CS224n学习笔记(三)
语言模型
对于一个文本中出现的单词 \(w_i\) 的概率,他更多的依靠的是前 \(n\) 个单词,而不是这句话中前面所有的单词。
\[
P\left(w_{1}, \ldots, w_{m}\right)=\prod_{i=1}^{i=m} P\left(w_{i} | w_{1}, \ldots, w_{i-1}\right) \approx \prod_{i=1}^{i=m} P\left(w_{i} | w_{i-n}, \ldots, w_{i-1}\right)
\]
在翻译系统中就是对于输入的短语,通过对所有的输出的语句进行评分,得到概率最大的那个输出,作为预测的概率。
n-gram 语言模型
对于N-Gram模型,首先要知道其中的该模型中的 count的意思,count 可以用来表示单词出现的频率,这个模型与条件概率密切相关,其中,
\[
\begin{aligned} p\left(w_{2} | w_{1}\right) &=\frac{\operatorname{count}\left(w_{1}, w_{2}\right)}{\operatorname{count}\left(w_{1}\right)} \\ p\left(w_{3} | w_{1}, w_{2}\right) &=\frac{\operatorname{count}\left(w_{1}, w_{2}, w_{3}\right)}{\operatorname{count}\left(w_{1}, w_{2}\right)} \end{aligned}
\]
对于上面的式子的解释就是,我们将 连续单词出现的频率作为概率,然后通过条件概率的形式预测出下一个单词。这个模型面临的问题是,选取多大的框,也就是选取前面多少个单词,这里面还牵涉到稀疏问题,不必要的信息就不存储,同时还要存储必要信息。
对于上面的模型需要考虑一些问题,首先是,分母分子为零的
基于窗口的神经语言模型
传统的模型可以简化为下面的图片中的样式:
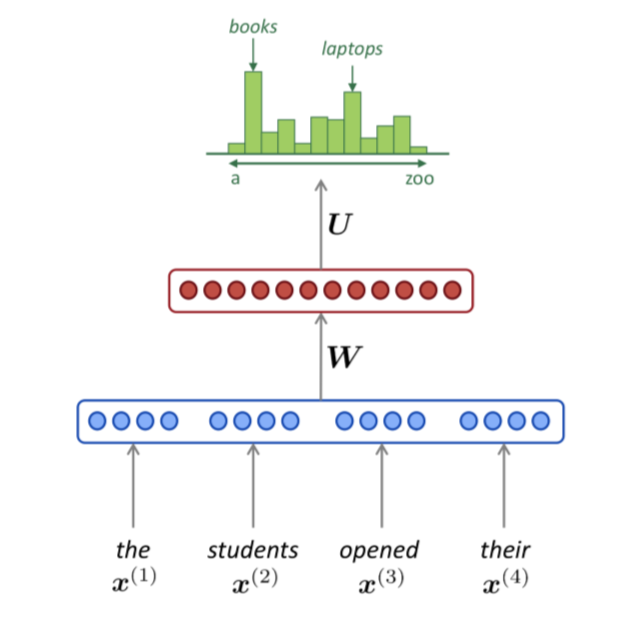
蓝色的一层是对输入的处理,获取单词向量:\(\boldsymbol{e}=\left[\boldsymbol{e}^{(1)} ; \boldsymbol{e}^{(2)} ; \boldsymbol{e}^{(3)} ; \boldsymbol{e}^{(4)}\right]\)。然后红色就是中间的隐含层,\(h=f\left(\boldsymbol{W} \boldsymbol{e}+\boldsymbol{b}_{1}\right)\),最后加一个 \(Softmax\) 层,就是分类的意思,\(\hat{y}=\operatorname{softmax}\left(U h+b_{2}\right)\)。
Recurrent Neural Networks (RNN)
传统的 \(RNN\) 如下图所示,是一个比较简单的结构,我们可以用两个式子来表示:
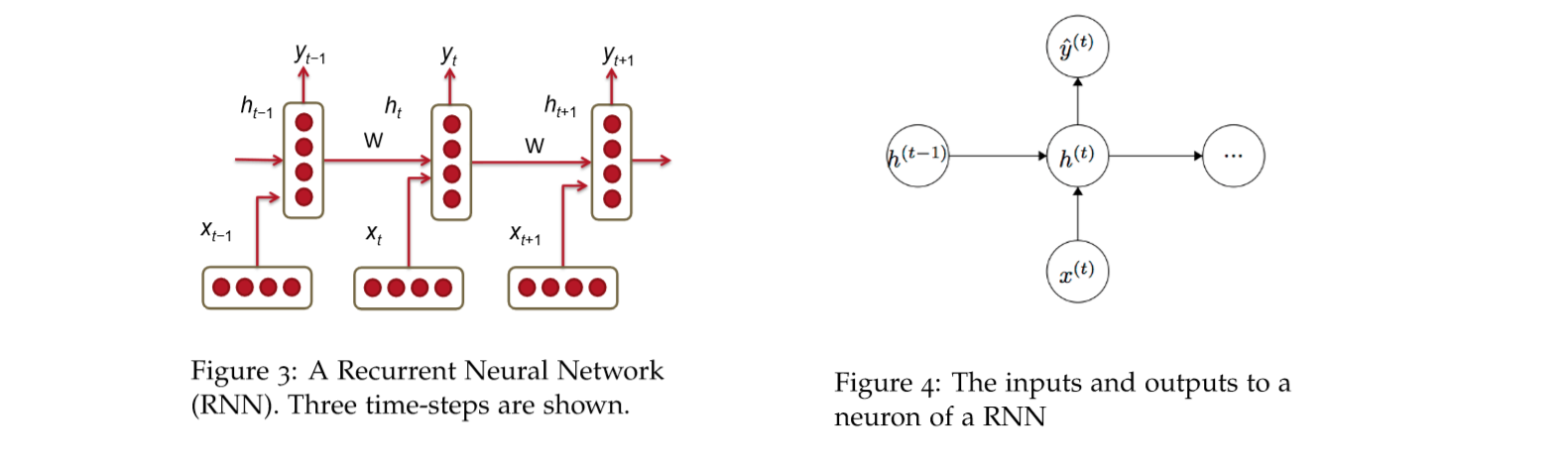
对于每一层的输入,像下面这个式子,其中激活函数一般会使用 \(tanh()\), 也可以使用 \(sigmoid\),下面的两个矩阵 \(W^{(hh)}\) 和矩阵 \(W^{(hx)}\) 维度不同,因为本质都是线性的,所以维度不同没有关系。
