测试脚本配置、ORM必知必会13条、双下划线查询、一对多外键关系、多对多外键关系、多表查询
测试脚本配置
'''
当你只是想测试django中的某一个文件内容 那么你可以不用书写前后端交互的形式而是直接写一个测试脚本即可
脚本代码无论是写在应用下的test.py还是单独开设py文件都可以
'''
# 测试环境的准备 去manage.py中拷贝前四行代码到测试文件 然后自己写两行
import os
import sys
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")
import django
django.setup()
# 在这个代码块的下面就可以测试django里面的单个py文件了
************注意,新导入的模块也要在这个下面书写,不能放在最上面***************
必知必会13条
| 名字 | 作用 |
|---|---|
| all() | 查询所有数据 |
| filter() | 带有过滤条件的查询 |
| get() | 直接拿数据对象,取不到就报错 |
| first() | 取QuerySet里的第一个元素 |
| last() | 取QuerySet里的最后一个元素 |
| values() | 获取指定数据的字段(其他不要),结果为列表套字典 |
| values_list() | 获取指定数据的字段(其他不要),结果为列表套元组 |
| distinct() | 去重(必须一模一样,不能忽视主键和unique) |
| order_by() | 排序(默认升序,条件加减号就是降序) |
| reverse() | 反转(前提是数据已经排序过了) |
| count() | 统计个数 |
| exclude() | 排除在外 |
| exists() | 返回布尔值(存在Ture,不存在False) |
准备工作:
class User(models.Model):
name = models.CharField(max_length=32, verbose_name='姓名')
age = models.IntegerField(verbose_name='年龄')
register_time = models.DateField()
def __str__(self):
return self.name # 这样打印对象就会显示对应的名字
get()
obj = models.User.objects.get(pk=6) # 取出来的直接是数据对象 并且取不到就报错 所以一般还是用filter
first()、last()
obj = models.User.objects.all().first() # 取第一个
obj1 = models.User.objects.all().last() # 取最后一个
print(obj, obj1) # kevin oscar
values()
res = models.User.objects.values('name', 'age') # 只取某些字段(其他不要) 类似于select name,age from...
# 结果是列表字典
print(res) # <QuerySet [{'name': 'kevin', 'age': 16}, {'name': 'jason666', 'age': 55}]>
values_list()
res = models.User.objects.values_list('name', 'age') # 也是只取某些字段(其他不要)
# 结果是列表套元组
print(res) # <QuerySet [('kevin', 16), ('jason666', 55), ('tony', 44), ('oscar', 32)]>
