520,用Python定制你的《本草纲目女孩》
摘要:让我们来用Python定制出心仪的“本草纲目女孩”,敲出魔性的代码舞蹈,520,准备好心仪女孩的舞蹈视频,把这份别出心裁的礼物给TA
本文分享自华为云社区《【云驻共创】华为云AI之用Python定制我的《本草纲目女孩》》,作者:愚公搬代码。
前言
近日,《本草纲目》毽子操的视频刷屏网络。公司里更是多了很多刘畊宏女孩,在520到来之际特意奉献这篇文章给大家。如果有心仪的女孩这篇文章可以帮助你哦。
歌词:抬腿!拍腿!,侧边的肥肉咔咔掉,人鱼线马甲线我都要!刘畊宏的男孩女孩看过来。
让我们来用Python定制出心仪的“本草纲目女孩”,敲出魔性的代码舞蹈,520,准备好心仪女孩的舞蹈视频,把这份别出心裁的礼物给TA️。
一、华为云ModelArts-Notebook介绍
1.华为云ModelArts-Notebook
ModelArts集成了基于开源的Jupyter Notebook和JupyterLab,可为您提供在线的交互式开发调试工具。您无需关注安装配置,在ModelArts管理控制台直接使用Notebook,编写和调测模型训练代码,然后基于该代码进行模型的训练。
其中,ModelArts还提供了华为自研的分布式训练加速框架MoXing,您可以在Notebook中使用MoXing编写训练脚本,让您代码编写更加高效、代码更加简洁。
1.1 Jupyter Notebook是什么
Jupyter Notebook是一个可以在浏览器中使用的交互式的计算应用程序,该应用程序的所有可见的内容,以笔记本文档表示,包括计算的输入和输出、解释文本、数学、图像和对象的富媒体等表示。因此,Jupyter Notebook可以实现将代码、文字完美结合起来,非常适合从事机器学习、数据分析等数据科学工作的人员。
Jupyter Notebook相关文档:https://docs.jupyter.org/en/latest/
1.2 JupyterLab是什么
JupyterLab是一个交互式的开发环境,是Jupyter Notebook的下一代产品,可以使用它编写Notebook、操作终端、编辑MarkDown文本、打开交互模式、查看csv文件及图片等功能。
JupyterLab相关文档:https://jupyterlab.readthedocs.io/en/stable/
1.3 什么是Moxing
MoXing是华为云ModelArts团队自研的分布式训练加速框架,它构建于开源的深度学习引擎TensorFlow、MXNet、PyTorch、Keras之上。相对于TensorFlow和MXNet原生API而言,MoXing API让模型代码的编写更加简单,允许用户只需要关心数据输入(input_fn)和模型构建(model_fn)的代码,即可实现任意模型在多GPU和分布式下的高性能运行,降低了TensorFlow和MXNet的使用门槛。另外,MoXing-TensorFlow还将支持自动超参选择和自动模型结构搜索,用户无需关心超参和模型结构,做到模型全自动学习。
Moxing相关文档:https://github.com/huaweicloud/ModelArts-Lab/tree/master/docs/moxing_api_doc
2.Python-Opencv
Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫做ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
Python解释器易于扩展,可以使用C语言或C++(或者其他可以通过C调用的语言)扩展新的功能和数据类型。Python也可用于可定制化软件中的扩展程序语言。Python丰富的标准库,提供了适用于各个主要系统平台的源码或机器码。
OpenCV用C++语言编写,它具有C++,Python,Java和MATLAB接口,并支持Windows,Linux,Android和Mac OS,OpenCV主要倾向于实时视觉应用,并在可用时利用MMX和SSE指令,如今也提供对于C#、Ch、Ruby,GO的支持。
opencv-python的github网址:https://pypi.org/project/opencv-python/
OpenCV官网:https://opencv.org/
二、本地案例实现Python定制我的《本草纲目女孩》
1.案例实现流程
众所周知,视频是由一帧帧图像构成,Opencv处理视频图像信息的原理就是将视频转为一帧帧图像,处理完图像后再转换为视频。
用Python实现案例流程如下:

2.案例环境部署
2.1 本机环境
- vs2022
- anaconda(已经包括opencv和PIL)
- python
2.2 安装对应的anaconda包
anaconda这是一个非常常用的python包集成管理工具,其中预安装了很多python库,使得我们不需要去手动安装各种的第三方库,我们知道自己取手动安装的过程中,很容易就会遇到一些报错,解决起来也非常的麻烦。
anaconda官网:https://www.anaconda.com/products/distribution#Downloads
下载完软件包一路点击安装就行了,安装成功后会出现如下界面。
查看是否安装成功命令:conda --version
2.3 安装opencv-python
进入anaconda控制台输入如下命令:
pip install opencv-python
3.案例实现代码
本案例的实现过程主要分为以下几步:
1. 导入数据
2. 导入库函数
3. 将视频转化为图像帧
4. 对图片帧进行ASCII码的转换
5. 将转换好的图片帧合成视频
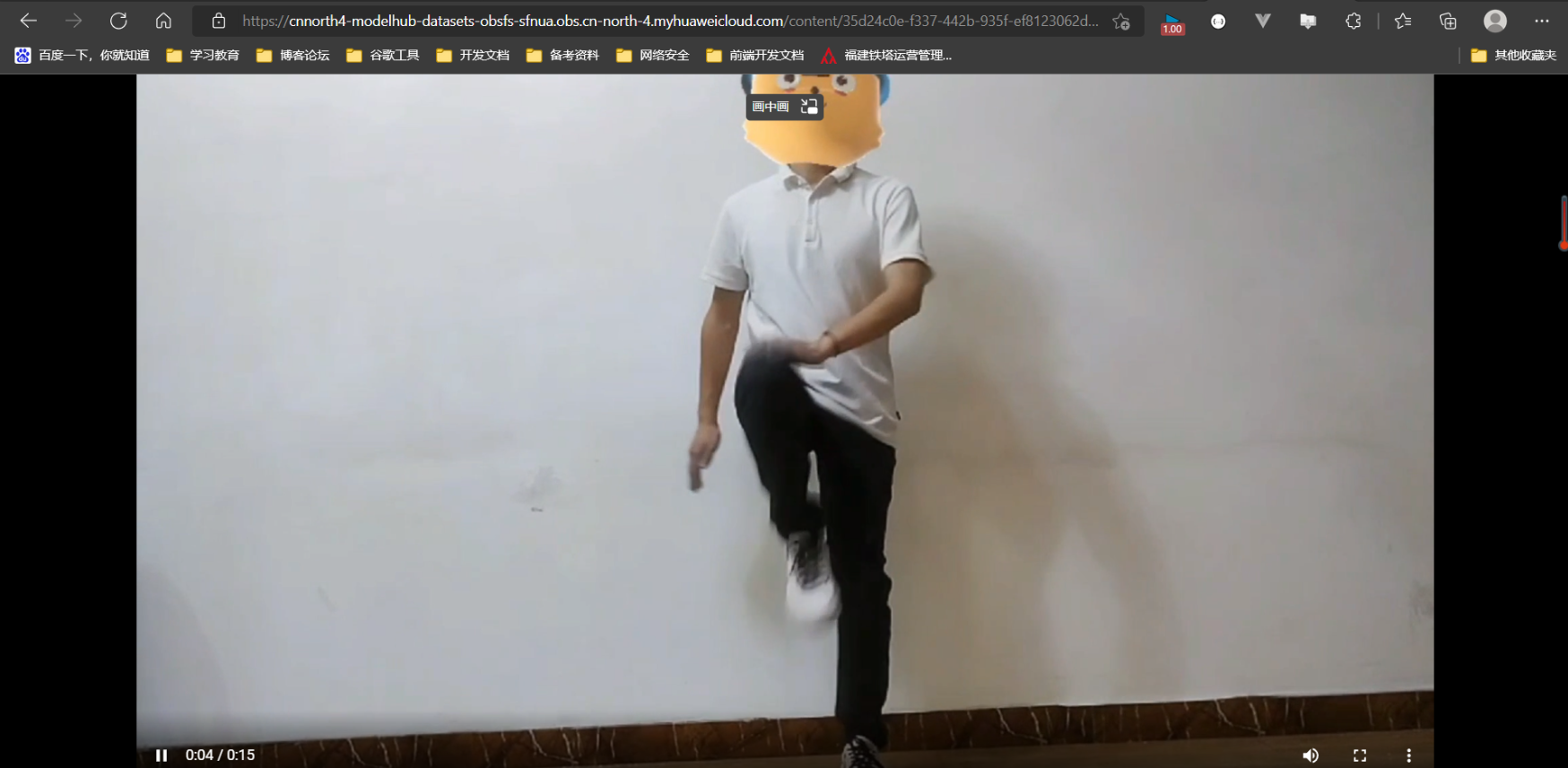
3.1 导入数据
3.2 导入库函数
#导入Python库
import cv2
from PIL import Image,ImageFont,ImageDraw
import os
from cv2 import VideoWriter, VideoWriter_fourcc, imread, resize
3.3 将视频转化为图像帧
#将视频转换为图片存入目标文件夹 def video_to_pic(vp):
number = 0 # 判断载入的视频是否可以打开
if vp.isOpened(): #r:布尔型 (True 或者False),代表有没有读取到图片,frame:表示截取到的一帧的图片的数据,是个三维数组
r,frame = vp.read() #判断文件夹是否存在,不存在的话则新建文件夹
if not os.path.exists('cache_pic'):
os.mkdir('cache_pic')
os.chdir('cache_pic') else:
r = False #遍历视频,并将每一帧图片写入文件夹
while r:
number += 1
cv2.imwrite(str(number)+'.jpg',frame)
r,frame = vp.read() print('\n由视频一共生成了{}张图片!'.format(number)) # 修改当前工作目录至主目录
os.chdir("..")
