《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记
论文题目:《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》
论文作者:Qibin Hou, Zihang Jiang, Li Yuan et al.
论文发表年份:2022.2
模型简称:ViP
发表期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence
Abstract
在本文中,我们提出了一种概念简单、数据高效的类似MLP的视觉识别体系结构——视觉置换器(Vision Permutator)。不同于最近的类似MLP的模型大都沿着平坦的空间维度编码空间信息。由于认识到二维特征表示所携带的位置信息的重要性,Vision Permutator通过线性投影分别对沿高度和宽度维度的特征表示进行编码。这使得Vision Permutator可以沿着一个空间方向捕获远程依赖关系,同时保持沿着另一个方向的精确位置信息。由此产生的位置敏感输出,然后以相互补充的方式聚合,形成感兴趣的对象的表达。Vision Permutator由纯1 × 1卷积组成,但可以对全局信息进行编码。Vision Permutator也消除了对自注意力的依赖,因此效率更高。开源代码: https://github.com/Andrew-Qibin/VisionPermutator
Method
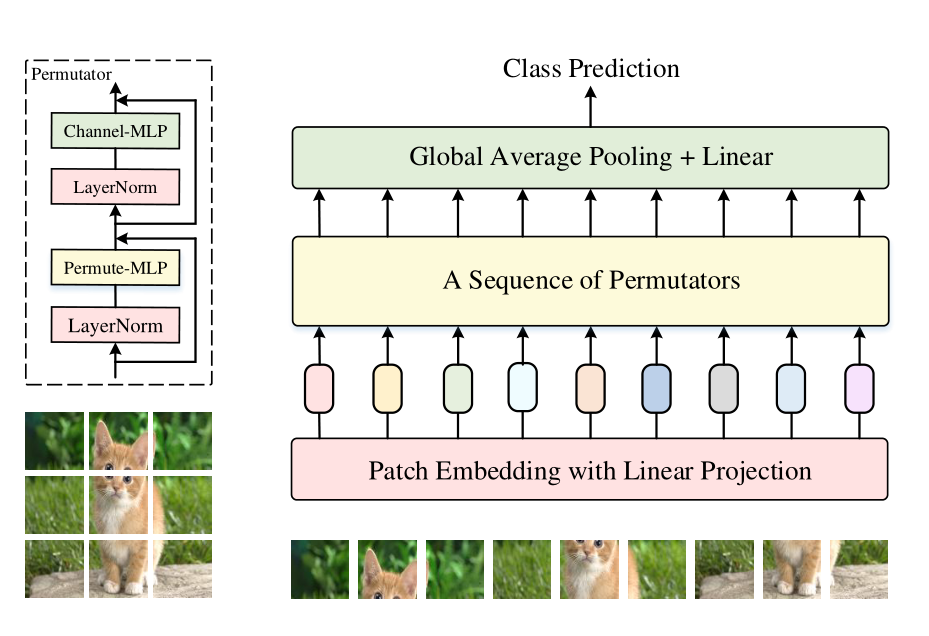
Vision Permutator从与Vision Transformers类似的tokenization操作开始,它将输入图像统一地分割为小块,然后将它们映射到带有线性投影的token embedding。然后将形状为“height×width×channels”的结果token embeddings到Permutator block序列中,每个Permutator block由一个用于空间信息编码的Permute-MLP和一个用于通道信息混合的Channel - MLP组成。Permute-MLP层如下图所示,
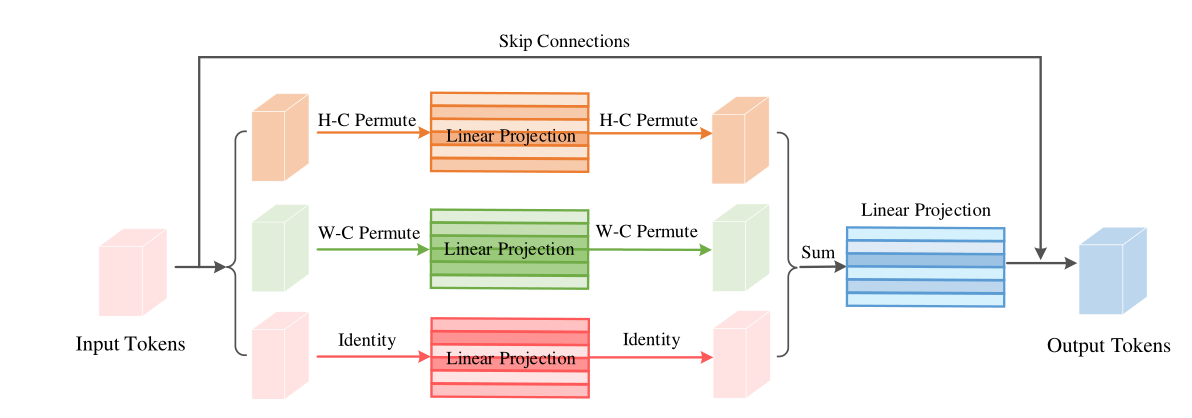