\[
h_{t}=\sigma\left(W^{(h h)} h_{t-1}+W^{(h x)} x_{[t]}\right)
\]
然后先通过一个矩阵 \(W^{(S)}\) 然后通过一个 \(Softmax\) 函数就可以了,
\[
\hat{y}_{t}=\operatorname{softmax}\left(W^{(S)} h_{t}\right)
\]
对于 \(softmax\) 函数,我们还要知道,\(\hat{y}_{t}\) 是最终预测的得分,而我们 \(RNN\) 传递的是 \(h_t\)。其中\(W^{(S)} \in \mathbb{R}^{|V| \times D_{h}}\) and \(\hat{y} \in \mathbb{R}^{|V|}\)。

上图就是对于一个句子的翻译,可以看出传统方法,与 RNN的区别。
RNN 的损失函数
我们通常用交叉熵损失函数来表示错误率,交叉熵损失函数就是统计预测正确的本来正确的概率,然后取反作为目标函数,通常还会取一个对数,
\[
J^{(t)}(\theta)=-\sum_{j=1}^{|V|} y_{t, j} \times \log \left(\hat{y}_{t, j}\right)
\]
如果一个语料库的大小为 \(T\),那么交叉熵损失函数就是应用于 大小为 \(T\) 的每一个单词:
\[
J=\frac{1}{T} \sum_{t=1}^{T} J^{(t)}(\theta)=-\frac{1}{T} \sum_{t=1}^{T} \sum_{j=1}^{|V|} y_{t, j} \times \log \left(\hat{y}_{t, j}\right)
\]
RNN还有一个概念叫做困惑,所谓困惑,定义如下:
\[
Perplexity =2^{J}
\]
RNN 的优缺点及其使用
使用 RNN的时的一些问题,
- RNN 网络具有记忆性,
- RNN 网络使用时,内存大小与语句大小成比例。
- RNN 中矩阵的大小与迭代的次数有关。
RNN 中的梯度消失与梯度爆炸问题
举个例子,对于两个句子:
"Jane walked into the room. John walked in too. Jane said hi to ___"
"Jane walked into the room. John walked in too. It was late in the day, and everyone was walking home after a long day at work. Jane said hi to ___"
使用RNN预测空格里面的单词,第一个句子预测正确的概率要更大一些。
下面从数学的角度解释梯度消失问题。
就像传统神经网络反向传播的时候一样,我们要对参数矩阵求导,以此获得最佳的参数。而在 RNN中,我们需要将每一次的损失加起来,也就是下面的式子:
\[
\frac{\partial E}{\partial W}=\sum_{t=1}^{T} \frac{\partial E_{t}}{\partial W}
\]
对于每一个时间点 \(t\),我们使用链式规则,
\[
\frac{\partial E_{t}}{\partial W}=\sum_{k=1}^{t} \frac{\partial E_{t}}{\partial y_{t}} \frac{\partial y_{t}}{\partial h_{t}} \frac{\partial h_{t}}{\partial h_{k}} \frac{\partial h_{k}}{\partial W}
