10分钟go crawler colly从入门到精通
Introduction
本文对colly如何使用,整个代码架构设计,以及一些使用实例的收集。
Colly是Go语言开发的Crawler Framework,并不是一个完整的产品,Colly提供了类似于Python的同类产品(BeautifulSoup 或 Scrapy)相似的表现力和灵活性。
Colly这个名称源自 Collector 的简写,而Collector 也是 Colly的核心。
Colly Official Docs,内容不是很多,最新的消息也很就远了,仅仅是活跃在Github
Concepts
Architecture
从理解上来说,Colly的设计分为两层,核心层和解析层,
Collector:是Colly实现,该组件负责网络通信,并负责在Collector作业运行时执行对应事件的回调。Parser:这个其实是抽象的,官网并未对此说明,goquery和一些htmlquery,通过这些就可以将访问的结果解析成类Jquery对象,使html拥有了,XPath选择器和CSS选择器
通常情况下Crawler的工作流生命周期大致为
- 构建客户端
- 发送请求
- 获取响应的数据
- 将相应的数据解析
- 对所需数据处理
- 持久化
而Colly则是将这些概念进行封装,通过将事件注册到每个步骤中,通过事件的方式对数据进行清理,抽象来说,Colly面向的是过程而不是对象。大概的工作架构如图
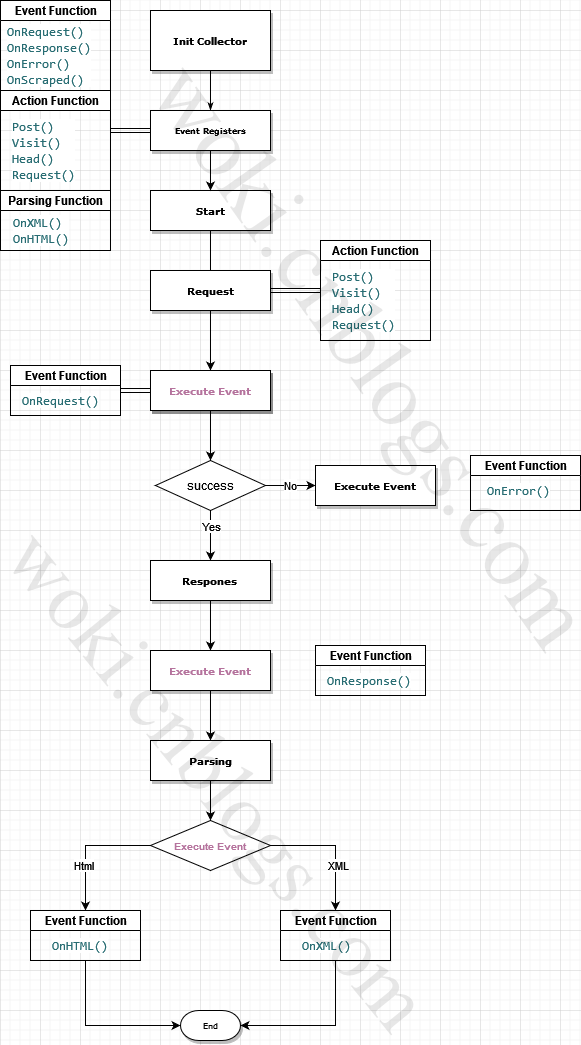
event
通过上述的概念,可以大概了解到 Colly 是一个基于事件的Crawler,通过开发者自行注册事件函数来触发整个流水线的工作
Colly 具有以下事件处理程序:
- OnRequest:在请求之前调用
- OnError :在请求期间发生错误时调用
- OnResponseHeaders :在收到响应头后调用
- OnResponse: 在收到响应后调用
- OnHTML:如果接收到的内容是 HTML,则在 OnResponse 之后立即调用
- OnXML :如果接收到的内容是 HTML 或 XML,则在 OnHTML 之后立即调用
- OnScraped:在 OnXML 回调之后调用
- OnHTMLDetach:取消注册一个OnHTML事件函数,取消后,如未执行过得事件将不会再被执行
- OnXMLDetach:取消注册一个OnXML事件函数,取消后,如未执行过得事件将不会再被执行
Reference
Utilities
简单使用
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// Instantiate default collector
c := colly.NewCollector(
// Visit only domains: hackerspaces.org, wiki.hackerspaces.org
colly.AllowedDomains("hackerspaces.org", "wiki.hackerspaces.org"),
)
// On every a element which has href attribute call callback
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
link := e.Attr("href")
// Print link
fmt.Printf("Link found: %q -> %s\n", e.Text, link)
// Visit link found on page
// Only those links are visited which are in AllowedDomains
c.Visit(e.Request.AbsoluteURL(link))
})
// Before making a request print "Visiting ..."
