学习 MongoDB(一)
1、介绍
MongoDB是C++语言编写,是一个基于分布式文件存储的开源数据库系统,MongoDB将数据存储为一个文档,
数据结构由键值对(key=>value)组成,MongoDB文档类似于 JSON 对象
2、MongoDB和MySQL对比
1、逻辑结构对比
MySQL mongo
库 库
表 集合
字段 key:value
行 文档 2、内容对比:
1)mysql数据结构:
name age job
oldzhang 28 it
xiaozhang 28 it
xiaofei 18 student 2)mongo数据结构:
{name:'oldzhang',age:'28',job:'it'},
{name:'xiaozhang',age:'28',job:'it'},
{name:'xiaofei',age:'18',job:'student'}
3、应用场景
游戏场景: 使用 MongoDB 存储游戏的用户信息,装备、积分等直接以内嵌文档的形式存储,方便查询、更新
物流场景: 使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来
社交场景: 使用 MongoDB 存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能
物联网场景: 使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析
视频直播: 使用 MongoDB 存储用户信息、礼物信息等,用户评价
电商场景: 使用 MongoDB 存储上衣和裤子两种商品,除了有共同属性(产地、价格、材质、颜色等),还有各自不同的属性(上衣的肩宽、胸围、袖长,裤子臀围、脚口和裤长)
4、安装与部署
官方文档:https://docs.mongodb.com/manual/?_ga=2.57024426.1834178963.1557492386-816165234.1557492386
1、系统准备
1) redhat或cnetos6.2以上系统
2) 系统开发包完整
3) ip地址和hosts文件解析正常
4) iptables防火墙&SElinux关闭
5) 关闭大页内存机制
# echo never > /sys/kernel/mm/transparent_hugepage/enabled
# echo never > /sys/kernel/mm/transparent_hugepage/defrag
其他系统关闭参照官方文档: https://docs.mongodb.com/manual/tutorial/transparent-huge-pages/
# vim /etc/security/limits.conf
* - nofile 65535 2、二进制安装
下载地址:https://www.mongodb.org/dl/linux/
1)创建用户和组
# useradd mongodb -s /sbin/nologin -M 2)创建mongodb所需目录
# mkdir -p /mongodb/{conf,log,data} 3)下载并解压软件到指定位置
# wget http://downloads.mongodb.org/linux/mongodb-linux-x86_64-rhel70-3.2.16.tgz
# tar xf mongodb-linux-x86_64-rhel70-3.6.12_.tgz
# cp -a mongodb-linux-x86_64-rhel70-3.6.12/bin /mongodb/ 4)设置目录权限
# chown -R mongod:mongod /mongodb 5)设置用户环境变量
# su - mongod
# vim .bash_profile
export PATH=/mongodb/bin:$PATH
# source .bash_profile 3、启动mongodb
# su - mongod
# mongod --dbpath=/mongodb/data --logpath=/mongodb/log/mongodb.log --port=27017 --logappend --fork 4、配置文件说明(YAML格式)
systemLog: #系统日志
destination: file #日志以文件保存
path: "/mongodb/log/mongodb.log" #日志位置
logAppend: true #日志以追加模式记录
storage: #数据存储
journal: #记录回滚日志
enabled: true
dbPath: "/mongodb/data" #数据路径的位置
directoryPerDB: true
wiredTiger: #存储引擎
engineConfig:
cacheSizeGB: 1 #缓存大小
directoryForIndexes: true #索引单独存放
collectionConfig:
blockCompressor: zlib #启动压缩
indexConfig:
prefixCompression: true
processManagement: #进程控制
fork: true #后台守护进程
pidFilePath: <string> #pid文件的位置,一般不配置,自动生成到data中
net: #网络配置
bindIp: <ip> #监听地址
port: <port> #端口号,不配置默认是: 27017
security: #安全配置
authorization: enabled #打开用户名密码验证 5、编写配置文件
# cat > /mongodb/conf/mongo.conf <<EOF
systemLog:
destination: file
path: "/mongodb/log/mongodb.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "/mongodb/data/"
processManagement:
fork: true
net:
port: 27017
bindIp: 10.0.1.51,127.0.0.1
EOF 6、mongodb的关闭和启动方式
# mongod -f /mongodb/conf/mongo.conf --shutdown
# mongod -f /mongodb/conf/mongo.conf
# mongo localhost:27017 #登录
> use admin #切换库
> db.shutdownServer() #执行关机函数 7、systemd 管理(root)
# cat > /etc/systemd/system/mongod.service <<EOF
[Unit]
Description=mongodb
After=network.target remote-fs.target nss-lookup.target
[Service]
User=mongod
Type=forking
ExecStart=/mongodb/bin/mongod --config /mongodb/conf/mongo.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/mongodb/bin/mongod --config /mongodb/conf/mongo.conf --shutdown
PrivateTmp=true
[Install]
WantedBy=multi-user.target
EOF
# systemctl restart mongod
# systemctl stop mongod
# systemctl start mongod
5、mongodb基本操作
1、默认库
# mongo #登录
> show databases #查看库
> show dbs
admin库: 系统预留库,MongoDB系统管理库
local库: 本地预留库,存储关键日志
config库: MongoDB配置信息库
test库: 登录时默认存在的库(隐藏的库) 2、命令种类
1) 库
> db #当前在的库
> db.[TAB] #类似于linux中的tab功能
> db.help() #db级别的命令使用帮助
2) 表(collection):
> db.Collection_name.xxx
