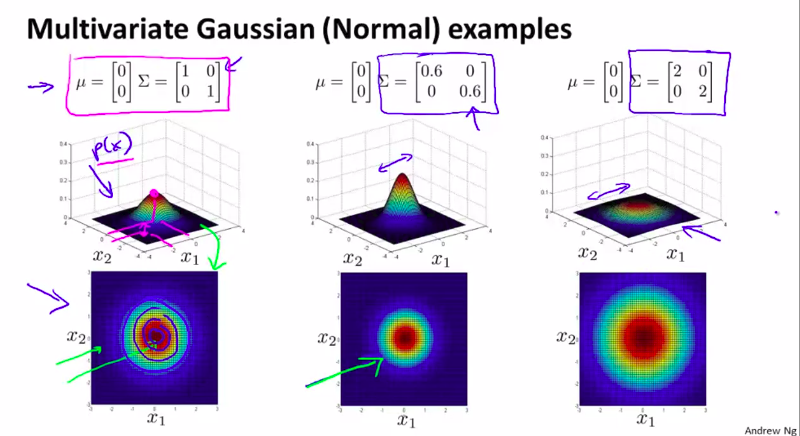
注意观察协方差矩阵的变化和图像的变化
另一种情况:
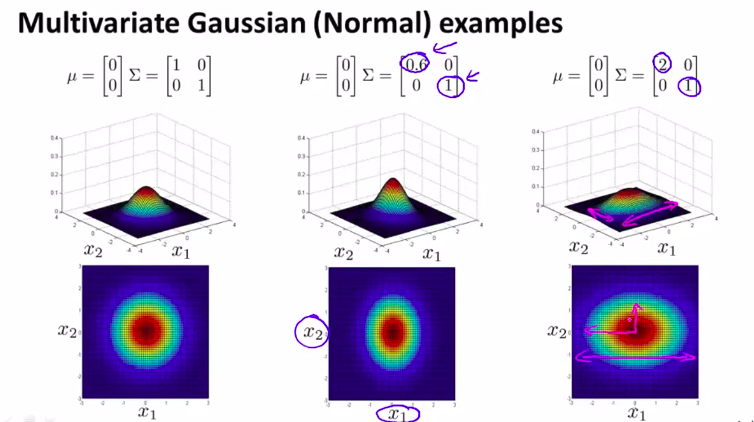
类似的:
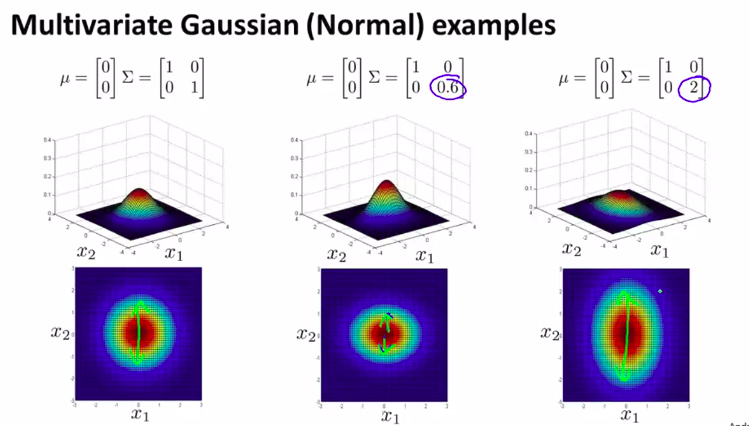
所以,现在,多元高斯分布的一个好处是,你可以用它给数据的相关性建立模型。可以用它来给x1和x2高度相关的情况下建立模型。即:如果改变协方差矩阵非对角线上的元素,你会得到一种不同的高斯分布
如: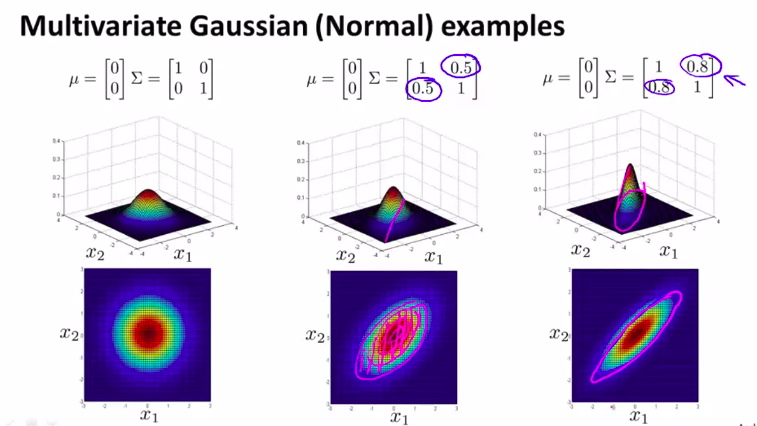
所以,以上是我们把非对角线上的元素设置为正数的情况。如果是负数的话。
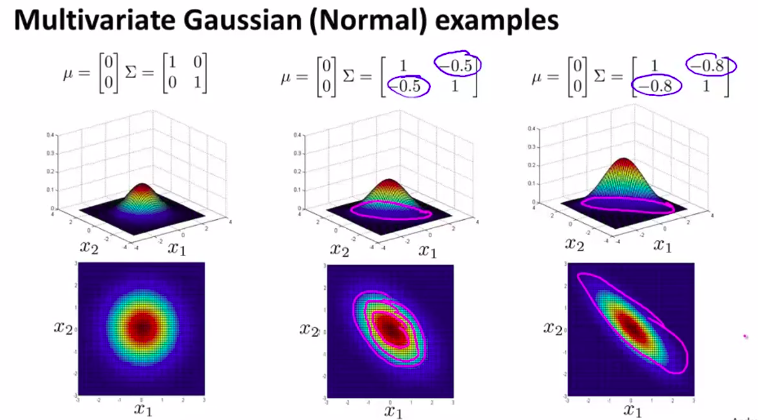
当然,除了协方差矩阵,还可以改变\(\mu\)的值.当然,这只会改变中心点而已
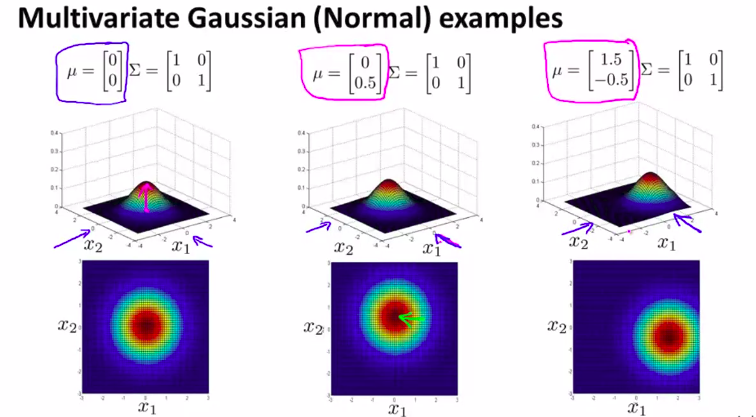