return number
3.4 对图片帧进行ASCII码的转换
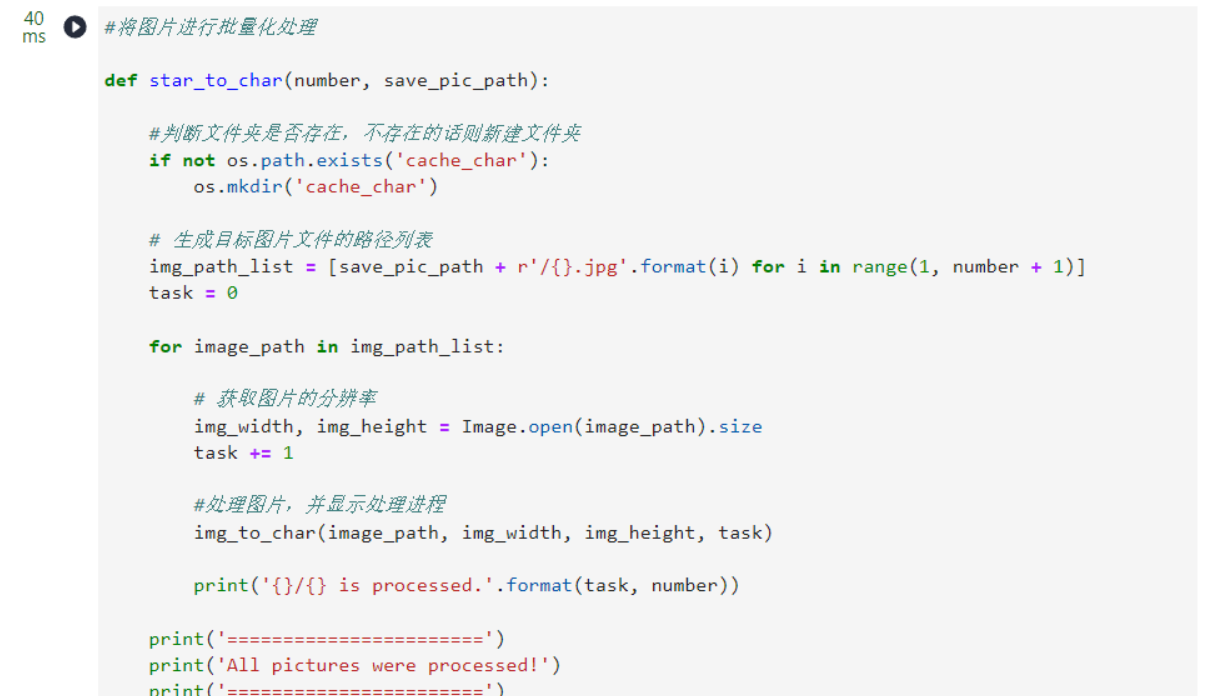
#将图片进行批量化处理
def star_to_char(number, save_pic_path):
#判断文件夹是否存在,不存在的话则新建文件夹
if not os.path.exists('cache_char'):
os.mkdir('cache_char')
# 生成目标图片文件的路径列表
img_path_list = [save_pic_path + r'/{}.jpg'.format(i) for i in range(1, number + 1)]
task = 0
for image_path in img_path_list:
# 获取图片的分辨率
img_width, img_height = Image.open(image_path).size
task += 1
#处理图片,并显示处理进程
img_to_char(image_path, img_width, img_height, task)
print('{}/{} is processed.'.format(task, number))
print('=======================')
print('All pictures were processed!')
print('=======================')
return 0
# 将图片转换为灰度图像后进行ascii_char中的ASCII值输出
# 函数输入像素RGBA值,输出对应的字符码。其原理是将字符均匀地分布在整个灰度范围内,像素灰度值落在哪个区间就对应哪个字符码。
def get_char(r, g, b, alpha=256):
#ascii_char就是字符列表,用来将不同灰度的像素进行不同字符体替换的参照。
ascii_char = list("#RMNHQODBWGPZ*@$C&98?32I1>!:-;. ")
#alpha在为0的时候便是完全透明的图片,所以返回空
if alpha == 0:
return ''
length = len(ascii_char)
#转为灰度图
#RGBA是代表Red(红色)、Green(绿色)、Blue(蓝色)和Alpha的色彩空间,Alpha通道一般用作不透明度参数
#如果一个像素的alpha通道数值为0%,那它就是完全透明的,而数值为100%则意味着一个完全不透明的像素
gray = int(0.2126 * r + 0.7152 * g + 0.0722 * b)
# unit = (256.0 + 1) / len(ascii_char)
unit = 256 / len(ascii_char)
return ascii_char[int(gray / unit)]
def img_to_char(image_path, raw_width, raw_height, task):
width = int(raw_width / 6)
height = int(raw_height / 15)
# 以RGB模式打开
im = Image.open(image_path).convert('RGB')
im = im.resize((width, height), Image.NEAREST)
txt = ''
color = []
#遍历图片的每个像素
for i in range(height):
for j in range(width):
pixel = im.getpixel((j, i))
# 将颜色加入进行索引
color.append((pixel[0], pixel[1], pixel[2]))
if len(pixel) == 4:
txt += get_char(pixel[0], pixel[1], pixel[2], pixel[3])
else:
txt += get_char(pixel[0], pixel[1], pixel[2])
txt += '\n'
color.append((255, 255, 255))
im_txt = Image.new("RGB", (raw_width, raw_height), (255, 255, 255))
dr = ImageDraw.Draw(im_txt)
font = ImageFont.load_default().font
x, y = 0, 0
font_w, font_h = font.getsize(txt[1])
font_h *= 1.37 # 调整字体大小
for i in range(len(txt)):
if (txt[i] == '\n'):
x += font_h
y = -font_w
dr.text((y, x), txt[i], fill=color[i])
y += font_w
#存储处理后的图片至文件夹
os.chdir('cache_char')
im_txt.save(str(task) + '.jpg')
#直接进入新创建的文件夹将生成的图片直接存入文件夹中
os.chdir("..")