3) 行(document)
> db.t1.insert()
4)复制集有关(replication set):
> rs.[TAB]
> rs.help()
5)分片集群(sharding cluster)
> sh.[TAB]
> sh.help() 3、帮助
> help
> KEYWORDS.help()
> KEYWORDS.[TAB]
> db.help()
> db.a.help()
> rs.help()
> sh.help() 4、常用操作
> db.version() #查看当前db版本
> db #显示当前数据库
> db.getName() #显示当前数据库
> show dbs #查询所有数据库
> use local #切换数据库
> show tables; #查看所有表
> db.stats() #显示当前数据库状态
> db.getMongo() #查看当前数据库的连接机器地址
> db.hello.insert({name:"a"}) #录入数据
> db.hello.find() #查看数据
> db.hello.drop() #删除表 5、库的操作
> use linux #use库,自动创建(临时,show 看不到库)
> db.db.insert({name:"haha"}) #创建db库,并插入数据(永久库)
> db.dropDatabase() #删除数据库(要use库) 6、集合的操作
1) 创建表:
方法1:
> use app
> db.createCollection('a')
> db.createCollection('b')
> show tables; #查看当前库所有的表
> db.getCollectionNames()
方法2:
> use oldboy
> db.oldguo.insert({id:"1",name:"tom"}) #自动创建表
2) 查询数据
> db.oldguo.find() #查看所有数据(默认显示20条,输入it,查看下一页)
> db.oldguo.find({id:"1"}) #查找某个条件
> db.oldguo.find({id:"1"}).pretty() #按行显示(json)
3) 删除集合
> use app
> db.log.drop() #删除表
4) 重命名集合
> db.log.renameCollection("log1") #更改表名
5) 批量插入数据
for(i=0;i<10000;i++){db.log.insert({"uid":i,"name":"mongodb","age":6,"date":newDate()})}
6) 其他
> DBQuery.shellBatchSize=50; #每页显示50条记录
> db.log.findOne() #查看第1条记录
> db.log.count() #统计记录数
> db.log.remove({}) #删除集合中所有记录
> db.log.distinct("name") #某列去重
> db.log.stats() #集合状态
> db.log.dataSize() #集合中数据的原始大小
> db.log.totalIndexSize() #集合中索引数据的原始大小
> db.log.totalSize() #集合中索引+数据压缩存储之后的大小
> db.log.storageSize() #集合中数据压缩存储的大小
6、用户及权限管理
1、介绍
MySQL 的登录验证方式: 用户名+密码+IP+端口号
MongoDB的登录验证方式: 用户名+密码+IP+端口号+验证库 2、注意事项
验证库: 建立用户时use到的库,对于管理员用户,必须在admin库下创建
1) 建用户时,use到的库,就是此用户的验证库
2) 登录时,必须明确指定验证库才能登录
3) 管理员的验证库是admin,普通用户的验证库是所管理的库
4) 如果直接登录到数据库,不进行use,默认的验证库是test,生产不推荐
5) 从3.6 版本开始,不添加bindIp参数,默认不让远程登录,只能本地管理员登录 3、用户创建语法
> use admin #在库下创建用户
> db.createUser( #创建用户命令
{
user: "root", #用户名
pwd: "root123", #密码
roles: [
{ role: "root", #角色(root,readWrite,read)
db: "admin" } ] #管理的库
}
)
登录
# mongo -u root -p 10.0.0.51/admin 4、创建超级管理员
1) 修改配置文件(开启认证功能)
# vim /mongodb/conf/mongo.conf
net:
port: 27017
bindIp: 10.0.0.51,127.0.0.1
security:
authorization: enabled
2) 创建管理员用户(必须use admin库下去创建,只能针对库设置权限,不能针对表)
# mongo
> use admin
> db.createUser(
{
user: "root",
pwd: "root123",
roles: [ { role: "root", db: "admin" } ]
}
)
3) 验证用户
> db.auth('root','root123')
4) 重启mongodb
# mongod -f /mongodb/conf/mongo.conf --shutdown
# mongod -f /mongodb/conf/mongo.conf
5) 登录验证
方法1:
# mongo -uroot -proot123 admin
# mongo -uroot -proot123 10.0.0.51/admin
# mongo -uroot -proot123 10.0.0.51:27017/admin
方法2:
# mongo
> use admin
> db.auth('root','root123')
6) 查看用户:
> use admin
> db.system.users.find().pretty() #查看用户的信息 5、创建库管理用户
1) 管理员登录
# mongo -uroot -proot123 admin
2) 创建app库管理用户
> use app
> db.createUser(
{
user: "admin",
pwd: "admin",
roles: [ { role: "dbAdmin", db: "app" } ]
}
)
3) 验证并登录测试
> db.auth('admin','admin')
# mongo -uadmin -padmin 10.0.0.51/app 6、创建app库,可读可写的用户
1) 管理员登录
# mongo -uroot -proot123 admin
2) 创建app库管理用户
> use app
> db.createUser(
{
user: "app01",
pwd: "app01",
roles: [ { role: "readWrite", db: "app" } ]
}
)
3) 验证并登录测试
# mongo -uapp01 -papp01 10.0.0.51/app 7、创建app库可读可写,并对test库只读的用户
1) 管理员登录
# mongo -uroot -proot123 10.0.0.51/admin
2) 创建app库管理用户
> use app
> db.createUser(
{
user: "app02",
pwd: "app02",
roles: [ { role: "readWrite", db: "app" },
{ role: "read", db: "test" }]
}
)
3) 验证并登录测试
# mongo -uapp02 -papp02 10.0.0.51/app
> db.system.users.find().pretty() 8、删除用户
1) 管理员登录
# mongo -uroot -proot123 10.0.0.51/admin
2) 删除用户(必须use到用户的验证库)
> use app
> db.dropUser("app01")
7、MongoDB复制集RS(ReplicationSet)
1、基本原理
基本1主2从的结构,自带互相监控投票机制(Raft(MongoDB)、Paxos(mysql MGR用的是变种))
