安装 python 爬虫框架 Scrapy
官方安装说明文档:https://doc.scrapy.org/en/latest/intro/install.html#installing-scrapy
一、scrapy 需要以下依赖

二、一般来说,你可以通过以下命令直接安装 Scrapy(依赖会被自动安装)
pip3 install scrapy
注:关于pip 和 pip3 的区别,请看 这里
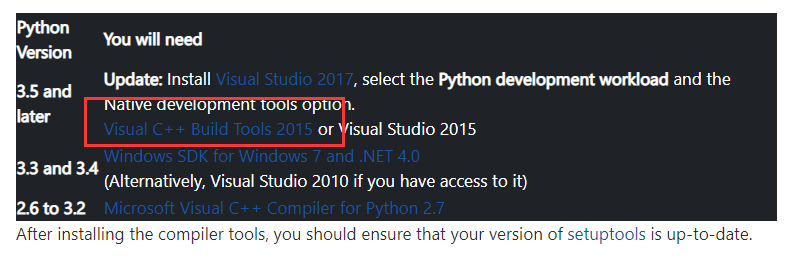
三、一个常见的问题是:安装 twisted 时,会报 “Microsoft visual c++ 14.0 is required” 错误
解决办法有两个:
1、老老实实安装 Visual C++ Build Tools 2015 套件,套件比较大(大概4G),安装时间比较久,传送门:Visual C++ Build Tools 2015
2、用安装 whl 文件的方式安装 Twisted
打开:https://www.lfd.uci.edu/~gohlke/pythonlibs/,crtl + f 查找 twisted,选择适合自己的版本下载

注:这个网站打开有点慢,翻墙的话,会好一点
四、进入 Twisted 的下载目录,shift + 鼠标右键,选择 “在此处打开 Powershell 窗口”,执行以下命令,安装 Twisted
pip3 install Twisted-19.2.1-cp37-cp37m-win32.whl
五、正常安装 Scrapy
pip3 install scrapy
六、如遇到其他错误,可以重复以上步骤,使用 whl 文件方式安装 python 扩展
非官方:https://www.lfd.uci.edu/~gohlke/pythonlibs/
本文链接:https://www.cnblogs.com/tujia/p/11169180.html
安装 python 爬虫框架 Scrapy的更多相关文章
- Linux 安装python爬虫框架 scrapy
Linux 安装python爬虫框架 scrapy http://scrapy.org/ Scrapy是python最好用的一个爬虫框架.要求: python2.7.x. 1. Ubuntu14.04 ...
- Ubuntu14.04下如何安装Python爬虫框架Scrapy
按照官方文档的说明,安装scrapy 需要以下程序或者库: (1).Python 2.7 (2).lxml. Most linux distributions ships PRepackaged ve ...
- win环境安装python爬虫框架scrapy
#官网下载python for windows #https://www.python.org/downloads/ #安装后在“计算机->属性->高级系统设置->环境变量-> ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- 《Python3网络爬虫开发实战》PDF+源代码+《精通Python爬虫框架Scrapy》中英文PDF源代码
下载:https://pan.baidu.com/s/1oejHek3Vmu0ZYvp4w9ZLsw <Python 3网络爬虫开发实战>中文PDF+源代码 下载:https://pan. ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- 《精通Python爬虫框架Scrapy》学习资料
<精通Python爬虫框架Scrapy>学习资料 百度网盘:https://pan.baidu.com/s/1ACOYulLLpp9J7Q7src2rVA
随机推荐
- Pycharm中设置默认头注释
在编写Python项目时,我们可能需要添加一些默认的信息,比如添加文件创建的时间,比如添加文件作者,等等,这些信息可以自己在python脚本中添加,但是也可以在Pycharm中配置模板,每次创建文件的 ...
- 201671030106 何启芝 实验十四 团队项目评审&课程学习总结
项目 内容 这个作业属于哪个课程 >>2016级计算机科学与工程学院软件工程(西北师范大学) 这个作业的要求在哪里 >>实验十四 团队项目评审&课程学习总结 课程学习目 ...
- Ribbon自带负载均衡策略
IRule这是所有负载均衡策略的父接口,里边的核心方法就是choose方法,用来选择一个服务实例. AbstractLoadBalancerRuleAbstractLoadBalancerRule是一 ...
- LeetCode 886. Possible Bipartition
原题链接在这里:https://leetcode.com/problems/possible-bipartition/ 题目: Given a set of N people (numbered 1, ...
- 在windbg调试会话中查找.NET版本
如何在调试会话中找到调试对象中使用的.NET运行时版本?以自动/脚本方式,不使用调试器扩展或符号? 答案: !for_each_module .if ( ($sicmp( "@#Module ...
- Python 检查代码占用内存 工具和模块
只介绍简单的使用, 更多使用方法请查看官方文档 tracemalloc 官方文档 tracemalloc文档地址 使用 import tracemalloc tracemalloc.start() # ...
- Promise对异步编程的贡献以及基本API了解
异步: 核心: 现在运行的部分和将来运行的部分之间的关系 常用方案: 从现在到将来的等待,通常使用一个回调函数在结果返回时得到结果 控制台(因为console族是由宿主环境即游览器实现的)可能会使用异 ...
- 洛谷 P5614题解
吐槽:数据好像有点水,直接枚举到200可以得80 points. 另:我还是太弱了,比赛的时候只有90 points,#7死卡不过去,最后发现是没有判断 \(z_1\) 和 \(z_2\) 的范围-- ...
- 第10组 Alpha冲刺(2/4)
队名:凹凸曼 组长博客 作业博客 组员实践情况 童景霖 过去两天完成了哪些任务 文字/口头描述 继续学习Android studio和Java 完善项目APP原型 展示GitHub当日代码/文档签入记 ...
- UDF——查找单元的相邻单元
Fluent版本:Fluent 19.2 Visual Studio版本:Visual Studio 2013 测试文件及源码下载链接: https://pan.baidu.com/s/1AZ59hs ...