生产环境OOM\死锁问题排查修复
OOM:
1.快速恢复业务:如果是集群中的一台机器故障,先隔离故障服务器;如果是多台,则根据Nginx转发策略,对该功能转发到单独的集群,与其他流量隔离,确保其他业务不受影响
2.收集内存溢出Dump文件:方式有两种:
1.设置JVM启动参数
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/opt/jvmdump
设置之后,在每次发生内存溢出时,JVM会自动将堆转储,dump文件存放在-XX:HeapDumpPath指定的路径下
2.使用jmap命令收集
通过jamp -dump:live,format=b,file=/opt/jvm/dump.hprof pid
3.分析dump文件:可以通过MAT(Memory Analyzer Tool)进行分析,使用MAT打开Dump文件后,首页截图如下:
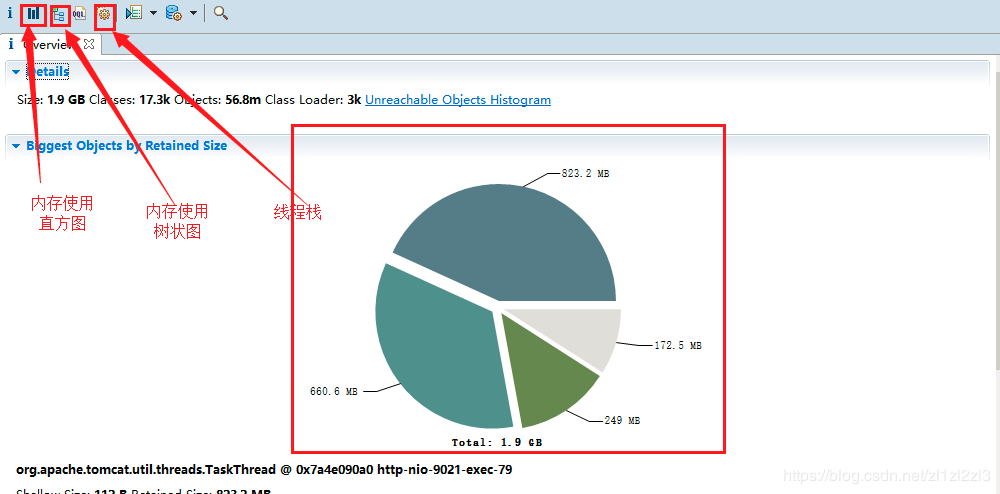
工具按钮介绍:
 :直方图视图,将堆中所有的内存消耗情况统计出来,其如图所示:
:直方图视图,将堆中所有的内存消耗情况统计出来,其如图所示:

 :内存使用树状结构,以线程为维度,树状形式展开,如图所示:
:内存使用树状结构,以线程为维度,树状形式展开,如图所示:

 线程栈,其截图如下:
线程栈,其截图如下:


根据该图,可以明确,堆的总大小为1.9G,被4个线程全部占据,导致其他线程无法再申请资源,抛出堆内存溢出错误。
接下来,我通常的做法是直接去看 这个视图(以线程为基本维度,查找线程中占用内存的对象),为后续定位排查提供必要的依据。
这个视图(以线程为基本维度,查找线程中占用内存的对象),为后续定位排查提供必要的依据。


从上面的截图中可以得出如下关键信息点:
org.apache.ibatis.executor.result.DefaultResultHandler内部持有一个List,其原始为java.util.HashMap,从这个类基本可以看出是与数据库的查询相关,对数据库返回结果的解码并组织成HashMap。
这个List中的元素总共有146033个,初步可以判断出是在一次查询中从数据库中一次查询出了太多数据,造成了内存溢出。
由于SQL查询代码中,是用HashMap来接收数据库中的返回字段,无法一时间看出是那个查询,那我们能不能精确找到是哪一个查询,哪一行代码,甚至与哪一条SQL语句呢?
答案是可以的,我们可以从 视图一探究竟。
视图一探究竟。
温馨提示:
视图使用技巧:展开技巧:沿着使用率最高的项一层一层进行展开,直至发现具体占用内存的对象。
接下来我们从 视图去寻找是哪个方法,哪条SQL语句触发的。
具体方法:首先完全展开一个线程,从展开图的底部向上寻找:
其线程的入口(控制层代码)