如果发生主库宕机,复制集内部进行投票选举,选择一个新的主库,
并自动通知客户端程序,主库已经发生切换,应用就会连接到新的主库 2、 Replication Set配置
1) 环境准备
多实例: 三个以上的mongodb节点(28017、28018、28019、28020)
2) 创建目录
# su - mongod
$ mkdir -p /mongodb/{28017,28018,28019,28020}/{data,conf,log}
3) 创建配置文件
$ cat > /mongodb/28017/conf/mongod.conf <<EOF
systemLog:
destination: file
path: /mongodb/28017/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/28017/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
processManagement:
fork: true
net:
bindIp: 10.0.0.51,127.0.0.1
port: 28017
replication:
oplogSizeMB: 2048
replSetName: my_repl
EOF
$ cp /mongodb/28017/conf/mongod.conf /mongodb/28018/conf/
$ cp /mongodb/28017/conf/mongod.conf /mongodb/28019/conf/
$ cp /mongodb/28017/conf/mongod.conf /mongodb/28020/conf/
$ sed -i 's#28017#28018#g' /mongodb/28018/conf/mongod.conf
$ sed -i 's#28017#28019#g' /mongodb/28019/conf/mongod.conf
$ sed -i 's#28017#28020#g' /mongodb/28020/conf/mongod.conf
4) 启动多个实例
$ mongod -f /mongodb/28017/conf/mongod.conf
$ mongod -f /mongodb/28018/conf/mongod.conf
$ mongod -f /mongodb/28019/conf/mongod.conf
$ mongod -f /mongodb/28020/conf/mongod.conf
5) 检查端口
$ netstat -lnp|grep 280 3、配置普通复制集(1主2从,从库普通从库)
1) 登录到28017节点
$ mongo --port 28017 admin
2) 定义一个config变量
> config = {_id: 'my_repl', members: [
{_id: 0, host: '10.0.0.51:28017'},
{_id: 1, host: '10.0.0.51:28018'},
{_id: 2, host: '10.0.0.51:28019'}]
}
> rs.initiate(config) #复制集初始化
3) 查询复制集状态
> rs.status()
备注: 创建完复制集,从库默认不可读写,看不到数据,需要执行命令才能读
临时命令(rs.slaveOk()),永久命令(echo "rs.slaveOk();" > ~/.mongorc.js) 4、1主1从1个arbiter
1) 登录到28017节点
$ mongo -port 28017 admin
2) 定义一个config变量
> config = {_id: 'my_repl', members: [
{_id: 0, host: '10.0.0.51:28017'},
{_id: 1, host: '10.0.0.51:28018'},
{_id: 2, host: '10.0.0.51:28019',"arbiterOnly":true}]
}
> rs.initiate(config) 5、复制集管理操作
1) 查看复制集
> rs.status() #查看复制集状态
> rs.isMaster() #查看当前是否为主节点
> rs.conf() #查看复制集配置信息
2) 添加删除节点
> rs.remove("ip:port") #删除一个从节点
> rs.add("ip:port") #添加一个从节点
> rs.addArb("ip:port") #添加一个仲裁节点 6、实例
1) 连接到主节点
$ mongo --port 28018 admin
2) 添加仲裁节点
> rs.addArb("10.0.0.53:28020")
3) 查看节点状态
> rs.isMaster()
4) 删除一个节点
> rs.remove("10.0.0.53:28019");
> rs.isMaster()
5) 新增从节点
> rs.add("10.0.0.53:28019")
> rs.isMaster() 7、特殊从节点
1) 介绍
arbiter节点: 负责选主过程中的投票,不存储任何数据,不提供任何服务
hidden节点: 隐藏节点,不参加选主,不对外提供服务
delay节点: 延时节点,数据落后于主库一段时间,不提供服务,不参加选主,通常配合hidden使用
priority 0: 权重为0,不参加选主
2) 配置延时节点(一般延时节点也配置成hidden)
> cfg=rs.conf() #把rs.conf()输出信息,赋值给变量cfg
> cfg.members[2].priority=0 #利用cfg变量调用节点,修改相应部分
> cfg.members[2].hidden=true
> cfg.members[2].slaveDelay=120
> rs.reconfig(cfg) #重新读取
3) 查看状态
> rs.conf()
4) 取消延时节点
> cfg=rs.conf()
> cfg.members[2].priority=1
> cfg.members[2].hidden=false
> cfg.members[2].slaveDelay=0
> rs.reconfig(cfg)
5) 注意事项
[2]: 中括号中的数字,不是id 的值,是节点的编号,从0开始 8、其他操作命令
> rs.conf() #查看副本集的配置信息
> rs.status() #查看副本集的状态
> rs.stepDown() #副本集角色切换(不要人为随便操作)
> rs.freeze(300) #锁定从库,不会变成主库(freeze()和stepDown单位都是秒)
> rs.slaveOk() #设置从库可读,在从库执行
> rs.printSlaveReplicationInfo() #查看副本节点(监控主从延时) 9、配置文件解析
1) 日志
systemLog: #系统日志
destination: file #日志输出,可指定file或syslog(输出到日志文件),若不指定,则输出到标准输出
verbosity: 0 #日志级别,0:默认值,包含info信息,1~5包含debug信息
logAppend: true #日志追加,当mongod/mongos重启后,true(追加模式继续记录),false(创建新的日志文件)
logRotate: rename #日志轮询,rename(重命名日志文件,默认值),reopen(利用logrotate特性,关闭并重新打开此日志文件,logAppend必须为true)
2)存储
storage: #存储相关
journal #是否开启回滚日志,用来恢复数据,仅对mongod进程有效,64位默认(true),32位(false)
directoryPerDB: true #是否将不同DB的数据,存储在不同的目录中
engine #存储引擎类型,3.0之后支持mmapv1(相当于MyISAM)、wiredTiger(相当于InnoDB),默认: mmapv1
wiredTiger: #存储引擎
cacheSizeGB: 1 #wiredTiger缓存工作集,内存大小
directoryForIndexes: true #是否将索引和collections存储到不同的目录
blockCompressor: zlib #数据压缩,算法可选none、snappy、zlib
