FlinkSQL 之乱序问题
乱序问题
在业务编写 FlinkSQL 时, 非常常见的就是乱序相关问题, 在出现问题时,非常难以排查,且无法稳定复现,这样无论是业务方,还是平台方,都处于一种非常尴尬的地步。
在实时 join 中, 如果是 Regular Join, 则使用的是 Hash Join 方式, 左表和右表根据 Join Key 进行hash,保证具有相同 Join Key 的数据能够 Hash 到同一个并发,进行 join 的计算 。
以下面的例子进行说明, 以下有三张表, 分别是订单表, 订单明细表, 和商品类目 。
- 这三张表的实时数据都从 MySQL 采集得到并实时写入 Kafka, 均会实时发生变化, 无法使用窗口计算
- 除了订单表有订单时间, 其他两张表都没有时间属性, 因此无法使用watermark
CREATE TABLE orders (
order_id VARCHAR,
order_time TIMESTAMP
) WITH (
'connector' = 'kafka',
'format' = 'changelog-json'
...
);
CREATE TABLE order_item (
order_id VARCHAR,
item_id VARCHAR
) WITH (
'connector' = 'kafka',)
'format' = 'changelog-json'
...
);
CREATE TABLE item_detail (
item_id VARCHAR,
item_name VARCHAR,
item_price BIGINT
) WITH (
'connector' = 'kafka',
'format' = 'changelog-json'
...
);
使用 Regular Join 进行多路 Join,数据表打宽操作如下所示
SELECT o.order_id, i.item_id, d.item_name, d.item_price, o.order_time
FROM orders o
LEFT JOIN order_item i ON o.order_id = i.order_id
LEFT JOIN item_detail d ON i.item_id = d.item_id
最终生成的 DAG 图如下所示:
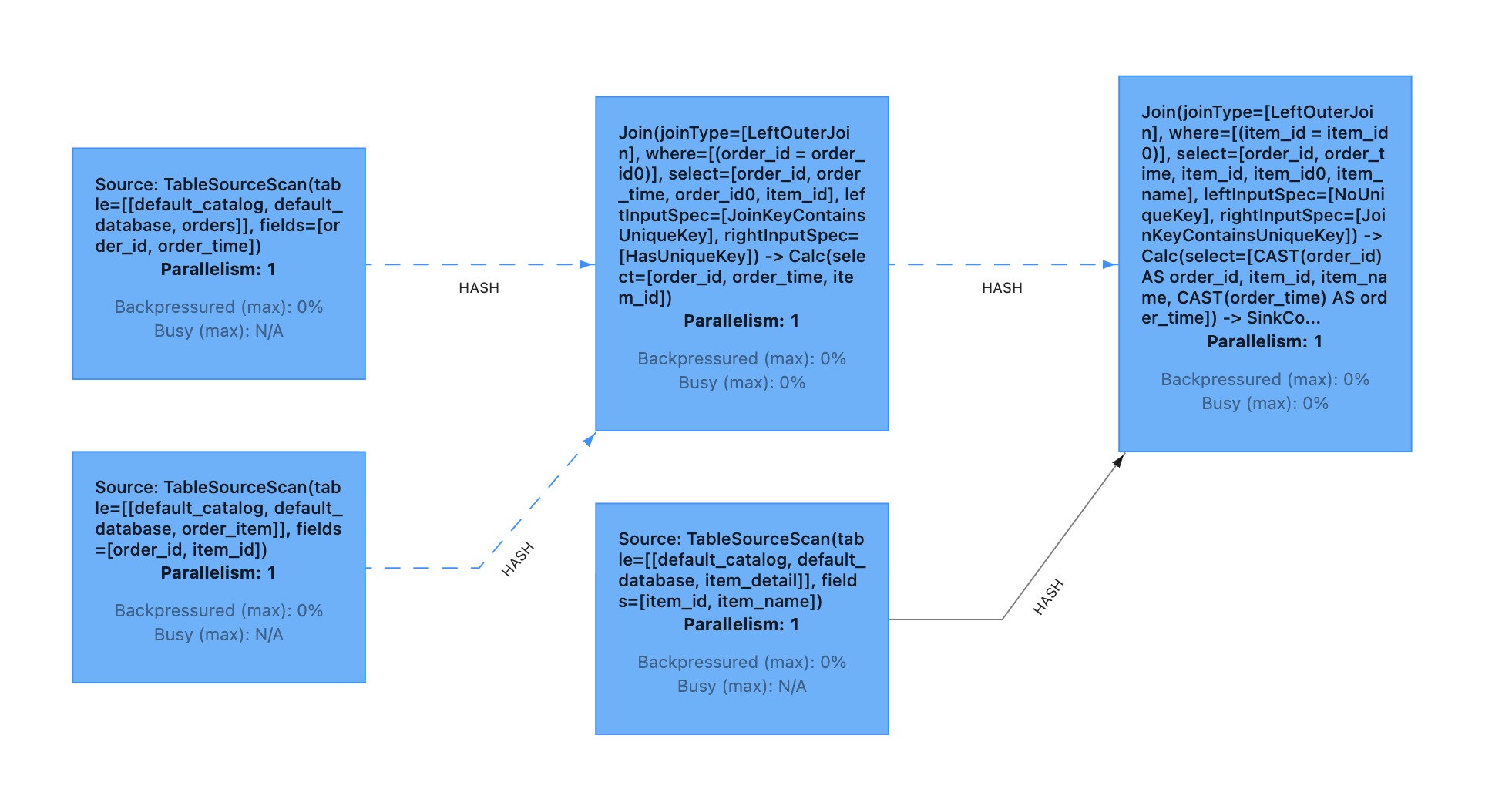
可以发现:
第一个 join (后面统一简称为ijoin1)的条件是 order_id,该 join 的两个输入会以 order_id 进行hash,具有相同 order_id 的数据能够被发送到同一个 subtask
第二个 join (后面统一简称为 join2)的条件则是 item_id, 该 join 的两个输入会以 item_id 进行hash,具有相同 item_id 的数据则会被发送到同一个 subtask.