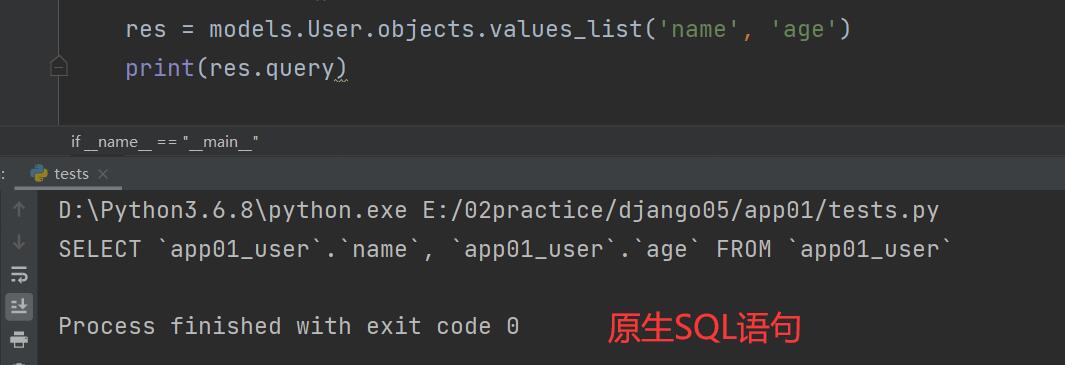
QuerySet对象
只要是QuerySet对象,就可以查看SQL语句
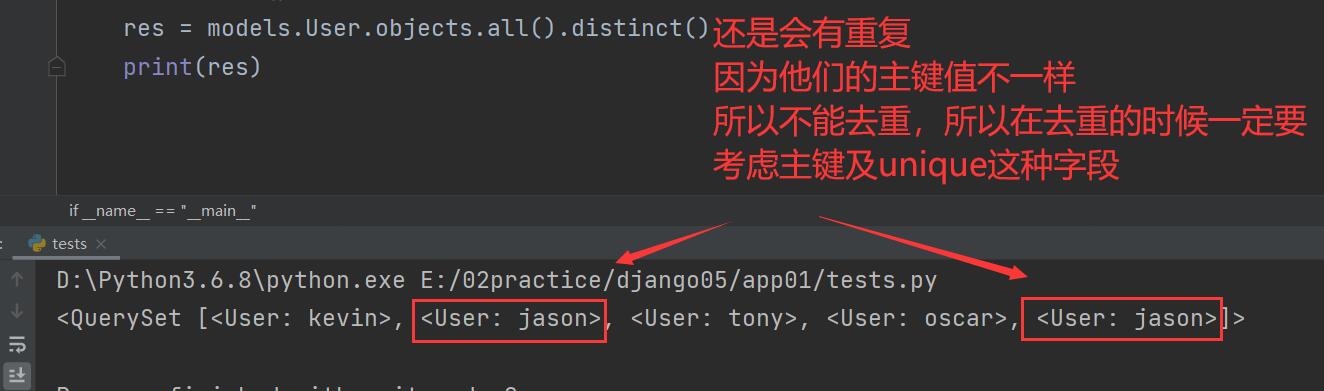
dictinct()
res = models.User.objects.all().distinct() # 去重失败
print(res)
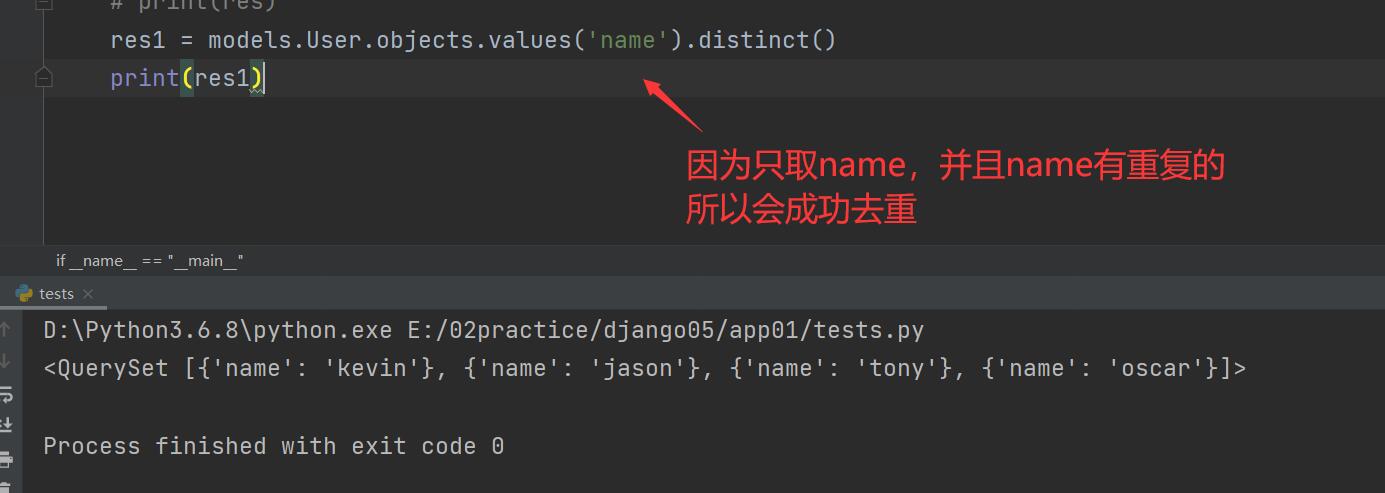
res1 = models.User.objects.values('name').distinct() # 去重成功
print(res1)
"""
去重一定要是一模一样的数据
如果带有主键那么肯定不一样 你在往后的查询中一定不要忽略主键
"""
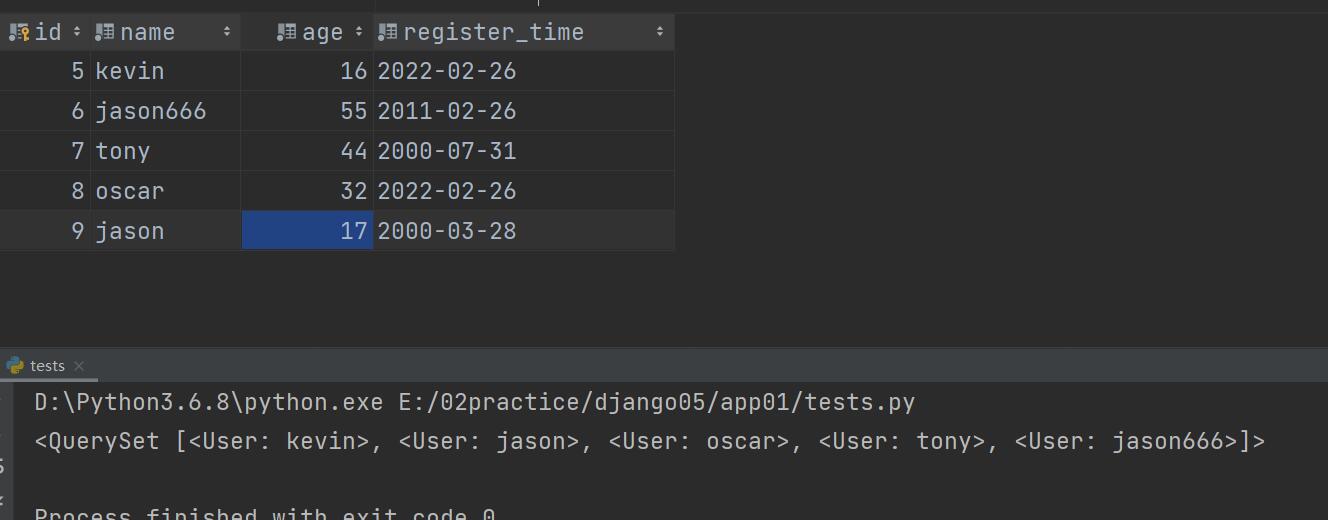
order_by()
升序
res = models.User.objects.order_by('age') # 排序(默认升序,条件加减号就是降序)
print(res)
降序
res = models.User.objects.order_by('-age') # 在字段前加 - 号就是降序
print(res)
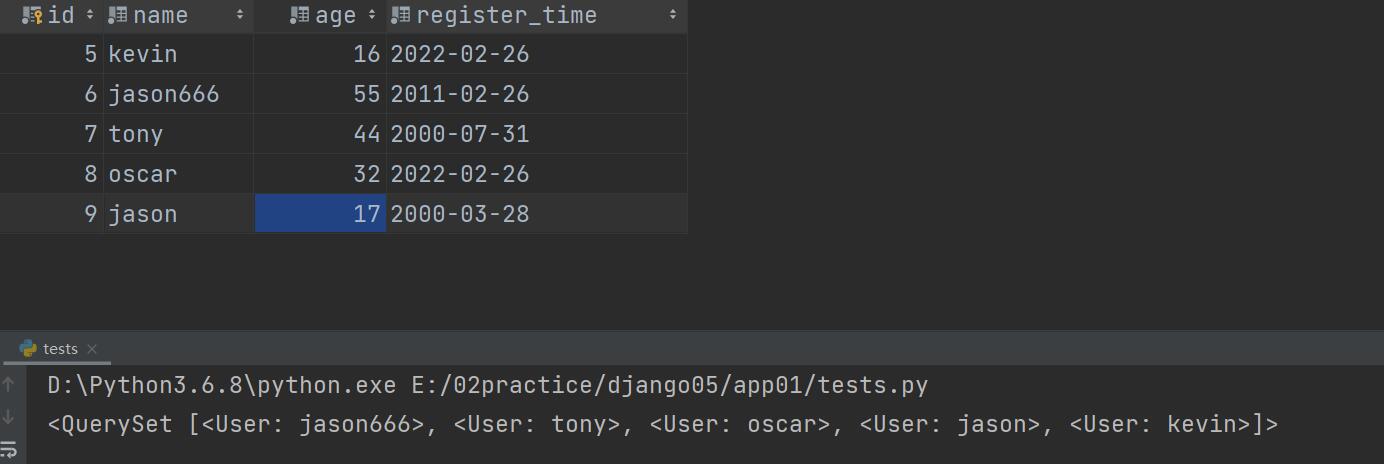
reverse()
res = models.User.objects.all()
res1 = models.User.objects.all().reverse() # 反转失败
res2 = models.User.objects.order_by('age').reverse() # 反转成功
print(res)
print(res1)
print(res2)
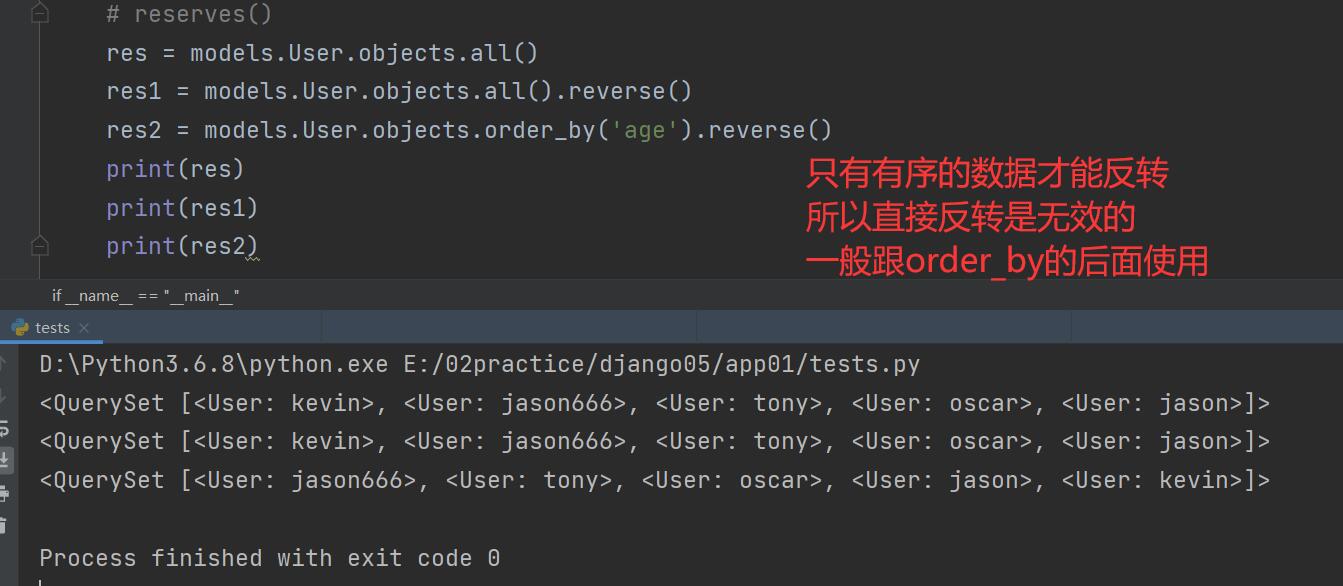
count()
res = models.User.objects.count()
print(res)
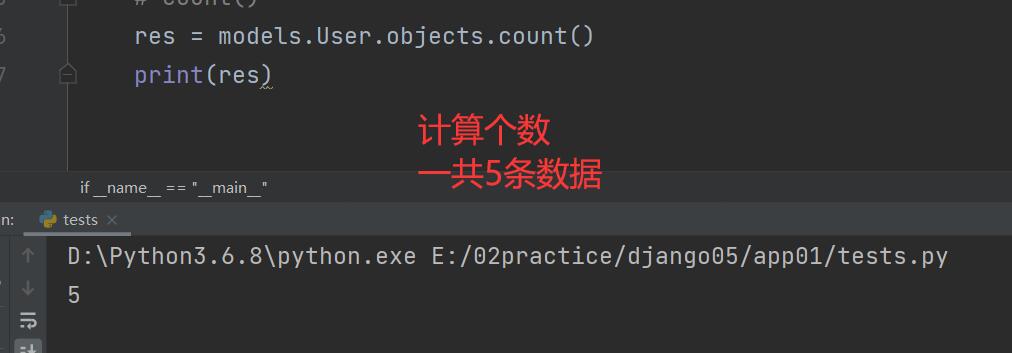
exclude()
res = models.User.objects.exclude(name='jason')
print(res)
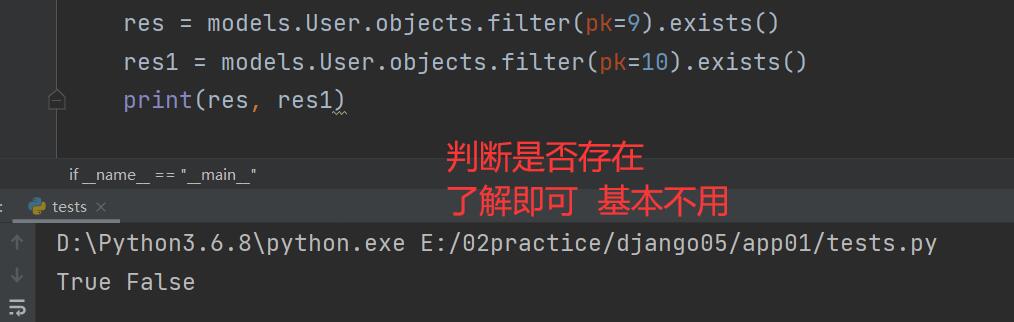
exists()
res = models.User.objects.filter(pk=9).exists()
res1 = models.User.objects.filter(pk=10).exists()
print(res, res1)
查看内部sql语句的方式
# 方式1
res = models.User.objects.values_list('name', 'age') # <QuerySet [('kevin', 16), ('jason666', 55), ('tony', 44), ('oscar', 32)]>
print(res.query) # SELECT `app01_user`.`name`, `app01_user`.`age` FROM `app01_user`
queryset对象才能够点击query查看内部的sql语句
# 方式2:所有的sql语句都能查看
# 去settings配置文件中配置一下即可 随便放在一个位置
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
神奇的双下划线查询
| 名字 | 意思 |
|---|---|
