es的查询、排序查询、分页查询、布尔查询、查询结果过滤、高亮查询、聚合函数、python操作es
今日内容概要
- es的查询
- Elasticsearch之排序查询
- Elasticsearch之分页查询
- Elasticsearch之布尔查询
- Elasticsearch之查询结果过滤
- Elasticsearch之高亮查询
- Elasticsearch之聚合函数
- Python操作es
内容详细
1、es的查询
1.1 准备数据
# 准备数据
PUT lqz/_doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
PUT lqz/_doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
PUT lqz/_doc/3
{
"name":"龙套偏房",
"age":22,
"from":"gu",
"desc":"mmp,没怎么看,不知道怎么形容",
"tags":["造数据", "真","难"]
}
PUT lqz/_doc/4
{
"name":"石头",
"age":29,
"from":"gu",
"desc":"粗中有细,狐假虎威",
"tags":["粗", "大","猛"]
}
PUT lqz/_doc/5
{
"name":"魏行首",
"age":25,
"from":"广云台",
"desc":"仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags":["闭月","羞花"]
}
1.2 match和term
match 和 term 中必须要加条件,但是我们有时候需要查询所有,不带条件,需要用到 match_all
1.3 match_all
# 查询所有
GET lqz/_search
{
"query": {
"match_all": {}
}
}
1.4 前缀查询match_phrase_prefix
# 查英文 beautiful --->be开头的---》能查到
GET lqz/_search
{
"query": {
"match_phrase_prefix": {
"name": "顾"
}
}
}
1.5 match_phrase
# 会分词,分词完成后,如果写了slop,会按分词之间间隔是slop数字去抽
GET t1/doc/_search
{
"query": {
"match_phrase": {
"title": {
"query": "中国世界",
"slop": 2
}
}
}
}
1.6 多条件查询,或的关系
# 只要name或者desc中带龙套就查出来
GET lqz/_search
{
"query": {
"multi_match": {
"query": "龙套",
"fields": ["name", "desc"]
}
}
}
2、Elasticsearch之排序查询
# 结构化查询
GET lqz/_search
{
"query": {
"match": {
"name": ""
}
}
}
# 排序查询---》可以按多个排序条件-->sort的列表中继续加
GET lqz/_search
{
"query": {
"match": {
"from": "gu"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
# 不是所有字段都可以排序--->只能是数字字段
3、Elasticsearch之分页查询
# from 和 size
GET lqz/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 3,
"size": 2
}
4、Elasticsearch之布尔查询
# must(and) should(or) must_not(not) filter
# must条件 and条件
GET lqz/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "sheng"
}
},
{
"match": {
"age": 18
}
}
]
}
}
}
"""
# 咱们认为的and查询,但是实际不行
GET lqz/_search
{
"query": {
"match": {
"from": "sheng",
"age":18
}
}
}
# 查询课程标题或者课程介绍中带python的数据
"""
# shoud or 条件---》搜索框,就是用它
GET lqz/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"from": "sheng"
}
},
{
"match": {
"age": 22
}
}
]
}
}
}
# must_not 既不是也不是
GET lqz/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"from": "gu"
}
},
{
"match": {
"tags": "可爱"
}
},
{
"match": {
"age": 18
}
}
]
}
}
}