\]
注意对于时间点 t, 我们要考虑从起始点一直到时间点 t,这是因为 RNN是链式的,而不像传统的神经网络不是链式的,相当于每一步都要进行一次优化矩阵 W,所以计算 \(d h_{t} / d h_{k}\) 可以用下面的方法:
\[
\frac{\partial h_{t}}{\partial h_{k}}=\prod_{j=k+1}^{t} \frac{\partial h_{j}}{\partial h_{j-1}}=\prod_{j=k+1}^{t} W^{T} \times \operatorname{diag}\left[f^{\prime}\left(h_{j-1}\right)\right]
\]
所以链式规则等价于下面的式子:
\[
\frac{\partial E}{\partial W}=\sum_{t=1}^{T} \sum_{k=1}^{t} \frac{\partial E_{t}}{\partial y_{t}} \frac{\partial y_{t}}{\partial h_{t}}\left(\prod_{j=k+1}^{t} \frac{\partial h_{j}}{\partial h_{j-1}}\right) \frac{\partial h_{k}}{\partial W}
\]
上周讲到神经网络中的梯度下降的时候,对矩阵的链式求导,我们讲到了雅可比矩阵,这里就用雅可比矩阵。
\[
\frac{\partial h_{j}}{\partial h_{j-1}}=\left[\frac{\partial h_{j}}{\partial h_{j-1,1}} \dots \frac{\partial h_{j}}{\partial h_{j-1, D_{n}}}\right]=\left[ \begin{array}{ccc}{\frac{\partial h_{j, 1}}{\partial h_{j-1,1}}} & {\cdots} & {\frac{\partial h_{j, 1}}{\partial h_{j-1, D_{n}}}} \\ {\vdots} & {\ddots} & {\vdots} \\ {\frac{\partial h_{j, D_{n}}}{\partial h_{j-1,1}}} & {\cdots} & {\frac{\partial h_{j, D_{n}}}{\partial h_{j-1, D_{n}}}}\end{array}\right]
\]
上面的式子很重要,因为要计算 \(h_j\) 与 \(h_{j-1}\)之间的关系,\(h_{t}=\sigma\left(W^{(h h)} h_{t-1}+W^{(h x)} x_{[t]}\right)\)。对这个函数中 \(h_{j-1}\) 求偏导。根据求导的链式法则
\[
\frac{\partial h_{j}}{\partial h_{j-1}} = W^{T} \times \operatorname{diag}\left[f^{\prime}\left(h_{j-1}\right)\right]
\]
