深度优先搜索 DFS 学习笔记
深度优先搜索 学习笔记
引入
深度优先搜索 DFS 是图论中最基础,最重要的算法之一。DFS 是一种盲目搜寻法,也就是在每个点 \(u\) 上,任选一条边 DFS,直到回溯到 \(u\) 时才选择别的边,如下图。
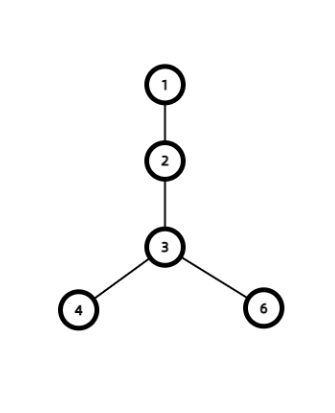
他的搜索顺序为 1-2-3-4-6。
递归实现指数型枚举
从 \(1\sim n\) 中这 \(n\) 个整数选取任意多个,输出所有可能的选择方案。
每一个数都有选与不选两种可能,相当于在每次递归上尝试选与不选两种分支,最后的时间复杂度即为 \(O(2^n)\)。
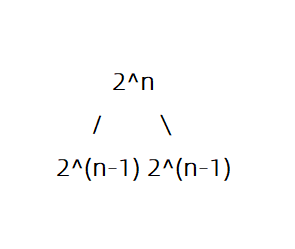
递归实现组合型枚举
组合型枚举的实现与指数型枚举的实现十分相近,只不过该问题是必须要在 \(n\) 个数中选取 \(m\) 个数,每个数还是有选、不选两条分支,所以实现直接在“指数型枚举”中加入两个剪枝即可:
- 若当前选择的数的个数大于 \(m\) 直接返回。
- 若当前选择的数的个数加上剩余的数的个数小于 \(m\) 则直接返回。
时间复杂度 \(O(2^n)\)。
递归实现排列型枚举
题目链接:题目详情 - 全排列问题 - ClorOJ (zshfoj.com)。
把每个可用的数作为数列中的下一个数,求解把剩余的 \(n-1\) 个数按照任意次序排列这个规模更小的子问题。
时间复杂度 \(O(n!)\)。
例题1 拔河比赛
题目链接:题目详情 - 拔河比赛 - ClorOJ (zshfoj.com)。
首先,由 (1) 可得,若 \(n\) 为奇数,则两边的人数仅相差 \(1\),否则若 \(n\) 为偶数,则两边人数相等。
考虑到条件 (1),显然我们可以只构造一个长度为 \(\left\lfloor\dfrac{n}{2}\right\rfloor\) 的组。
再考虑到条件 (2),显然两个组的体重之和 \(S\) 是固定的,肯定为 \(\sum\limits_{i=1}^{n}w_i\)。于是我们需要让这个长度为 \(\left\lfloor\dfrac{n}{2}\right\rfloor\) 的组的和尽量接近 \(\dfrac{s}{2}\)。
于是我们可以遍历每一个人,每个人要么选要么不选,即“指数型枚举”,在所有方法中找出最小的差值,即为答案。用一个三元组 \((x,y,z)\) 来描述状态,表示当前考虑到第 \(x\) 位成员,已经选择了 \(y\) 个人,体重和为 \(z\)。
代码:
#include<cstdio>
#include<cstring>
#include<cmath>
using namespace std;
int t,n,a[100100],b[100100],s=999999999,p;
inline int min(int x,int y){return x>y?y:x;}
inline void dfs(int k,int x,int u)
{
if(x>(n-x+1)) return;
if(abs(x-n+x)<2) s=min(s,abs(k));
for(int i=u+1;i<=n;i++)
{
if(b[i]<1)
{
b[i]=1;
dfs(k-2*a[i],x+1,i);
b[i]=0;
}
}
}
int main()
{