8. Anomaly Detection using the Multivariate Gaussian Distribution
我们先回顾一下上节所说的多元高斯正态分布
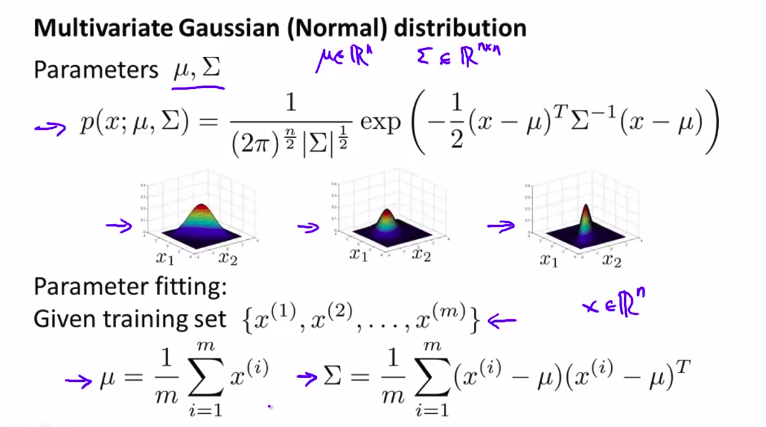
这种高级的方法也就是说:并不是像传统的方法,将所有关于x_i的p_i相乘,而是通过协方差矩阵,来拟合一个同时由多个特征量决定的正态分布函数,也就是多元正态分布函数

区别如下图:

注意观察,传统的图像的拉伸等都是沿着轴向的,这也导致了前面所说的那个异常点无法处理的情况出现。
这其实只不过是多元高斯函数的一种特例罢了
即:非对角线项全部为 0!

但是,什么时候用哪个呢?
- Original model 传统模型(更常用)
手动选择特征量来进行异常处理的时候。而不需要考虑到特征之间的相关性.
但是计算更cheaper !
样本数量小的时候也可以用! - Multivariate Gaussian多元高斯模型
需要考虑特征量之间的关系的时候!
但是计算更加cost !
而且,样本数量一定要大于特征量,否则矩阵会不可逆!