prefixCompression: true #是否对索引数据使用前缀压缩,前缀压缩(对经过排序的值压缩,有效减少索引数据的内存使用量)
3) 进程管理
processManagement: #进程相关
fork: true #后台运行
pidFilePath: /mongodb/data/mongod.pid #PID 文件路径
4)复制集
replication: #主从复制
oplogSizeMB: 2048 #oplog日志表的大小,oplog是记录到表中,默认为磁盘的5%
replSetName: #复制集的名,主从复制中集群的名字必须相同,在分片集群中,不同的分片,应有不同的名字
8、MongoDB 分片集群SH(Sharding Cluster)
1)、介绍
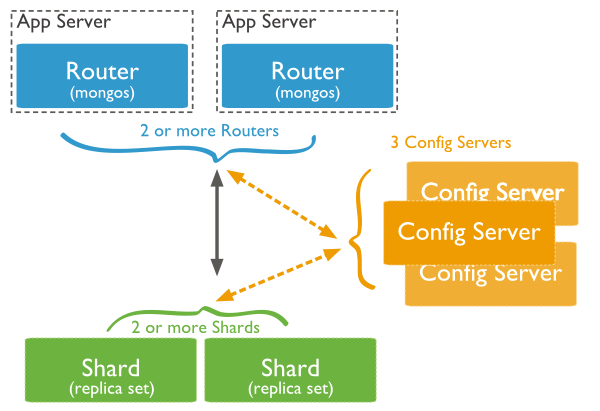
Shard: 分片集群,存储实际的数据,生产环境中一个shard集群,由多台机器多实例组成,防止单点故障
Config Server: 配置集群,mongod实例,存储整个集群的Metadata,其中包括chunk信息
mongos: 和客户端打交道的模块,数据路由,本身没有任何数据,处理数据时,直接找config server
2)、安装部署
1、规划:
10个实例:38017-38026
1) configserver: 38018-38020(3台构成的复制集,1主两从,不支持arbiter,复制集名字configsvr)
2) shard节点: sh1: 38021-38023,sh2: 38024-38026(1主两从,其中一个节点为arbiter,复制集名字sh1,sh2)
3) mongos: 38017 2、shard节点配置
1) 创建目录
# mkdir -p /mongodb/{38021,38022,38023,38024,38025,38026}/{log,data,conf}
2) 修改配置文件
A、sh1(分片节点一,21-23,1主1从1选举Arb)
# cat > /mongodb/38021/conf/mongodb.conf<<EOF
systemLog:
destination: file
path: /mongodb/38021/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/38021/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
bindIp: 10.0.0.51,127.0.0.1
port: 38021
replication:
oplogSizeMB: 2048
replSetName: sh1
sharding:
clusterRole: shardsvr #集群角色名,官方定义,不能自定义
processManagement:
fork: true
EOF
# cp /mongodb/38021/conf/mongodb.conf /mongodb/38022/conf/
# cp /mongodb/38021/conf/mongodb.conf /mongodb/38023/conf/
# sed 's#38021#38022#g' /mongodb/38022/conf/mongodb.conf -i
# sed 's#38021#38023#g' /mongodb/38023/conf/mongodb.conf -i
B、sh2(分片节点二,24-26,1主1从1选举Arb)
# cat > /mongodb/38024/conf/mongodb.conf<<EOF
systemLog:
destination: file
path: /mongodb/38024/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/38024/data
directoryPerDB: true
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
bindIp: 10.0.0.51,127.0.0.1
port: 38024
replication:
oplogSizeMB: 2048
replSetName: sh2
sharding:
clusterRole: shardsvr
processManagement:
fork: true
EOF
# cp /mongodb/38024/conf/mongodb.conf /mongodb/38025/conf/
# cp /mongodb/38024/conf/mongodb.conf /mongodb/38026/conf/
# sed 's#38024#38025#g' /mongodb/38025/conf/mongodb.conf -i
# sed 's#38024#38026#g' /mongodb/38026/conf/mongodb.conf -i
3) 启动节点,并配置复制集
A、启动
# mongod -f /mongodb/38021/conf/mongodb.conf
# mongod -f /mongodb/38022/conf/mongodb.conf
# mongod -f /mongodb/38023/conf/mongodb.conf
# mongod -f /mongodb/38024/conf/mongodb.conf
# mongod -f /mongodb/38025/conf/mongodb.conf
# mongod -f /mongodb/38026/conf/mongodb.conf
B、分片节点一
# mongo --port 38021 admin
> config = {_id: 'sh1', members: [
{_id: 0, host: '10.0.0.51:38021'},
{_id: 1, host: '10.0.0.51:38022'},
{_id: 2, host: '10.0.0.51:38023',"arbiterOnly":true}]
}
> rs.initiate(config)
C、分片节点二
# mongo --port 38024 admin
> config = {_id: 'sh2', members: [
{_id: 0, host: '10.0.0.51:38024'},
{_id: 1, host: '10.0.0.51:38025'},
{_id: 2, host: '10.0.0.51:38026',"arbiterOnly":true}]
}
> rs.initiate(config) 3、config节点配置
1) 创建目录
# mkdir -p /mongodb/{38018,38019,38020}/{log,data,conf}
2) 修改配置文件
# cat > /mongodb/38018/conf/mongodb.conf <<EOF
systemLog:
destination: file
path: /mongodb/38018/log/mongodb.conf
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/38018/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
bindIp: 10.0.0.51,127.0.0.1
port: 38018
replication:
oplogSizeMB: 2048
replSetName: configReplSet
sharding:
clusterRole: configsvr #集群角色名,官方定义,不能自定义
processManagement:
fork: true
EOF
# cp /mongodb/38018/conf/mongodb.conf /mongodb/38019/conf/
# cp /mongodb/38018/conf/mongodb.conf /mongodb/38020/conf/
# sed 's#38018#38019#g' /mongodb/38019/conf/mongodb.conf -i
# sed 's#38018#38020#g' /mongodb/38020/conf/mongodb.conf -i
3) 启动节点,并配置复制集
A、启动