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL.String())
})
// Start scraping on https://hackerspaces.org
c.Visit("https://hackerspaces.org/")
}
错误处理
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// Create a collector
c := colly.NewCollector()
// Set HTML callback
// Won't be called if error occurs
c.OnHTML("*", func(e *colly.HTMLElement) {
fmt.Println(e)
})
// Set error handler
c.OnError(func(r *colly.Response, err error) {
fmt.Println("Request URL:", r.Request.URL, "failed with response:", r, "\nError:", err)
})
// Start scraping
c.Visit("https://definitely-not-a.website/")
}
处理本地文件
word.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document title</title>
</head>
<body>
<p>List of words</p>
<ul>
<li>dark</li>
<li>smart</li>
<li>war</li>
<li>cloud</li>
<li>park</li>
<li>cup</li>
<li>worm</li>
<li>water</li>
<li>rock</li>
<li>warm</li>
</ul>
<footer>footer for words</footer>
</body>
</html>
package main
import (
"fmt"
"net/http"
"github.com/gocolly/colly/v2"
)
func main() {
t := &http.Transport{}
t.RegisterProtocol("file", http.NewFileTransport(http.Dir(".")))
c := colly.NewCollector()
c.WithTransport(t)
words := []string{}
c.OnHTML("li", func(e *colly.HTMLElement) {
words = append(words, e.Text)
})
c.Visit("file://./words.html")
for _, p := range words {
fmt.Printf("%s\n", p)
}
}
使用代理交换器
通过 ProxySwitcher , 可以直接使用一批代理IP池进行访问了,然而这里只有RR,如果需要其他的均衡算法,需要有自己实现了
package main
import (
"bytes"
"log"
"github.com/gocolly/colly"
"github.com/gocolly/colly/proxy"
)
func main() {
// Instantiate default collector
c := colly.NewCollector(colly.AllowURLRevisit())
// Rotate two socks5 proxies
rp, err := proxy.RoundRobinProxySwitcher("socks5://127.0.0.1:1337", "socks5://127.0.0.1:1338")
if err != nil {
log.Fatal(err)
}
c.SetProxyFunc(rp)
// Print the response
c.OnResponse(func(r *colly.Response) {
log.Printf("Proxy Address: %s\n", r.Request.ProxyURL)
log.Printf("%s\n", bytes.Replace(r.Body, []byte("\n"), nil, -1))
})
// Fetch httpbin.org/ip five times
for i := 0; i < 5; i++ {
c.Visit("https://httpbin.org/ip")
}
}
随机延迟
该功能可以对行为设置一种特征,以免被反扒机器人检测,并禁止我们,如速率限制和延迟
package main
import (
"fmt"
"time"
"github.com/gocolly/colly"
"github.com/gocolly/colly/debug"
)
func main() {
url := "https://httpbin.org/delay/2"
// Instantiate default collector
c := colly.NewCollector(
// Attach a debugger to the collector
colly.Debugger(&debug.LogDebugger{}),
colly.Async(true),
)
// Limit the number of threads started by colly to two
// when visiting links which domains' matches "*httpbin.*" glob
c.Limit(&colly.LimitRule{
DomainGlob: "*httpbin.*",
Parallelism: 2,
RandomDelay: 5 * time.Second,
})
