NLP论文解读:无需模板且高效的语言微调模型(上)
原创作者 | 苏菲
论文题目:
Prompt-free and Efficient Language Model Fine-Tuning
论文作者:
Rabeeh Karimi Mahabadi
论文地址:
https://openreview.net/pdf?id=6o5ZEtqP2g
提示学习(Prompt-learning)被誉为自然语言处理的“第 4 种范式”,它可以在少样本甚至零样本的条件下,通过将下游任务修改为语言生成任务来获得相对较好的模型。
但是,传统的提示学习需要针对下游任务手工设计模板,而且采用自回归的训练预测方法非常耗时。本文提出的PERFECT方法,无需手工设计特定模板,大大降低内存和存储消耗(分别降低了5个百分点和100个百分点)。
在12个NLP任务中,这种微调方法(PERFECT)在简单高效的同时,取得了与SOTA方法(如PET提示学习模型)相近甚至更高的结果。
论文的创新之处在于:
(1)使用特定任务适配器替代手工制作任务提示,提高了微调的采样效率且降低内存及存储消耗;
(2)使用不依赖于模型词汇集的多标记标签向量学习,替代手工编制的语言生成器,可以避免复杂的自回归解码过程。
01 背景介绍
论文作者首先介绍了少样本语言模型微调以及提示学习的问题定义、适配器、基于提示的微调、训练策略、预测策略等,然后再提出论文对这一问题和模型的改进方法。
图1所示的是一个情感分类器(提示学习模型),输入的提示模板为“x It was [MASK]”, 可以替换x为输入文本,通过语言生成器(Verbalizers)把词汇对应到极性标签(‘positive’或者‘negative’),从而获得整个文本的情感类别。
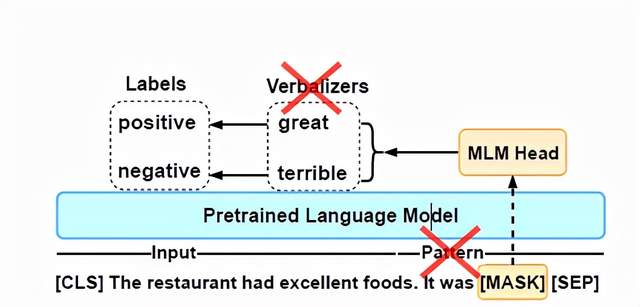
图1
现存的提示学习模型需要手工精心设计提示模板和语言生成器,以便将任务转化为掩码语言模型(MLM)和完形填空格式。这篇论文提出的PERFECT方法不需要任何手工构建工作,且可以去掉提示模板和语言生成器。
1.1问题的定义

论文作者进一步设定验证集与训练集的样本数相同(因为更大的验证集可能更有优势),因此论文作者使用的训练集有16个样本,即N=16,同时使用的验证集也有16个样本,总共是32个样本的少样本学习数据集。
1.2 适配层(Adapters)
在具有超大规模参数的预训练语言模型(PLMs)中,微调语言模型时可以通过加入一个小的特定任务层(称为适配层Adapters),那么在训练语言模型时只需要训练新加入的适配层和归一化层,而语言模型中的其它参数保持不变。
例如在Transformer模型中,其中的每一层主要由一个注意力block和一个前馈block构成,而这两个block后面都会接一个跳跃连接层;通常把适配层插在这些block之后且在跳跃连接层之前(如图2所示),那么在训练时仅仅需要优化图中绿色模块的参数。
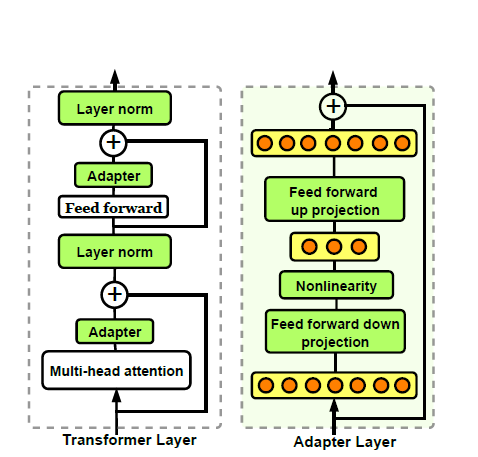
图2
1.3 基于提示的微调
标准的微调:标准的预训练语言模型微调方法是,首先将一个特殊符号[CLS]加入到输入x中,然后模型将其映射到隐藏层中的序列表示
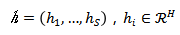

这种标准微调的主要缺点在于预训练和微调之间可能存在不一致,因为预训练时已经使用一个掩码语言模型进行了训练(用于预测被掩蔽的tokens),而微调时也进行了同样的训练。
基于提示的微调:为了解决这种不一致,基于提示的微调把任务转换为完型填空的形式。例如,图1所示的情感分类任务中,输入被转换为下面的提示形式:
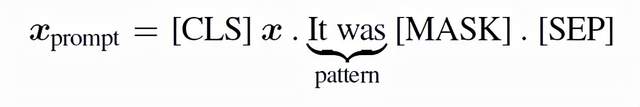

训练的策略:设是下游任务的标签,使用语言生成器(Verbalizers)可以将一个标签映射到预训练语言模型词库中的一个词语。那么,利用提示模板中的MASK,分类任务被转换到预测一个掩码的目标词语,预测标签y的概率为:
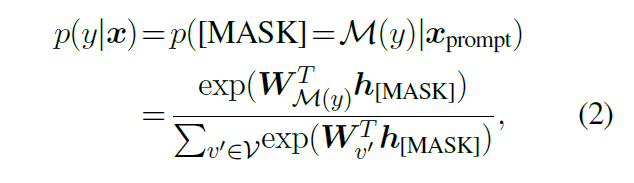