# 查询 from为gu,age大于25的数据怎么查 filter /gt> lt< lte=
GET lqz/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "gu"
}
}
],
"filter": {
"range": {
"age": {
"lt": 25
}
}
}
}
}
}
5、Elasticsearch之查询结果过滤
# 只查某几个字段
GET lqz/_search
{
"query": {
"match": {
"name": "顾老二"
}
},
"_source": ["name", "age"]
}
6、Elasticsearch之高亮查询
# 默认高亮
GET lqz/_search
{
"query": {
"match": {
"name": "石头"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
# 自定义高亮
GET lqz/_search
{
"query": {
"match": {
"from": "gu"
}
},
"highlight": {
"pre_tags": "<b class='key' style='color:red'>",
"post_tags": "</b>",
"fields": {
"from": {}
}
}
}
7、Elasticsearch之聚合函数
# avg max min sum
# avg 求平均年龄
GET lqz/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_avg": {
"avg": {
"field": "age"
}
}
},
"_source": ["name", "age"]
}
8、Python操作es
# 官方提供了python操作es包,基础包--》建议你用---》类似于pymysql
pip install elasticsearch
'''
# 如果官方没提供,使用requests模块,发送http请求即可
# 例如:
PUT lqz/_doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
# 用python操作
import requests
data = {
"name": "大娘子",
"age": 18,
"from": "sheng",
"desc": "肤白貌美,娇憨可爱",
"tags": ["白", "富", "美"]
}
res=requests.put('http://127.0.0.1:9200/lqz/_doc/6', json=data)
print(res.text)
'''
### 使用官方的包:
from elasticsearch import Elasticsearch
# Instantiate a client instance
client = Elasticsearch("http://localhost:9200")
# Call an API, in this example `info()`
# resp = client.info()
# print(resp)
# 创建索引(Index)
# result = client.indices.create(index='user')
# print(result)
# 删除索引
# result = client.indices.delete(index='user')
# 插入数据
# data = {'userid': '1', 'username': 'lqz','password':'123'}
# result = client.create(index='news', doc_type='_doc', id=1, body=data)
# print(result)
# 更新数据
'''
不用doc包裹会报错
ActionRequestValidationException[Validation Failed: 1: script or doc is missing
'''
# data ={'doc':{'userid': '1', 'username': 'lqz','password':'123ee','test':'test'}}
# result = client.update(index='news', doc_type='_doc', body=data, id=1)
# print(result)
# 删除数据
# result = client.delete(index='news',id=1)
# 查询
# 查找所有文档
# query = {'query': {'match_all': {}}}
# 查找名字叫做jack的所有文档
# query = {'query': {'term': {'username': 'lqz'}}}
# 查找年龄大于11的所有文档
query = {'query': {'range': {'age': {'gt': 28}}}}
allDoc = client.search(index='lqz', body=query)