| 字段_ _gt=条件 | 查找字段的值大于指定条件 |
| 字段_ _lt=条件 | 查找字段的值小于指定条件 |
| 字段_ _gte=条件 | 查找字段的值大于等于指定条件 |
| 字段_ _lte=条件 | 查找字段的值小于等于指定条件 |
| 字段_ _in=条件 | 查找字段的值在指定条件内(相当于or) |
| 字段_ _range=条件 | 查找字段的值在指定条件内(顾头顾尾) |
| 字段_ _contains=条件 | 模糊查询(区分大小写) |
| 字段_ _icontains=条件 | 模糊查询(忽略大小写) |
| 字段_ _startswith=条件 | 查找开头与条件相符的 |
| 字段_ _endswith=条件 | 查找结尾与条件相符的 |
| 字段_ _month=条件 | 查找月份为指定值的数据 |
| 字段_ _year=条件 | 查找年份为指定值的数据 |
| 字段_ _day=条件 | 查找日期为指定值的数据 |
| 字段_ _week_day=条件 | 查找周几为指定值的数据(2-6 代表的是周一到周五,1--周天,7--周六) |
1.年龄大于32岁的数据
res = models.User.objects.filter(age__gt=32)
print(res)
# <QuerySet [<User: jason666>, <User: tony>]>
2.年龄大于等于32岁的数据
res = models.User.objects.filter(age__gte=32)
print(res)
# <QuerySet [<User: jason666>, <User: tony>, <User: oscar>]>
3.年龄小于32岁的数据
res = models.User.objects.filter(age__lt=32)
print(res)
# <QuerySet [<User: kevin>, <User: jason>]>
4.年龄小于等于32岁的数据
res = models.User.objects.filter(age__lte=32)
print(res)
# <QuerySet [<User: kevin>, <User: oscar>, <User: jason>]>
5.年龄是18或32或40
res = models.User.objects.filter(age__in=[16, 32, 40])
print(res)
# <QuerySet [<User: kevin>, <User: oscar>]>
6.年龄在18到44岁之间的
res = models.User.objects.filter(age__range=[18, 44])
print(res)
# <QuerySet [<User: tony>, <User: oscar>]>
7.查询出名字里含有s的数据
res = models.User.objects.filter(name__contains='s')
print(res)
# <QuerySet [<User: jason666>, <User: oscar>, <User: jason>]>
8.查询出名字里含有J或j的数据(忽略大小写)
res = models.User.objects.filter(name__icontains='J')
print(res)
# <QuerySet [<User: jason666>, <User: jason>]>
9.查询出名字以t开头的数据
res = models.User.objects.filter(name__startswith='t')
print(res)
# <QuerySet [<User: tony>]>
10.查询出名字以n结尾的数据
