bert剪枝系列——Are Sixteen Heads Really Better than One?
1,概述
剪枝可以分为两种:一种是无序的剪枝,比如将权重中一些值置为0,这种也称为稀疏化,在实际的应用上这种剪枝基本没有意义,因为它只能压缩模型的大小,但很多时候做不到模型推断加速,而在当今的移动设备上更多的关注的是系统的实时相应,也就是模型的推断速度。另一种是结构化的剪枝,比如卷积中对channel的剪枝,这种不仅可以降低模型的大小,还可以提升模型的推断速度。剪枝之前在卷积上应用较多,而随着bert之类的预训练模型的出现,这一类模型通常比较大,且推断速度较慢。例如bert在文本分类的任务上,128的序列长度,其推断速度都只有80ms左右,这还只是单个模型,而一个大的系统,往往是有多个模型组成的。因此bert要想在工业界,尤其是移动端落地,是极度需要模型压缩的。
2,具体方法
看完这篇论文之后,更多的感觉是这篇论文并没有在剪枝上有太多的贡献,更像是对multi head中head的数量做了一个实验性的工作,探索了在multi head中并不是所有的head都需要,有很多head提取的信息对最终的结果并没有什么影响,是冗余存在的。
本论文在探讨在test阶段,去掉一部分head是否会影响模型的性能,得到的结论是大多数都不会,而且部分还会提升性能,作者给出了三种实验方法来证明这一点:
1,每次去掉一层中一个head,测试模型的性能
2,每次去掉一层中剩余的层,只保存一个head,测试模型的性能
3,通过梯度来判断每个head的重要性,然后去掉一部分不重要的head,测试模型的性能
为了实现上述的实验,作者对multi head的计算做了一些修改,修改后的公式如下:
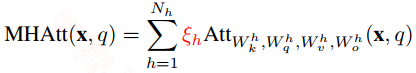
在这里引入了一个系数$\zeta_h$,该值的取值为0或1,它的作用是用来mask不重要的head。在训练时保持为1,到test的时候对部分head mask掉。
作者在基于transformer的机器翻译模型上和基于bert的NLI任务上做了实验,我们来看看上面三个实验的结果
Ablating One Head
去掉一个head,作者给出了实验结果如下:
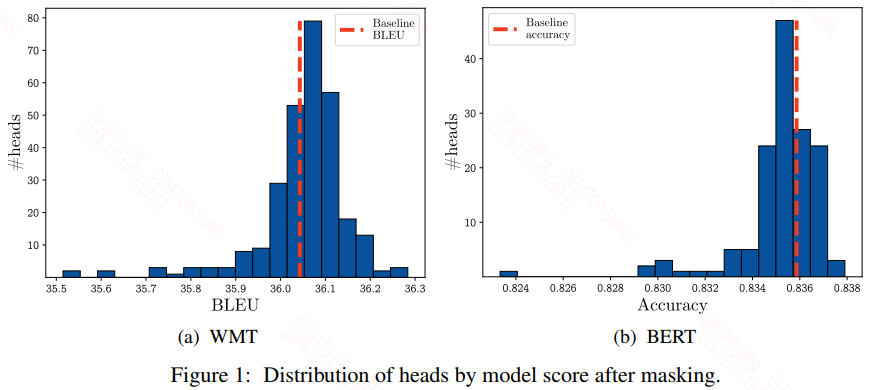