scanf("%d",&t);
while(t--)
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
p+=a[i];
}
dfs(p,0,0);
printf("%d\n",s);
for(int i=1;i<=n;i++) b[i]=0;
p=0;
s=999999999;
}
return 0;
}
剪枝
每次搜索可以看做从树根出发,遍历整棵树的过程。而所谓剪枝,即为通过某种判断,将不必要的遍历过程剪去。
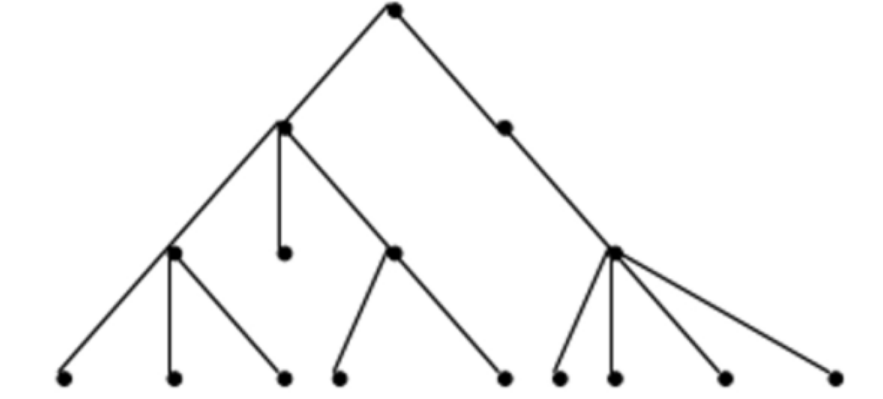
使用剪枝优化的核心问题是设计剪枝的判断方法,即确定哪些枝条应该舍去,哪些枝条应该保留。设计出好的剪枝判断方法往往能使得程序运行时间大幅度缩短,否则,也可能适得其反,因为判断也需要时间。
剪枝的原则
正确性
顾名思义,剪枝需要保证正确性,否则可能会遗漏掉更优的枝条。如果剪去了正确的答案,那么剩下的操作都毫无意义。所以正确性是剪枝的前提。
准确性
尽可能剪去多的不能通向正解的枝条。剪枝方法只有在具有了较高准确性的时候,才能真正的优化时间。
高效性
当设计好剪枝后,我们可能需要对搜索树的每个枝条都进行一次判断。然而,我们一般的剪枝是基于正解的“必要条件”进行判断,所以必然有很多非正解的枝条没有被剪枝。这些情况下的剪枝判断操作,对于程序效率的提高无疑是具有副作用的。所以如何平衡剪枝算法的准确性与高效性,往往是搜索算法优化的关键。
剪枝的技巧
优化搜索顺序
搜索数的各个层次,各个分支之间的顺序不是固定的,不同的搜索顺序会产生不同的搜索树。
排除等效冗余
如果沿着几条不同的分支能达到的子树是等效的,那么我们只需要对其中的一条分支进行搜索即可。
可行性剪枝
对当前状态进行检查,发现若分支无法到达正确答案的递归边界,则执行回溯。好比你在路上走,远远看到前方是死胡同,则直接折返绕路。在某些题目中也称“上下界剪枝”。
最优性剪枝
在最优化问题中,若当前花费的代价已经高于之前搜到的最优解,则直接返回,因为无法比之前搜到的最优解更优了。
记忆化
记录每个状态的搜索结果,在重复遍历一个状态时直接返回之前搜过的答案。此方法应用在 DFS 搜索为图的时候,如斐波那契数列。
例题2 数独游戏
Description
把 \(9\times 9\) 的数独补充完整,使得图中每行、每列、每个 \(3\times 3\) 的九宫格内数字 \(1\sim9\) 均恰好出现一次。
考虑 DFS。
Solution 1
找出一个还没有填的位置,检查 所有合法的数字。
搜索边界:1. 填满 \(9\times 9\) 的数独;2. 发现一个位置没有能填的合法数字。
可是这样的时间复杂度还是很大。
Solution 2
考虑优化搜索顺序,我们应该优先考虑“能填的合法数字”最少的位置。考虑这个位置上填什么数字。
此外,在每个状态上记录,检索,更新的开销。用位运算代替对数独各个位置所填的数字的记录,以及可填性的检查与统计。
- 对于每行、每列、每个九宫格,分别用一个 9 位二进制数保存哪些数字可以填。
- 若一行为
101100010,即 \(1,3,4,5,8\) 为不可以填写的,而 \(2,6,7,9\) 是可以填写的。 - 这里的位运算是可以自行选择的。
- 若一行为
- 可以做或运算,来判断某个数是否可以用。
- 当填写后,我们需要把九宫格更新。
Code