我们用 \(\beta_{W} ,\beta_{h}\)分别表示两个行列式的上确界,而对于上面的式子,我们有:
\[
\left\|\frac{\partial h_{j}}{\partial h_{j-1}}\right\| \leq\left\|W^{T}\right\|\left\|\operatorname{diag}\left[f^{\prime}\left(h_{j-1}\right)\right]\right\| \leq \beta_{W} \beta_{h}
\]
因此用于链式法则就是:
\[
\left\|\frac{\partial h_{t}}{\partial h_{k}}\right\|=\left\|\prod_{j=k+1}^{t} \frac{\partial h_{j}}{\partial h_{j-1}}\right\| \leq\left(\beta_{W} \beta_{h}\right)^{t-k}
\]
我们将最初的式子替换一下,就是下面这样:
\[
\frac{\partial E_{t}}{\partial W}=\sum_{k=1}^{t} \frac{\partial E_{t}}{\partial y_{t}} \frac{\partial y_{t}}{\partial h_{t}} \left(\beta_{W} \beta_{h}\right)^{t-k} \frac{\partial h_{k}}{\partial W}
\]
显然这里有指数的问题,所以问题就与直接与 \(\beta_{W} ,\beta_{h}\)相关了。所以梯度消失的问题就是 \(\beta_{W} \beta_{h}\) 与 1 的大小关系的问题了。当 \(\beta_{W} \beta_{h}\) 大于 1的时候我们成为梯度爆炸,接近 0 的时候,我们称为梯度消失。
RNN 梯度下降与梯度消失的解决方法
处理梯度上升的一个简单的策略就是设置阈值:
\[
\begin{array}{c}{\hat{g} \leftarrow \frac{\partial E}{\partial W}} \\ {\text { if }\|\hat{g}\| \geq \text { threshold then }} \\ {\hat{g} \leftarrow \frac{\text {threshold}}{\|\hat{g}\|} \hat{g}} \\ {\text { end if }}\end{array}
\]
为了解决梯度消失问题,可以采用两种方法,分别是初始化矩阵 \(W^{(h h)}\),而不是随机取这个矩阵。另一种方法是,激活函数使用 \(ReLU\) 而不是\(sigmod\) 函数,因为 ReLU 函数的导数要么是 0,要么是 1。
深度双向RNN
双向 RNN,顾名思义就是有两个方向相反的 RNN,如果未知的是中间位置的单词,我们也可以反过来预测,这就是反向 RNN的思想。就如同下面的公式所说的:
\[
\vec{h}_{t}=f\left(\vec{W} x_{t}+\vec{V} \vec{h}_{t-1}+\vec{b}\right)
\]
\[
\stackrel{\leftarrow}{h}_{t}=f\left(\stackrel\leftarrow{W} x_{t}+\stackrel{\leftarrow}{V} \stackrel{\leftarrow}h_{t+1}+\stackrel{\leftarrow}{b}\right)