正常情况下, 具有相同 order_id 的数据, 一定具有相同的 item_id,但由于上面的示例代码中,我们使用的是 left join 的写法, 即使没有 join 上, 也会输出为 null 的数据,这样可能导致了最终结果的不确定性。
以下面的数据为示例,再详细说明一下:
TABLE orders
| order_id | order_time |
|---|---|
| id_001 | 2022-06-03 00:00:00 |
TABLE order_item
| order_id | item_id |
|---|---|
| id_001 | item_001 |
TABLE item_detail
| item_id | item_name | item_price |
|---|---|---|
| item_001 | 类目1 | 10 |
输出数据如下:
1) 表示输出数据的并发
+I 表示数据的属性 (+I, , -D, -U, +U)
第一个 JOIN 输出
1) +I(id_001, null, 2022-06-03 00:00:00)
1) -D(id_001, null, 2022-06-03 00:00:00)
1) +I(id_001, item_001, 2022-06-03 00:00:00)
第二个 JOIN 输出
1) +I(id_001, null, null, null, 2022-06-03 00:00:00)
1) -D(id_001, null, null, null, 2022-06-03 00:00:00)
2) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) +I(id_001, item_001, 类目1, 10, 2022-06-03 00:00:00)
以上结果只是上述作业可能出现的情况之一,实际运行时并不一定会出现。 我们可以发现 join1 结果发送到 join2 之后, 相同的 order_id 并不一定会发送到同一个 subtask,因此当数据经过了 join2, 相同的 order_id 的数据会落到不同的并发,这样在后续的数据处理中, 有非常大的概率会导致最终结果的不确定性。
我们再细分以下场景考虑, 假设经过 join2 之后的结果为 join_view:
- 假设 join2 之后,我们基于 item_id 进行聚合, 统计相同类目的订单数
SELECT item_id, sum(order_id)
FROM join_view
GROUP BY item_id
很显然, 上述的乱序问题并不会影响这段逻辑的结果, item_id 为 null 的数据会进行计算, 但并不会影响 item_id 为 item_001 的结果.