#include <iostream>
#include <cmath>
#include <cstring>
using namespace std;
int a[100][100], b[100][2], c[100], fx[10][10], fy[10][10], fg[10][10], n;
string s;
bool check(int x, int y, int t) //判断是否可填该数
{
if (fx[x][t] || fy[y][t] || fg[(x - 1) / 3 * 3 + (y - 1) / 3 + 1][t])
return false;
else //无重复,即可填,判重数组标记为一
{
fx[x][t] = 1;
fy[y][t] = 1;
fg[(x - 1) / 3 * 3 + (y - 1) / 3 + 1][t] = 1;
return true;
}
}
void back(int x, int y, int t) //回溯,还原信息
{
fx[x][t] = 0;
fy[y][t] = 0;
fg[(x - 1) / 3 * 3 + (y - 1) / 3 + 1][t] = 0;
}
bool dfs(int dep) {
if (dep > n) {
n = 0;
for (int i = 1; i <= 9; i++) {
for (int j = 1; j <= 9; j++) {
if (a[i][j])
cout << a[i][j];
else
cout << c[++n];
}
}
cout << endl;
return true; //返回真,以便快速退出
} else {
int x = b[dep][0], y = b[dep][1];
for (int i = 1; i <= 9; i++) {
if (check(x, y, i)) {
c[dep] = i; //另存空格填的数
if (dfs(dep + 1))
return true; //直接退出
back(x, y, i);
}
}
}
return false;
}
int main() {
getline(cin, s);
while (s != "end") {
for (int i = 0; i < 81; i++) {
int xt = i / 9, yt = i % 9;
if (s[i] == '.') {
a[xt + 1][yt + 1] = 0;
b[++n][0] = xt + 1, b[n][1] = yt + 1; //存下空格坐标
} else {
a[xt + 1][yt + 1] = s[i] - 48;
fx[xt + 1][s[i] - 48] = 1;
fy[yt + 1][s[i] - 48] = 1;
fg[(xt / 3 * 3 + yt / 3 + 1)][s[i] - 48] = 1;
}
}
dfs(1);
n = 0;
memset(fx, 0, sizeof(fx));
memset(fy, 0, sizeof(fy));
memset(fg, 0, sizeof(fg));
getline(cin, s);
}
}
例题3 虫食算
Description
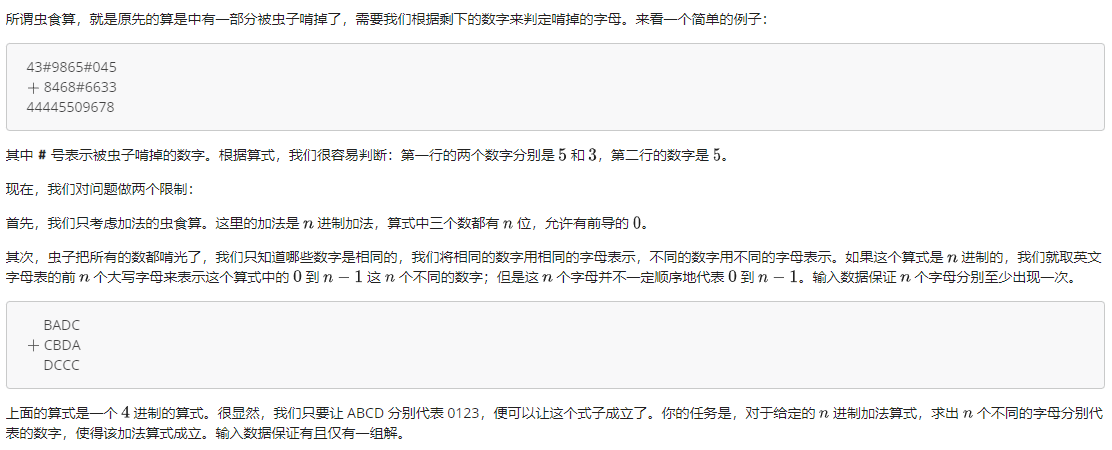
\(1\le n\le 26\).