从上面的图中可以看到大多数head去掉之后的模型分数还基本分布在baseline附近,从作者给的表格数据看会更加的清晰:
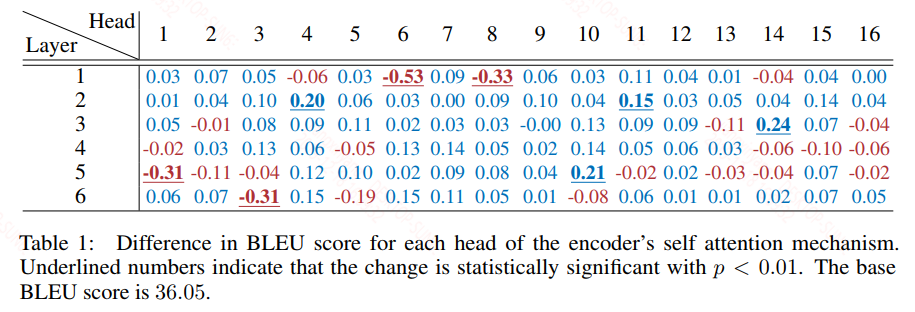
上面给出的是机器翻译的表格数据,蓝色的值表示性能增加,红色的值表示性能下降,大多数情况下性能是增加的,只有少部分性能会有所下降,只有极少部分性能会下降的比较多。
Ablating All Heads but One
当去掉一层中的其余head只保留一个head时,我们来看下模型的结果,这回作者给出了一个离散图:
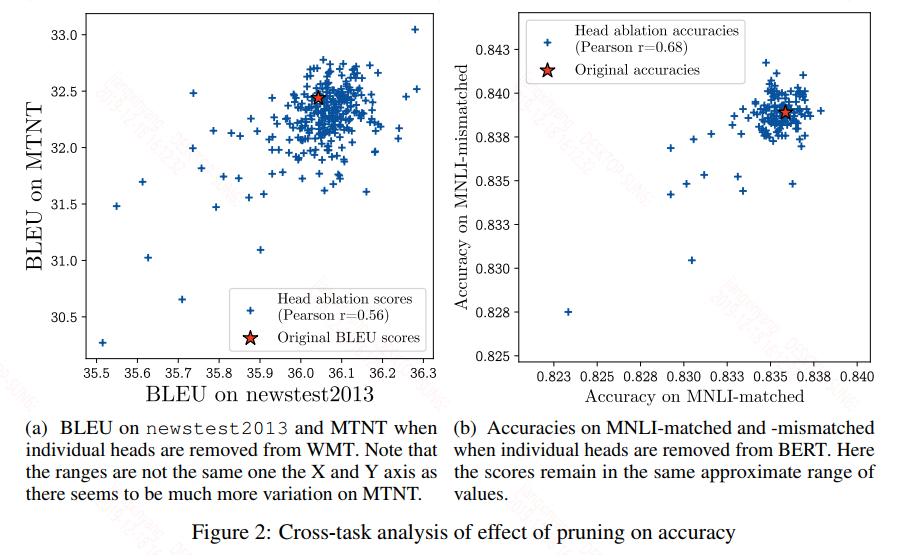
同样的,大多数情况下的性能都分布在baseline附近,同样看看表格会更清晰:

从上面来看除了机器翻译中的encoder-decoder之间的attention的最后一层会出现性能明显的下降,其他大多数情况都还好,甚至有的情况下性能反而上升。
上面两种实验都有一个共同的弊端,就是每次实验只能对一层做head的mask,但实际过程中所有层的head都有可能会被去除,且至于去除哪些还和层与层之间的依赖性有关,因此第三种方法可以来改善这个问题。
Head Importance Score for Pruning
在这里作者引入了梯度来衡量head的重要性,首先给出一个公式如下:
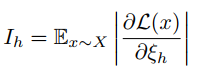
上面公式是对mask系数的偏导,我们知道偏导的值的大小可以衡量这个维度上对损失的影响大小,在这里作者对偏导取了个绝对值,避免在求期望的时候正负抵消,因为无论是正值还是负值,只要绝对值比较大,就可以衡量偏导对损失的影响是比较大的,这里的期望是对所有样本X的,因为单个batch是存在误差的,因此对全量样本计算的偏导求均值。
对上面的公式做一个链式转换,可以得到:

这样我们就可以用这个对head的期望梯度值来衡量其重要性,然后按百分比去除head,得到的结果如下:
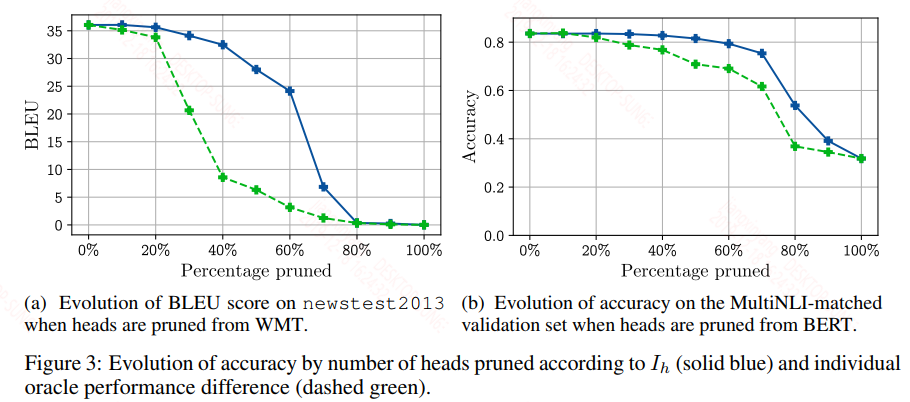
上面图中的实验是通过梯度来进行剪枝的,虚线是通过第一种方法中的分数来衡量head的重要性进行剪枝的,可以看到基于梯度的效果还是很明显的,但是剪枝范围也是有限的,超过这个范围之后,性能会急剧下降。
作者还测了下剪枝后模型的推断速度,个人感觉这个推断速度的减小真的是毫无意义:

如上图所示,只有在batch达到16的时候才有比较明显的速度提升,但是大多数线上运行的时候都是batch为1的。不过也不能就此下定论说减少head的数量是起不到加速效果的,个人感觉作者在这里测推断速度的时候是存在一些问题的:作者是先训练,后剪枝,但剪枝之后没有再训练,这也就意味着这些head仍然存在,只是将不需要的head前面的mask系数置为0而已。为什么做出这样的认定呢?因为在实际的multi head设计中,我们是要保证每个head得到的词向量拼接在一起等于原始的词向量,因为后面要进入到前向层,必须保持维度一致,我猜这里作者可能是将mask掉的head得到的向量置为0,这样这些值在下一层计算self-attention就没有意义了,至于为什么还是有加速,原因不明。以上个人猜测。
此外单纯得减少head的数量好像对加速意义不大,只有配合减小embedding size才有意义,否则计算复杂度基本一致,因为我们在做multi-attention时映射到不同子空间时,实际上是一个大的矩阵映射,这个大的矩阵的维度取决于embedding size,映射完之后再分割成多个而已。从计算上来看self-attention是耗时的,因为减少embedding size,减小序列长度都可以极大的提速(减小序列长度还会影响到前向层的速度)。
bert剪枝系列——Are Sixteen Heads Really Better than One?的更多相关文章
- Bert不完全手册6. Bert在中文领域的尝试 Bert-WWM & MacBert & ChineseBert
一章我们来聊聊在中文领域都有哪些预训练模型的改良方案.Bert-WWM,MacBert,ChineseBert主要从3个方向在预训练中补充中文文本的信息:词粒度信息,中文笔画信息,拼音信息.与其说是推 ...
- Transformer模型---decoder
一.结构 1.编码器 Transformer模型---encoder - nxf_rabbit75 - 博客园 2.解码器 (1)第一个子层也是一个多头自注意力multi-head self-atte ...
- Bert系列(二)——源码解读之模型主体
本篇文章主要是解读模型主体代码modeling.py.在阅读这篇文章之前希望读者们对bert的相关理论有一定的了解,尤其是transformer的结构原理,网上的资料很多,本文内容对原理部分就不做过多 ...