预测的策略:在预测阶段,这种基于提示的微调模型需要在给定上下文环境中选择使用哪一个Verbalizer,一般采取自回归的方式进行选择。首先把掩码token的数目从M修剪到每一个候选Verbalizer的token长度,并计算每一个掩码token概率。
然后,用概率最大的Verbalizer中的token替代相应的掩码token,再重新计算剩下的掩码token概率。重复这种自回归解码方式,直到所有要预测的掩码token都被计算完毕。
这种预测策略速度很慢,因为模型中前向路径传递的数目会随着类别数目、Verbalizer的token数目的增加而增长。
总的看来,基于提示的微调方法的成功严重依赖于手工工程的patterns和verbalizers,而寻找合适的verbalizers和patters也是困难的。
此外,手工定制的verbalizers会带来以下的效率方面的问题:
a)由于需要更新预训练语言模型的embedding层,所以会引起大量内存超负荷;
b)由于需要很小的学习率(通常是10-5),这会大大减慢verbalizers的微调速度;
c)把verbalizers作为预训练语言模型的一个token会影响输入在微调时的表示学习;
d)verbalizers的token长度是变化的,这使得其向量化会变得复杂,也是提高微调效率的一个挑战。为了解决上述困难和挑战,论文作者提出了下面的无需verbalizer和patterns的少样本学习微调方法(PERFECT)。
论文解读上篇先到这里,下篇将为大家继续分享作者独到的创新之处。
NLP论文解读:无需模板且高效的语言微调模型(上)的更多相关文章
- NLP论文解读:无需模板且高效的语言微调模型(下)
原创作者 | 苏菲 论文题目: Prompt-free and Efficient Language Model Fine-Tuning 论文作者: Rabeeh Karimi Mahabadi 论文 ...
- 医学AI论文解读 |Circulation|2018| 超声心动图的全自动检测在临床上的应用
文章来自微信公众号:机器学习炼丹术.号主炼丹兄WX:cyx645016617.文章有问题或者想交流的话欢迎- 参考目录: @ 目录 0 论文 1 概述 2 pipeline 3 技术细节 3.1 预处 ...
- 人工智能论文解读精选 | PRGC:一种新的联合关系抽取模型
NLP论文解读 原创•作者 | 小欣 论文标题:PRGC: Potential Relation and Global Correspondence Based Joint Relational ...
- 从单一图像中提取文档图像:ICCV2019论文解读
从单一图像中提取文档图像:ICCV2019论文解读 DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regressi ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- 注意力论文解读(1) | Non-local Neural Network | CVPR2018 | 已复现
文章转自微信公众号:[机器学习炼丹术] 参考目录: 目录 0 概述 1 主要内容 1.1 Non local的优势 1.2 pytorch复现 1.3 代码解读 1.4 论文解读 2 总结 论文名称: ...
- 论文解读丨基于局部特征保留的图卷积神经网络架构(LPD-GCN)
摘要:本文提出一种基于局部特征保留的图卷积网络架构,与最新的对比算法相比,该方法在多个数据集上的图分类性能得到大幅度提升,泛化性能也得到了改善. 本文分享自华为云社区<论文解读:基于局部特征保留 ...
随机推荐
- web.xml 配置文件?
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi="http:// ...
- Python绘图工具turtle库的使用
#PythonDraw.py import turtle #引入了一个绘图库(海归库) turtle.setup(650,350,200,200) #设置一个窗体 turtle.penup() #将画 ...
- 转载_最值得阅读学习的10个C语言开源项目代码
"源代码面前,了无秘密",阅读优秀代码无疑是开发人员得以窥见软件堂奥而登堂入室的捷径.本文选取10个C语言优秀开源项目的代码作为范本,分别给予点评,免去东搜西罗之苦,点赞!那么问题 ...
- 用Java实现生成图片验证码
通过代码实现生成一个随机验证码图片,且生成后自动打开: package day_12_17; import javax.imageio.ImageIO; import java.awt.*; impo ...
- Java判断是否是回文字符串
public static boolean isPalindrome(String str) { int start = 0, end = str.length() - 1; while (start ...
- iOS 如何监听用户在手机设置里改变了系统的时间?
如何监听用户未退出APP但通过Home键在手机设置里改变了系统的时间? 用户虽未退出APP,但是当它按Home键退到后台时 ,会调用该方法: - (void)applicationDidEnterBa ...
- Note -「Lagrange 插值」学习笔记
目录 问题引入 思考 Lagrange 插值法 插值过程 代码实现 实际应用 「洛谷 P4781」「模板」拉格朗日插值 「洛谷 P4463」calc 题意简述 数据规模 Solution Step 1 ...
- verification 时间不推进,挂起
时间不推进,挂起 0时刻 windows-> new -> source Browser 可能是仿真精度不够,比如进度是1ns,但是时钟有0.1ns为周期的,这种情况下,仿真器会吧这个周期 ...
- Spring系列18:Resource接口及内置实现
本文内容 Resource接口的定义 Resource接口的内置实现 ResourceLoader接口 ResourceLoaderAware 接口 Resource接口的定义 Java 的标准 ja ...
- JAVA8学习——Stream底层的实现二(学习过程)
继续深入Stream的底层实现过程 2.spliterator() 接上 https://www.cnblogs.com/bigbaby/p/12159495.html 我们这次回到最开始源码分析的地 ...