Solution
考虑 DFS。很明显可以依次枚举每个字母代表什么数字,但 \(O(n!)\) 的复杂度很明显无法通过本题 \(n\le26\) 的数据。
如何剪枝?做加法竖式的时候要从右到左计算,考虑如何判断当前方案不合法。
- 从后往前枚举每一列,记当前的被加数、加数与和分别为 \(a,b,c\),进位为 \(t\),若出现 \(a+b+t\ne c\) 的情况则不合法。
- 若右边存在某个数尚未确定,那么上一位的 \(t\) 可能为 \(0,1\) 中的任意一个。这是若 \(a+b\ne c\) 且 \(a+b+1\ne c\),那么也是不合法。
- 对于最高位判断是否有进位,若有进位则根据题意,和也是一个 \(n\) 位数,不合法。
Code
#include <bits/stdc++.h>
#define N 55
using namespace std;
int n, ct;
int a[N], b[N];
char s[4][N];
void dfs(int x, int y, int t) {
if (ct == 1)
return;
if (y == -1) {
if (t == 0) {
for (int i = 0; i < n; ++i) printf("%d ", a[i]);
ct = 1;
}
return;
}
for (int i = y; i >= 0; --i) {
int a1 = a[s[1][i] - 'A'], a2 = a[s[2][i] - 'A'], a3 = a[s[3][i] - 'A'];
if (a1 == -1 || a2 == -1 || a3 == -1)
continue;
if ((a1 + a2) % n != a3 && (a1 + a2 + 1) % n != a3)
return;
}
if (a[s[x][y] - 'A'] < 0) {
for (int i = n - 1; i >= 0; --i) {
if (b[i] == 0) {
if (x != 3) {
a[s[x][y] - 'A'] = i;
b[i] = 1;
dfs(x + 1, y, t);
a[s[x][y] - 'A'] = -1;
b[i] = 0;
} else {
int sum = a[s[1][y] - 'A'] + a[s[2][y] - 'A'] + t;
if (sum % n != i)
continue;
b[i] = 1;
a[s[x][y] - 'A'] = i;
dfs(1, y - 1, sum / n);
b[i] = 0;
a[s[x][y] - 'A'] = -1;
}
}
}
return;
}
if (x != 3) {
dfs(x + 1, y, t);
} else {
int sum = a[s[1][y] - 'A'] + a[s[2][y] - 'A'] + t;
if (sum % n != a[s[3][y] - 'A'])
return;
dfs(1, y - 1, sum / n);
}
}
int main() {
scanf("%d", &n);
for (int i = 1; i <= 3; ++i) scanf("%s", s[i]);
memset(a, -1, sizeof(a));
dfs(1, n - 1, 0);
return 0;
}
总结
- 深搜其实还是非常好用的。
- 骗分。
- 其实深搜的功能远远不止骗分,请举一反三。
深度优先搜索 DFS 学习笔记的更多相关文章
- 初涉深度优先搜索--Java学习笔记(二)
版权声明: 本文由Faye_Zuo发布于http://www.cnblogs.com/zuofeiyi/, 本文可以被全部的转载或者部分使用,但请注明出处. 上周学习了数组和链表,有点基础了解以后,这 ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析(新手向)
深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每个点仅被访问一次,这个过程就是图的遍历.图的遍历常用的有深度优先搜索和广度优先搜索,这两者对于有向图和无向图 ...
- 利用广度优先搜索(BFS)与深度优先搜索(DFS)实现岛屿个数的问题(java)
需要说明一点,要成功运行本贴代码,需要重新复制我第一篇随笔<简单的循环队列>代码(版本有更新). 进入今天的主题. 今天这篇文章主要探讨广度优先搜索(BFS)结合队列和深度优先搜索(DFS ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析
转自:https://www.cnblogs.com/FZfangzheng/p/8529132.html 深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每 ...