// Start scraping in four threads on https://httpbin.org/delay/2
for i := 0; i < 4; i++ {
c.Visit(fmt.Sprintf("%s?n=%d", url, i))
}
// Start scraping on https://httpbin.org/delay/2
c.Visit(url)
// Wait until threads are finished
c.Wait()
}
多线程请求队列
package main
import (
"fmt"
"github.com/gocolly/colly"
"github.com/gocolly/colly/queue"
)
func main() {
url := "https://httpbin.org/delay/1"
// Instantiate default collector
c := colly.NewCollector(colly.AllowURLRevisit())
// create a request queue with 2 consumer threads
q, _ := queue.New(
2, // Number of consumer threads
&queue.InMemoryQueueStorage{MaxSize: 10000}, // Use default queue storage
)
c.OnRequest(func(r *colly.Request) {
fmt.Println("visiting", r.URL)
if r.ID < 15 {
r2, err := r.New("GET", fmt.Sprintf("%s?x=%v", url, r.ID), nil)
if err == nil {
q.AddRequest(r2)
}
}
})
for i := 0; i < 5; i++ {
// Add URLs to the queue
q.AddURL(fmt.Sprintf("%s?n=%d", url, i))
}
// Consume URLs
q.Run(c)
}
异步
默认情况下,Colly的工作模式是同步的。可以使用 Async 函数启用异步模式。在异步模式下,我们需要调用Wait 等待Collector 工作完成。
package main
import (
"fmt"
"github.com/gocolly/colly/v2"
)
func main() {
urls := []string{
"http://webcode.me",
"https://example.com",
"http://httpbin.org",
"https://www.perl.org",
"https://www.php.net",
"https://www.python.org",
"https://code.visualstudio.com",
"https://clojure.org",
}
c := colly.NewCollector(
colly.Async(),
)
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println(e.Text)
})
for _, url := range urls {
c.Visit(url)
}
c.Wait()
}
最大深度
深度是在访问这个页面时,其页面还有link,此时需要采集到入口link几层的link?默认1
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// Instantiate default collector
c := colly.NewCollector(
// MaxDepth is 1, so only the links on the scraped page
// is visited, and no further links are followed
colly.MaxDepth(1),
)
// On every a element which has href attribute call callback
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
link := e.Attr("href")
// Print link
fmt.Println(link)
// Visit link found on page
e.Request.Visit(link)
})
// Start scraping on https://en.wikipedia.org
c.Visit("https://en.wikipedia.org/")
}
Reference
10分钟go crawler colly从入门到精通的更多相关文章
- 一起学react (1) 10分钟 让你dva从入门到精通
前言 如果文章中有错误的地方的话 可以直接加我QQ:469373256 自己针对一些问题做的优化版本 目前刚启动 还不是很成熟 https://github.com/fangkyi03/fastkit ...
- C# 10分钟完成百度人脸识别——入门篇
嗨咯,小编在此祝大家新年快乐财多多! 今天我们来盘一盘人脸注册.人脸识别等相关操作,这是一个简单入门教程. 话不多说,我们进入主题: 完成人脸识别所需的步骤: 注册百度账号api,创建自己的应用: 创 ...
- C# 10分钟完成百度图片提取文字(文字识别)——入门篇
现在图片文字识别已经很成熟了,比如qq长按图片,点击图片识别就可以识别图片的文字,将不认识的.文字数量大的.或者不能赋值的值进行二次可复制功能. 我们现在就基于百度Ai开放平台进行个人文字识别,dem ...
- C# 10分钟完成百度语音技术(语音识别与合成)——入门篇
我们已经讲了人脸识别(入门+进阶).图片识别(入门).下面是链接: C# 10分钟完成百度人脸识别——入门篇 C# 30分钟完成百度人脸识别——进阶篇(文末附源码) C# 10分钟完成百度图片提取文字 ...