return 0
3.5 将转换好的图片帧合成视频
# 进度条显示
def process_bar(percent, start_str='', end_str='', total_length=0):
bar = ''.join("■ " * int(percent * total_length)) + ''
bar = '\r' + start_str + bar.ljust(total_length) + ' {:0>4.1f}%|'.format(percent * 100) + end_str
print(bar, end='', flush=True) #图片帧合成视频 def jpg_to_video(char_image_path, FPS): # 设置视频编码器,这里使用MP42编码器
video_fourcc = VideoWriter_fourcc(*"MP42") # 生成目标字符图片文件的路径列表
char_img_path_list = [char_image_path + r'/{}.jpg'.format(i) for i in range(1, number + 1)] # 获取图片的分辨率
char_img_test = Image.open(char_img_path_list[1]).size
if not os.path.exists('video'):
os.mkdir('video')
video_writter = VideoWriter('video/output.avi', video_fourcc, FPS, char_img_test)
sum = len(char_img_path_list)
count = 0
for image_path in char_img_path_list:
img = cv2.imread(image_path)
video_writter.write(img)
end_str = '100%'
count = count + 1
process_bar(count / sum, start_str='', end_str=end_str, total_length=15) video_writter.release()
print('\n')
print('=======================')
print('The video is finished!')
print('=======================')
3.6 主函数
if __name__ == "__main__":
#初始视频路径
video_path = 'test_demo0510.mp4' #原始视频转为图片的图片保存路径
save_pic_path = 'cache_pic' #图片经处理后的图片保存路径
save_charpic_path = 'cache_char' # 读取视频
vp = cv2.VideoCapture(video_path) # 将视频转换为图片 并进行计数,返回总共生成了多少张图片
number = video_to_pic(vp) # 计算视频帧数