- 假设 join2 之后, 我们将结果直接写入 MySQL, MySQL 主键为 order_id
CREATE TABLE MySQL_Sink (
order_id VARCHAR,
item_id VARCHAR,
item_name VARCHAR,
item_price INT,
order_time TIMESTAMP,
PRIMARY KEY (order_id) NOT ENFORCED
) with (
'connector' = 'jdbc'
);
INSERT INTO MySQL_Sink SELECT * FROM JOIN_VIEW;
由于我们在 Sink connector 中未单独设置并发, 因此 sink 的并发度是和 join2 的并发是一样的, 因此 join2 的输出会直接发送给 sink 算子, 并写入到 MySQL 中。
由于是不同并发同时在写 MySQL ,所以实际写 MySQL的顺序可能如下所示:
2) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) +I(id_001, item_001, 类目1, 10, 2022-06-03 00:00:00)
1) +I(id_001, null, null, 2022-06-03 00:00:00)
1) -D(id_001, null, null, 2022-06-03 00:00:00)
很显然, 最终结果会是 为 空, 最终写入的是一条 delete 数据
- 假设 join2 之后, 我们将结果直接写入 MySQL, 主键为 order_id, item_id, item_name
CREATE TABLE MySQL_Sink (
order_id VARCHAR,
item_id VARCHAR,
item_name VARCHAR,
item_price INT,
order_time TIMESTAMP,
PRIMARY KEY (order_id) NOT ENFORCED
) with (
'connector' = 'jdbc'
);
INSERT INTO MySQL_Sink SELECT * FROM JOIN_VIEW;
和示例2一样, 我们未单独设置 sink 的并发, 因此数据会之间发送到 sink 算子, 假设写入 MySQL 的顺序和示例2一样:
2) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) +I(id_001, item_001, 类目1, 10, 2022-06-03 00:00:00)
1) +I(id_001, null, null, null, 2022-06-03 00:00:00)
1) -D(id_001, null, null, null, 2022-06-03 00:00:00)
最终结果会是
2) +I(id_001, item_001, 类目1, 2022-06-03 00:00:00)
由于 MySQL 的主键是 order_id, item_id, item_name 所以最后的 -D 记录并不会删除 subtask 2 写入的数据, 这样最终的结果是正确的。
- 假设 join2 之后, 我们将结果写入 kafka,写入格式为 changelog-json , 下游作业消费 kafka 并进行处理
CREATE TABLE kafka_sink (
order_id VARCHAR,
item_id VARCHAR,
item_name VARCHAR,
item_price INT,
order_time TIMESTAMP,
PRIMARY KEY (order_id, item_id, item_name) NOT ENFORCED
) with (
'connector' = 'kafka',
'format' = 'changelog-json',
'topic' = 'join_result'
);
INSERT INTO kafka_sink select * from JOIN_VIEW;
默认,如果不设置 partitioner, kafka sink 会以我们在 DDL 中配置的主键生成对应的 hash key, 用于通过 hash 值生成 partition id。
有一点我们需要注意, 由于 join2 的输出已经在不同的并发了, 所以无论 kafka_sink 选择以 order_id 作为唯一的主键, 还是以 order_id, item_id, item_name 作为主键, 我们都无法控制不同并发写入 kafka 的顺序, 我们只能确保相同的并发的数据能够有序的被写入 kafka 的同一 partition 。
- 如果设置 order_id 为主键, 我们可以保证上述的所有数据能够被写入同一个 partition
- 如果设置 order_id, item_id, item_name 则上面不同并发的输出可能会被写入到不同的 partition
所以,我们需要关注的是, 当数据写入 kafka 之后, 下游怎么去处理这一份数据:
- 基于 order_id 进行去重,并按天聚合,计算当天的累加值。
以下面的 SQL 为例, 下游在消费 kafka 时, 为了避免数据重复, 先基于 order_id 做了一次去重, 用 order_id 作为分区条件, 基于proctime() 进行去重 (增加table.exec.source.cdc-events-duplicate该参数, 框架会自动生成去重算子).
