Spark实现分组TopN
一.概述
在许多数据中,都存在类别的数据,在一些功能中需要根据类别分别获取前几或后几的数据,用于数据可视化或异常数据预警。在这种情况下,实现分组TopN就显得非常重要了,因此,使用了Spark聚合函数和排序算法实现了分布式TopN计算功能。
二.代码实现
package scala
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* 计算分组topN
* Created by Administrator on 2019/11/20.
*/
object GroupTopN {
Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别
def main(args: Array[String]) {
//创建测试数据
val test_data = Array("CJ20191120,201911", "CJ20191120,201910", "CJ20191105,201910", "CJ20191105,201909", "CJ20191111,201910")
val spark = SparkSession.builder().appName("GroupTopN").master("local[2]").getOrCreate()
val sc = spark.sparkContext
val test_data_rdd = sc.parallelize(test_data).map(row => {
val Array(scene, cycle) = row.split(",")
Row(scene, cycle)
})
// 设置数据模式
val structType = StructType(Array(
StructField("scene", StringType, true),
StructField("cycle", StringType, true)
))
// 转换为df
val test_data_df = spark.createDataFrame(test_data_rdd, structType)
test_data_df.createOrReplaceTempView("test_data_df")
// 拼接周期
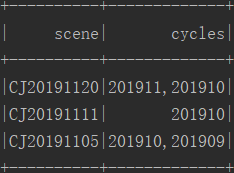
val scene_ws = spark.sql("select scene,concat_ws(',',collect_set(cycle)) as cycles from test_data_df group by scene")
scene_ws.count()
scene_ws.show()
scene_ws.createOrReplaceTempView("scene_ws")
/**
* 定义参数确定N的大小,暂定为1
*/
val sum = 1
// 创建广播变量,把N的大小广播出去
val broadcast = sc.broadcast(sum)
/**
* 定义Udf实现获取组内的前N个数据
*/
spark.udf.register("getTopN", (cycles : String) => {
val sum = broadcast.value
var mid = ""
if(cycles.contains(",")){ // 多值
val cycle = cycles.split(",").sorted.reverse // 降序排序
val min = Math.min(cycle.length, sum)
for(i <- 0 until min){
if(mid.equals("")){
mid = cycle(i)
}else{
mid += "," + cycle(i)
}
}
}else{ // 单值
mid = cycles
}
mid
})
val result = spark.sql("select scene,getTopN(cycles) cycles from scene_ws")
result.show()
spark.stop()
}
}
三.结果

四.备注
当N大于1时,多个数据会拼接在一起,若想每个一行,可是使用使用列转行功能,参考我的博客:https://www.cnblogs.com/yszd/p/11266552.html
Spark实现分组TopN的更多相关文章
- 020 Spark中分组后的TopN,以及Spark的优化(重点)
一:准备 1.源数据 2.上传数据 二:TopN程序编码 1.程序 package com.ibeifeng.bigdata.spark.core import java.util.concurren ...
- 大数据学习day29-----spark09-------1. 练习: 统计店铺按月份的销售额和累计到该月的总销售额(SQL, DSL,RDD) 2. 分组topN的实现(row_number(), rank(), dense_rank()方法的区别)3. spark自定义函数-UDF
1. 练习 数据: (1)需求1:统计有过连续3天以上销售的店铺有哪些,并且计算出连续三天以上的销售额 第一步:将每天的金额求和(同一天可能会有多个订单) SELECT sid,dt,SUM(mone ...
- QL查询案例:取得分组 TOP-N
[转]SQL查询案例:取得分组 TOP-N CREATE TABLE TopnTest ( name VARCHAR(10), --姓名 procDate DATETIME, ...
- 用Spark完成复杂TopN计算的两种逻辑
如果有商品品类的数据pairRDD(categoryId,clickCount_orderCount_payCount),用Spark完成Top5,你会怎么做? 这里假设使用Java语言进行编写,那么 ...