res = models.User.objects.filter(name__endswith='n')
print(res)
# <QuerySet [<User: kevin>, <User: jason>]>
11.查询注册时间是2月份的数据
res = models.User.objects.filter(register_time__month='2')
print(res)
# <QuerySet [<User: kevin>, <User: jason666>, <User: oscar>]>
12.查询注册时间是2011年的数据
res = models.User.objects.filter(register_time__year='2011')
print(res)
# <QuerySet [<User: jason666>]>
13.查询注册时间是26号的数据
res = models.User.objects.filter(register_time__day='26')
print(res)
# <QuerySet [<User: kevin>, <User: jason666>, <User: oscar>]>
14.查询注册时间是周三的数据 *********1表示星期天,7表示星期六, 2-6 代表的是星期一到星期五。**********
res = models.User.objects.filter(register_time__week_day='7')
print(res)
# <QuerySet [<User: kevin>, <User: jason666>, <User: oscar>]>
15.查询注册时间是2000年3月份的数据
res = models.User.objects.filter(register_time__year='2000', register_time__month='3')
print(res)
# <QuerySet [<User: jason>]>
一对多外键增删改查
增(绑定关系)
# 方式1:直接写
models.Book.objects.create(title='三国演义', price=123.66, publish_id=1)
# 方式2:虚拟字段传关联表对象
publish_obj = models.Publish.objects.filter(pk=2).first()
models.Book.objects.create(title='红楼梦', price=321.44, publish=publish_obj)
删(删除关系)
models.Publish.objects.filter(pk=1).delete() # 是级联删除的
改(修改关系)
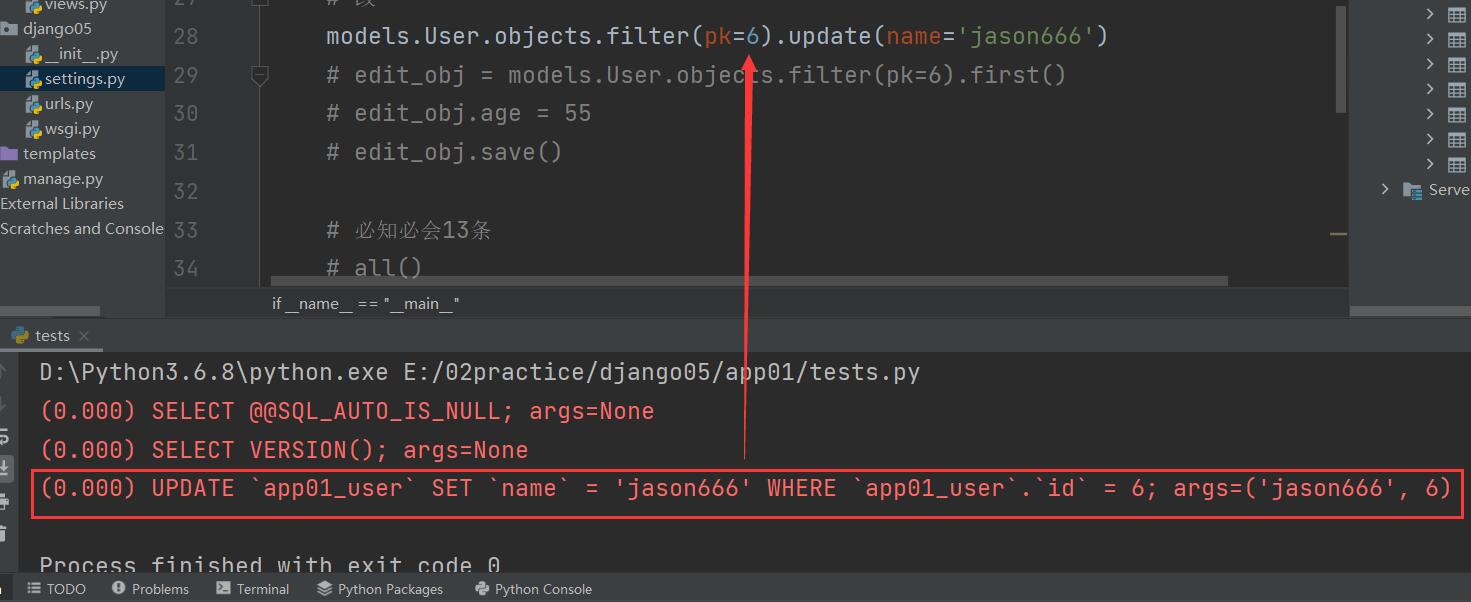
# 方式一:直接改
models.Book.objects.filter(pk=1).update(publish_id=2)
# 方式二:虚拟字段传关联表对象
publish_obj = models.Publish.objects.filter(pk=1).first()
models.Book.objects.filter(pk=1).update(publish=publish_obj) # 这里的publish是虚拟字段
多对多外键增删改查
原理: 因为多对多的关系是在第三张表里,而我们又不能直接去操作第三张表,所以这里ORM帮助我们进行更简单的操作,就是利用对象点多对多外键字段的方式进入第三张表,然后对其进行操作
增:add(绑定关系)