FPS = vp.get(cv2.CAP_PROP_FPS) # 将图像进行字符串处理后
star_to_char(number, save_pic_path) vp.release() # 将图片合成为视频
jpg_to_video(save_charpic_path, FPS)
3.7 运行结果
运行后一共生成了382张图片,和视频文件,保存在如下文件夹下。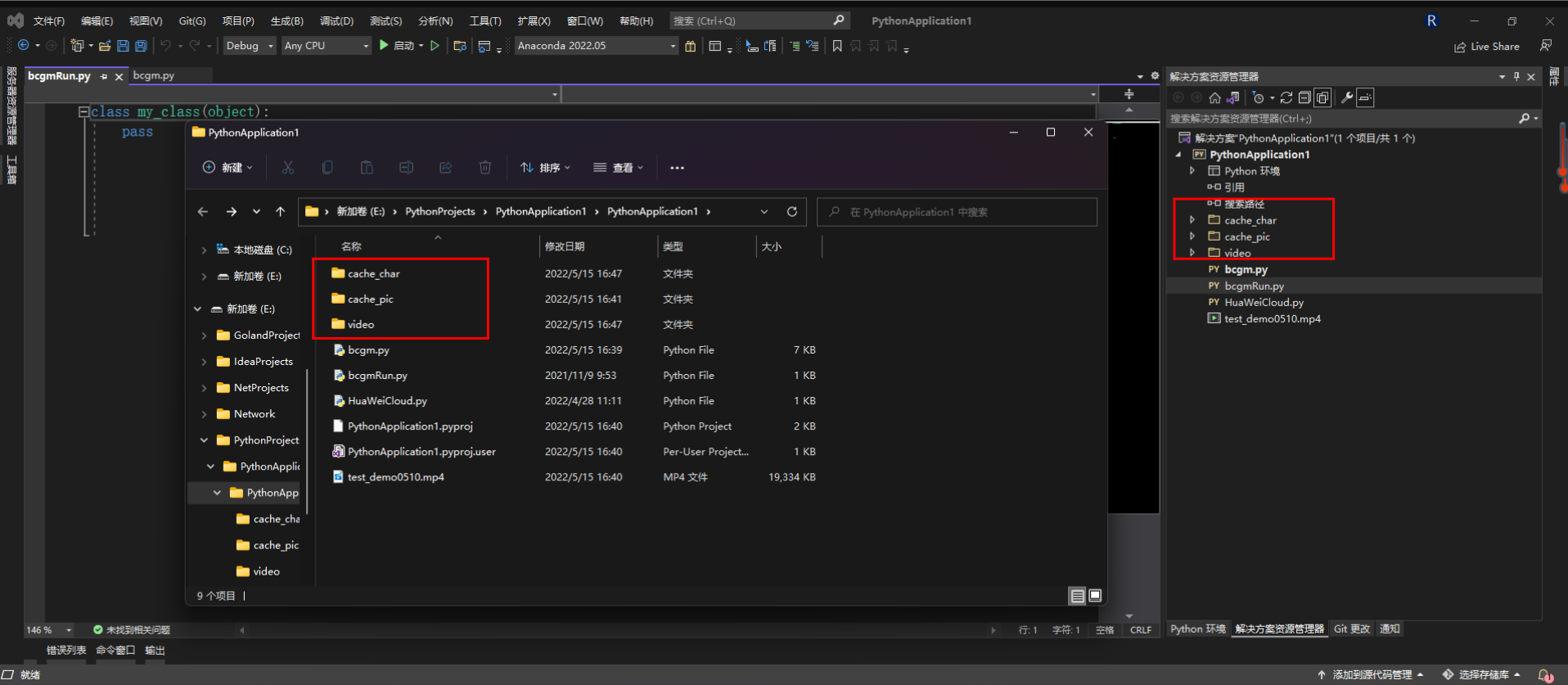
4.案例播放代码
import cv2
from IPython.display import clear_output, Image, display def show_video(video_path, show_text):
video = cv2.VideoCapture(video_path) while True:
try:
clear_output(wait=True)
# 读取视频
ret, frame = video.read()
if not ret:
break
height, width, _ = frame.shape
cv2.putText(frame, show_text, (0, 100), cv2.FONT_HERSHEY_TRIPLEX, 3.65, (255, 0, 0), 2)
frame = cv2.resize(frame, (int(width / 2), int(height / 2)))
_, ret = cv2.imencode('.jpg', frame) display(Image(data=ret)) except KeyboardInterrupt:
video.release() #视频循环播放
i=1
while i>0:
show_video('video/output.avi',str(i))
i=i+1

三、华为云AI实现Python定制我的《本草纲目女孩》
1.基础配置
"本草纲目"健身操字符串视频操作实例的案例页面如下:https://developer.huaweicloud.com/develop/aigallery/Notebook/detail?id=c81526e5-cc88-497f-8a21-41a5632e014e
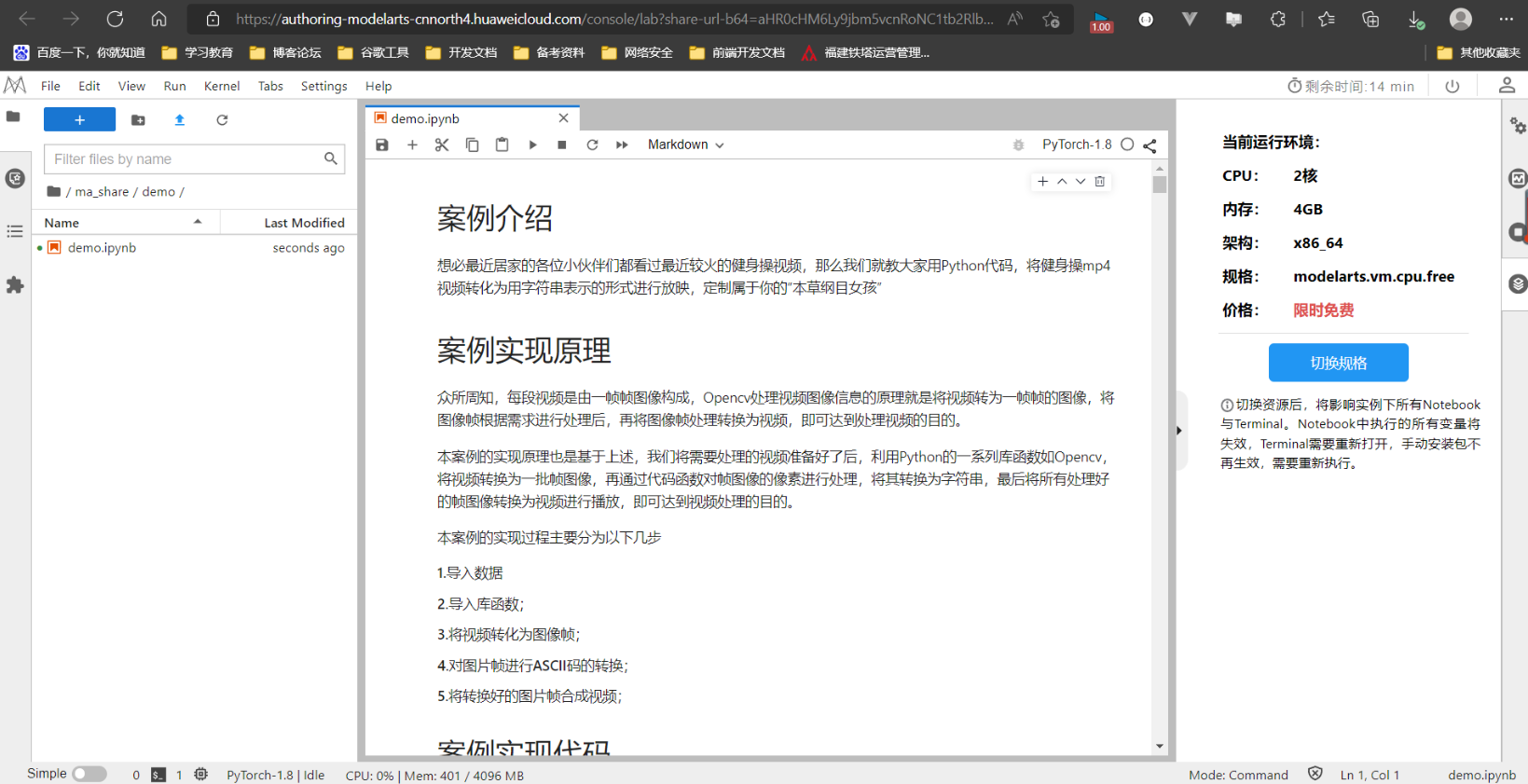
点击Run in ModelArts,进入JupyterLab页面。
配置当前运行环境,切换规格,并选择免费的就好了。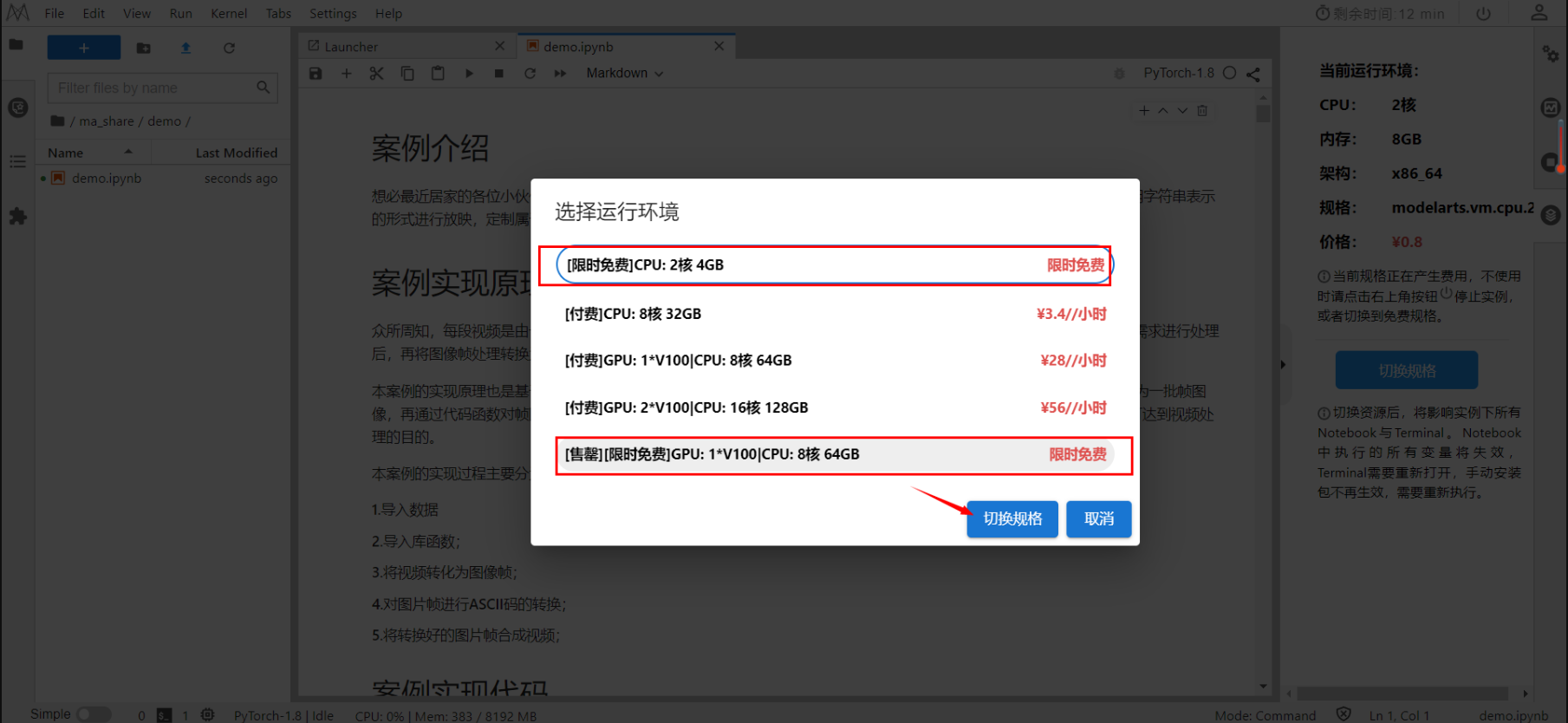
2.导入数据
选择下方代码,点击运行。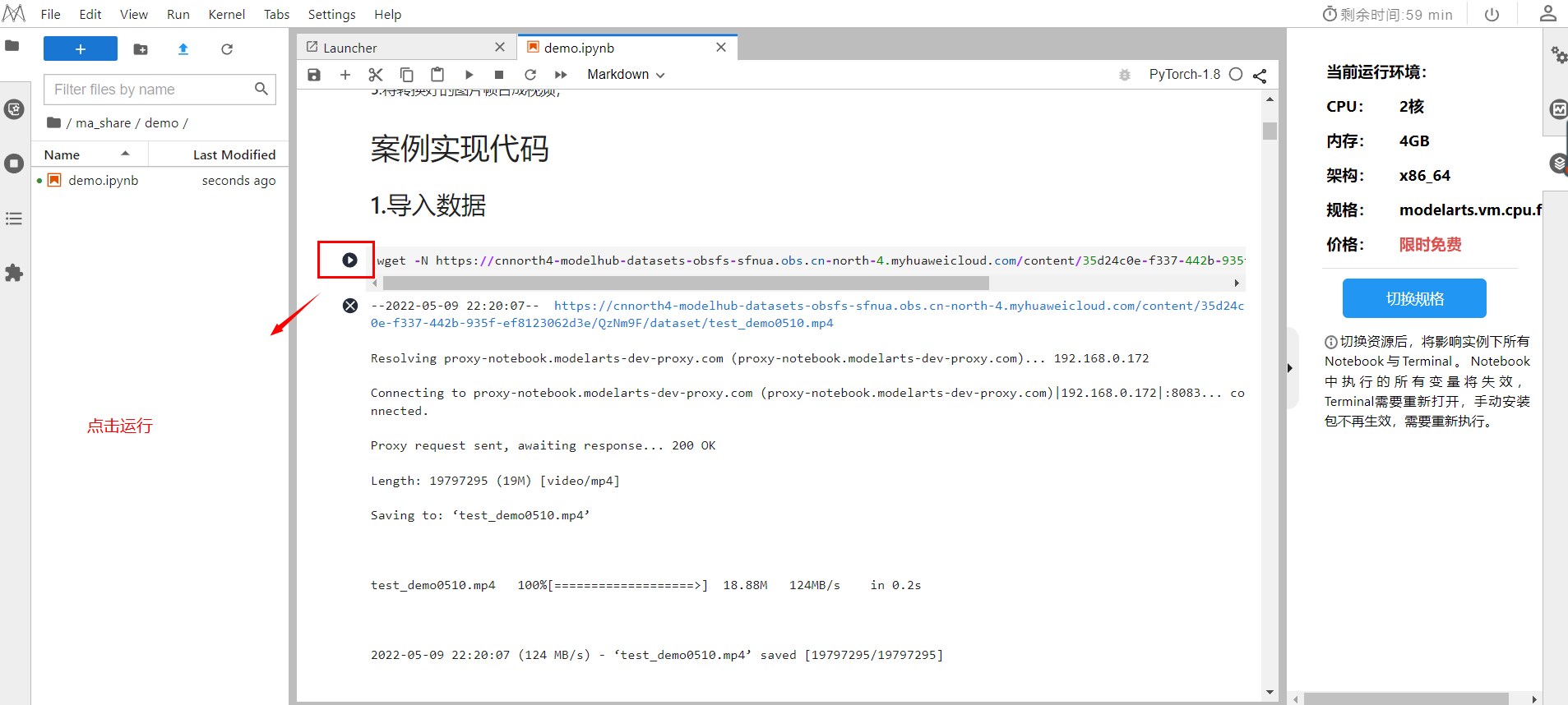
运行完成后如下: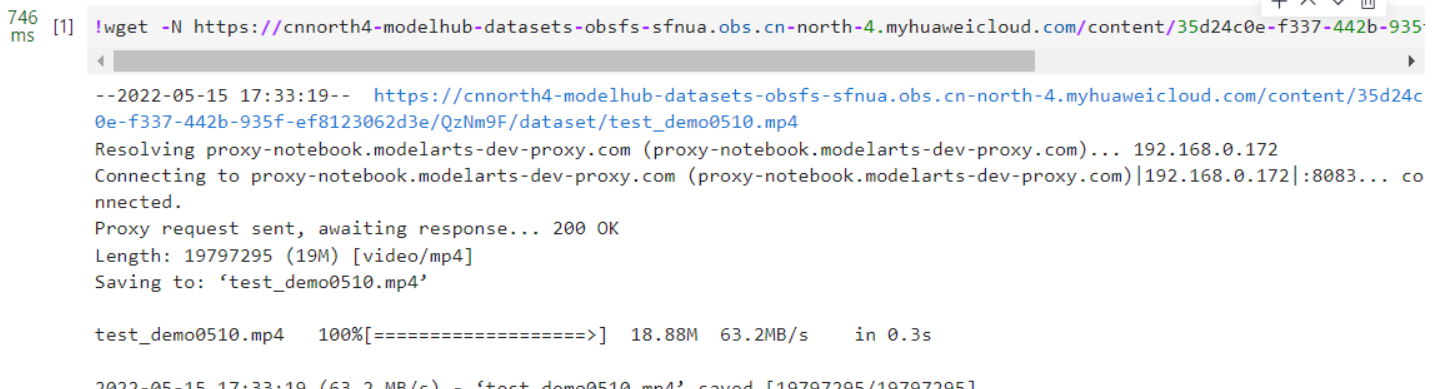
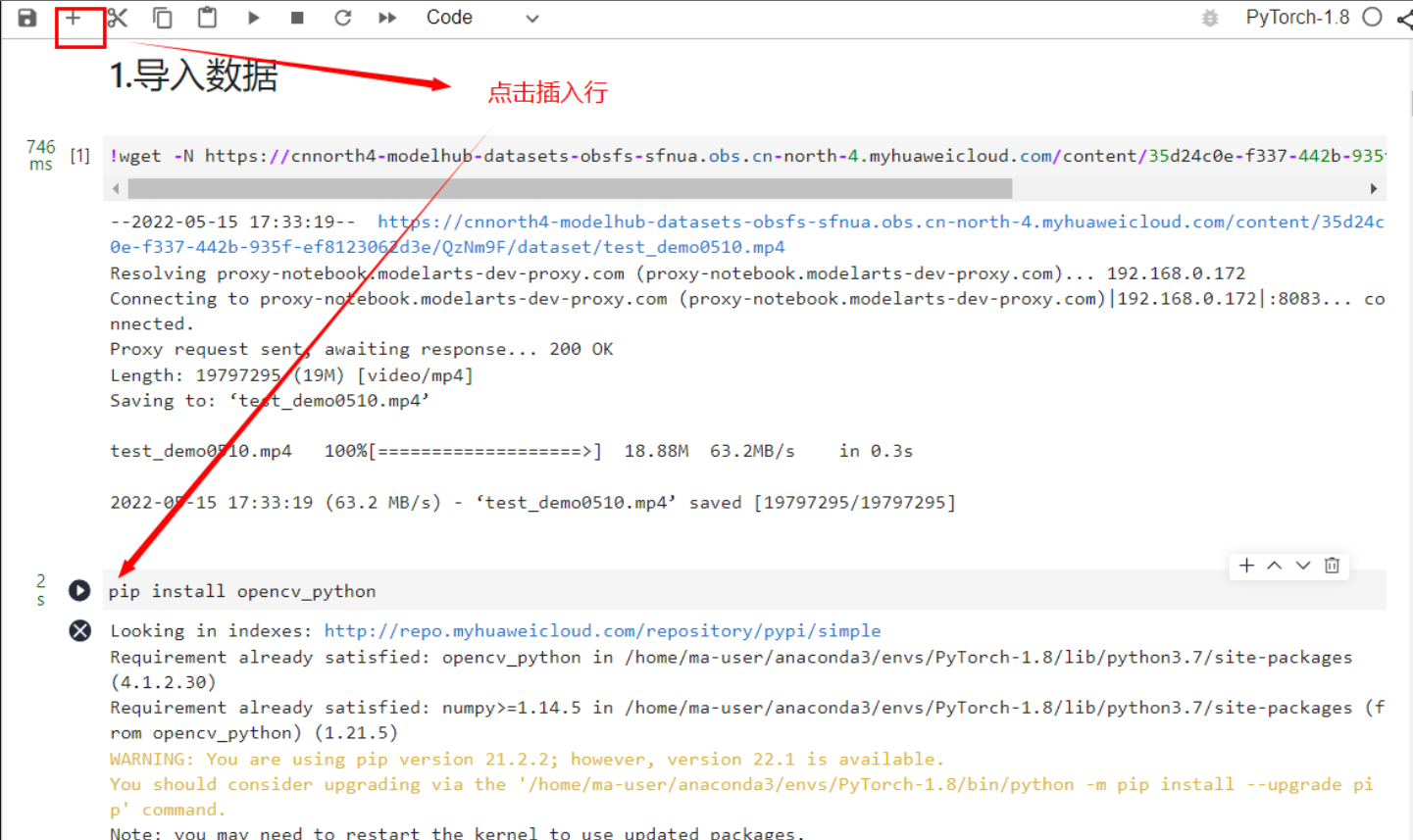
3.安装相关依赖
选择下方代码,点击运行安装opencv包
pip install opencv_python
4.导入库函数
#导入Python库
import cv2
from PIL import Image,ImageFont,ImageDraw