\]
\[
\hat{y}_{t}=g\left(U h_{t}+c\right)=g\left(U\left[\stackrel{\rightarrow}{h}_{t} ; \stackrel{\leftarrow}{h}_{t}\right]+c\right)
\]
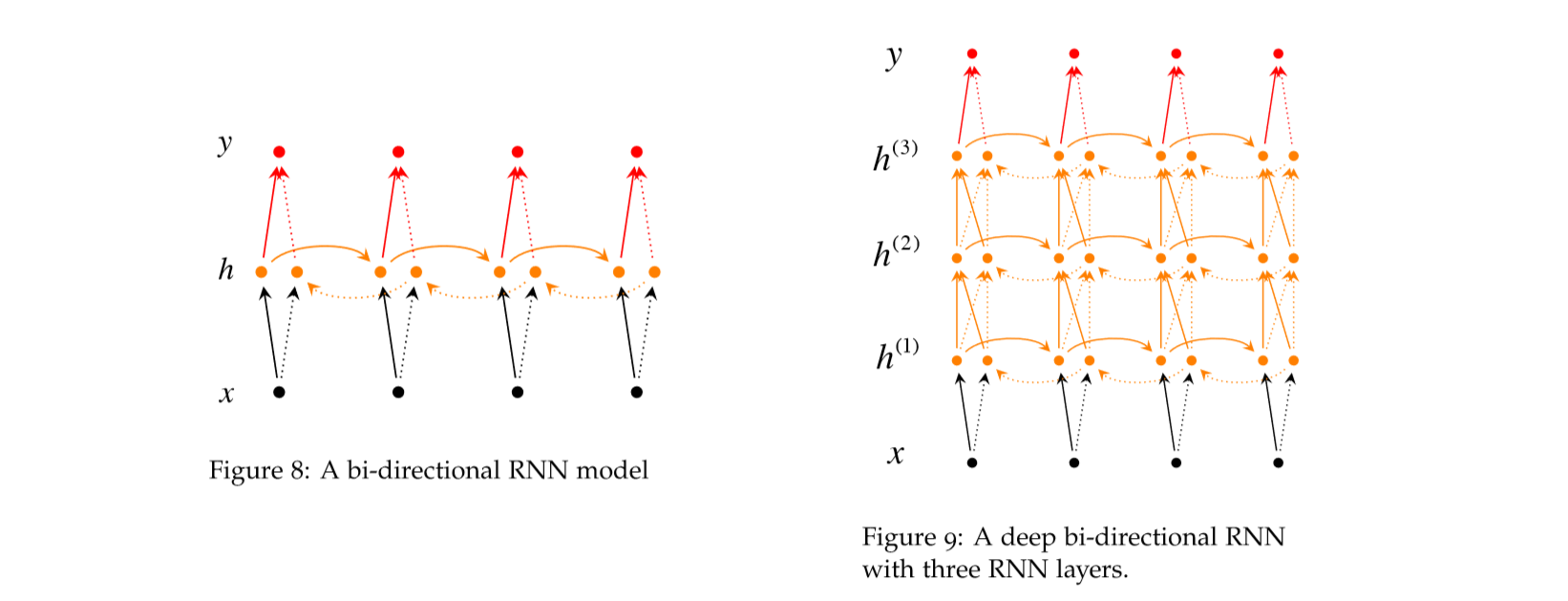
上面右图是多层 RNN 的模型,对于 \(h_t^{(i)}\),既与前一层 t 时刻的神经元 \(h_t^{(i-1)}\) 有关,还和 \(h_{t-1}^{(i)}\) 这一层前一个时刻的神经元有关,也就是每一个时间步长,不仅会纵向传播(RNN的序列传播),还会横向传播,所有的层,并行的向前传播),用公式表示就是:
\[
\vec{h}_{t}^{(i)}=f\left(\vec{W}^{(i)} h_{t}^{(i-1)}+\vec{V}^{(i)} \vec{h}_{t-1}^{(i)}+\vec{b}^{(i)}\right)
\]
\[
\stackrel{\leftarrow}{h}_{t}^{(i)}=f\left(\stackrel{\leftarrow}{W}^{(i)} h_{t}^{(i-1)}+\stackrel{\leftarrow}{V}^{(i)} \stackrel{\leftarrow}{h}_{t-1}^{(i)}+\stackrel{\leftarrow}{b}^{(i)}\right)
\]
\[
\hat{y}_{t}=g\left(U h_{t}+c\right)=g\left(U\left[\vec{h}_{t}^{(L)} ; \stackrel{\leftarrow}{h}_{t}^{(L)}\right]+c\right)
\]
RNN 翻译模型
我们使用 RNN来完成翻译,首先是 encoder,前面我们讲过神经依赖解析算法,如果我们用 RNN实现这一步,那就是这里的encoder了,这一步主要是讲源语句转化为 dense的单词向量。下面左图中的,前三层神经网络就是encoder的过程,然后最后两层就是将向量转换为另一种语言,也就是decoder的过程,其实decoder真正做的是,将向量转为另一种语言表示的向量。

下面的等式:
\[
h_{t}=\phi\left(h_{t-1}, x_{t}\right)=f\left(W^{(h h)} h_{t-1}+W^{(h x)} x_{t}\right)
\]
表示的是encoder的过程。在decoder阶段,
\[
h_{t}=\phi\left(h_{t-1}\right)=f\left(W^{(h h)} h_{t-1}\right)
\]
\[
y_{t}=\operatorname{softmax}\left(W^{(S)} h_{t}\right)
\]
对于上面的模型,我们可以使用交叉熵损失函数作为目标函数:
\[
\max _{\theta} \frac{1}{N} \sum_{n=1}^{N} \log p_{\theta}\left(y^{(n)} | x^{(n)}\right)
\]
拓展
对于 decoder阶段的隐层状态可以有三种不同的输入,分别是:
- decoder 前一个时间段的状态 \(h_{t-1}\).
