【TensorFlow官方文档】MNIST机器学习入门
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片;它也包含每一张图片对应的标签,告诉我们这个是数字几。比如,下面这四张图片的标签分别是5,0,4,1。
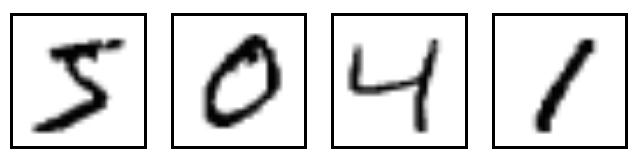
从一个很简单的数学模型开始:训练一个机器学习模型用于预测图片里面的数字,它叫做Softmax Regression。
- Softmax回归介绍
我们知道MNIST的每一张图片都表示一个数字,从0到9。我们希望得到给定图片代表每个数字的概率。比如说,我们的模型可能推测一张包含9的图片代表数字9的概率是80%但是判断它是8的概率是5%(因为8和9都有上半部分的小圆),然后给予它代表其他数字的概率更小的值。
softmax模型可以用来给不同的对象分配概率。softmax回归(softmax regression)分两步:
第一步,为了得到一张给定图片属于某个特定数字类的证据(evidence),我们对图片像素值进行加权求和。如果这个像素具有很强的证据说明这张图片不属于该类,那么相应的权值为负数,相反如果这个像素拥有有利的证据支持这张图片属于这个类,那么权值是正数。下面的图片显示了一个模型学习到的图片上每个像素对于特定数字类的权值。红色代表负数权值,蓝色代表正数权值。

我们也需要加入一个额外的偏置量(bias),因为输入往往会带有一些无关的干扰量。因此对于给定的输入图片x 它代表的是数字 i 的证据可以表示为

其中bi代表数字 i 类的偏置量,j代表给定图片 x 的像素索引用于像素求和。然后用softmax函数可以把这些证据转换成概率 y :
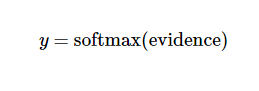
这里的softmax可以看成是一个激励(activation)函数或者链接(link)函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布。因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值。softmax函数可以定义为:
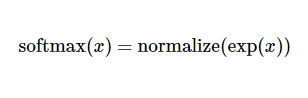
展开等式右边的子式,可以得到:
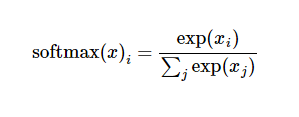
对于softmax回归模型可以用下面的图解释,对于输入的 xs 加权求和,再分别加上一个偏置量,最后再输入到softmax函数中:
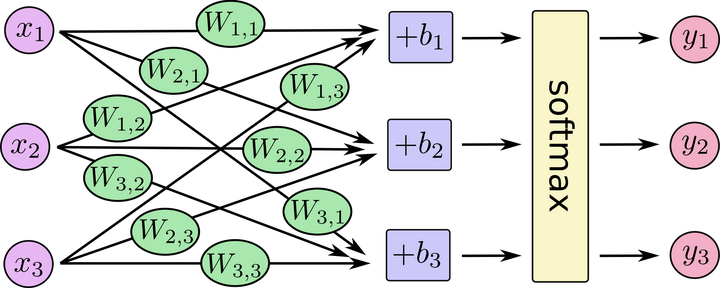
把它写成一个等式:
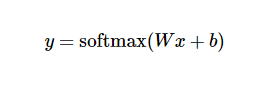
- 导入MNIST数据集
import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
上面代码是官方文档里的,但你发现运行会出错,改为下面这个代码:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
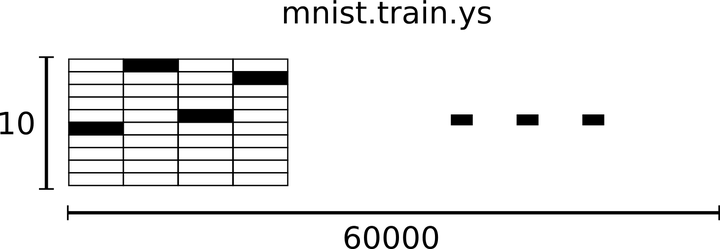
下载下来的数据集被分成两部分:60000行的训练数据集( mnist.train )和10000行的测试数据集( mnist.test )。每一个MNIST数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。我们把这些图片设为“xs”,把这些标签设为“ys”。训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels 。
每一张图片包含28X28个像素点。我们可以用一个数字数组来表示这张图片(把这个数组展开成一个向量,长度是 28x28 = 784):

因此,在MNIST训练数据集中,mnist.train.images 是一个形状为 [60000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。

相对应的MNIST数据集的标签是介于0到9的数字,用来描述给定图片里表示的数字。这里标签数据是"one-hot vectors"。 一个one-hot向量除了某一位的数字是1以外其余各维度数字都是0。所以在此教程中,数字n将表示成一个只有在第n维度(从0开始)数字为1的10维向量。比如,标签0将表示成([1,0,0,0,0,0,0,0,0,0,0])。因此,mnist.train.labels 是一个 [60000, 10] 的数字矩阵。