继续往上查找,要找到SQL语句,应该找到Mybatis处理结果集相关的类,如图所示:

然后展开boundSql即能找到SQL语句:

然后鼠标可以放在SQL属性中,右键,可以将SQL语句复制出来。

由于这里涉及到公司的代码机密,故在这里不贴出具体的SQL语句。
这里根据后面的分析,原来是在做导出功能的时候,没有使用分页对数据进行分页查询,分页写入Excel文件,而是一次将全部数据查询,导致导出功能如果并发数超过4个时,就会将所有内存耗尽。
解决方案:
首先在运维层面将该请求导入到指定的一台服务器上,是导出任务与其他任务进行隔离,避免对其他重要服务造成影响。
项目组对其代码进行修复,可以使用分页查数据,然后分配写入Excel。
死锁:
1.查看系统日志,找到对应的死锁方法:
org.springframework.dao.CannotAcquireLockException: could not execute statement; SQL [n/a]; nested exception is org.hibernate.exception.LockAcquisitionException: could not execute statement
at com.kuding.order.services.ChildOrderService.lambda$modifyChildOrderDeliverStatus$23(ChildOrderService.java:423)
at com.kuding.order.services.ChildOrderService.modifyChildOrderDeliverStatus(ChildOrderService.java:416)
at com.kuding.order.controllers.ChildOrderController.modifyDeliveringStatus(ChildOrderController.java:68)
at com.kuding.common.basestructure.filters.GeetestFilter.doFilter(GeetestFilter.java:102)
Caused by: org.hibernate.exception.LockAcquisitionException: could not execute statement
at com.kuding.common.basestructure.interfaces.daointerfacesv2.AbstractDao.create(AbstractDao.java:22)
Caused by: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction
2.在mysql中使用命令:SHOW ENGINE INNODB STATUS;总能获取到最近一些问题信息,通过搜索deadlock 关键字即可找到死锁的相关日志信息。
分析哪些语句申请锁资源冲突,结合1来确定对应的代码,通过使用分布式锁或者修改获取数据锁顺序来修复
生产环境OOM\死锁问题排查修复的更多相关文章
- 总结:利用asp.net core日志进行生产环境下的错误排查(asp.net core version 2.2,用IIS做服务器)
概述 调试asp.net core程序时,在输出窗口中,在输出来源选择“调试”或“xxx-ASP.NET Core Web服务器”时,可以看到类似“info:Microsoft.AspNetCore. ...
- 生产环境JAVA进程高CPU占用故障排查
问题描述:生产环境下的某台tomcat7服务器,在刚发布时的时候一切都很正常,在运行一段时间后就出现CPU占用很高的问题,基本上是负载一天比一天高. 问题分析:1,程序属于CPU密集型,和开发沟通过, ...
- 生产环境下JAVA进程高CPU占用故障排查
问题描述:生产环境下的某台tomcat7服务器,在刚发布时的时候一切都很正常,在运行一段时间后就出现CPU占用很高的问题,基本上是负载一天比一天高. 问题分析:1,程序属于CPU密集型,和开发沟通过, ...
- 使用Windbg找出死锁,解决生产环境中运行的软件不响应请求的问题
前言 本文介绍本人的一次使用Windbg分析dump文件找出死锁的过程,并重点介绍如何确定线程所等待的锁及判断是否出现了死锁. 对于如何安装及设置Windbg请参考:<使用Windbg和SoS扩 ...