- encoder 的最后一层的状态,就像图 11所示
- 前一个预测的输出的单词
所以我们可以考虑结合这三个输出,也就得到下面的模型:
\[
h_{t}=\phi\left(h_{t-1}, c, y_{t-1}\right)
\]
这个顺带提到,在谷歌提出的 sequence to sequence中,可以考虑将输入单词反转来提高翻译的准确率。
GRU
我们先看下 GRU直观的解释。
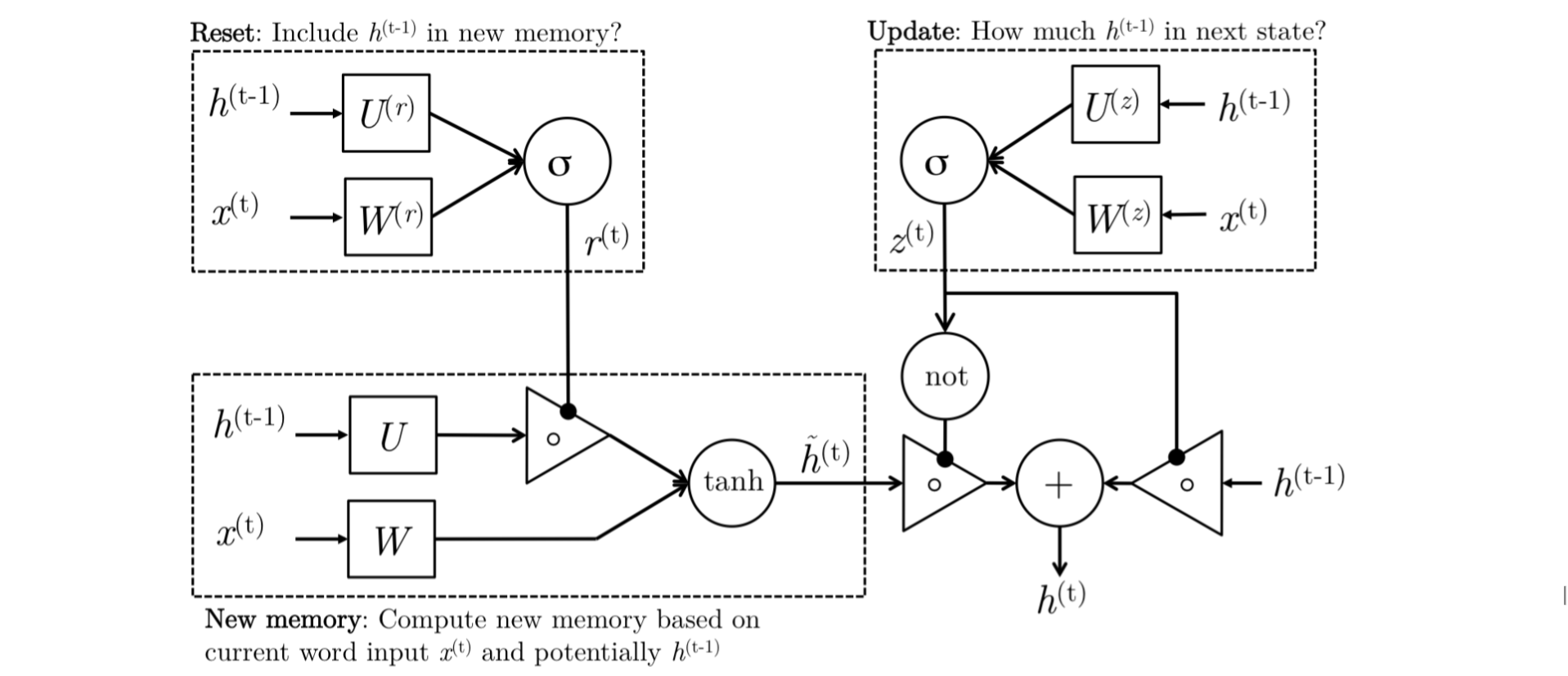
新存储信息的产生
\[
\tilde{h}_{t}=\tanh \left(r_{t} \circ U h_{t-1}+W x_{t}\right)
\]
一个新的内存状态表示,对于一个新输入的单词,考虑过去的状态,既根据语境结合新的单词与前面上下文的语境。比如我们读到句子中的一个毫不相关的单词,那么就不考虑这个单词的效益。
Reset Gate
\[
r_{t}=\sigma\left(W^{(r)} x_{t}+U^{(r)} h_{t-1}\right)
\]
可以看作是一个经过激活函数的门,来判断 \(h_{t-1}\) 对 \(h_t\) 的影响,判断是否可以完全忽略 \(h_{t-1}\) 如果 \(h_{t-1}\) 与产生新内存无关。比如我们进入一个完全新的句子,在长语句中进入一个完全新的句子,就可以不考虑 \(h_{t-1}\)。
Update Gate
\[
z_{t}=\sigma\left(W^{(z)} x_{t}+U^{(z)} h_{t-1}\right)
\]
这也是一个门,用来判断更新的时候的取值,从上面的图中可以打看到, \(z_t\) 是在 \(\tilde{h}_{t}\) 与 \(h_{(\mathrm{t}-1)}\) 之间的权衡的。我们可以这么说,当 \(z_t\) \(\approx 1\) 的时候,\(h_{t-1}\) 这一层几乎全部复制给 \(h_t\),而当 \(z_t\) $\approx 0 $ 的时候,我们更多的将 \(\tilde{h}_{t}\) 传到下一个状态。
Hidden state:
\[
h_{t}=\left(1-z_{t}\right) \circ \tilde{h}_{t}+z_{t} \circ h_{t-1}
\]
隐含层在计算的时候,是考虑到对 \(\tilde{h}_{t}\) 与 \(h_{(\mathrm{t}-1)}\) 之间的权衡取舍,这也是 GRU的核心之一。GRU的核心就是,首先判断新来的单词与上下文之间的关系,需要联合语句构造新的语境。