- 实现回归模型
使用TensorFlow之前,首先导入它:
import tensorflow as tf
我们通过操作符号变量来描述这些可交互的操作单元,可以用下面的方式创建一个:
x = tf.placeholder("float", [None, 784])
x 不是一个特定的值,而是一个占位符 placeholder ,我们在TensorFlow运行计算时输入这个值。我们希望能够输入任意数量的MNIST图像,每一张图展平成784维的向量。我们用2维的浮点数张量来表示这些图,这个张量的形状是 [None,784 ] 。(这里的 None 表示此张量的第一个维度可以是任何长度的。)
权重值和偏置量当然可以把它们当做是另外的输入(使用占位符),但TensorFlow有一个更好的方法来表示它们:Variable 。 一个 Variable 代表一个可修改的张量,存在在TensorFlow的用于描述交互性操作的图中。它们可以用于计算输入值,也可以在计算中被修改。对于各种机器学习应用,一般都会有模型参数,可以用 Variable 表示。在这里,我们都用全为零的张量来初始化 W 和b 。因为我们要学习 W 和 b 的值,它们的初值可以随意设置。
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
现在,我们可以实现我们的模型啦。只需要一行代码!
y = tf.nn.softmax(tf.matmul(x,W) + b)
- 训练模型
为了训练我们的模型,我们首先需要定义一个指标来评估这个模型是好的。其实在机器学习,我们通常定义指标来表示一个模型是坏的,这个指标称为成本(cost)或损失(loss),然后尽量最小化这个指标。但是,这两种方式是相同的。一个非常常见的,非常漂亮的成本函数是“交叉熵”(cross-entropy)。
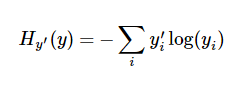
y 是我们预测的概率分布, y' 是实际的分布(我们输入的one-hot vector)。比较粗糙的理解是,交叉熵是用来衡量我们的预测用于描述真相的低效性。
为了计算交叉熵,我们首先需要添加一个新的占位符用于输入正确值:
y_ = tf.placeholder("float", [None,10])
计算交叉熵:
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
首先,用 tf.log 计算 y 的每个元素的对数。接下来,我们把 y_ 的每一个元素和 tf.log(y) 的对应元素相乘。最后,用 tf.reduce_sum 计算张量的所有元素的总和。(注意,这里的交叉熵不仅仅用来衡量单一的一对预测和真实值,而是所有100幅图片的交叉熵的总和。对于100个数据点的预测表现比单一数据点的表现能更好地描述我们的模型的性能。
现在我们知道我们需要我们的模型做什么啦,用TensorFlow来训练它是非常容易的。因为TensorFlow拥有一张描述你各个计算单元的图,它可以自动地使用反向传播算法(backpropagation algorithm)来有效地确定你的变量是如何影响你想要最小化的那个成本值的。然后TensorFlow会用你选择的优化算法来不断地修改变量以降低成本。
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
在这里,我们要求TensorFlow用梯度下降算法(gradient descent algorithm)以0.01的学习速率最小化交叉熵。梯度下降算法(gradient descent algorithm)是一个简单的学习过程,TensorFlow只需将每个变量一点点地往使成本不断降低的方向移动。当然TensorFlow也提供了其他许多优化算法:只要简单地调整一行代码就可以使用其他的算法。
在运行计算之前,我们需要添加一个操作来初始化我们创建的变量:
init = tf.initialize_all_variables()
现在我们可以在一个 Session 里面启动我们的模型,并且初始化变量:
sess = tf.Session()
sess.run(init)
然后开始训练模型,这里我们让模型循环训练1000次!