- 生产环境下JAVA进程高CPU占用故障排查---temp
问题描述:生产环境下的某台tomcat7服务器,在刚发布时的时候一切都很正常,在运行一段时间后就出现CPU占用很高的问题,基本上是负载一天比一天高. 问题分析:1,程序属于CPU密集型,和开发沟通过, ...
- 生产环境部署springcloud微服务启动慢的问题排查
今天带来一个真实案例,虽然不是什么故障,但是希望对大家有所帮助. 一.问题现象: 生产环境部署springcloud应用,服务部署之后,有时候需要10几分钟才能启动成功,在开发测试环境则没有这个问题. ...
- 生产出现oom问题,怎么排查?
生产出现oom问题,怎么排查? 1.使用dmesg命令查看系统日志 dmesg |grep -E 'kill|oom|out of memory',可以查看操作系统启动后的系统日志,这里就是查看跟 ...
- 生产环境中,数据库升级维护的最佳解决方案flyway
官网:https://flywaydb.org/ 转载:http://casheen.iteye.com/blog/1749916 1. 引言 想到要管理数据库的版本,是在实际产品中遇到问题后想到的 ...
- mysql innodb引擎 一次线上死锁分析排查步骤
我们的线上erp系统一天使用人员反映部分数据死活保存不上而且页面操作很慢.开始以为操作数据量大的原因, 后来查看了我们线上的glowroot系统,发现slowtrace中有超长时间的访问,点开查看详情 ...
随机推荐
- Struts CRUD
Struts CRUD 利用struts完成增删改查 思路: 1.导入相关的pom依赖(struts.自定义标签库的依赖) 2.分页的tag类导入.z.tld.完成web.xml的配置 3.dao层去 ...
- ESA2GJK1DH1K升级篇: 升级STM32 预热: 单片机定时 使用 http 获取云端文本文件里面的内容,然后显示在液晶屏
前言: 实现功能概要 STM32使用AT指令控制Wi-Fi以TCP方式连接咱上节安装的Web服务器,然后使用http的get协议获取云端文本文件里面的内容, 然后把获取的数据显示在OLED液晶屏. ...
- python paramiko的使用介绍
一: 使用paramiko #设置ssh连接的远程主机地址和端口t=paramiko.Transport((ip,port))#设置登录名和密码t.connect(username=username, ...
- 使用emplace操作
C++ 11新标准中引入了三个新成员——emplace_front.emplace和emplace_back,这些操作构造而不是拷贝元素.这些操作分别对应push_front.insert和push_ ...
- shell中echo输出换行的方法
[~]#echo "Hello world.\nHello sea" Hello world.\nHello sea [~]#echo -e "Hello world.\ ...
- C# ini配置文件操作类
/// <summary> /// INI文件操作类 /// </summary> public class IniFileHelper { /// <summary&g ...
- Mysql变量、存储过程、函数、流程控制
一.系统变量 系统变量: 全局变量 会话变量 自定义变量: 用户变量 局部变量 说明:变量由系统定义,不是用户定义,属于服务器层面 注意:全局变量需要添加global关键字,会话变量需要添加sessi ...
- Linux内核kobject结构体分析
1.前言 Linux内核中有大量的驱动,而这些驱动往往具有类似的结构,根据面向对象的思想,可以将共同的部分提取为父类,而这个父类就是kobject,kobject结构体中包含了大量设备的必须信息,而三 ...
- mybatis:updatebyexample与updateByExampleSelective
MyBatis,通常逆向工程工具生成接口和xml映射文件用于简单的单表操作. 有两个方法: updateByExample 和 updateByExampleSelective ,作用是对数据库进行 ...
- 爬虫框架 ---- scrapy 框架的介绍与安装
----- 爬虫 基于B/S 模式的数据采集技术,按照一定的规则,自动的抓取万维网信息程序 以一个或多个页面为爬取起点,从页面中提取链接实现深度爬取 使用爬虫的列子 第三方抢票软件(360/猎豹/ ...