# mongod -f /mongodb/38018/conf/mongodb.conf
# mongod -f /mongodb/38019/conf/mongodb.conf
# mongod -f /mongodb/38020/conf/mongodb.conf
B、配置复制集
# mongo --port 38018 admin
< config = {_id: 'configReplSet', members: [
{_id: 0, host: '10.0.0.51:38018'},
{_id: 1, host: '10.0.0.51:38019'},
{_id: 2, host: '10.0.0.51:38020'}]
}
> rs.initiate(config)
备注: configserver老版本中,可以是一个节点,新版本中,必须是复制集,新老版本都不支持arbiter 4、mongos节点配置
1) 创建目录
# mkdir -p /mongodb/38017/conf /mongodb/38017/log
2) 修改配置文件
# cat >/mongodb/38017/conf/mongos.conf<<EOF
systemLog:
destination: file
path: /mongodb/38017/log/mongos.log
logAppend: true
net:
bindIp: 10.0.0.51,127.0.0.1
port: 38017
sharding:
configDB: configReplSet/10.0.0.51:38018,10.0.0.51:38019,10.0.0.51:38020 #configserver集群节点
processManagement:
fork: true
EOF
3) 启动mongos
# mongos -f /mongodb/38017/conf/mongos.conf
备注: 启动不了,检查configserver集群节点,mongos依赖configserver 5、分片集群添加节点(把shar所有节点加入到configserver集群中)
1)连接mongs的admin数据库
# su - mongod
# mongo 10.0.0.51:38017/admin
2) 添加分片
> db.runCommand( { addshard : "sh1/10.0.0.51:38021,10.0.0.51:38022,10.0.0.51:38023",name:"shard1"} )
> db.runCommand( { addshard : "sh2/10.0.0.51:38024,10.0.0.51:38025,10.0.0.51:38026",name:"shard2"} )
3) 列出分片
> mongos> db.runCommand( { listshards : 1 } )
4) 查看集群状态
> sh.status()
3)、分片集群操作
分片集群操作
1、介绍
1) 分片规则:
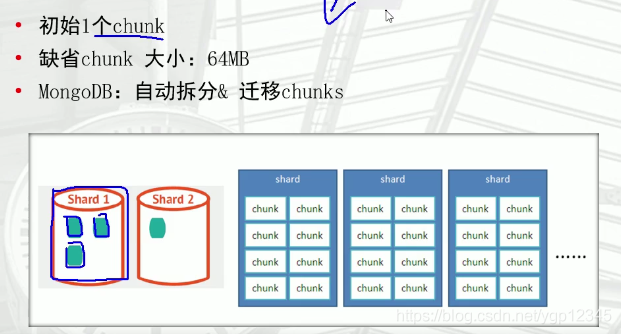
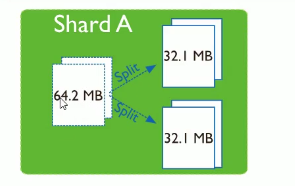
默认数据存储在shard1上,在shard1初始1个chunk(默认大小64M),chunk大于64M,会自动拆分,
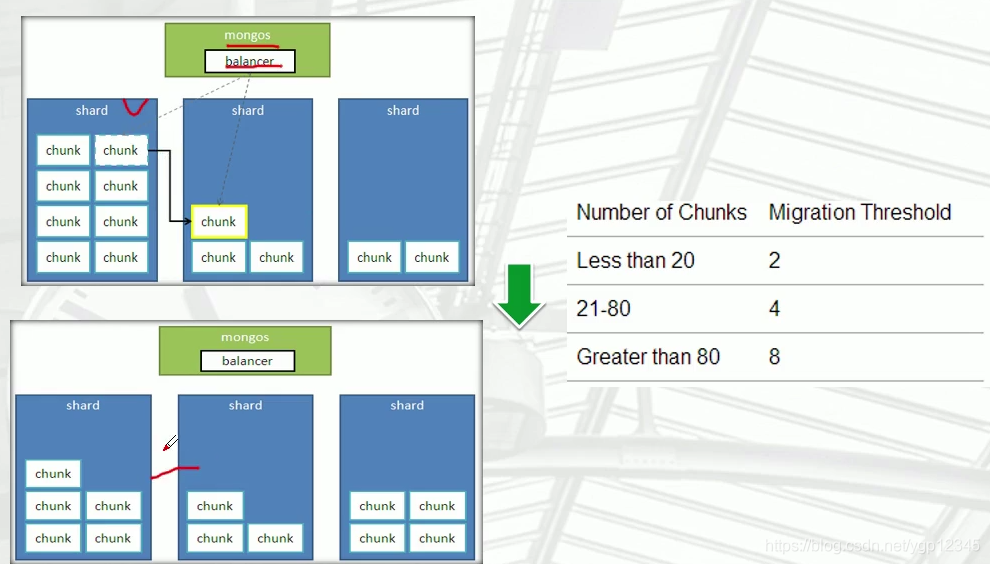
如果shard1的chunk比较多,会自动迁移一部分到shard2,mongos会自动检查所有节点chunk情况,
若发现分片不均衡,会触发balancer操作,自动chunk迁移(通过网络迁移) 2) 分片键
必须为分片collection定义分片键,基于一个或多个列(类似一个索引)
分片键定义数据空间,想象key space类似一条线上一个点数据
一个key range是一条线上一段数据,我们可以按照分片键进行Range和Hash分片
分片键是不可变,分片键必须有索引,分片键大小限制512字节,分片键用于路由查询
MongoDB不接受已进行collection级分片的collection上插入无分片键的文档(不支持空行) 2、Range分片
1) 激活分片功能
# mongo --port 38017 admin
> db.runCommand( { enablesharding : "test" } )
2) 创建索引(分片键必须要建索引)
> use test
> db.vast.ensureIndex( { id: 1 } )
3) 开启分片(range分片一般是数字列,条件查询多的列)
> use admin
> db.runCommand( { shardcollection : "test.vast",key : {id: 1} } ) #1:从小到大,-1:从大到小
4) 插入数据
admin> use test
test> for(i=1;i<1000000;i++){ db.vast.insert({"id":i,"name":"shenzheng","age":70,"date":new Date()}); }
test> db.vast.stats()
5) 查看分片结果
shard1:
# mongo --port 38021
> use test
> db.vast.count();
shard2:
# mongo --port 38024
> use test
> db.vast.count();
备注:去分片节点查看数据,会发现只写在一个节点上,是因为没有设置blancer,
数据录完后,mogos会触发blancer操作,进行chunk自动转移,所以要等一段时间 3、Hash分片
1) 激活分片功能
# mongo --port 38017 admin
> use admin
> db.runCommand( { enablesharding : "oldboy" } )
2) 创建哈希索引
> use oldboy
> db.vast.ensureIndex( { id: "hashed" } )
3) 开启分片
> use admin
> sh.shardCollection( "oldboy.vast", { id: "hashed" } )
4) 插入数据
> use oldboy
> for(i=1;i<100000;i++){ db.vast.insert({"id":i,"name":"shenzheng","age":70,"date":new Date()}); }
5) 查看分片结果
shard1:
# mongo --port 38021
> use oldboy
> db.vast.count();
shard2:
# mongo --port 38024
> use oldboy
> db.vast.count(); 4、分片集群的查询
> sh.status() #分片状态(重要)
> db.runCommand({ isdbgrid : 1}) #判断是否Shard集群
> db.runCommand({ listshards : 1}) #列出所有分片信息
> use config #列出开启分片的数据库
> db.databases.find( { "partitioned": true } )
> db.databases.find() #列出所有数据库分片情况
> db.collections.find().pretty() #查看分片的分片键
> db.printShardingStatus() #查看分片的详细信息 5、分片集群的删除及添加
1) 确认blance是否在工作
> sh.getBalancerState()
2) 删除shard2节点(谨慎)
> db.runCommand( { removeShard: "shard2" } )
注意: 删除操作会立即触发blancer,自动chunk迁移
3) 添加分片
> db.runCommand( { addshard : "sh3/192.168.2.10:38030,192.168.2.11:38031,192.168.2.12:38032",name:"shard3"} )
注意: 添加操作会触发blancer,自动chunk迁移
4)、balancer操作
1、介绍
mongos的一个重要功能,自动巡查所有shard节点上的chunk的情况,自动做chunk迁移。 2、什么时候工作?