Permute-MLP层由三个独立的分支组成,每个分支沿特定的维度编码特征,即高度、宽度或通道维度。Channel-MLP模块的结构与Transformer中的前馈层相似,包括两个完全连接的层,中间有一个GELU激活。公式如下:

对于Channel信息编码,只需要一个权重WC∈RC×C的全连接层,就可以对输入X进行线性投影,得到XC。对于高度信息编码,首先对传入的分割好的每个tokens作维度变换(ex:Transpose the first (Height) dimension and the third (Channel) dimension: (H, W, C) → (C, W, H).)然后沿着通道维度连接它们作为Premute的输出,传入Linear Projection:连接权重为WH∈RC×C的全连接层,混合高度信息。再通过维度变换复原输入维度。对宽度信息编码作类似处理,最后讲三个分支的输出加和作为最后全连接层的输入。Linear Projection的输出公式表示如下:(最后输出再与input tokens作跳跃连接得到最终Permute-MLP的输出。)
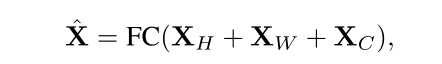
Weighted Permute-MLP:上述方法只是简单地将所有三个分支的输出通过元素相加来融合。在这里,我们通过重新校准不同分支的重要性,进一步改进了上述Permute-MLP,并提出加权Permute-MLP。这可以通过利用分散注意力(split attention)实现。不同的是,分散注意力应用于XH、XW和XC,而不是由分组卷积生成的一组张量。在下文中,我们默认使用Permutator中的加权Permute-MLP。
Experiment
与ImageNet上最近的类MLP模型比较Top-1精度,所有模型都是在没有外部数据的情况下进行训练的。在相同的计算量和参数约束下,我们的模型始终优于其他方法。
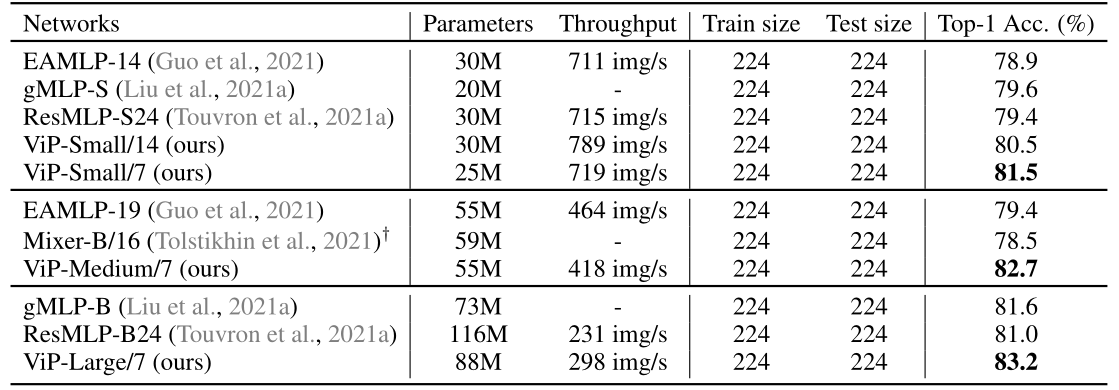
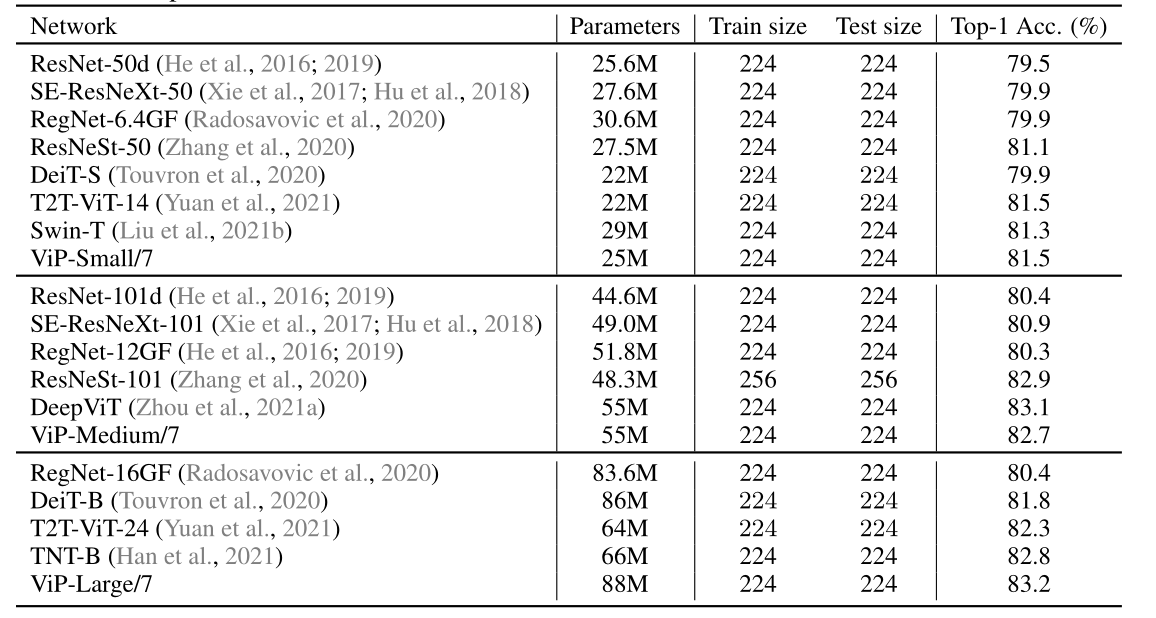
与ImageNet上的经典CNN和Vision Transformer的精度比较。所有模型都是在没有外部数据的情况下进行训练的。在相同的计算和参数约束下,我们的模型可以与一些强大的基于CNN和基于Transformer的模型竞争。
.
