11、spark内核架构剖析与宽窄依赖
一、内核剖析
1、内核模块
1、Application
2、spark-submit
3、Driver
4、SparkContext
5、Master
6、Worker
7、Executor
8、Job
9、DAGScheduler
10、TaskScheduler
11、ShuffleMapTask and ResultTask
2、图解
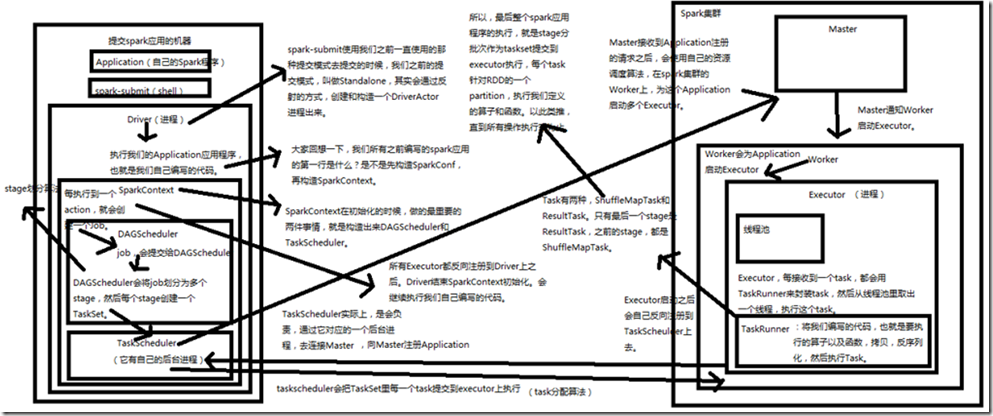
自己编写的Application,就是我们自己写的程序,拷贝到用来提交spark应用的机器,使用spark-submit提交这个Application,提交之后,spark-submit在Standalone模式下会通过反射的方式,创建和构造一个DriverActor进程。 启动DriverActor进程后,开始执行Application应用程序,也就是我们自己编写的代码,第一件事就是构造SparkContext,这时,会初始化DAGScheduler和TaskScheduler,
构造完TaskScheduler后,TaskScheduler实际上,是会负责,通过一个后台进程,去连接Master,向Master注册Application; Master接收到Application注册的请求之后,会使用自己的资源调度算法,在Spark集群的Wroker上,为这个Application启动多个Executor,Master通知Wroker启动Executor; Executor启动之后,会自动反向注册到TaskScheduler上去,所有Executor都反向注册到Driver上之后,Driver结束SparkContext初始化,会继续执行我们自己编写的代码
每执行到一个Action,就会创造一个job,job会提交给DAGScheduler; DAGScheduler会将多个job划分为多个stage(stage划分算法),然后每个stage创建一个TaskSet,TaskSet会给TaskScheduler,TaskScheduler会把TaskSet里每一个task提交到Executor上执行(task分配算法); Task有两种,ShuffleMapTask和ResultTask,只有最后一个stage是ResultTask,之前的stage,都是ShuffleMapTask; Executor每接收到一个task,都会用TaskRunner来封装task,然后从线程池里取出一个线程,执行这个task; TaskRunner,将我们编写的代码,也就是要执行的算子以及函数,拷贝,反序列化,然后执行task。 所以,最后整个Spark应用程序的执行,就是stage分批次作为taskset提交到Executor执行,每个task针对RDD的一个partition,执行我们定义的算子和函数,依次类推,直到所有操作完为止;
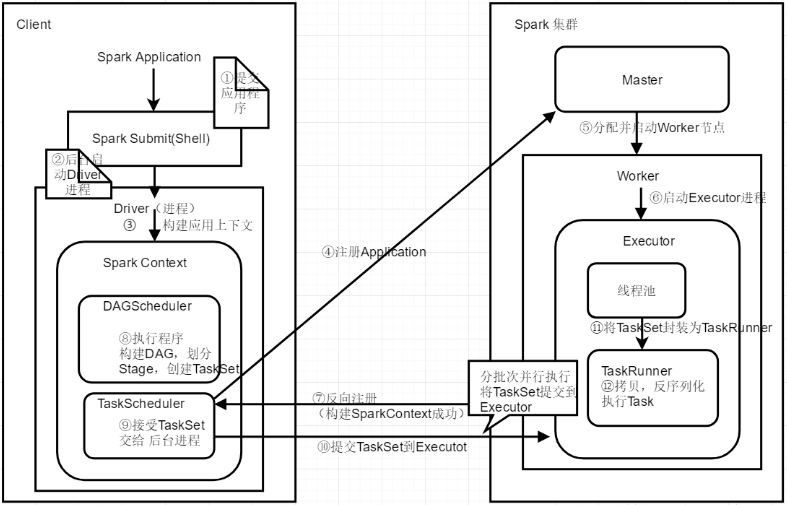
1、首先是提交打包的应用程序,使用Spark submit或者spark shell工具执行。 2、提交应用程序后后台会在后台启动Driver进程(注意:这里的Driver是在Client上启动,如果使用cluster模式提交任务,
Driver进程会在Worker节点启动)。 3、开始构建Spark应用上下文。一般的一个Spark应用程序都会先创建一个Sparkconf,然后来创建SparkContext。如下代码所示:
val conf=new SparkConf() val sc=new SparkContext(conf)。在创建SparkContext对象时有两个重要的对象,DAGScheduler和TaskScheduler(具体作用后面会详细讲解)。 4、构建好TaskScheduler后,它对应着一个后台进程,接着它会去连接Master集群,向Master集群注册Application。 5、Master节点接收到应用程序之后,会向该Application分配资源,启动一个或者多个Worker节点。 6、每一个Worker节点会为该应用启动一个Executor进程来执行该应用程序。 7、向Master节点注册应用之后,master为应用分配了节点资源,在Worker启动Executor完成之后,此时,Executo会向TaskScheduler反向注册,以让它知道Master为应用
程序分配了哪几台Worker节点和Executor进程来执行任务。到此时为止,整个SparkContext创建完成。 8、创建好SparkContext之后,继续执行我们的应用程序,每执行一个action操作就创建为一个job,将job交给DAGScheduler执行,然后DAGScheduler会将多个job划
分为stage(这里涉及到stage的划分算法,比较复杂)。然后每一个stage创建一个TaskSet。 9、实际上TaskScheduler有自己的后台进程会处理创建好的TaskSet。 10、然后就会将TaskSet中的每一个task提交到Executor上去执行。(这里也涉及到task分配算法,提交到哪几个worker节点的executor中去执行)。 11、Executor会创建一个线程池,当executor接收到一个任务时就从线程池中拿出来一个线程将Task封装为一个TaskRunner。 12、在TaskRunner中会将我们程序的拷贝,反序列化等操作,然后执行每一个Task。对于这个Task一般有两种,ShufflerMapTask和ResultTask,只有最后一个stage的task
是ResultTask,其它的都是ShufflerMapTask。 13、最后会执行完所有的应用程序,将stage的每一个task分批次提交到executor中去执行,每一个Task针对一个RDD的partition,执行我们定义的算子和函数,直到全部
执行完成。
二、宽窄依赖
1、Wordcount图解

2、宽窄依赖
宽依赖(Shuffle Dependency),就是Shuffle,每一个父RDD的partition中的数据,都可能会传输一部分到下一个RDD的每个partition中,此时就会出现,父RDD和子RDD的partition之间,具有交互错综复杂的关系,
那么,这种情况,就叫做两个RDD之间是宽依赖,同时,他们之间发生的操作,是Shuffle;
窄依赖(Narrow Dependency),一个RDD,对它的父RDD,只有简单的一对一依赖关系,也就是说,RDD的每个partition,仅仅依赖于父RDD中的一个partition,父RDD和子RDD的partition之间的对应关系是一对一的
这种情况下,是简单的RDD之间的依赖关系,也被称之为窄依赖;
11、spark内核架构剖析与宽窄依赖的更多相关文章
- SQLServer内核架构剖析 (转载)
SQL Server内核架构剖析 (转载) 这篇文章在我电脑里好长时间了,今天不小心给翻出来了,觉得写得很不错,因此贴出来共享. 不得不承认的是,一个优秀的软件是一步一步脚踏实地积累起来的,众多优秀的 ...