# 先拿到书籍对象
book_obj = models.Book.objects.filter(pk=2).first()
# book_obj.author这时候已经进入了第三张关系表 这时就可以任意操作了
# 方式一:直接写关联对象的主键
book_obj.author.add(1) # 给该书籍对象绑定主键为1的作者
book_obj.author.add(2, 3) # 因为是多对多 所以支持传多个
# 方式二:传关联表对象
author_obj1 = models.Author.objects.filter(pk=1).first()
author_obj2 = models.Author.objects.filter(pk=2).first()
author_obj3 = models.Author.objects.filter(pk=3).first()
book_obj.author.add(author_obj1)
book_obj.author.add(author_obj2, author_obj3) # 同样支持传多个参数
总结:
通过对象点多对多外键字段进入第三张表
然后用add添加关系 既支持写关联表的主键
也支持传被关联表对象 而且支持传多个参数
删:remove(删除关系)
# 先拿到书籍对象
book_obj = models.Book.objects.filter(pk=1).first()
# 方式一:直接写关联对象的主键
book_obj.author.remove(2)
book_obj.author.remove(1, 3) # 同样支持传多个参数
# 方式二:传关联表对象
author_obj1 = models.Author.objects.filter(pk=1).first()
author_obj2 = models.Author.objects.filter(pk=2).first()
author_obj3 = models.Author.objects.filter(pk=3).first()
book_obj.author.remove(author_obj1)
book_obj.author.remove(author_obj2, author_obj3) # 同样支持传多个参数
总结:
通过对象点多对多外键字段进入第三张表
然后用remove删除关系 既支持写关联表的主键
也支持传被关联表对象 而且支持传多个参数
改:set(修改关系):特殊
# 先拿到书籍对象
book_obj = models.Book.objects.filter(pk=1).first()
# 方式一:直接写关联对象的主键
book_obj.author.set([1, 3]) # 必须放个可迭代对象
book_obj.author.set([2])
book_obj.author.set([1,2,3])
# 方式二:传关联表对象
author_obj1 = models.Author.objects.filter(pk=1).first()
author_obj2 = models.Author.objects.filter(pk=2).first()
author_obj3 = models.Author.objects.filter(pk=3).first()
book_obj.author.set([author_obj2])
book_obj.author.set([author_obj1, author_obj3])
总结:
通过对象点多对多外键字段进入第三张表
然后用set修改关系(参数必须是可迭代对象)
**原先有的数据也要写 不写则会被删除 **
既支持写关联表的主键 也支持传被关联表对象
而且支持传多个参数
清空:clear(清空关系)
