java实现wordCount的map
打开IDEA,File——new ——Project,新建一个项目
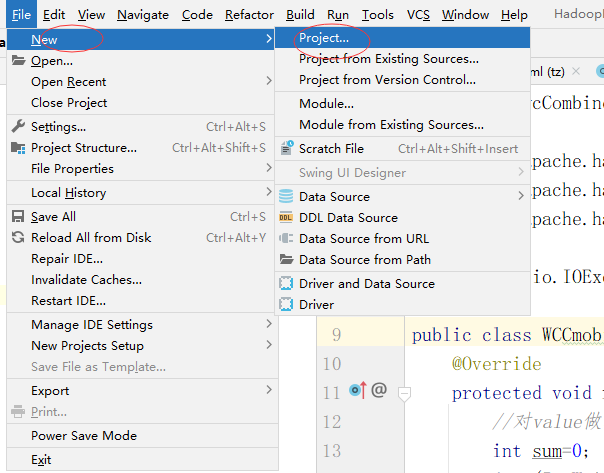
我们已经安装好了maven,不用白不用
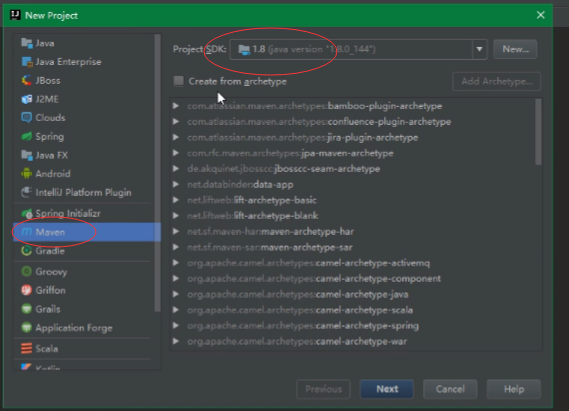
这里不要选用骨架,Next。在写上Groupid,Next。
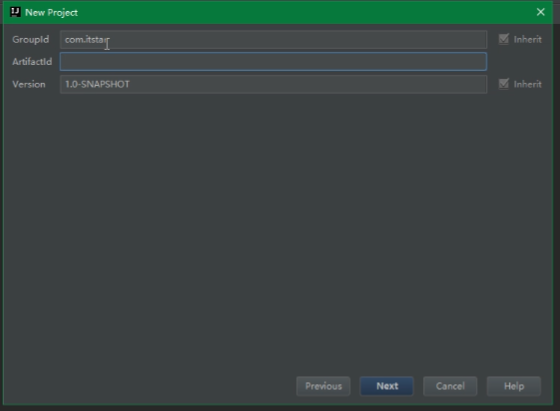
写上项目名称,finish。ok。
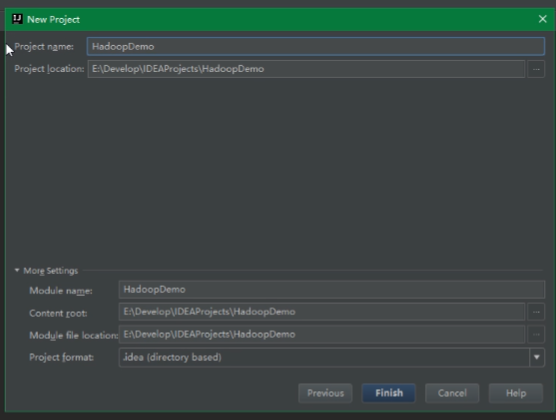
一个项目就建好了,他长这样:
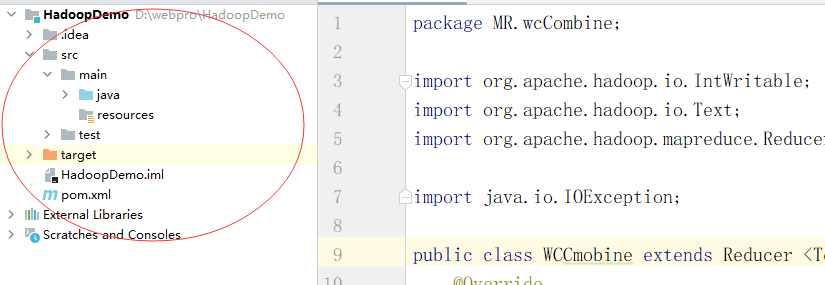
新建的项目要配置一下maven。毕竟我们马上就要用它。然后导入依赖
打开pom.xml
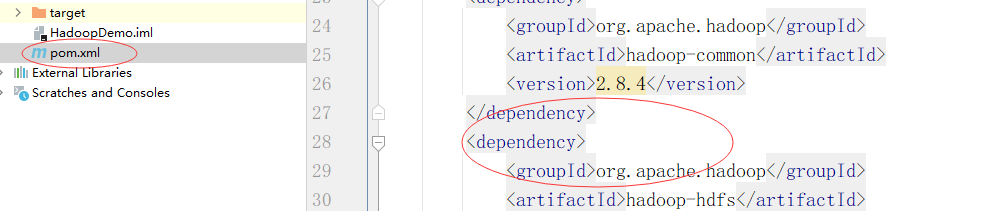
不愿意一个一个敲的话,可以使用cv大法。
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
等待下载的时候我们可以创建项目了。打开src——main——java,右键Package,我们在这里新建一个package。我们在这里包里面写一个wordcount的案例
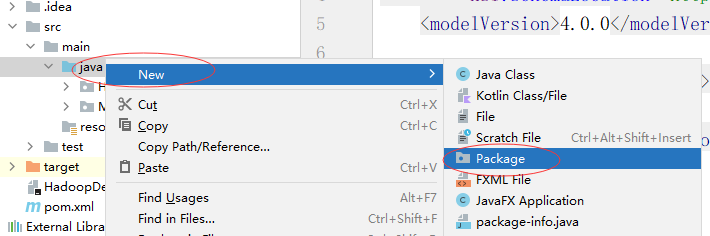
名字就叫MR
 .