LSTM
LSTM之前有所接触,感觉理解的不够深刻,比起 GRU,门明显变多了,但是本质差不了太多,先看下直观解释:

New memory generation:
\[
\tilde{c}_{t}=\tanh \left(W^{(c)} x_{t}+U^{(c)} h_{t-1}\right)
\]
这一步与 GRU类似。
Input Gate:
\[
i_{t}=\sigma\left(W^{(i)} x_{t}+U^{(i)} h_{t-1}\right)
\]
判断新的单词是否值得作为参数,和 GRU一样。通过与上下文的结合,判断这个输入,有多大的权重作为新的特征。
Forget Gate:
\[
f_{t}=\sigma\left(W^{(f)} x_{t}+U^{(f)} h_{t-1}\right)
\]
忘记层,与 Input Gate 类似,但是这里是判断是否忘记,也就是判断是否忘记前面所记录的信息,我们可以理解为特征。
Final memory generation:
\[
c_{t}=f_{t} \circ c_{t-1}+i_{t} \circ \tilde{c}_{t}
\]
这一层就是根据前面的几个门,信息留下的权重,新的信息考虑进去的权重。
Output/Exposure Gate:
\[
o_{t}=\sigma\left(W^{(o)} x_{t}+U^{(o)} h_{t-1}\right)
\]
\[
h_{t}=o_{t} \circ \tanh \left(c_{t}\right)
\]
这里的两个函数的目的是将 \(h_t\) 与 \(C_t\) 分开,因为 \(C_t\) 中存储了很多不必要的信息。因为隐含层作为每一个门的参数,所以这里需要考虑哪些信息留在隐含层。所以使用了一个门 \(O_t\)。
CS224n学习笔记(三)的更多相关文章
- Oracle学习笔记三 SQL命令
SQL简介 SQL 支持下列类别的命令: 1.数据定义语言(DDL) 2.数据操纵语言(DML) 3.事务控制语言(TCL) 4.数据控制语言(DCL)
- [Firefly引擎][学习笔记三][已完结]所需模块封装
原地址:http://www.9miao.com/question-15-54671.html 学习笔记一传送门学习笔记二传送门 学习笔记三导读: 笔记三主要就是各个模块的封装了,这里贴 ...