# 先拿到书籍对象
book_obj = models.Book.objects.filter(pk=1).first()
# 清空
book_obj.author.clear()
总结:
clear()里不加任何参数
正反向的概念(跨表查询必备知识)
正向
如果外键字段在我手上,那么我查你就是正向
eg:
book >>>外键字段在书那(正向)>>> publish
反向
如果外键字段不在我手上,那么我查你就是反向
eg:
publish >>>外键字段在书那(反向)>>> book
口诀
正向查询按外键字段
反向查询按表名小写
多表查询
子查询(基于对象的跨表查询)
结论:
正向查询
在查询结果可能有多个的时候要加all()
获得的是一个列表套对象
结果不可能为多个的时候不需要加all()
直接获取数据对象
1.查询书籍主键为1的出版社名称
book_obj = models.Book.objects.filter(pk=1).first()
publish_obj = book_obj.publish # 结果为出版社对象
print(publish_obj.name) # 东方出版社
2.查询书籍主键为2的作者姓名
book_obj = models.Book.objects.filter(pk=2).first()
author_obj = book_obj.author.all().first() # 出现app01.Author.None是因为没加all()
print(author_obj.name) # tank
3.查询作者jason的电话号码
author_obj = models.Author.objects.filter(name='jason').first()
author_detail_obj = author_obj.author_detail
print(author_detail_obj.phone) # 110
反向查询
在查询结果可能为多个的时候要加_set.all()
获得的是一个列表套对象
结果不可能为多个的时候不需要加_set.all()
直接获取数据对象
1.查询出版社是东方出版社出版的书
publish_obj = models.Publish.objects.filter(name='东方出版社').first()
book_obj = publish_obj.book_set.all() # 因为可能有多个 所以要加all()
print(book_obj) # <QuerySet [<Book: Book object>, <Book: Book object>, <Book: Book object>]>
2.查询作者是tank写过的书
author_obj = models.Author.objects.filter(name='tank').first()
book_obj = author_obj.book_set.all() # 因为可能有多个 所以要加all() 就算最后只有一个数据也要加_set.all()
print(book_obj) # <QuerySet [<Book: Book object>]>
3查询手机号是110的作者姓名
author_detail_obj = models.AuthorDetail.objects.filter(phone='110').first()
author_obj = author_detail_obj.author # 因为只可能是一个 所以不加_set.all()
print(author_obj) # Author object
联表查询(基于双下划线的跨表查询)
正向查询按字段
反向查询按表名小写
1.查询jason的手机号和作者年龄