《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记的更多相关文章
- [place recognition]NetVLAD: CNN architecture for weakly supervised place recognition 论文翻译及解析(转)
https://blog.csdn.net/qq_32417287/article/details/80102466 abstract introduction method overview Dee ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 论文笔记——Rethinking the Inception Architecture for Computer Vision
1. 论文思想 factorized convolutions and aggressive regularization. 本文给出了一些网络设计的技巧. 2. 结果 用5G的计算量和25M的参数. ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- 论文笔记:ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware 2019-03-19 16:13:18 Pape ...
- 论文笔记:DARTS: Differentiable Architecture Search
DARTS: Differentiable Architecture Search 2019-03-19 10:04:26accepted by ICLR 2019 Paper:https://arx ...
- 论文笔记:Progressive Neural Architecture Search
Progressive Neural Architecture Search 2019-03-18 20:28:13 Paper:http://openaccess.thecvf.com/conten ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
- 论文笔记系列-DARTS: Differentiable Architecture Search
Summary 我的理解就是原本节点和节点之间操作是离散的,因为就是从若干个操作中选择某一个,而作者试图使用softmax和relaxation(松弛化)将操作连续化,所以模型结构搜索的任务就转变成了 ...
随机推荐
- 2022-7-12 javascript(2) 第七组 刘昀航
@ 目录 2022-7-12学习 第七组 刘昀航 前情提要 一.for循环 二.for in循环 三.while 和 do...while循环 1.while do... while 四.内置函数 五 ...
- 题解 $UVA$ 11825【$Hackers$' $Crackdown$】
本题的数学模型是:把\(\mathcal{n}\)个集合\(\mathcal{P1,P2,...,Pn}\)分成尽量多组,使得每组中所以集合的并集等于全集.这里集合\(\mathcal{Pi}\)就是 ...
- Java-类与对象-多态
Java类与对象-多态 多态:类与对象三大特征之一 什么是多态? 同类型的对象,执行同一个行为,会表现出不同的行为特征. 多态的形式 1.父类类型 对象名称 = new 子类构造器(); 2.接口 对 ...
- Webpack学习系列 - Webpack5 怎么集成Babel ?
程序员优雅哥简介:十年程序员,呆过央企外企私企,做过前端后端架构.分享vue.Java等前后端技术和架构. 本文摘要:主要通过实操讲解运用Webpack 5 如何集成 Babel Babel 对于前端 ...
- JavaScript 权威指南-学习笔记(一)
本文所有教程及源码.软件仅为技术研究.不涉及计算机信息系统功能的删除.修改.增加.干扰,更不会影响计算机信息系统的正常运行.不得将代码用于非法用途,如侵立删! ## JavaScript 权威指南-学 ...
- springmvc静态资源配置
<servlet> <servlet-name>dispatcher</servlet-name> <servlet-class>org.springf ...
- Docker 11 自定义镜像
参考源 https://www.bilibili.com/video/BV1og4y1q7M4?spm_id_from=333.999.0.0 https://www.bilibili.com/vid ...
- CSO视角:Sigstore如何保障软件供应链安全?
本文作者 Chris Hughes,Aquia的联合创始人及CISO,拥有近20年的网络安全经验. SolarWinds 和 Log4j 等影响广泛的软件供应链攻击事件引起了业界对软件供应链安全的关注 ...
- python九周周末总结
python九周周末总结 UDP协议 udp协议的交互模式服务端不需要考虑客户端是否退出,你发多少那么他就会按照你发的东西直接去传输给客户端不存在黏包现象 服务端: import socket ser ...
- 【Prometheus+Grafana系列】监控MySQL服务
前言 前面的一篇文章已经介绍了 docker-compose 搭建 Prometheus + Grafana 服务.当时实现了监控服务器指标数据,是通过 node_exporter.Prometheu ...