- 取分组TOPN好理解案例
- 分别使用Hadoop和Spark实现TopN(1)——唯一键
0.简介 TopN算法是一个经典的算法,由于每个map都只是实现了本地的TopN算法,而假设map有M个,在归约的阶段只有M x N个,这个结果是可以接受的并不会造成性能瓶颈. 这个TopN算法在ma ...
- TopN问题(分别使用Hadoop和Spark实现)
简介 TopN算法是一个经典的算法,由于每个map都只是实现了本地的TopN算法,而假设map有M个,在归约的阶段只有M x N个,这个结果是可以接受的并不会造成性能瓶颈. 这个TopN算法在map阶 ...
- spark面试总结3
Spark core面试篇03 1.Spark使用parquet文件存储格式能带来哪些好处? 1) 如果说HDFS 是大数据时代分布式文件系统首选标准,那么parquet则是整个大数据时代文件存储格式 ...
- Spark面试相关
Spark Core面试篇01 随着Spark技术在企业中应用越来越广泛,Spark成为大数据开发必须掌握的技能.前期分享了很多关于Spark的学习视频和文章,为了进一步巩固和掌握Spark,在原有s ...
随机推荐
- day4_变量和作用域
全局变量与局部变量: 全局变量: 定义变量时,变量左边没有缩进,就是全局变量,可以被当前py文件的任何地方给引用 局部变量: 有缩进的变量就是局部变量 函数的作用域: def test1(): age ...
- VMware虚拟机安装使用及系统安装教程
虚拟机是利用软件来模拟出完整计算机系统的工具.具有完整硬件系统功能的.运行在一个完全隔离环境中.虚拟机的使用范围很广,如未知软件评测.运行可疑型工具等,即使这些程序中带有病毒,它能做到的只有破坏您的虚 ...
- 学习:逆向PUSH越界/INT 68/反调试导致的程序
自己根据shark恒老师的分析,总结一下: 一般反调试自动关闭程序利用的函数有: 1.CreateToolhelp32Snapshot 2.FindWindow 3.ExitProcess 4.Pos ...
- Linux学习笔记-第6天 - 问题的根本
这些知识其实看起来很简单,之前不管是在学习C语言还是bat批处理,类似结构早已熟知. 但其实运用起来并不算好,可能真正的原因还 是在于得多练习吧.希望明年的今天自己不要再纠结与这些基础性的知识.
- NLP之预训练
内容是结合:https://zhuanlan.zhihu.com/p/49271699 可以直接看原文 预训练一般要从图像处理领域说起:可以先用某个训练集合比如训练集合A或者训练集合B对这个网络进行预 ...
- Python爬虫爬取数据的步骤
爬虫: 网络爬虫是捜索引擎抓取系统(Baidu.Google等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 步骤: 第一步:获取网页链接 1.观察需要爬取的多 ...
- Linux性能优化实战学习笔记:第四十六讲
一.上节回顾 不知不觉,我们已经学完了整个专栏的四大基础模块,即 CPU.内存.文件系统和磁盘 I/O.以及网络的性能分析和优化.相信你已经掌握了这些基础模块的基本分析.定位思路,并熟悉了相关的优化方 ...
- [LeetCode] 885. Spiral Matrix III 螺旋矩阵之三
On a 2 dimensional grid with R rows and C columns, we start at (r0, c0) facing east. Here, the north ...
- Docker笔记:常用服务安装——Nginx、MySql、Redis(转载)
转载地址:https://www.cnblogs.com/spec-dog/p/11320513.html 开发中经常需要安装一些常用的服务软件,如Nginx.MySql.Redis等,如果按照普通的 ...
- C#原型模式(深拷贝、浅拷贝)
原型模式就是用于创建重复的对象,当想要创建一个新的对象但是开销比较大或者想将对象的当前状态保存下来的时候,我们就可以使用原型模式. 创建原型 public abstract class Base { ...