# 正向
res = models.Author.objects.filter(name='jason').values('author_detail__phone', 'age')
print(res) # <QuerySet [{'author_detail__phone': 110, 'age': 18}]>
# 反向
res = models.AuthorDetail.objects.filter(author__name='jason').values('phone', 'author__age')
print(res) # <QuerySet [{'phone': 110, 'author__age': 18}]>
2.查询书籍主键为1的出版社名和书的名称
# 正向
res = models.Book.objects.filter(pk=1).values('publish__name', 'title')
print(res) # <QuerySet [{'publish__name': '东方出版社', 'title': '三国演义'}]>
# 反向
res = models.Publish.objects.filter(book__id=1).values('name', 'book__title')
print(res) # <QuerySet [{'name': '东方出版社', 'book__title': '三国演义'}]>
3.查询书籍主键为2的作者姓名
# 正向
res = models.Book.objects.filter(pk=2).values('author__name')
print(res) # <QuerySet [{'author__name': 'tank'}]>
# 反向
res = models.Author.objects.filter(book__id=2).values('name')
print(res) # <QuerySet [{'name': 'tank'}]>
4.查询书籍主键是2的作者的年龄
# 正向
res = models.Book.objects.filter(pk=2).values('author__age')
print(res) # <QuerySet [{'author__age': 50}]>
# 反向
res = models.Author.objects.filter(book__id=2).values('age')
print(res) # <QuerySet [{'age': 50}]>
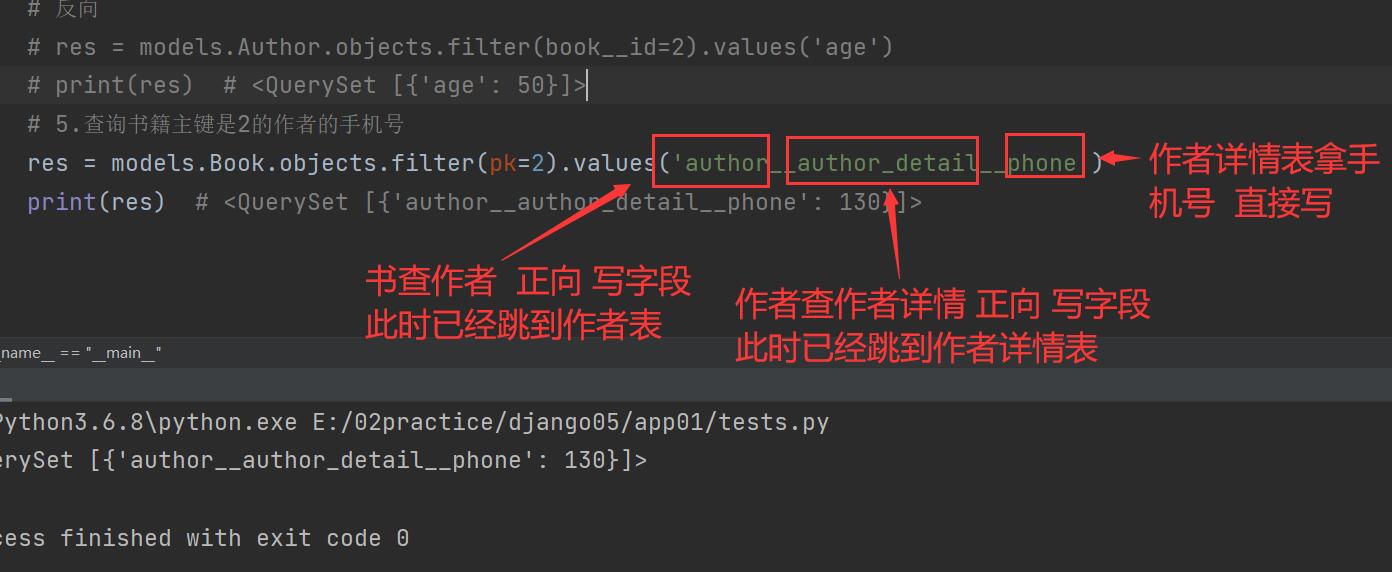
5.查询书籍主键是2的作者的手机号(涉及3张表)
res = models.Book.objects.filter(pk=2).values('author__author_detail__phone')
print(res) # <QuerySet [{'author__author_detail__phone': 130}]>
res = models.AuthorDetail.objects.filter(author__book__id=2).values('phone')
print(res)
测试脚本配置、ORM必知必会13条、双下划线查询、一对多外键关系、多对多外键关系、多表查询的更多相关文章
- Django ORM 操作 必知必会13条 单表查询
ORM 操作 必知必会13条 import os # if __name__ == '__main__': # 当前文件下执行 os.environ.setdefault('DJANGO_SETTIN ...