-- https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/config/
set 'table.exec.source.cdc-events-duplicate'='true';
CREATE TABLE kafka_source (
order_id VARCHAR,
item_id VARCHAR,
item_name VARCHAR,
item_price INT,
order_time TIMESTAMP,
PRIMARY KEY (order_id) NOT ENFORCED
) with (
'connector' = 'kafka',
'format' = 'changelog-json',
'topic' = 'join_result'
);
-- 按order_time 聚合, 计算每天的营收
SELECT DATE_FORMAT(order_time, 'yyyy-MM-dd'), sum(item_price)
FROM kafka_source
GROUP BY DATE_FORMAT(order_time, 'yyyy-MM-dd')
结果上述的计算,我们预计结果会如何输出:
去重之后可能的输出为:
1) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
1) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
1) +I(id_001, item_001, 类目1, 10, 2022-06-03 00:00:00)
1) -D(id_001, item_001, 类目1, 10, 2022-06-03 00:00:00)
1) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
1) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
经过聚合算子算子:
1) +I(2022-06-03, null)
1) -D(2022-06-03, null)
1) +I(2022-06-03, 10)
1) -D(2022-06-03, 10)
1) +I(2022-06-03, 0)
1) -D(2022-06-03, 0)
1) +I(2022-06-03, null)
1) -D(2022-06-03, null)
可以发现,最终输出结果为2022-06-03, null,本文列举的示例不够完善, 正常情况下, 当天肯定会有其他的记录, 结果当天的结果可能不会为 null, 但我们可以知道的是,由于数据的乱序, 数据和实际结果已经不准确了。
2) 基于order_id, item_id, item_name 去重,之后按天聚合,计算当天的累加值。
-- https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/config/
set 'table.exec.source.cdc-events-duplicate'='true';
CREATE TABLE kafka_source (
order_id VARCHAR,
item_id VARCHAR,
item_name VARCHAR,
item_price INT,
order_time TIMESTAMP,
PRIMARY KEY (order_id, item_id, item_name) NOT ENFORCED
) with (
'connector' = 'kafka',
'format' = 'changelog-json',
'topic' = 'join_result'
);
-- 按order_time 聚合, 计算每天的营收
SELECT DATE_FORMAT(order_time, 'yyyy-MM-dd'), sum(item_price)
FROM kafka_source
GROUP BY DATE_FORMAT(order_time, 'yyyy-MM-dd')
去重之后的输出:
1) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
1) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
1) +I(id_001, item_001, 类目1, 10, 2022-06-03 00:00:00)
2) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
由于我们主键设置的是 order_id, item_id, item_name 所以
(id_001, item_001, null, null, 2022-06-03 00:00:00) 和
1) +I(id_001, item_001, 类目1, 10, 2022-06-03 00:00:00) 是不同的主键, 所以并不会互相影响。
经过聚合之后的结果:
1) +I(2022-06-03, null)
1) -D(2022-06-03, null)
1) +I(2022-06-03, 10)
1) -D(2022-06-03, 10)
1) +I(2022-06-03, 10)
1) -D(2022-06-03, 10)
1) +I(2022-06-03, 10)
以上就是最终结果的输出, 可以发现我们最终的结果是没有问题的。
原因分析
下图是原始作业的数据流转变化情况
orders(orders) --> |hash:order_id| join1(join1)
