Python学习日记(四十) Mysql数据库篇 八
Mysql存储过程
存储过程是保存在Mysql上的一个别名(就是一堆SQL语句),使用别名就可以查到结果不用再去写SQL语句。存储过程用于替代程序员写SQL语句。
创建存储过程
delimiter //
CREATE PROCEDURE p1()
BEGIN
SELECT * FROM studenttable;
INSERT INTO teachertable(tname) VALUES('陈晨');
END //
delimiter ;
当我们写完这段代码并执行,再去调用p1()就可以直接执行里面的查询
call p1();
执行结果:
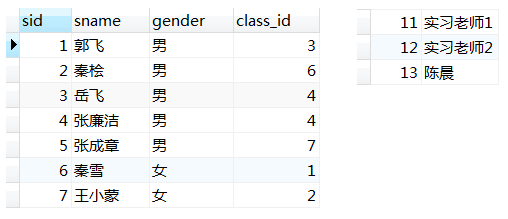
这样的好处能让功能代码都整合到一块且不用再去写SQL语句,不好之处在于如果要改数据库中的资料,那不一定能从存储过程中能拿到数据。
在公司处理数据时选用的方式:
方式一:
Mysql(DBA):存储过程
程序(程序员):调用存储过程
方式二:
Mysql:什么都不做
程序:写SQL语句
方式三:
Mysql:什么都不做
程序:类和对象(本质就是SQL语句 )
通过Python中的pymysql模块拿到p1的数据:
import pymysql
conn = pymysql.connect(host = 'localhost',user = 'root',password = '',database = 'db2',charset = 'utf8')
cursor = conn.cursor()
cursor.callproc('p1')
conn.commit()
result = cursor.fetchall()
print(result)
cursor.close()
conn.close()
传参数in
in表示传入一个值
delimiter //
CREATE PROCEDURE p2(
IN pid INT,
IN pnumber INT
)
BEGIN
SELECT * FROM scoretable WHERE student_id > pid AND number > pnumber;
END //
delimiter ;
呼叫执行过程p2并带入参数
call p2(15,90);
这样就能找到大于学生ID15并且分数大于90 的学生成绩
利用pymysql执行达到相同效果:
cursor.callproc('p2',(15,80))
传参数out
out伪造了一个返回值,主要用于表示存储过程的执行结果
delimiter //
create procedure p3(
in pid int,
out pnumber int
)
begin
set pnumber = 80;
select student_id from scoretable where student_id > pid and number > pnumber group by student_id;
end //
delimiter ;
呼叫执行过程p3并带入参数
set @pn = 80;
call p3(20,@pn);
select @pn;
在pymysql中执行
import pymysql
conn = pymysql.connect(host = 'localhost',user = 'root',password = '',database = 'db2',charset = 'utf8')
cursor = conn.cursor() cursor.callproc('p3',(15,80))
r1 = cursor.fetchall()
print(r1) cursor.execute('select @_p3_0,@_p3_1') #返回前面写的这两个参数15 80
r2 = cursor.fetchall()
print(r2) cursor.close()
conn.close()
传参数inout
结合in和out两种特性
事务
比方说双方进行一笔交易,但出现某种错误,一方支付了钱另一方没有收到,就可以通过事务回滚到最初的状态
delimiter //
create procedure p4(
out p_status tinyint -- 状态变量,用于判断是否出现执行异常
)
begin
declare exit handler for sqlexception -- 执行出现异常的代码
begin
set p_status = 1; -- 1表示出现异常
rollback; -- 将事务回滚
end ; start transaction; -- 开始事务
select student_id from scoretable group by student_id;
insert into scoretable(student_id,course_id,number) values(25,3,78);
commit; -- 结束事务
set p_status = 2; -- 2表示没有出现异常
end //
delimiter ;
游标
游标的性能虽然不高但是能实现循环的效果,对于每一行数据要进行分开计算的时候我们才需要用到游标
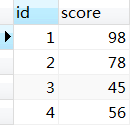
先创建两个表t2、t3,然后实现t3中每行score的值等于每行t2中id+score的值
t2:
t3:
存储过程代码:
delimiter //
create procedure p5()
begin
declare p_id int;
declare p_score int;
declare done int default false;
declare temp int; declare my_cursor cursor for select id,score from t2;
declare continue handler for not found set done = true; open my_cursor;
p_l:loop
fetch my_cursor into p_id,p_score;
if done then
leave p_l;
end if;
set temp = p_id + p_score;
insert into t3(score) values(temp);
end loop p_l;
close my_cursor;
end //
delimiter ;
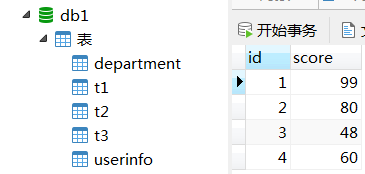
执行p5:
call p5();
结果:
动态执行SQL(防SQL注入)
delimiter //
create procedure p7(
in arg int
)
-- 预检测SQL语句是否具有合法性
begin
set @ppp = arg;
prepare prod from 'select * from studenttable where sid > ?';
execute prod using @ppp;
deallocate prepare prod;
end //
delimiter ;
call p7(15)
Python学习日记(四十) Mysql数据库篇 八的更多相关文章
- Python学习日记(四十一) Mysql数据库篇 九
前言 索引的主要作用是起到约束和加速查找,ORM框架(sqlalchemy)是用类和对象对数据库进行操作 索引的种类 按种类去分 1.普通索引:能够加速查找 2.主键索引:能够加速查找.不能为空.不能 ...