- JSP学习笔记(三):简单的Tomcat Web服务器
注意:每次对Tomcat配置文件进行修改后,必须重启Tomcat 在E盘的DATA文件夹中创建TomcatDemo文件夹,并将Tomcat安装路径下的webapps/ROOT中的WEB-INF文件夹复 ...
- java之jvm学习笔记三(Class文件检验器)
java之jvm学习笔记三(Class文件检验器) 前面的学习我们知道了class文件被类装载器所装载,但是在装载class文件之前或之后,class文件实际上还需要被校验,这就是今天的学习主题,cl ...
- VSTO学习笔记(三) 开发Office 2010 64位COM加载项
原文:VSTO学习笔记(三) 开发Office 2010 64位COM加载项 一.加载项简介 Office提供了多种用于扩展Office应用程序功能的模式,常见的有: 1.Office 自动化程序(A ...
- Java IO学习笔记三
Java IO学习笔记三 在整个IO包中,实际上就是分为字节流和字符流,但是除了这两个流之外,还存在了一组字节流-字符流的转换类. OutputStreamWriter:是Writer的子类,将输出的 ...
- NumPy学习笔记 三 股票价格
NumPy学习笔记 三 股票价格 <NumPy学习笔记>系列将记录学习NumPy过程中的动手笔记,前期的参考书是<Python数据分析基础教程 NumPy学习指南>第二版.&l ...
- Learning ROS for Robotics Programming Second Edition学习笔记(三) 补充 hector_slam
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS for Robotics Pr ...
- Learning ROS for Robotics Programming Second Edition学习笔记(三) indigo rplidar rviz slam
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS for Robotics Pr ...
- Typescript 学习笔记三:函数
中文网:https://www.tslang.cn/ 官网:http://www.typescriptlang.org/ 目录: Typescript 学习笔记一:介绍.安装.编译 Typescrip ...
随机推荐
- JavaWeb 之 JSON
一.概述 1.概念 JSON:JavaScript Object Notation JavaScript对象表示法 2.基本格式 var p = {"name":"张三 ...
- linux修改当前用户环境变量永久生效
在linux环境中,修改当前用户环境变量,且永久生效的方法如下. 1,编辑~/.bash_profile文件 1 2 3 # Get the aliases and functions 4 if [ ...
- 【技巧】如何使用客户端发布BLOG+如何快速发布微信公众号文章
[技巧]如何使用客户端发布BLOG+如何快速发布微信公众号文章 1 BLOG文档结构图 2 前言部分 2.1 导读和注意事项 各位技术爱好者,看完本文后,你可以掌握如下的技能,也 ...
- IDEA整合SVN遇到的坑
1.安装SVN客户端 注意客户端版本与汉化插件的版本匹配问题,否则汉化无效 2.安装客户端时第二项默认不安装记得要手动选择为安装,否则不会生成svn.exe,这个文件会在IDEA中配置 3.安装客 ...
- go调度: 第二部分-go调度器
前言 这个博客是三部分中提供go调度器的语义和机制的部分. 博客三部分的顺序: 1) go调度: 第一部分-操作系统调度 2) go调度: 第二部分-go调度器 3) go调度: 第三部分-并发 介绍 ...
- Spring Boot 默认支持的并发量
Spring Boot应用支持的最大并发量是多少? Spring Boot 能支持的最大并发量主要看其对Tomcat的设置,可以在配置文件中对其进行更改.当在配置文件中敲出max后提示值就是它的默认值 ...
- 百度语音合成api/sdk及demo
1.流程 1)换取token 用Api Key 和 SecretKey.访问https://openapi.baidu.com/oauth/2.0/token 换取 token // appKey = ...
- IDEA中css文件包红色下划线
选中该文件,右键 -> Analyze -> Configure Current File Analysis... Highlighting Level置为None
- ThinkPHP模板之二
模板布局及变量比较,循环. controller <?php /** * Created by PhpStorm. * User: Sahara * Date: 2019/6/23 * Time ...
- Thinkphp下记录和统计时间(微秒)和内存使用情况
* 记录和统计时间(微秒)和内存使用情况 * 使用方法: * <code> * G('begin'); // 记录开始标记位 * // ... 区间运行代码 * G('end'); // ...