order_item(order_item) -->|hash:order_id| join1
join1 --> |hash:item_id| join2(join2)
item_detail(item_detail) --> |hash:item_id| join2
- A 基于 item_id 聚合, 计算相同类目的订单数 (结果正确)
join2(join2) --> |hash:item_id| group(group count:order_id)
- B 将join的数据 sink 至 MySQL (主键为 order_id) (结果错误)
join2(join2) --> |forward| sink(sink)
sink --> |jdbc send| MySQL(MySQL primarykey:order_id)
- C 将join的数据 sink 至 MySQL (主键为 order_id, item_id, item_name) (结果正确)
join2(join2) --> |forward| sink(sink)
sink --> |jdbc send| MySQL(MySQL primarykey:order_id)
- D 将 join 的数据 sink 至 kafka, 下游消费 kafka 数据并进行去重处理, 下游处理时,又可以分为两种情况。
- D-1 按 order_id 分区并去重 (结果错误)
- D-2 按 order_id, item_id, item_name 分区并去重 (结果正确)
join2(join2) --> |forward| sink(sink)
sink --> |kafka client| kafka(Kafka fixed partitioner)
kafka --> |hash:order_id| rank(rank orderby:proctime)
rank --> |"hash:date_format(order_time, 'yyyy-MM-dd')"| group("group agg:sum(item_price)")
join2(join2) --> |forward| sink(sink key)
sink --> |kafka client| kafka(Kafka fixed partitioner)
kafka --> |hash:order_id+item_id+item_name| rank(rank orderby:proctime)
rank --> |"hash:date_format(order_time, 'yyyy-MM-dd')"| group("group agg:sum(item_price)")
从上面 A, B, C, D-1, D-2 这四种 case, 我们不难发现, 什么情况下会导致错误的结果, 什么情况下不会导致错误的结果, 关键还是要看每个 task 之间的 hash 规则。
case B 产生乱序主要原因时在 sink operator, hash的条件由原来的 order_id+item_id_item_name 变成了 order_id
case D-1 产生乱序主要发生在去重的 operator, hash 的规则由原来的 order_id+item_id+item_name 变为了 order_id
我们大概能总结以下几点经验
- Flink 框架在可以保证 operator 和 operator hash 时, 一定是可以保证具有相同 hash 值的数据的在两个 operator 之间传输顺序性
- Flink 框架无法保证数据连续多个 operator hash 的顺序, 当 operator 和 operator 之间的 hash 条件发生变化, 则有可能出现数据的顺序性问题。
- 当 hash 条件由少变多时, 不会产生顺序问题, 当 hash 条件由多变少时, 则可能会产生顺序问题。
总结
大多数业务都是拿着原来的实时任务, 核心逻辑不变,只是把原来的 Hive 替换成 消息队列的 Source 表, 这样跑出来的结果,一般情况下就很难和离线对上,虽然流批一体是 Flink 的优势, 但对于某些 case , 实时的结果和离线的结果还是会产生差异, 因此我们在编写 FlinkSQL 代码时, 一定要确保数据的准备性, 在编写代码时,一定要知道我们的数据大概会产生怎样的流动, 产生怎样的结果, 这样写出来的逻辑才是符合预期的。
FlinkSQL 之乱序问题的更多相关文章
- 由乱序播放说开了去-数组的打乱算法Fisher–Yates Shuffle
之前用HTML5的Audio API写了个音乐频谱效果,再之后又加了个播放列表就成了个简单的播放器,其中弄了个功能是'Shuffle'也就是一般播放器都有的列表打乱功能,或者理解为随机播放. 但我觉得 ...
- iOS之数组的排序(升序、降序及乱序)
#pragma mark -- 数组排序方法(升序) - (void)arraySortASC{ //数组排序 //定义一个数字数组 NSArray *array = @[@(3),@(4),@(2) ...
- volatile关键字及编译器指令乱序总结
本文简单介绍volatile关键字的使用,进而引出编译期间内存乱序的问题,并介绍了有效防止编译器内存乱序所带来的问题的解决方法,文中简单提了下CPU指令乱序的现象,但并没有深入讨论. 以下是我搭建的博 ...
- Fisher-Yates 乱序算法
这两篇博客[1][2]的模式是我心仪的一种科技博客的方式,提供源代码,显示运行图形结果,通俗地介绍理论原理. 直接把结论摘录下来吧. 随机算法如果写成如下形式 randomIndex = random ...