- Python学习日记(三十三) Mysql数据库篇 一
背景 Mysql是一个关系型数据库,由瑞典Mysql AB开发,目前属于Oracle旗下的产品.Mysql是目前最流行的关系型数据库管理系统之一,在WEB方面,Mysql是最好的RDBMS(Relat ...
- Python学习日记(三十七) Mysql数据库篇 五
pymsql的使用 初识pymysql模块 先在数据库中创建一个用户信息表,里面包含用户的ID.用户名.密码 create table userinfo( uid int not null auto_ ...
- Python学习日记(四十二) Mysql数据库篇 十
前言 当我们自己去写SQL代码的时候有时候会因为不熟练会导致效率低,再之后要进行许多的优化,并且操作也较为繁琐.因此ORM框架就能够解决上面的问题,它能根据自身的一些规则来帮助开发者去生成SQL代码. ...
- python学习笔记之——操作mysql数据库
Python 标准数据库接口为 Python DB-API,Python DB-API为开发人员提供了数据库应用编程接口. Python 数据库接口支持非常多的数据库,你可以选择适合你项目的数据库: ...
- Python学习笔记9-Python 链接MySql数据库
Python 链接MySql数据库,方法很简单: 首先需要先 安装一个MySql链接插件:MySQL-python-1.2.3.win-amd64-py2.7.exe 下载地址:http://dev. ...
- Python学习日记(三十六) Mysql数据库篇 四
MySQL作业分析 五张表的增删改查: 完成所有表的关系创建 创建教师表(tid为这张表教师ID,tname为这张表教师的姓名) create table teacherTable( tid int ...
- Python学习日记(三十四) Mysql数据库篇 二
外键(Foreign Key) 如果今天有一张表上面有很多职务的信息 我们可以通过使用外键的方式去将两张表产生关联 这样的好处能够节省空间,比方说你今天的职务名称很长,在一张表中就要重复的去写这个职务 ...
- Python学习日记(三十八) Mysql数据库篇 六
Mysql视图 假设执行100条SQL语句时,里面都存在一条相同的语句,那我们可以把这条语句单独拿出来变成一个'临时表',也就是视图可以用来查询. 创建视图: CREATE VIEW passtvie ...
随机推荐
- USACO Score Inflation
洛谷 P2722 总分 Score Inflation https://www.luogu.org/problem/P2722 JDOJ 1697: Score Inflation https://n ...
- 手机日期控件mobiscroll
query Mobiscroll是一个用于触摸设备(Android phones, iPhone, iPad, Galaxy Tab)的日期和时间选择器jQuery插件.以及各种滑动插件可以让用户很方 ...
- <Math> 50 367
50. Pow(x, n) abs (Integer.MIN_VALUE) > Integer.MAX_VALUE class Solution { public double myPow(do ...
- 【领会要领】web前端-轻量级框架应用(jQuery基础)
作者 | Jeskson 来源 | 达达前端小酒馆 jquery的安装和语法,jquery的多种选择器,dom操作和jquery事件. jQuery框架,简介,优势,安装,语法,jQuery选择器,i ...
- [LeetCode] 16. 3Sum Closest 最近三数之和
Given an array nums of n integers and an integer target, find three integers in nums such that the s ...
- .NetCore 使用k8s部署服务的过程中需要注意的地方以及遇到的问题
这里开始我准备了3台测试服务器,这里我使用了JumpServer管理起来了,这里我们来看下: Master :192.168.0.236 Node1:192.168.0.237 Node2:192.1 ...
- Azure Devops (VSTS) Extensions 开发小记
我在使用tfx-cli打包Azure Devops插件时,输出了很黄很黄很亮瞎眼的(尤其是在Visual Studio Code采用了Dark Black Theme的情况下)警告warning: P ...
- 雪花算法(snowflake)的JAVA实现
snowflake算法由twitter公司出品,原始版本是scala版,用于生成分布式ID,结构图: 算法描述: 最高位是符号位,始终为0,不可用. 41位的时间序列,精确到毫秒级,41位的长度可以使 ...
- python 根据文件的编码格式读取文件
因为各种文件的不同格式,导致导致文件打开失败,这时,我们可以先判断文件的编码吗格式,然后再根据文件的编码格式进行读取文件 举例:有一个data.txt文件,我们不知道它的编码格式,现在我们需要读取文件 ...
- 【MySQL】Mariadb安装
Mariadb安装 1.解压 [root@oradb bin]# tar zxvf mariadb-10.3.18-linux-x86_64.tar.gz [root@oradb bin]# mv m ...