1) 自动运行,会检测系统不繁忙的时候做迁移
2) 在做节点删除的时候,立即开始迁移工作
3) balancer只能在预设定的时间窗口内运行(balancer默认24小时工作的,为了性能,必须设置时间)
4) 有需要时可以关闭和开启blancer(备份时,要关闭balancer)
> sh.stopBalancer()
> sh.startBalancer() 3、自定义balancer的时间段
官网文档: https://docs.mongodb.com/manual/tutorial/manage-sharded-cluster-balancer/#schedule-the-balancing-window
1) 登录到mongos
# mongo --port 38017 admin
2) 设置balancer的时间段
> use config
> sh.setBalancerState( true )
> db.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "3:00", stop : "5:00" } } }, true )
3) 查看balancer(2个都可以查看)
> sh.getBalancerWindow()
> sh.status()
4) 关闭某个集合的balance(了解)
> sh.disableBalancing("students.grades")
5) 打开某个集合的balancer(了解)
> sh.enableBalancing("students.grades")
6) 确定某个集合的balance是开启或者关闭(了解)
> db.getSiblingDB("config").collections.findOne({_id : "students.grades"}).noBalance;
9、MongoDB数据备份恢复
1、备份恢复工具介绍
1) mongoexport/mongoimport **
2) mongodump/mongorestore ***** 2、备份工具区别
mongoexport/mongoimport 导入/导出的是JSON格式或者CSV格式
mongodump/mongorestore 导入/导出的是BSON格式
1)JSON可读性强但体积大,BSON是二进制文件,体积小但可读性弱
2)跨版本还原时,BSON格式随版本可能有所不同,不同版本数据迁移会失败,推荐使用JSON格式
3)JSON虽有较好的跨版本通用性,但只保留数据部分,不保留索引,账户等其他基础信息 3、应用场景总结
mongoexport/mongoimport: json csv
1) 异构平台迁移 mysql <---> mongodb
2) 同平台,跨大版本 mongodb 2 ----> mongodb 3
mongodump/mongorestore
日常备份恢复时使用 4、导出工具(mongoexport)
1) 介绍
mongoexport: 把一个collection导出成JSON或CSV格式的文件
使用场景: 版本差异较大,异构平台数据迁移
2) 参数说明
# mongoexport --help
-h: #指明数据库宿主机的IP
-u: #指明数据库的用户名
-p: #指明数据库的密码
-d: #指明数据库的名字
-c: #指明collection的名字
-f: #指明要导出那些列
-o: #指明到要导出的文件名
-q: #指明导出数据的过滤条件
--authenticationDatabase admin #验证库
3) 单表导出json格式
# mongoexport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log -o /mongodb/log.json
4) 单表导出csv格式
# mongoexport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log --type=csv -f uid,name,age,date -o /mongodb/log.csv
5) 注意事项
备份文件名可自定义,默认导出JSON格式数据,加--type=csv -f 字段,导出CSV格式 5、导入工具(mongoimport)
1) 介绍
mongoimport: 一个特定格式文件中的内容,导入到指定的collection中,可以导入JSON或CSV格式数据
2) 参数说明
# mongoimport --help
-h: #指明数据库宿主机的IP
-u: #指明数据库的用户名
-p: #指明数据库的密码
-d: #指明数据库的名字
-c: #指明collection的名字
-f: #指明要导入那些列
-j: #并行(cpu核数)
--drop: #覆盖原来表中内容
3) 恢复json格式数据
# mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log1 /mongodb/log.json
4) 恢复csv格式数据
# csv格式的文件头行,有列名
# mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log2 --type=csv --headerline --file /mongodb/log.csv
# csv格式的文件头行,没有列名
# mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log3 --type=csv -f id,name,age,date --file /mongodb/log1.csv
5) 注意事项
--headerline: 指明第一行是列名,不需要导入,如果导入没有头行,不想加-f只想用--headerline,要手工(vi编辑)加入列名 6、案例(异构平台数据迁移)
1) 介绍
mysql -----> mongodb(mysql里world库city表进行数据导出,再导入到mongodb)
2) mysql开启安全路径
# vim /etc/my.cnf
secure-file-priv=/tmp
# /etc/init.d/mysqld restart
3) 导出mysql的city表数据
以csv的格式导出(fields terminated by ',': 默认分隔符是空格,设置分隔符逗号)
mysql> select * from world.city into outfile '/tmp/city1.csv' fields terminated by ',';
4) 处理备份csv文件
mysql>> desc world.city #查看表字段
# vim /tmp/city.csv(添加第一行列名信息,文件大,不推荐)
ID,Name,CountryCode,District,Population
5) 导入数据
方法1(有列名)
# mongoimport -uroot -proot123 --port=27017 --authenticationDatabase admin -d world -c city --type=csv --headerline /tmp/city1.csv
方法2(无列名)
# mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d world -c city --type=csv -f ID,Name,CountryCode,District,Population --file /tmp/city1.csv
6) 检查数据
# mongo --port 38017 admin
> use world
> db.city.find(); 7、案例2(world库下100张表,全部迁移到mongodb)
1) 思路
mysql> select * from world.city into outfile '/tmp/world_city.csv' fields terminated by ',';
使用infomation_schema.columns(导出字段),information_schema.tables(导出语句)
2) 批量导出字段
mysql> use information_schema
mysql> select table_name ,group_concat(column_name) from columns where table_schema='world' group by table_name;
3) 批量导出语句
mysql> use information_schema
mysql> select concat("select * from ",table_schema,".",table_name ," into outfile '/tmp/",table_schema,"_",table_name,".csv' fields terminated by ',';")
from information_schema.tables where table_schema ='world';
4) mysql导出csv
mysql> select * from test_info