import os
from cv2 import VideoWriter, VideoWriter_fourcc, imread, resize

5.将视频转化为图像帧
#将视频转换为图片存入目标文件夹 def video_to_pic(vp):
number = 0 # 判断载入的视频是否可以打开
if vp.isOpened(): #r:布尔型 (True 或者False),代表有没有读取到图片,frame:表示截取到的一帧的图片的数据,是个三维数组
r,frame = vp.read() #判断文件夹是否存在,不存在的话则新建文件夹
if not os.path.exists('cache_pic'):
os.mkdir('cache_pic')
os.chdir('cache_pic') else:
r = False #遍历视频,并将每一帧图片写入文件夹
while r:
number += 1
cv2.imwrite(str(number)+'.jpg',frame)
r,frame = vp.read() print('\n由视频一共生成了{}张图片!'.format(number)) # 修改当前工作目录至主目录
os.chdir("..")
return number
6.对图片帧进行ASCII码的转换
#将图片进行批量化处理
def star_to_char(number, save_pic_path):
#判断文件夹是否存在,不存在的话则新建文件夹
if not os.path.exists('cache_char'):
os.mkdir('cache_char')
# 生成目标图片文件的路径列表
img_path_list = [save_pic_path + r'/{}.jpg'.format(i) for i in range(1, number + 1)]
task = 0
for image_path in img_path_list:
# 获取图片的分辨率
img_width, img_height = Image.open(image_path).size
task += 1
#处理图片,并显示处理进程
img_to_char(image_path, img_width, img_height, task)
print('{}/{} is processed.'.format(task, number))
print('=======================')
print('All pictures were processed!')
print('=======================')
return 0
# 将图片转换为灰度图像后进行ascii_char中的ASCII值输出
# 函数输入像素RGBA值,输出对应的字符码。其原理是将字符均匀地分布在整个灰度范围内,像素灰度值落在哪个区间就对应哪个字符码。
def get_char(r, g, b, alpha=256):
#ascii_char就是字符列表,用来将不同灰度的像素进行不同字符体替换的参照。