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
该循环的每个步骤中,我们都会随机抓取训练数据中的100个批处理数据点,然后我们用这些数据点作为参数替换之前的占位符来运行 train_step 。
使用一小部分的随机数据来进行训练被称为随机训练(stochastic training)- 在这里更确切的说是随机梯度下降训练。在理想情况下,我们希望用我们所有的数据来进行每一步的训练,因为这能给我们更好的训练结果,但显然这需要很大的计算开销。所以,每一次训练我们可以使用不同的数据子集,这样做既可以减少计算开销,又可以最大化地学习到数据集的总体特性。
- 评估模型
首先让我们找出那些预测正确的标签。 tf.argmax 是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,比如 tf.argmax(y,1) 返回的是模型对于任一输入x预测到的标签值,而 tf.argmax(y_,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
这行代码会给我们一组布尔值。为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。例如[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75 .
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
最后,我们计算所学习到的模型在测试数据集上面的正确率。
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
这个最终结果值应该大约是91%。
- 完整运行代码
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('G:\MNIST DATABASE\MNIST_data',one_hot=True) def add_layers(inputdata,inputsize,outputsize,activation_function=None):
Weights = tf.Variable(tf.random_normal([inputsize,outputsize]))
biases = tf.Variable(tf.zeros([1,outputsize]) + 0.1) Weights_biases_add = tf.matmul(inputdata,Weights) + biases if activation_function is None:
outputs = Weights_biases_add
else:
outputs = activation_function(Weights_biases_add) return outputs def get_accuracy(v_x,v_y_):
global prediction
y_pre = sess.run(prediction,feed_dict={x:v_x})
correct_prediction = tf.equal(tf.argmax(y_pre,1),tf.argmax(v_y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
return sess.run(accuracy,feed_dict={x:v_x,y_:v_y_}) x = tf.placeholder(tf.float32,[None,784])
y_ = tf.placeholder(tf.float32,[None,10]) prediction = add_layers(x,784,10,activation_function=tf.nn.softmax) cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(prediction),
reduction_indices=[1])) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) init = tf.initialize_all_variables() sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs,batch_ys = mnist.train.next_batch(100)
sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys}) if i % 50 ==0:
print(get_accuracy(mnist.test.images,mnist.test.labels))
【TensorFlow官方文档】MNIST机器学习入门的更多相关文章
- 人工智能系统Google开源的TensorFlow官方文档中文版
人工智能系统Google开源的TensorFlow官方文档中文版 2015年11月9日,Google发布人工智能系统TensorFlow并宣布开源,机器学习作为人工智能的一种类型,可以让软件根据大量的 ...
- TensorFlow官方文档
关于<TensorFlow官方文档> <TensorFlow官方文档>原文地址:http://devdocs.io/tensorflow~python/ ,本次经过W3Csch ...
- TensorFlow 官方文档中文版【转】
转自:http://wiki.jikexueyuan.com/project/tensorflow-zh/ TensorFlow 官方文档中文版 你正在阅读的项目可能会比 Android 系统更加深远 ...