- Django框架之第六篇(模型层)--单表查询和必知必会13条、单表查询之双下划线、Django ORM常用字段和参数、关系字段
单表查询 补充一个知识点:在models.py建表是 create_time = models.DateField() 关键字参数: 1.auto_now:每次操作数据,都会自动刷新当前操作的时间 2 ...
- 13条必知必会&&测试
1.13条必知必会 <> all(): 查询所有结果 <> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <> get(**kwargs) ...
- 数据库学习之中的一个: 在 Oracle sql developer上执行SQL必知必会脚本
1 首先在開始菜单中打开sql developer: 2. 创建数据库连接 点击左上角的加号 在弹出的对话框中填写username和password 測试假设成功则点击连接,记得角色要写SYSDBA ...
- MySQL必知必会-官方数据库表及SQL脚本导入生成
最近在复习SQL语句,看的是MySQL必知必会这本书,但是发现附录中只有表设计,没有表的具体数据.所以在学习相应的语句中体验不是很好,去网上查了数据库的内容,自己慢慢导入到了数据库中.把表放出来作为参 ...
- django基础之day04,必知必会13条,双下划线查询,字段增删改查,对象的跨表查询,双下划线的跨表查询
from django.test import TestCase # Create your tests here. import os import sys if __name__ == " ...
- 《MySQL必知必会》整理
目录 第1章 了解数据库 1.1 数据库基础 1.1.1 什么是数据库 1.1.2 表 1.1.3 列和数据类型 1.1.4 行 1.1.5 主键 1.2 什么是SQL 第2章 MySQL简介 2.1 ...
- SQL 必知必会
本文介绍基本的 SQL 语句,包括查询.过滤.排序.分组.联结.视图.插入数据.创建操纵表等.入门系列,不足颇多,望诸君指点. 注意本文某些例子只能在特定的DBMS中实现(有的已标明,有的未标明),不 ...
- .NET程序员项目开发必知必会—Dev环境中的集成测试用例执行时上下文环境检查(实战)
Microsoft.NET 解决方案,项目开发必知必会. 从这篇文章开始我将分享一系列我认为在实际工作中很有必要的一些.NET项目开发的核心技术点,所以我称为必知必会.尽管这一系列是使用.NET/C# ...
随机推荐
- rodert教你学FFmpeg实战这一篇就够了
rodert教你学FFmpeg实战这一篇就够了 建议收藏,以备查阅 pdf阅读版: 链接:https://pan.baidu.com/s/11kIaq5V6A_pFX3yVoTUvzA 提取码:jav ...
- jdbc action 接口示例
package com.gylhaut.action; import java.sql.SQLException;import java.util.ArrayList;import java.util ...
- 空顺序表的实现(基于c语言)
书中对于创建一个空线性表的定义如下: struct SeqList{ int MAXNUM; // 顺序表中最大元素的个数(也就是最多多少个元素),(其实MAXNUM也可以定义在外面) int n; ...
- RISC / CISC
RISC(精简指令集计算机)和CISC(复杂指令集计算机)是当前CPU的两种架构.它们的区别在于不同的CPU设计理念和方法. CPU架构是厂商给属于同一系列的CPU产品定的一个规范,主要目的是为了区分 ...
- python写一个web目录扫描器
用到的模块urliib error #coding = utf-8 #web目录扫描器 by qianxiao996 #博客地址:https://blog.csdn.net/qq_36374896 i ...
- SpringMVC解决前端传来的中文字符乱码问题
以前乱码问题通过过滤器解决,而SpringMVC给我们提供了一个过滤器,可以在web.xml中添加以下配置 修改了xml文件需要重启服务器! <!--配置解决中文乱码过滤器--> < ...
- 迷宫问题,打印所有路径,深度搜索,dfs
#include<iostream> using namespace std; int maze [5][5] = { 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0 ...
- react单向数据流怎么理解?
React是单向数据流,数据主要从父节点传递到子节点(通过props).如果顶层(父级)的某个props改变了,React会重渲染所有的子节点.
- 两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对?
对. 因为equals()方法可以用开发者重写,hashCode()方法也可以由开发者来重写,因此它们是否相等并没有必然的关系. 如果对象要保存在HashSet或HashMap中,它们的equals( ...
- 什么是 Spring Boot?
Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手.