- 就是要你明白机器学习系列--决策树算法之悲观剪枝算法(PEP)
前言 在机器学习经典算法中,决策树算法的重要性想必大家都是知道的.不管是ID3算法还是比如C4.5算法等等,都面临一个问题,就是通过直接生成的完全决策树对于训练样本来说是“过度拟合”的,说白了是太精确 ...
- acdream 小晴天老师系列——晴天的后花园 (暴力+剪枝)
小晴天老师系列——晴天的后花园 Time Limit: 10000/5000MS (Java/Others) Memory Limit: 128000/64000KB (Java/Others) ...
- Bert系列 源码解读 四 篇章
Bert系列(一)——demo运行 Bert系列(二)——模型主体源码解读 Bert系列(三)——源码解读之Pre-trainBert系列(四)——源码解读之Fine-tune 转载自: https: ...
- bert系列二:《BERT》论文解读
论文<BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding> 以下陆续介绍ber ...
- Bert系列(三)——源码解读之Pre-train
https://www.jianshu.com/p/22e462f01d8c pre-train是迁移学习的基础,虽然Google已经发布了各种预训练好的模型,而且因为资源消耗巨大,自己再预训练也不现 ...
- 广告行业中那些趣事系列6:BERT线上化ALBERT优化原理及项目实践(附github)
摘要:BERT因为效果好和适用范围广两大优点,所以在NLP领域具有里程碑意义.实际项目中主要使用BERT来做文本分类任务,其实就是给文本打标签.因为原生态BERT预训练模型动辄几百兆甚至上千兆的大小, ...
随机推荐
- alertmanager
alertmanager主要用于接收prometheus发送的告警信息: wget下载,解压, 配置alertmanager.yml,内容如下: 在prometheus文件下添加rules.yml内容 ...
- destoon模块绑定二级域名出现 File not found解决办法
昨天晚上帮一个朋友给我说他绑定模块二级域名出现 File not found,所以今天分享关于解决办法. 模块启用二级域名后,首页打开正常,但是点内容页和列表页出现File not found. 解决 ...
- angular的Hash 模式和 HTML 5 模式
去除地址 # ,将{ provide: LocationStrategy, useClass: HashLocationStrategy }改为 { provide: LocationStrategy ...
- Django Form 内置字段
常用字段: Field required=True, 是否允许为空 widget=None, HTML插件 label=None, 用于生成Label标签或显示内容 initial=None, 初始值 ...
- 【洛谷3515】[POI2011] Lightning Conductor(决策单调性)
点此看题面 大致题意: 给你一个序列,对于每个\(i\)求最小的自然数\(p\)使得对于任意\(j\)满足\(a_j\le a_i+p-\sqrt{|i-j|}\). 证明单调性 考虑到\(\sqrt ...
- PMP图表(必背)
- GC(二)CMS
什么是CMS CMS全称 Concurrent Mark Sweep,是一款并发的.使用标记-清除算法的垃圾回收器, 使用场景 GC过程短暂停,适合对时延要求较高的服务,用户线程不允许长时间的停顿. ...
- Uboot启动流程分析(一)
1.前言 Linux系统的启动需要一个bootloader程序,该bootloader程序会先初始化DDR等外设,然后将Linux内核从flash中拷贝到DDR中,最后启动Linux内核,uboot的 ...
- 修改 Oracle 数据库实例字符集
Ø 简介 在 Oracle 中创建数据库实例后,就会有对应使用的编码字符集.当我们设置的字符集与操作系统或者其他软件字符集不一致时,就会出现个字符长度存储一个汉字. 2. SIMPLIFIED ...
- 生成 Visual Studio 中的代码的文档生成神器
当我们在团队开发中的时候,经常要给别人提供文档,有了这个工具,设置一下,一键生成.前提是你要写好xml注释. 这也是开源项目: https://sandcastle.codeplex.com/ 它就是 ...