- C# 10分钟完成百度翻译(机器翻译)——入门篇
我们之前基于百度ai开发平台实现了人脸识别 [1].文字识别 [2].语音识别 [3] 与合成的入门和进阶,今天我们来实现百度翻译的实现. 随着"一带一路"政策的开展,各种项目迎接 ...
- Apache Shiro系列三,概述 —— 10分钟入门
一.介绍 看完这个10分钟入门之后,你就知道如何在你的应用程序中引入和使用Shiro.以后你再在自己的应用程序中使用Shiro,也应该可以在10分钟内搞定. 二.概述 关于Shiro的废话就不多说了 ...
- JavaScript 10分钟入门
JavaScript 10分钟入门 随着公司内部技术分享(JS进阶)投票的失利,先译一篇不错的JS入门博文,方便不太了解JS的童鞋快速学习和掌握这门神奇的语言. 以下为译文,原文地址:http://w ...
- emacs最简单入门,只要10分钟
macs最简单入门,只要10分钟 windwiny @2013 无聊的时候又看到鼓吹emacs的文章,以前也有几次想尝试,结果都是玩不到10分钟就退出删除了. 这次硬着头皮,打开几篇文章都看完 ...
- 不用搭环境的10分钟AngularJS指令简易入门01(含例子)
不用搭环境的10分钟AngularJS指令简易入门01(含例子) `#不用搭环境系列AngularJS教程01,前端新手也可以轻松入坑~阅读本文大概需要10分钟~` AngularJS的指令是一大特色 ...
随机推荐
- POJ3368题解
题目大意:一个非降序序列,有若干查询,每次查询一个区间中重复次数最多的数字的个数. 思路:因为是非降序的,所以可以从头遍历把每个相同的数字划为一个块,用p[i]表示ai划分到了哪个块里面,同时还可以记 ...
- 哈工大 信息安全实验 XSS跨站脚本攻击原理与实践
XX大学XX学院 <网络攻击与防御> 实验报告 实验报告撰写要求 实验操作是教学过程中理论联系实际的重要环节,而实验报告的撰写又是知识系统化的吸收和升华过程,因此,实验报告应该体现完整性. ...
- C语言每日一题
66. 加一 /** * Note: The returned array must be malloced, assume caller calls free(). */ /* 从后向前(从个位)开 ...
- LeetCode-290-单词规律
单词规律 题目描述:给定一种规律 pattern 和一个字符串 str ,判断 str 是否遵循相同的规律. 这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 str 中的每个非 ...
- 数字逻辑实践6-> 从数字逻辑到计算机组成 | 逻辑元件总结与注意事项
00 一些前言 数字逻辑是计算机组成与体系结构的前导课,但是在两者的衔接之间并没有那么流畅,比如对面向硬件电路的设计思路缺乏.这篇总结是在数字逻辑和计组体系结构的衔接阶段进行的. 虽然这篇文是两门课的 ...
- laravel 5.6 API 接口开发限制接口访问频率
在laravel 5.6及以上版本中框架中已自带ThrottleRequests,但是为了更好的处理消息,我们可以再新加一个中间件,来更方便的处理相应信息 第一步: php artisan make: ...
- 初探JVM字节码
作者: LemonNan 原文地址: https://juejin.im/post/6885658003811827725 代码地址: https://github.com/LemonLmNan/By ...
- 08 Java的方法 方法的定义
2.方法的定义 Java的方法类似于其他语言的函数,是一段用来完成特定功能的代码片段,一般情况下,定义一个方法包含以下语法: **方法包含一个方法头和一个方法体.**下面是一个方法的所有部分: 修饰符 ...
- web自动化之selenium(三)文件上传
1.上传标签为input #若上传文件的标签为<input>可以直接定位标签,然后send_keys(文件路径)可以直接上传 2.利用第三方软件Autoit上传 1.下载Autoit:ht ...
- 七天接手react项目 系列 —— react 脚手架创建项目
其他章节请看: 七天接手react项目 系列 react 脚手架创建项目 前面我们一直通过 script 的方式学习 react 基础知识,而真实项目通常是基于脚手架进行开发. 本篇首先通过 reac ...