ascii_char = list("#RMNHQODBWGPZ*@$C&98?32I1>!:-;. ")
#alpha在为0的时候便是完全透明的图片,所以返回空
if alpha == 0:
return ''
length = len(ascii_char)
#转为灰度图
#RGBA是代表Red(红色)、Green(绿色)、Blue(蓝色)和Alpha的色彩空间,Alpha通道一般用作不透明度参数
#如果一个像素的alpha通道数值为0%,那它就是完全透明的,而数值为100%则意味着一个完全不透明的像素
gray = int(0.2126 * r + 0.7152 * g + 0.0722 * b)
# unit = (256.0 + 1) / len(ascii_char)
unit = 256 / len(ascii_char)
return ascii_char[int(gray / unit)]
def img_to_char(image_path, raw_width, raw_height, task):
width = int(raw_width / 6)
height = int(raw_height / 15)
# 以RGB模式打开
im = Image.open(image_path).convert('RGB')
im = im.resize((width, height), Image.NEAREST)
txt = ''
color = []
#遍历图片的每个像素
for i in range(height):
for j in range(width):
pixel = im.getpixel((j, i))
# 将颜色加入进行索引
color.append((pixel[0], pixel[1], pixel[2]))
if len(pixel) == 4:
txt += get_char(pixel[0], pixel[1], pixel[2], pixel[3])
else:
txt += get_char(pixel[0], pixel[1], pixel[2])
txt += '\n'
color.append((255, 255, 255))
im_txt = Image.new("RGB", (raw_width, raw_height), (255, 255, 255))
dr = ImageDraw.Draw(im_txt)
font = ImageFont.load_default().font
x, y = 0, 0
font_w, font_h = font.getsize(txt[1])
font_h *= 1.37 # 调整字体大小
for i in range(len(txt)):
if (txt[i] == '\n'):
x += font_h
y = -font_w
dr.text((y, x), txt[i], fill=color[i])
y += font_w
#存储处理后的图片至文件夹
os.chdir('cache_char')
im_txt.save(str(task) + '.jpg')
#直接进入新创建的文件夹将生成的图片直接存入文件夹中
os.chdir("..")