- 【算法入门】深度优先搜索(DFS)
深度优先搜索(DFS) [算法入门] 1.前言深度优先搜索(缩写DFS)有点类似广度优先搜索,也是对一个连通图进行遍历的算法.它的思想是从一个顶点V0开始,沿着一条路一直走到底,如果发现不能到达目标解 ...
- 广度优先搜索 BFS 学习笔记
广度优先搜索 BFS 学习笔记 引入 广搜是图论中的基础算法之一,属于一种盲目搜寻方法. 广搜需要使用队列来实现,分以下几步: 将起点插入队尾: 取队首 \(u\),如果 $u\to v $ 有一条路 ...
- 平面上的地图搜索--Java学习笔记(四)
版权声明: 本文由Faye_Zuo发布于http://www.cnblogs.com/zuofeiyi/, 本文可以被全部的转载或者部分使用,但请注明出处. 这一个月以来,都在学习平面上的地图搜索,主 ...
- 用深度优先搜索(DFS)解决多数图论问题
前言 本文大概是作者对图论大部分内容的分析和总结吧,\(\text{OI}\)和语文能力有限,且部分说明和推导可能有错误和不足,希望能指出. 创作本文是为了提供彼此学习交流的机会,也算是作者在忙碌的中 ...
- 深度优先搜索(DFS)
[算法入门] 郭志伟@SYSU:raphealguo(at)qq.com 2012/05/12 1.前言 深度优先搜索(缩写DFS)有点类似广度优先搜索,也是对一个连通图进行遍历的算法.它的思想是从一 ...
随机推荐
- 还在担心CC攻击? 让我们来了解它, 并尽可能将其拒之服务之外.
还在担心CC攻击? 让我们来了解它, 并尽可能将其拒之服务之外. CC攻击是什么? 基本原理 CC原名为ChallengeCollapsar, 这种攻击通常是攻击者通过大量的代理机或者肉鸡给目标服务器 ...
- 正则-Java注释代码
今天写了个匹配java中常见的注释,记录一下,以备后用,使用条件将行两边的空格trim掉. (^\/\*.*)|(^\/\/.*)|(^\*.*)
- 详细描述一下 Elasticsearch 搜索的过程?
想了解 ES 搜索的底层原理,不再只关注业务层面了. 解答: 搜索拆解为"query then fetch" 两个阶段. query 阶段的目的:定位到位置,但不取. 步骤拆解如下 ...
- Dubbo 的整体架构设计有哪些分层?
接口服务层(Service):该层与业务逻辑相关,根据 provider 和 consumer 的 业务设计对应的接口和实现 配置层(Config):对外配置接口,以 ServiceConfig 和 ...
- vue集成webpack,遭遇 SyntaxError: Unknown word
这个错误根本和我的项目八竿子打不着,错误原因是配置了 css 的rule,将 这个rule注释掉,正常运行没有问题, 可是我却有强迫症,既然处理 node_modules 文件里才出现的错误,那么我就 ...
- C++模板学习之优先队列实现
转载:https://www.cnblogs.com/muzicangcang/p/10579250.html 今天将继续将强C++模板类的学习,同时为了巩固已经学习过的数据结构中有关优先队列的知识, ...
- 我们能自己写一个容器类,然后使用 for-each 循环码?
可以,你可以写一个自己的容器类.如果你想使用 Java 中增强的循环来遍历, 你只需要实现 Iterable 接口.如果你实现 Collection 接口,默认就具有该属性.
- java集合类框架的基本接口有哪些
集合类接口指定了一组叫做元素的对象.集合类接口的每一种具体的实现类都可以以他自己的方式对元素进行保存和排序.有的集合允许重复的键,有些不允许. java集合类里面最基本 的接口: Collection ...
- 运筹学之"概率"和"累计概率"和"谁随机数"
概率 = 2/50 = 0.2 累计概率 = 上个概率加本次概率 案例1 概率=销量天数 / 天数 = 2 /100 = 0.02 累计概率 = 上个概率加本次概率 = 0.02 +0.03 = 0. ...
- Thoughtworks Technology Radar #26 技术雷达26期
Thoughtworks Technology Radar #26 Techniques Adopt Four key metrics Google Cloud's DevOps Research a ...