into outfile '/tmp/test.csv'
fields terminated by ',' #字段间以,号分隔
optionally enclosed by '"' #字段用"号括起
escaped by '"' #字段中使用的转义符为"
lines terminated by '\r\n'; #行以\r\n结束
5) mysql导入csv
mysql> load data infile '/tmp/test.csv'
into table test_info
fields terminated by ','
optionally enclosed by '"'
escaped by '"'
lines terminated by '\r\n'; 8、mongodump和mongorestore基本使用
1) 介绍
能够在Mongodb运行时备份,工作原理是对运行的Mongodb做查询,然后将查到的结果写入磁盘,但备份不一定是数据库的实时快照,
如果备份时数据库有写入操作,备份的文件可能和数据库的数据不一致,备份时对其它客户端性能会产生的影响
2) mongodump参数说明
$ mongodump --help
-h: #数据库宿主机的IP
-u: #数据库的用户名
-p: #数据库的密码
-d: #数据库的名字
-c: #collection的名字
-o: #要导出的文件名
-q: #导出数据的过滤条件
-j, #并行
--oplog #同时备份oplog
3) 备份
全备
# mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -o /mongodb/backup
单库备份
# mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -d world -o /mongodb/backup/
单表备份
# mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log -o /mongodb/backup/
压缩备份
# mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -o /mongodb/backup/ --gzip
# mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -o /mongodb/backup/ | xargs tar -czf all.tar.gz
4) 恢复
恢复全备
# mongorestore -uroot -proot123 --port 27017 --authenticationDatabase admin /mongodb/backup/
# mongorestore -uroot -proot123 --port=27017 --authenticationDatabase admin /mongodb/backup/ --gzip
单库恢复
# mongorestore -uroot -proot123 --port 27017 --authenticationDatabase admin -d world1 /mongodb/backup/world
单表恢复
# mongorestore -uroot -proot123 --port 27017 --authenticationDatabase admin -d world -c t1 --gzip /mongodb/backup/oldboy/log1.bson.gz
恢复前drop库
# mongorestore -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy --drop /mongodb/backup/oldboy
5) bson二进制转换json恢复
备份出来的表文件有json和bson格式,json:表中的列信息,bson:源数据,bson二进制文件可以用命令查看或导出json格式的文件
# bsondump abc.bson > abc.json
# mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c abc abc.json 9、MongoDB集群备份和恢复
1) oplog介绍
oplog: 记录mongod实例一段时间内数据库的变更(插入/更新/删除)操作,replica set或master/slave模式专用
在replica set中oplog是一个定容集合(capped collection),默认大小是磁盘空间的5%(通过--oplogSizeMB参数修改)
位于local库的db.oplog.rs,当空间用完时会自动覆盖最老的记录
2) 查看oplog内容
> use local
> db.oplog.rs.find().pretty()
"ts" : Timestamp(1553597844, 1), #时间戳,1:时间内第几个操作
"op" : "n" #操作类型
"o" : #具体操作内容
op类型:"i":insert, "u":update, "d":delete, "c":db cmd(drop操作)
3) oplog大小规划
> rs.printReplicationInfo() #查看oplog时间窗口
configured oplog size: 2048MB #集合大小
log length start to end: 423849secs (117.74hrs) #预计窗口覆盖时间
oplog first event time: Wed Sep 09 2015 17:39:50 GMT+0800 (CST)
oplog last event time: Mon Sep 14 2015 15:23:59 GMT+0800 (CST)
now: Mon Sep 14 2015 16:37:30 GMT+0800 (CST)
方法1: 设置足够大的空间(但管理很麻烦)
方法2: 定期备份oplog.rs表
4) oplog备份和恢复
热备(--oplog:会记录备份过程中的数据变化,以oplog.bson保存)
# mongodump --port 28017 --oplog -o /mongodb/backup
恢复
# mongorestore --port 28017 --oplogReplay /mongodb/backup 10、案例
1) 背景
每天0点全备,oplog恢复窗口为48小时
某天,上午10点world.city 业务表被误删除
2) 恢复思路:
停应用,找测试库
恢复昨天晚上全备
截取全备之后到world.city误删除时间点的oplog,并恢复到测试库
将误删除表导出,恢复到生产库
3) 模拟原始数据
# mongo --port 28017
> use wo
> for(var i = 1 ;i < 20; i++) {db.ci.insert({a: i});}
4) 全备(将备份过程中产生的日志进行备份)
# mongodump --port 28017 --oplog -o /mongodb/backup
5) 插入新数据
> db.ci1.insert({id:1})
> db.ci2.insert({id:2})
6) 误删除数据
> db.ci.drop()
> show tables;
7) 备份oplog.rs表
# mongodump --port 28017 -d local -c oplog.rs -o /mongodb/backup
8) 获取oplog误删除时间点位置
$ mongo --port 28017
> use local
> db.oplog.rs.find({op:"c"}).pretty();
"ts" : Timestamp(1553659908, 1)
9) 恢复备份+应用oplog
# cp oplog.rs.bson /mongodb/backup/oplog.bson
# mongorestore --port 28018 --oplogReplay --oplogLimit "1553659908:1" --drop /mongodb/backup/ 11、分片集群的备份
1) 要备份什么
config server、shard 节点(单独进行备份)
2) 备份有什么困难和问题
chunk迁移的问题: 备份的时,避开迁移的时间窗口
shard节点之间的数据不在同一时间点: 选业务量较少的时候
3) 手工备份
停balancer
备份时,同一个时间点,把configserver和shard节点的从库,临时摘下来
备份完成后,再把从库加回去
学习 MongoDB(一)的更多相关文章
- 【MongoDB】学习MongoDB推荐三本书
近期学习mongodb,感觉这三本书写得不错.非常大家分享一下:
- 孤荷凌寒自学python第六十六天学习mongoDB的基本操作并进行简单封装5
孤荷凌寒自学python第六十六天学习mongoDB的基本操作并进行简单封装5并学习权限设置 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第十二天. 今天继续学习mongo ...