# print(allDoc['hits']['hits'][0]['_source'])
print(allDoc)
# python操作es的包---》类似于django的orm包
# 用的最多的是查询
# 写个脚本,把课程表的数据,同步到es中(建立索引---》插入数据)
# High level Python client for Elasticsearch
# https://github.com/elastic/elasticsearch-dsl-py
from datetime import datetime
from elasticsearch_dsl import Document, Date, Nested, Boolean,analyzer, InnerDoc, Completion, Keyword, Text,Integer
from elasticsearch_dsl.connections import connections
connections.create_connection(hosts=["localhost"])
class Article(Document):
title = Text(fields={'title': Keyword()})
author = Text()
class Index:
name = 'myindex' # 索引名
if __name__ == '__main__':
# Article.init() # 创建映射
# 保存数据
# article = Article()
# article.title = "测试测试"
# article.author = "刘清政"
# article.save() # 数据就保存了
# 查询数据
# s=Article.search()
# s = s.filter('match', title="测试")
# results = s.execute()
# print(results)
# 删除数据
# s = Article.search()
# s = s.filter('match', title="测试").delete()
# 修改数据
s = Article().search()
s = s.filter('match', title="测试")
results = s.execute()
print(results[0])
results[0].title="xxx"
results[0].save()
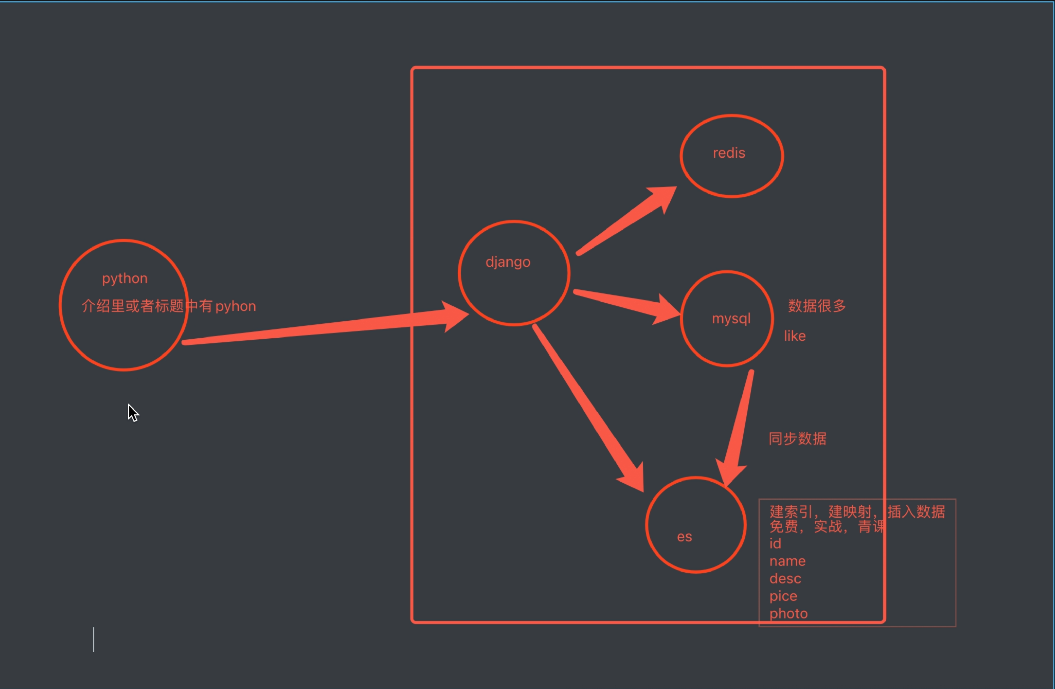
# es数据和mysql数据同步
-方案一:第三方同步脚本,实时同步mysql和es数据,软件运行,配置一下就可以了,后台一直运行
-https://github.com/go-mysql-org/go-mysql-elasticsearch
-编译成可执行文件,启动就行----》linux上编译,go sdk---》跨平台编译
-方案二:(简历里说---》es和mysql的同步工具)
-自己用python写---》三个表,pymysql---》es中---》后台一直运行
-三个表,删除数据呢?公司里的数据都不删,都是软删除
-三个表增加---》记录每个表同步到的位置id号---》
-pymysql es
-免费课表(id,name,price),实战课表(id,name,price,teacher)
id_1=0
id_2=0
pymyql打开免费课,查询id如果大于id_1,把大于id_1的取出来组装成字典,存入es
pymyql打开实战课,查询id如果大于id_2,把大于id_2的取出来,存入es
-同步到es中---》es中只存id,name,price
-方案三:使用celery,只要mysql相应的表里插入一条数据,就使用celery的异步,把这条记录插入到es中去
-方案四:信号---》监控到哪个表发生了变化---》只要xx表发生变化,就插入es
es的查询、排序查询、分页查询、布尔查询、查询结果过滤、高亮查询、聚合函数、python操作es的更多相关文章
- python 操作es
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上. Lucene 可能是目前存在的,不论开源还是私有的,拥有最先进,高性能和全功能搜索 ...
- SQL 数据库备、还,附、分,数据查询,聚合函数
认识数据库备份和事务日志备份 数据库备份与日志备份是数据库维护的日常工作,备份的目的是在于当数据库出现故障或者遭到破坏时可以根据备份的数据库及事务日志文件还原到最近的时间点将损失降到最低点. 数据库备 ...
- 【软件实施面试】MySQL和Oracle联合查询以及聚合函数面试总结
软件实施面试系列文章第二弹,MySQL和Oracle联合查询以及聚合函数的面试总结.放眼望去全是MySQL,就不能来点Oracle吗?之前面过不少公司,也做过不少笔试题,现在已经很少做笔试题了.你肚子 ...
- 多表查询思路、navicat可视化软件、python操作MySQL、SQL注入问题以及其他补充知识
昨日内容回顾 外键字段 # 就是用来建立表与表之间的关系的字段 表关系判断 # 一对一 # 一对多 # 多对多 """通过换位思考判断""" ...