- TensorFlow 官方文档中文版
http://wiki.jikexueyuan.com/list/deep-learning/ TensorFlow 官方文档中文版 你正在阅读的项目可能会比 Android 系统更加深远地影响着世界 ...
- tensorflow官方文档中的sub 和mul中的函数已经在API中改名了
在照着tensorflow 官方文档和极客学院中tensorflow中文文档学习tensorflow时,遇到下面的两个问题: 1)AttributeError: module 'tensorflow' ...
- TensorFlow 官方文档中文版 --技术文档
1.文档预览 2.文档下载 TensorFlow官方文档中文版-v1.2.pdf 提取码:pt7p
- TensorFlow 官方文档中文版学习
TensorFlow 官方文档中文版 地址:http://wiki.jikexueyuan.com/project/tensorflow-zh/
- 在 Ubuntu 上安装 TensorFlow (官方文档的翻译)
本指南介绍了如何在 Ubuntu 上安装 TensorFlow.这些指令也可能对其他 Linux 变体起作用, 但是我们只在Ubuntu 14.04 或更高版本上测试了(我们只支持) 这些指令. 一 ...
- Tensorflow官方文档中文版——第二章(瞎奖杯写)
包含如下几个部分: 1.面向机器学习初学者的 MNIST 初级教程 2.面向机器学习专家的 MNIST 高级教程 3.TensorFlow 使用指南 4.卷积神经网络 5.单词的向量表示(word e ...
随机推荐
- sql 树形递归查询
sql 树形递归查询: with ProductClass(ClassId,ClassName) as ( union all select c.ClassId,c.ClassName from Cl ...
- Redis 学习-持久化与主从复制
一.持久化 1. RDB rdb 是 redis 内存到硬盘的快照,用于持久化 ①. 通过执行命令,主动保存快照 save # 执行保存快照,执行时 redis 会处理阻塞状态直至执行完成. bgsa ...
- [LeetCode] 72. 编辑距离 ☆☆☆☆☆(动态规划)
https://leetcode-cn.com/problems/edit-distance/solution/bian-ji-ju-chi-mian-shi-ti-xiang-jie-by-labu ...
- 安装xadmin模板依赖
### 安装xadmin模板依赖sudo pip3 install django-crispy-forms django-formtools django-import-export django-r ...
- helm笔记
一.注意事项 1.values.yaml 中可以使用'#'号注释行,而/templates 下的文件不能用#号,如果要注释可以使用 {{/* context */}} 2.{{- #忽略 ...
- POST请求接口实列
通过响应状态来判断是否读取数据与抛出异常,然后通过判断获取的字节数去读取数据或抛出异常 /** * 发送HttpPost请求 * @param strURL * 服务地址 * @param param ...
- nginx 代理 websocket
nginx 代理 websocket nginx 首先确认版本必须是1.3以上 map指令的作用: 该作用主要是根据客户端请求中$http_upgrade 的值,来构造改变$connection_up ...
- 公用表表达式(CTE) with as
在编写T-SQL代码时,往往需要临时存储某些结果集.前面我们已经广泛使用和介绍了两种临时存储结果集的方法:临时表和表变量.除此之外,还可以使用公用表表达式的方法.公用表表达式(Common Table ...
- SQL进阶系列之2自连接
写在前面 一般地,SQL的连接运算根据其特征的不同,有着不同的名称,比如内连接.外连接.交叉连接等,这些连接大多是以不同的表或视图为对象进行的,针对相同的表进行的连接成为自连接.理解自连接有助于我们理 ...
- linux系统编程之进程(二)
今天继续学习进程相关的东东,上节提到了,当fork()之后,子进程复制了父进程当中的大部分数据,其中对于打开的文件,如果父进程打开了,子进程则不需要打开了,是共享的,所以首先先来研究下共享文件这一块的 ...