- 孤荷凌寒自学python第六十五天学习mongoDB的基本操作并进行简单封装4
孤荷凌寒自学python第六十五天学习mongoDB的基本操作并进行简单封装4 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第十一天. 今天继续学习mongoDB的简单操作 ...
- 孤荷凌寒自学python第六十四天学习mongoDB的基本操作并进行简单封装3
孤荷凌寒自学python第六十四天学习mongoDB的基本操作并进行简单封装3 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第十天. 今天继续学习mongoDB的简单操作, ...
- 孤荷凌寒自学python第六十三天学习mongoDB的基本操作并进行简单封装2
孤荷凌寒自学python第六十三天学习mongoDB的基本操作并进行简单封装2 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第九天. 今天继续学习mongoDB的简单操作, ...
- 孤荷凌寒自学python第六十二天学习mongoDB的基本操作并进行简单封装1
孤荷凌寒自学python第六十二天学习mongoDB的基本操作并进行简单封装1 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第八天. 今天开始学习mongoDB的简单操作, ...
- 学习mongoDB的一些感受(转自:http://blog.csdn.net/liusong0605/article/details/11581019)
曾经使用过mongoDB来保存文件,最一开始,只是想总结一下在开发中如何实现文件与mongoDB之间的交互.在此之前,并没有系统的了解过mongoDB,虽然知道我们用它来存储文件这些非结构化数据,但是 ...
- [aaronyang] nodejs学习-mongodb[1]
1.资源提供与安装(ayjs.net) 学习说明:nodejs还是在非windows环境下操作好,所以一切还是 当前时间:2014年12月06日aaronyang 官网地址:www.mongodb.o ...
- NoSQL学习——MongoDB
MongoDB作为一款文档数据库,支持分片存储,scale-out,集群自动切换,下面将粗略的配置步骤总结如下: 几个重要概念: 数据库:集合--记录--游标(查询时标记序号) sharding分片: ...
- 学习Mongodb(一)
图片摘录自陈彦铭出品2012.5的<10天掌握MongDB> MongoDB的特点--->面向集合存储,易于存储对象类型的数据--->模式自由--->支持动态查询---& ...
随机推荐
- 商城秒杀系统总结(Java)
本文写的较为零散,对没有基础的同学不太友好. 一.秒杀系统项目总结(基础版) classpath 在.properties中时常需要读取资源,定位文件地址时经常用到classpath 类路径指的是sr ...
- python学习笔记:1、读取文本文件,按行处理
需求源于 整理 时序报告.按照以前的思路 都是按行行的 进行处理 提取需要的信息,判断. 首先的操作应该是读取. python的读取 两个方法 (1) 通过readline()来进行读取 f = op ...
- PCL库在Linux环境下的编译安装
PCL库在Linux环境下的编译安装 PCL库的源码库:https://github.com/PointCloudLibrary/pcl 下载完了之后解压下来 编译库的几个步骤 mkdir build ...
- 《手把手教你》系列技巧篇(七十一)-java+ selenium自动化测试-自定义类解决元素同步问题(详解教程)
1.简介 前面宏哥介绍了几种关于时间等待的方法,也提到了,在实际自动化测试脚本开发过程,百分之90的报错是和元素因为时间不同步而发生报错.本文介绍如何新建一个自定义的类库来解决这个元素同步问题.这样, ...
- 微服务入门三:SpringCloud Alibaba
一.什么是SpringCloud Alibaba 1.简介 1)简介 阿里云未分布式应用开发提供了一站式解决方案.它包含了开发分布式应用程序所需的所有组件,使您可以轻松地使用springcloud开发 ...
- 『现学现忘』Docker基础 — 16、Docker中的基本概念和底层原理
目录 1.Docker的底层原理 2.Docker中常用的基本概念 3.run命令的运行流程 4.为什么Docker比VM快 Docker架构图: 我们依照Docker架构图进行Docker基础概念的 ...
- (数据科学学习手札134)pyjanitor:为pandas补充更多功能
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 pandas发展了如此多年,所包含的功能已 ...
- elasticsearch的安装与使用
1:官网进行下载 https://www.elastic.co/cn/elasticsearch/ 2:这里我用的是7.15.2 3:进行下载解压至d 盘 4:接下来我们cmd 切换目录进行运行 5: ...
- (acwing蓝桥杯c++AB组)1.2 递推
1.2 递推与递归 文章目录 1.2 递推与递归 位运算相关知识补充 pair与vector相关知识补充 题目目录与网址链接 下面的讲解主要针对这道题目的题解AcWing 116. 飞行员兄弟 - A ...
- Intellij IDEA远程debug线上项目记录
远程调试,特别是当你在本地开发的时候,你需要调试服务器上的程序时,远程调试就显得非常有用. JAVA 支持调试功能,本身提供了一个简单的调试工具JDB,支持设置断点及线程级的调试同时,不同的JVM通过 ...