- Spark RDD基本概念、宽窄依赖、转换行为操作
目录 RDD概述 RDD的内部代码 案例 小总结 转换.行动算子 宽.窄依赖 Reference 本文介绍一下rdd的基本属性概念.rdd的转换/行动操作.rdd的宽/窄依赖. RDD:Resilie ...
- [转载]SQL Server内核架构剖析
原文链接:http://www.sqlserver.com.cn 我们做管理软件的,主要核心就在数据存储管理上.所以数据库设计是我们的重中之重.为了让我们的管理软件能够稳定.可扩展.性能优秀.可跟踪排 ...
- SQLSERVER内核架构剖析 (转)
我们做管理软件的,主要核心就在数据存储管理上.所以数据库设计是我们的重中之重.为了让我们的管理软件能够稳定.可扩展.性能优秀.可跟踪排错. 可升级部署.可插件运行,我们往往研发自己的管理软件开发平台. ...
- 小记--------spark内核架构原理分析
首先会将jar包上传到机器(服务器上) 1.在这台机器上会产生一个Application(也就是自己的spark程序) 2.然后通过spark-submit(shell) 提交程序 ...
- SQL Server内核架构剖析与NUMA
http://www.cnblogs.com/lyhabc/p/4272053.html http://www.cnblogs.com/lyhabc/archive/2013/02/05/289247 ...
- Spark- Spark内核架构原理和Spark架构深度剖析
Spark内核架构原理 1.Driver 选spark节点之一,提交我们编写的spark程序,开启一个Driver进程,执行我们的Application应用程序,也就是我们自己编写的代码.Driver ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- Spark运行时的内核架构以及架构思考
一: Spark内核架构 1,Drive是运行程序的时候有main方法,并且会创建SparkContext对象,是程序运行调度的中心,向Master注册程序,然后Master分配资源. 应用程序: A ...
随机推荐
- COCOeval接口使用
COCOeval类简介 class COCOeval: # Interface for evaluating detection on the Microsoft COCO dataset. # # ...
- 如何为非常不确定的行为(如并发)设计安全的 API,使用这些 API 时如何确保安全
原文:如何为非常不确定的行为(如并发)设计安全的 API,使用这些 API 时如何确保安全 .NET 中提供了一些线程安全的类型,如 ConcurrentDictionary<TKey, TVa ...
- NIO开发Http服务器(3):核心配置和Request封装
最近学习了Java NIO技术,觉得不能再去写一些Hello World的学习demo了,而且也不想再像学习IO时那样编写一个控制台(或者带界面)聊天室.我们是做WEB开发的,整天围着tomcat.n ...
- 【转载】Java对象的生命周期
Java对象的生命周期 在Java中,对象的生命周期包括以下几个阶段: 1. 创建阶段(Created) 2. 应用阶段(In Use) 3. 不可见阶段(Invisib ...
- 基于【 springBoot +springCloud+vue 项目】一 || 后端搭建
缘起 本项目是基于之前学习的一个Dubbo+SSM分布式项目进行升级,基于此项目对前后端分离项目.微服务项目进一步深入学习.之前学习了vue.springBoot.springCloud后,没有进行更 ...
- js数据类型及判断数据类型
众所周知,js有7种数据类型 1. null 2. undefined 3. boolean 4. number 5. string 6. 引用类型(object.array.function) 7. ...
- [LeetCode] 72. 编辑距离 ☆☆☆☆☆(动态规划)
https://leetcode-cn.com/problems/edit-distance/solution/bian-ji-ju-chi-mian-shi-ti-xiang-jie-by-labu ...
- Git-fatal:remote error:You can't push to git://github.com/username/*.git use https:
注意不是git://github.com/cs942651107/TestCode.git 一个:一个@协议不一样,:的不能push 关联远程库git remote add origin git ...
- SQL Server 字段提取拼音首字母
目前工作中遇到一个情况,需要将SQL Server中的一个字段提取拼音的首字母,字段由汉字.英文.数字以及“-”构成,百度了一堆,找到如下方法,记录一下,以备后用! 首先建立一个函数 --生成拼音首码 ...
- Android自动化测试探索(一)adb详细介绍
adb详细介绍 #1. 基本简介 adb,即Android Debug Bridge,它是Android开发/测试人员不可替代的强大工具 #2. Mac上安装adb 安装brew /usr/bin/r ...