return 0
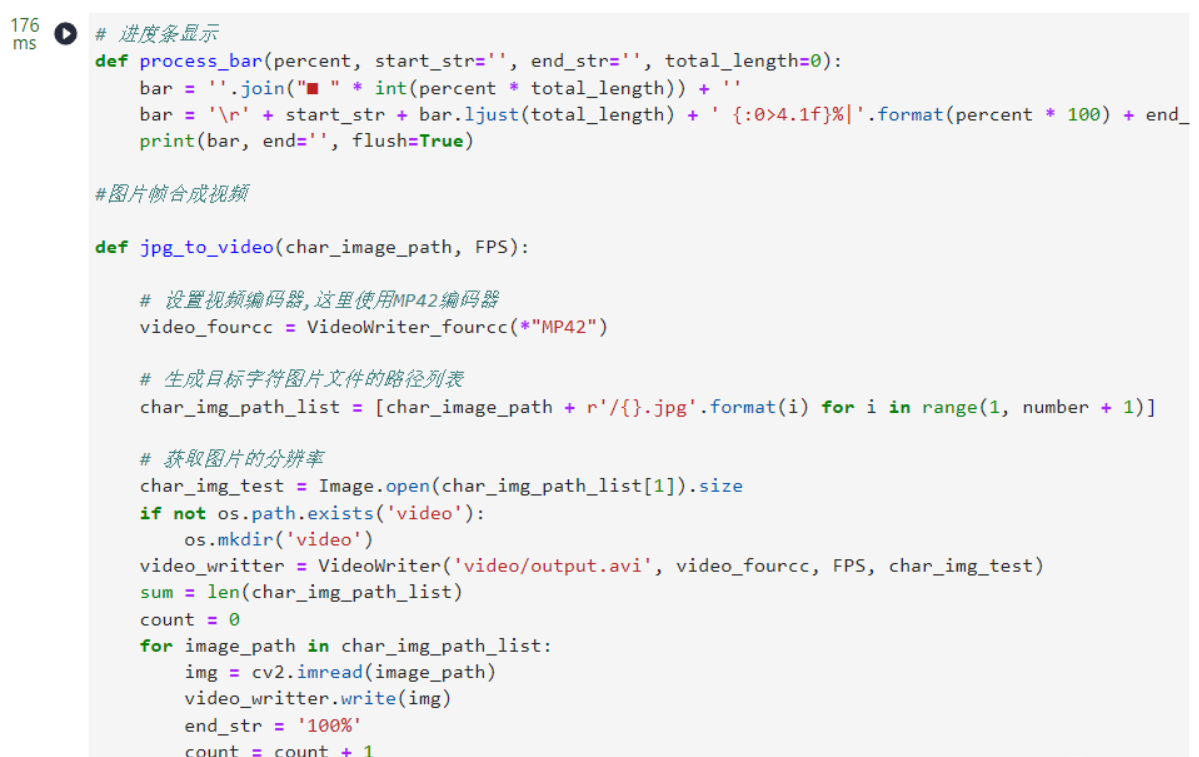
7.将转换好的图片帧合成视频
# 进度条显示
def process_bar(percent, start_str='', end_str='', total_length=0):
bar = ''.join("■ " * int(percent * total_length)) + ''
bar = '\r' + start_str + bar.ljust(total_length) + ' {:0>4.1f}%|'.format(percent * 100) + end_str
print(bar, end='', flush=True) #图片帧合成视频 def jpg_to_video(char_image_path, FPS): # 设置视频编码器,这里使用MP42编码器
video_fourcc = VideoWriter_fourcc(*"MP42") # 生成目标字符图片文件的路径列表
char_img_path_list = [char_image_path + r'/{}.jpg'.format(i) for i in range(1, number + 1)] # 获取图片的分辨率
char_img_test = Image.open(char_img_path_list[1]).size
if not os.path.exists('video'):
os.mkdir('video')
video_writter = VideoWriter('video/output.avi', video_fourcc, FPS, char_img_test)
sum = len(char_img_path_list)
count = 0
for image_path in char_img_path_list:
img = cv2.imread(image_path)
video_writter.write(img)
end_str = '100%'
count = count + 1
process_bar(count / sum, start_str='', end_str=end_str, total_length=15) video_writter.release()
print('\n')
print('=======================')
print('The video is finished!')
print('=======================')
8.运行主函数
if __name__ == "__main__":
#初始视频路径
video_path = 'test_demo0510.mp4' #原始视频转为图片的图片保存路径
save_pic_path = 'cache_pic' #图片经处理后的图片保存路径
save_charpic_path = 'cache_char' # 读取视频
vp = cv2.VideoCapture(video_path) # 将视频转换为图片 并进行计数,返回总共生成了多少张图片
number = video_to_pic(vp) # 计算视频帧数
FPS = vp.get(cv2.CAP_PROP_FPS) # 将图像进行字符串处理后
star_to_char(number, save_pic_path) vp.release() # 将图片合成为视频
jpg_to_video(save_charpic_path, FPS)
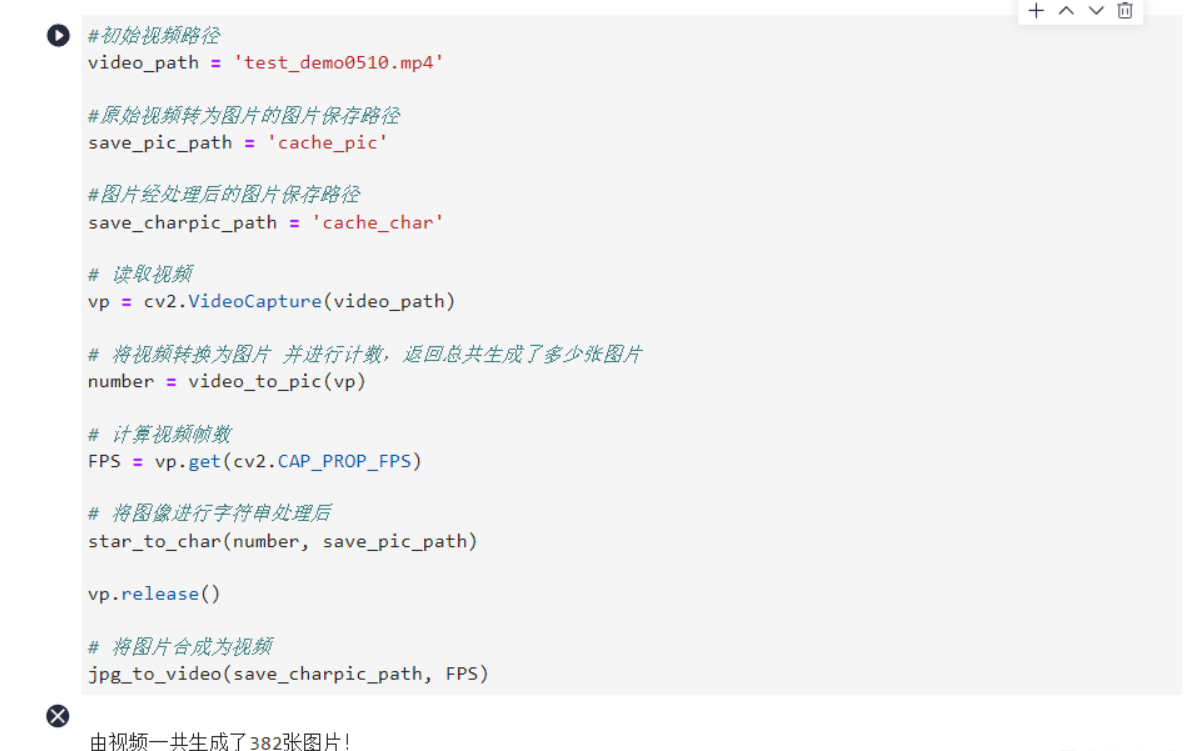
等待主函数执行完成,后会生成如下三个文件夹: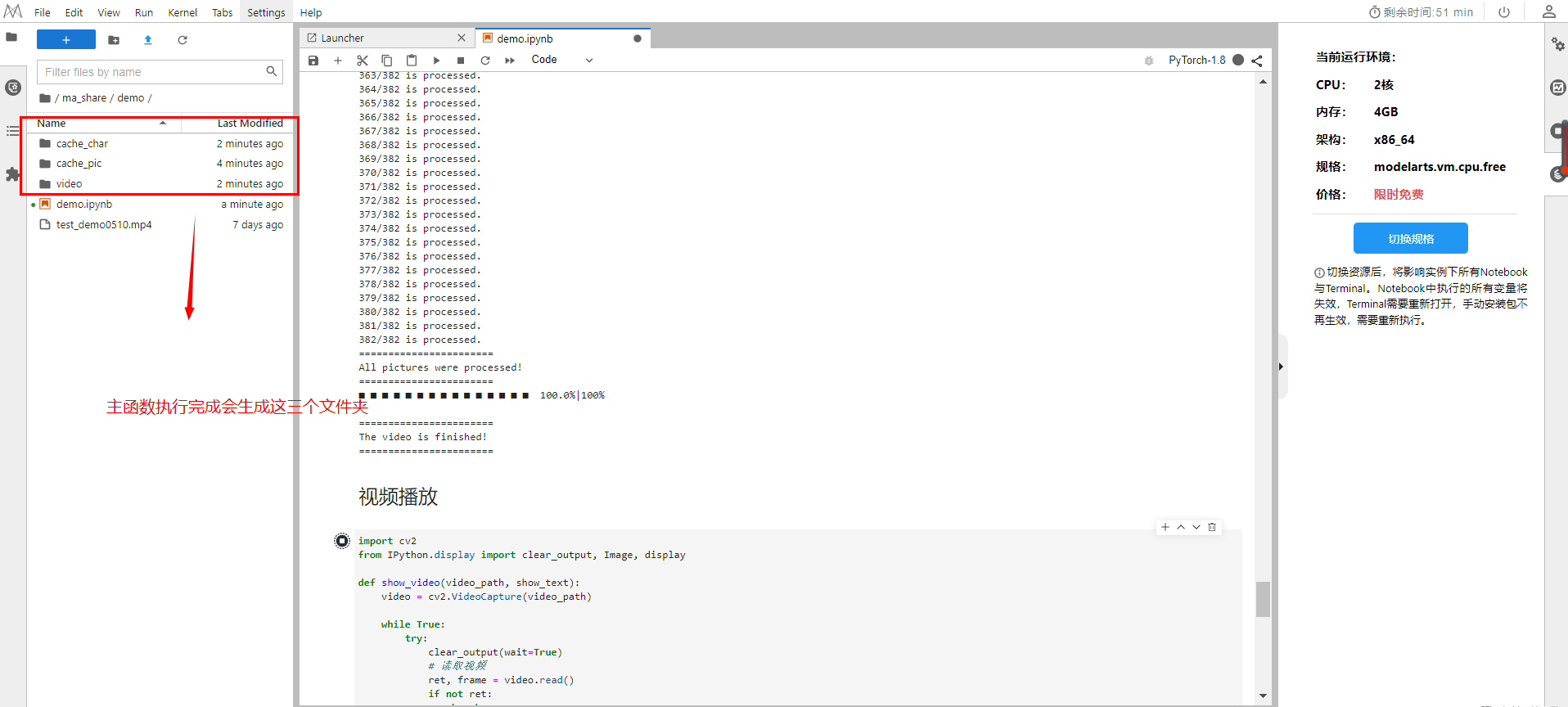
9.播放视频
总结
本文主要介绍了本地开发和华为云ModelArts开发两种形式,从开发流程中大家也明白那种形式开发更简单。
ModelArts是面向开发者的一站式AI开发平台,为机器学习与深度学习提供海量数据预处理及半自动化标注、大规模分布式Training、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。
华为云ModelArts-Notebook云开发的优势不需要本地进行安装资源包,在ModelArts-Notebook环境就已经集成了这些环境,减少了人为部署压力,更易于上手、更高性能、一站式服务、支持多种主流框架。
本文整理自华为云社区【内容共创】活动第16期。查看活动详情:https://bbs.huaweicloud.com/blogs/352652
520,用Python定制你的《本草纲目女孩》的更多相关文章
- Python定制类(进阶6)
转载请标明出处: http://www.cnblogs.com/why168888/p/6411919.html 本文出自:[Edwin博客园] Python定制类(进阶6) 1. python中什么 ...
- python定制类(1):__getitem__和slice切片