- TCP协议下大数据传输IOCP乱序问题
毕业后稀里糊涂的闭门造车了两年,自己的独立博客也写了两年,各种乱七八糟,最近准备把自己博客废了,现在来看了下这两年写的对我来说略微有点意义的文章只此一篇,转载过来以作留念. 写的很肤浅且凌乱,请见谅. ...
- 疯狂位图之——位图生成12GB无重复随机乱序大整数集
上一篇讲述了用位图实现无重复数据的排序,排序算法一下就写好了,想弄个大点数据测试一下,因为小数据在内存中快排已经很快. 一.生成的数据集要求 1.数据为0--2147483647(2^31-1)范围内 ...
- clumsy 0.1 测试工具(延迟\掉包\节流\重发\乱序\篡改)
clumsy : http://jagt.github.io/clumsy/可以模拟以下几种场景: 延迟(Lag),把数据包缓存一段时间后再发出,这样能够模拟网络延迟的状况. 掉包(Drop),随机丢 ...
- IOS第四天(6:答题区按钮点击和乱序)
#pragma mark - 答题区按钮点击方法 - (void)answerClick:(UIButton *)button { // 1. 如果按钮没有字,直接返回 ) return; // 2. ...
- IOS第四天(3:数组的排序和乱序)
数组的升序和降序 - (void)sortWith:(NSArray *)array { // 排序 array = [array sortedArrayUsingComparator:^NSComp ...
随机推荐
- Blazor组件自做三 : 使用JS隔离封装ZXing扫码
Blazor组件自做三 : 使用JS隔离封装ZXing扫码 本文基础步骤参考前两篇文章 Blazor组件自做一 : 使用JS隔离封装viewerjs库 Blazor组件自做二 : 使用JS隔离制作手写 ...
- An=n的前n项和的前n项和
#include<iostream> using namespace std; int main() { int n,a=0,b=0; cin>>n; for(int i=1; ...
- js知识梳理4.继承的模式探究
写在前面 注:这个系列是本人对js知识的一些梳理,其中不少内容来自书籍:Javascript高级程序设计第三版和JavaScript权威指南第六版,感谢它们的作者和译者.有发现什么问题的,欢迎留言指出 ...
- RESTFUL风格的接口命名规范
1.首先restfulf风格的api是基于资源的,url命名用来定位资源,而不是表示动作,动作通过请求方式进行表示. 2.URL中应该单复数区分,推荐的实践是永远只用复数.比如GET /api/use ...
- HCIE笔记-第二节-数据封装+传输介质
数据传输的形式 1.电路交换 在通信之前,维护一条逻辑意义上的链路,这条链路仅仅可以传递两者的数据 2.报文交换 在数据之外,加上能够标识接收者.发送者的信息 3.分组交换(最主流) 依然进行报文交换 ...
- Go能实现AOP吗?
hello~大家好,我是小楼,今天分享的话题是Go是否能实现AOP? 背景 写Java的同学来写Go就特别喜欢将两者进行对比,就经常看到技术群里讨论,比如Go能不能实现Java那样的AOP啊?Go写个 ...
- golang bufio解析
golang bufio 当进行频繁地对少量数据读写时会占用IO,造成性能问题.golang的bufio库使用缓存来一次性进行大块数据的读写,以此降低IO系统调用,提升性能. 在Transport中可 ...
- 【第三课】常用的Linux命令(学习笔记)
4月8日 学习笔记打卡
- Oracle 错误表
ORA-00001: 违反唯一约束条件 (.) ORA-00017: 请求会话以设置跟踪事件 ORA-00018: 超出最大会话数 ORA-00019: 超出最大会话许可数 ORA-00020: 超出 ...
- Golang(go语言)开发环境配置
VSCode开发环境配置 目录 VSCode开发环境配置 先到VSCode官网去下载适合自己系统的VSCode安装软件 演示在WIndows下 安装使用 演示在Linux(Ubuntu/centos) ...