.
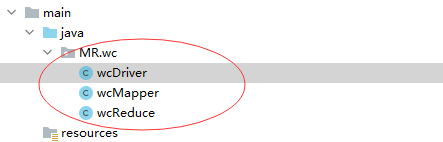
mr下再建一个包:wc。如图:

在wc下新建一个java类:wcMapper。这个类负责读取单词,生成map(键值对)
再创建一个wcReduce类。这个类负责聚合,把key相同的数据放到一起,并且累加value。
再创建一个wcDriver类,驱动类主要用于关联Mapper 和 Reducer 以及 提交整个程序。就像这样:
在写代码之前,我们先看一个mapreduce编程规范:
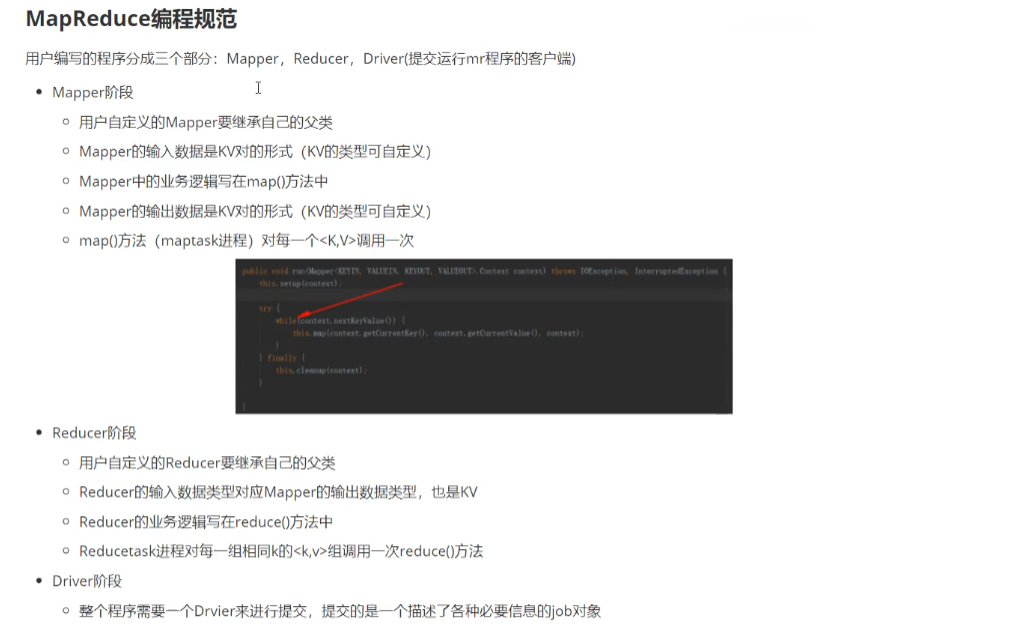
继续看代码,我们先写wcMapper类
package MR.wc;
/**
* 按行读取数据,拆成一个一个的单词
* */
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**继承Mapper类,这个类要是hadoop.mapreduce.Mapper
* 这里有一个泛型, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>KEYIN,VALUEIN 规定数据是以什么类型进入map程序(MR程序提供了几种类型)
* KEYIN这个参数表示读取文件的行数,一般是数字类型。由于是文件可能会很大,一般不用int,而是用long
* VALUEIN这个参数表示读取数据的格式,也就是单词的格式,这里就是字符串
* 我们的对象要在节点之间通过网络传输,就需要序列化。但是java的序列化是一个重量级序列化框架,一个对象被序列化后,会附带很多额外的信息
* (各种校验信息,header,继承体系等),不便于在网络中高效传输。所以hadoop开发了一套序列化机制(writable),精简,高效
*
*
*/
public class wcMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text ko=new Text();
IntWritable vo=new IntWritable(1);//value值默认为1
//重写map方法,key跟value是我们读取进来的数据,数据处理玩以后就放到congtext(上下文)里面
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//读取到的这一行数据先转成String类型
String line = value.toString();
//按照空格切分单词
String[] words = line.split(" ");
//处理数据
for (String word : words) {
//keyout设置成单词
ko.set(word);
//通过上下把处理好的数据写出
context.write(ko,vo);
}
}}
到这里,map这个过程就写完了,这个过程就实现了按行读取数据,并且把单词转化成了key,value的形式,给每个单词的value值标成了1,然后通过上下文把数据写出,在wc这个程序中,实际上就是把这个key,value传给了wcRecude。让reduce过程去按照key聚合value。
常用java类型对应的HadoopWritable类型:

java实现wordCount的map的更多相关文章
- Spark:用Scala和Java实现WordCount
http://www.cnblogs.com/byrhuangqiang/p/4017725.html 为了在IDEA中编写scala,今天安装配置学习了IDEA集成开发环境.IDEA确实很优秀,学会 ...