python定制类(1):__getitem__和slice切片 1.__getitem__的简单用法: 当一个类中定义了__getitem__方法,那么它的实例对象便拥有了通过下标来索引的能力. c ...
- python定制后处理云图
用后处理软件处理的云图会出现这样或那样的不满意,其实我们可以将求解数据导出以后,借助python定制云图. 我们以fluent为例 求解完成之后,我们将我们需要做云图的物理量以ASCII导出 如下的p ...
- python 定制类
看到类似__slots__这种形如__xxx__的变量或者函数名就要注意,这些在Python中是有特殊用途的. __slots__我们已经知道怎么用了,__len__()方法我们也知道是为了能让cla ...
- Python - 定制pattern的string模板(template) 具体解释
定制pattern的string模板(template) 具体解释 本文地址: http://blog.csdn.net/caroline_wendy/article/details/28625179 ...
- 使用Python定制词云
一.实验介绍 1.1 实验内容 在互联网时代,人们获取信息的途径多种多样,大量的信息涌入到人们的视线中.如何从浩如烟海的信息中提炼出关键信息,滤除垃圾信息,一直是现代人关注的问题.在这个信息爆炸的时代 ...
- python定制类详解
1.什么是定制类python中包含很多内置的(Built-in)函数,异常,对象.分别有不同的作用,我们可以重写这些功能. 2.__str__输出对象 class Language(object): ...
- Python定制容器
Python 中,像序列类型(如列表.元祖.字符串)或映射类型(如字典)都是属于容器类型,容器是可定制的.要想成功地实现容器的定制,我们需要先谈一谈协议.协议是什么呢?协议(Protocols)与其他 ...
- Python定制化天气预报消息推送
sansui-Weather 代码码云 介绍 定制化天气预报消息推送(练手小脚本) Python脚本实现天气查询应用,提醒她注意保暖! 功能介绍 天气信息获取 当天天气信息提示 第二天天气信息提示 网 ...
随机推荐
- ubuntu中有关环境变量的问题
ubuntu查看环境变量方法 在Ubuntu中,我们可以使用三个命令来查看当前环境变量的设置,以确定我们有没有把路径加载到环境变量中去.我们 可以使用env,export,或者echo $path, ...
- python-输入列表,求列表元素和(eval输入应用)
在一行中输入列表,输出列表元素的和. 输入格式: 一行中输入列表. 输出格式: 在一行中输出列表元素的和. 输入样例: [3,8,-5] 输出样例: 6 代码: a = eval(input()) t ...
- Android Studio配置openvc
最近项目中需要用到opencv,于是就研究了一下怎么在Android studio中配置opencv,记录一下,免得以后还会使用. 一.因为本人Android Studio是4.1的,网上资料大多是3 ...
- 各种类型的Dialog
下面是几种对话框的效果 图一: 图二: 图三: 图四: 图五: 图六: 图七: 图1效果:该效果是当按返回按钮时弹出一个提示,来确保无误操作,采用常见的对话框样式. 代码: 创建对话框方法dialog ...
- iframe引入微信公众号文章
微信在文章页面设置了响应头""frame-ancestors 'self'"阻止了外部页面将其嵌套的行为,文章的图片也设置了防盗链的功能,这就导致了直接在iframe中引 ...
- 通过uniCloud白捡一个在线图库管理工具,可支持图床外链
喜欢写文章的技术大佬们,应该都有一个自己的在线图片管理工具吧. 尤其是在写markdown时,为了让我们的文章"图文并茂",显得不那么枯燥,就经常需要在合适的地方插入一些关联性的图 ...
- 基于Debian搭建Hyperledger Fabric 2.4开发环境及运行简单案例
相关实验源码已上传:https://github.com/wefantasy/FabricLearn 前言 在基于truffle框架实现以太坊公开拍卖智能合约中我们已经实现了以太坊智能合约的编写及部署 ...
- 论文解读(MLGCL)《Multi-Level Graph Contrastive Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- 《手把手教你》系列基础篇(八十八)-java+ selenium自动化测试-框架设计基础-Log4j 2实现日志输出-下篇(详解教程)
1.简介 上一篇宏哥讲解和分享了如何在控制台输出日志,但是你还需要复制粘贴才能发给相关人员,而且由于界面大小限制,你只能获取当前的日志,因此最好还是将日志适时地记录在文件中直接打包发给相关人员即可.因 ...
- 【原创】记一次DouPHP站点的RCE实战之旅
声明 本次实践是在合法授权情况下进行,数据已经全部脱敏,主要是提供思路交流学习,请勿用于任何非法活动,否则后果自负. 实战记录 信息收集 1,踩点站点 通过fofa 查到目标DouPHP框架该站点(也 ...