- ES 25 - Elasticsearch的分页查询及其深分页问题 (deep paging)
目录 1 分页查询方法 2 分页查询的deep paging问题 1 分页查询方法 在GET请求中拼接from和size参数 // 查询10条数据, 默认从第0条数据开始 GET book_shop/ ...
- [原创]java WEB学习笔记92:Hibernate学习之路-- -QBC 检索和本地 SQL 检索:基本的QBC 查询,带 AND 和 OR 的QBC,统计查询,排序,分页
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- EF:分页查询 + 条件查询 + 排序
/// <summary> /// linq扩展类---zxh /// </summary> /// <typeparam name="T">& ...
- 在ASP.NET MVC中使用Boostrap实现产品的展示、查询、排序、分页
在产品展示中,通常涉及产品的展示方式.查询.排序.分页,本篇就在ASP.NET MVC下,使用Boostrap来实现. 源码放在了GitHub: https://github.com/darrenji ...
- oracle入门(8)——实战:支持可变长参数、多种条件、多个参数排序、分页的存储过程查询组件
[本文介绍] 学了好几天,由于项目需要,忙活了两天,写出了个小组件,不过现在还只能支持单表操作.也没考虑算法上的优化,查询速度要比hibernate只快了一点点,可能是不涉及多表查询的缘故吧,多表的情 ...
随机推荐
- H5: 表单验证失败的提示语
前言 前端的童鞋在写页面时, 都不可避免的总会踩到表单验证这个坑. 这时候, 我们就要跪了, 因为要写一堆js来检查. 但是自从H5出现后, 很多常见的表达验证, 它都已经帮我们实现了, 让我 ...
- idea maven web项目tomcat本地部署
条件:1.安装jdk 2.安装tomcat idea 创建maven web项目部署在 tomcat maven plugin中 本地部署: 1.新建maven web项目 2.输入项目名称 3. ...
- vue引入swiper
https://github.com/surmon-china/vue-awesome-swiper/blob/master/examples/03-pagination.vue https://su ...
- ORM中聚合函数、分组查询、Django开启事务、ORM中常用字段及参数、数据库查询优化
聚合函数 名称 作用 Max() 最大值 Min() 最小值 Sum() 求和 Count() 计数 Avg() 平均值 关键字: aggregate 聚合查询通常都是配合分组一起使用的 关于数据库的 ...
- vue--vuex 状态管理模式
前言 vuex作为vue的核心插件,同时在开发中也是必不可少的基础模块,本文来总结一下相关知识点. 正文 1.基于单向数据流问题而产生了Vuex 单向数据流是vue 中父子组件的核心概念,props ...
- Typora原生态的图片格式快速转化为HTML格式
Typora更改图片样式 前言 在Typora中插入的图片,默认是居中且显示原图大小的,如果想要缩小显示,可以右击图片选择缩放图片. 但是,当我上传到博客园中时,并没有保留 居中.缩放 的样式 ...
- Python学习进度汇报
学习进度还是比较慢的,上周五(18号晚上安装了Pycharm)就开始学,五天只到这个位置,当前一直是2倍速看黑马的Python视频,外加查看菜鸟的文档,需要加快一些进度了,后续还有后续的目标要实现,争 ...
- vue3项目后台管理系统模板
Vue3.0 发布第一个版本至今有一段时间了,到现在一直在更新优化,在性能方面,对比 Vue2.x ,性能的提升比较明显,打包后体积更小 来看下 Vue3.x 新增了哪些功能和特性. Performa ...
- Codeforces Round #719 (Div. 3) C. Not Adjacent Matrix
地址 Problem - C - Codeforces 题意 每个格子,该格子和相邻的格子的值不能相同 题解 思维题, 先从1~n输出奇数,再输出偶数 代码 #include <iostream ...
- 算法基础⑦搜索与图论--BFS(宽度优先搜索)
宽度优先搜索(BFS) #include<cstdio> #include<cstring> #include<iostream> #include<algo ...