- Java集合框架之map
Java集合框架之map. Map的主要实现类有HashMap,LinkedHashMap,TreeMap,等等.具体可参阅API文档. 其中HashMap是无序排序. LinkedHashMap是自 ...
- Java中如何遍历Map对象的4种方法
在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都实现了Map接口,以下方法适用于任何map实现(HashMap, TreeMap, LinkedHa ...
- JAVA的容器---List,Map,Set (转)
JAVA的容器---List,Map,Set Collection├List│├LinkedList│├ArrayList│└Vector│ └Stack└SetMap├Hashtable├HashM ...
- 转!! Java中如何遍历Map对象的4种方法
在Java中如何遍历Map对象 How to Iterate Over a Map in Java 在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都 ...
- Java 集合系列 15 Map总结
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 08 Map架构
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- 【转】Java中如何遍历Map对
在Java中如何遍历Map对象 How to Iterate Over a Map in Java 在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都 ...
- 【转】Java中如何遍历Map对象的4种方法
原文网址:http://blog.csdn.net/tjcyjd/article/details/11111401 在Java中如何遍历Map对象 How to Iterate Over a Map ...
随机推荐
- 1903021121—刘明伟—Java第三周作业—学习在eclipse上创建并运行java程序
项目 内容 课程班级博客链接 19信计班(本) 作业要求链接 第三周作业 作业要求 每道题要有题目,代码,截图 扩展阅读 eclipse如何创建java程序 java语言基础(上) 扩展阅读心得: 想 ...
- docker+nginx+redis部署前后端分离项目!!!
介绍本文用的经典的前后端分离开源项目.项目的拉取这些在另一篇博客!!! 其中所需要的前后端打包本篇就不做操作了!!不明白的去看另一篇博客!!! 地址:http://www.cnblogs.com/ps ...
- JWT 访问令牌
JWT 访问令牌 更为详细的介绍jwt 在学习jwt之前我们首先了解一下用户身份验证 1 单一服务器认证模式 一般过程如下: 用户向服务器发送用户名和密码. 验证服务器后,相关数据(如用户名,用户角色 ...
- Go内存管理一文足矣
最早学习C.C++语言时,它们都是把内存的管理全部交给开发者,这种方式最灵活但是也最容易出问题,对人员要求极高:后来出现的一些高级语言像Java.JavaScript.C#.Go,都有语言自身解决了内 ...
- 766. Toeplitz Matrix - LeetCode
Question 766. Toeplitz Matrix Solution 题目大意: 矩阵从每条左上到右下对角线上的数都相等就返回true否则返回false 思路: 遍历每一行[i,j]与[i+1 ...
- unity---判断物体碰撞的对象
脚本效果 trrn对象为地面,排除这个选项
- awk-文本处理【中文手册版】
01. 简介 AWK是一个文本(面向行和列)处理工具,同时它也是一门脚本语言. AWK其名称得自于它的创始人 Alfred Aho .Peter Weinberger 和 Brian Kernigha ...
- 20212115 实验三 《python程序设计》实验报告
实验报告 20212115<python程序设计>实验三报告 课程:<Python程序设计>班级: 2121姓名: 朱时鸿学号:20212115实验教师:王志强老师实验日期:2 ...
- CF1682E Unordered Swaps
鸽着,我不知道为什么对? 题意: 思路: code: #include<bits/stdc++.h> using namespace std; const int N=5e5+5; int ...
- 【摸鱼神器】UI库秒变LowCode工具——列表篇(一)设计与实现
内容摘要: 需求分析 定义 interface 定义 json 文件 定义列表控件的 props 基于 el-table 封装,实现依赖 json 渲染 实现内置功能:选择行(单选.多选),格式化.锁 ...