如图:

Tips:如果拟合 多元高斯模型的时候,如果发现协方差矩阵 \(\Sigma\) 是不可逆的,一般只有2种情况
- m>n(一定要满足)
- 含有冗余特征量
冗余特征量意思就是,有的特征量根本不传达信息,
也即是说 多余!!
从数学上来讲,也可以理解为,特征量矩阵中,有线性相关的项!!!
当然,碰上冗余特征量的几率超级小
week_9(异常检测)的更多相关文章
- 利用KD树进行异常检测
软件安全课程的一次实验,整理之后发出来共享. 什么是KD树 要说KD树,我们得先说一下什么是KNN算法. KNN是k-NearestNeighbor的简称,原理很简单:当你有一堆已经标注好的数据时,你 ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- 异常检测算法--Isolation Forest
南大周志华老师在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结. iTree 提到森林 ...
- 机器学习:异常检测算法Seasonal Hybrid ESD及R语言实现
Twritters的异常检测算法(Anomaly Detection)做的比较好,Seasonal Hybrid ESD算法是先用STL把序列分解,考察残差项.假定这一项符合正态分布,然后就可以用Ge ...
- Spark实战4:异常检测算法Scala语言
异常检测原理是根据训练数据的高斯分布,计算均值和方差,若测试数据样本点带入高斯公式计算的概率低于某个阈值(0.1),判定为异常点. 1 创建数据集转化工具类,把csv数据集转化为RDD数据结构 imp ...
- 基于机器学习的web异常检测
基于机器学习的web异常检测 Web防火墙是信息安全的第一道防线.随着网络技术的快速更新,新的黑客技术也层出不穷,为传统规则防火墙带来了挑战.传统web入侵检测技术通过维护规则集对入侵访问进行拦截.一 ...
- Andrew Ng机器学习课程笔记--week9(上)(异常检测&推荐系统)
本周内容较多,故分为上下两篇文章. 一.内容概要 1. Anomaly Detection Density Estimation Problem Motivation Gaussian Distrib ...
- 异常检测算法:Isolation Forest
iForest (Isolation Forest)是由Liu et al. [1] 提出来的基于二叉树的ensemble异常检测算法,具有效果好.训练快(线性复杂度)等特点. 1. 前言 iFore ...
- 《为大量出现的KPI流快速部署异常检测模型》 笔记
以下我为这篇<Rapid Deployment of Anomaly Detection Models for Large Number of Emerging KPI Streams>做 ...
随机推荐
- Docker搭建kafka及监控
环境安装 docker安装 yum update yum install docker # 启动 systemctl start docker # 加入开机启动 systemctl enable do ...
- Qemu/Limbo/KVM镜像 最精简Linux+Wine,可运行Windows软件,内存占用不到70M,存储占用500M
镜像特征: Alpine Edge系统 内置Wine 7.8,可运行大量Windows 软件 高度精简,内存占用仅68MB,存储占用仅500MB 完全开源 镜像说明: 用户名为root,密码为空格. ...
- 关于aws的ec2实例导出成ova后在vmware中的网络配置不生效的问题
在aws上的ec2实例,尤其是使用了aws市场中的ami创建的linux系统,默认情况下,网络配置都是通过dhcp自动获取的, 这周笔者将一台ec2实例(redhat/linux 8.3)导出/转换成 ...
- 常见的 Kerberos 错误消息
常见的 Kerberos 错误消息 问题:All authentication systems disabled; connection refused 原因:此版本的 rlogind 不支持任何验证 ...
- CSAPP实验attacklab
attacklab 实验报告和答案文件都在 https://github.com/thkkk/attacklab
- golang的内存管理
0.1.索引 https://blog.waterflow.link/articles/1663406367769 1.内存管理 内存管理是管理计算机内存的过程,在主存和磁盘之间移动进程以提高系统的整 ...
- pta第一次博客
目录 pta第一次博客 1.前言 2.设计与分析 第二次作业第二题 第三次作业第一题 第三次作业第二题 第三次作业第三题 3.踩坑心得: 4.改进建议 5.总结 pta第一次博客 1.前言 这三次pt ...
- 前后端分离项目(九):实现"添加"功能(后端接口)
好家伙,来了来了,"查"已经完成了,现在是"增" 前端的视图已经做好了,现在我们来完善后端 后端目录结构 完整代码在前后端分离项目(五):数据分页查询(后端 ...
- Day16异常1
package com.exception.demo01;public class demo01 { public static void main(String[] args) { try{new ...
- jupyter初体验
安装: 1.若是已经安装了anaconda,则通过 jupyter notebook 命令进入: 2.若是只安了python: pip3 install --upgrade pip 对pip进行 ...