scrapy框架爬取智联招聘网站上深圳地区python岗位信息。
爬取字段,公司名称,职位名称,公司详情的链接,薪资待遇,要求的工作经验年限
1,items中定义爬取字段
import scrapy class ZhilianzhaopinItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
company_name = scrapy.Field()
jobName = scrapy.Field()
company_url = scrapy.Field()
salary = scrapy.Field()
workingExp = scrapy.Field()
2,主程序函数
# -*- coding: utf-8 -*-
import scrapy
from urllib.parse import urlencode
import json
import math
from zhilianzhaopin.items import ZhilianzhaopinItem
class ZlzpSpider(scrapy.Spider):
name = 'zlzp'
# allowed_domains = ['www.zhaopin.com']
start_urls = ['https://fe-api.zhaopin.com/c/i/sou?']
data = {
'start': '',
'pageSize': '',
'cityId': '',
'kw': 'python',
'kt': ''
}
def start_requests(self):
url = self.start_urls[0]+urlencode(self.data)
yield scrapy.Request(url=url,callback=self.parse) def parse(self, response):
response = json.loads(response.text)
sum = int(response['data']['count'])
for res in response['data']['results']:
item = ZhilianzhaopinItem()
item['company_name'] = res['company']['name']
item['jobName'] = res['jobName']
item['company_url'] = res['company']['url']
item['salary'] = res['salary']
item['workingExp'] = res['workingExp']['name']
yield item for url_info in range(90,sum,90):
self.data['start'] = str(url_info)
url_i = self.start_urls[0]+urlencode(self.data)
yield scrapy.Request(url=url_i,callback=self.parse)
3,settings中设置请求头和打开下载管道
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'
ITEM_PIPELINES = {
'zhilianzhaopin.pipelines.ZhilianzhaopinPipeline': 300,
}
4,创建数据库,
5,pipelines.py文件中写入数据库
import pymysql
# 写入mysql数据库
class ZhilianzhaopinPipeline(object):
conn = None
mycursor = None
def open_spider(self, spider):
print('链接数据库...')
self.conn = pymysql.connect(host='172.16.25.4', user='root', password='root', db='scrapy')
self.mycursor = self.conn.cursor()
def process_item(self, item, spider):
print('正在写数据库...')
company_name = item['company_name']
jobName = item['jobName']
company_url = item['company_url']
salary = item['salary']
workingExp = item['workingExp']
sql = 'insert into zlzp VALUES (null,"%s","%s","%s","%s","%s")' % (company_name, jobName, company_url,salary,workingExp)
bool = self.mycursor.execute(sql)
self.conn.commit()
return item def close_spider(self, spider):
print('写入数据库完成...')
self.mycursor.close()
self.conn.close()
6,查看是否写入成功
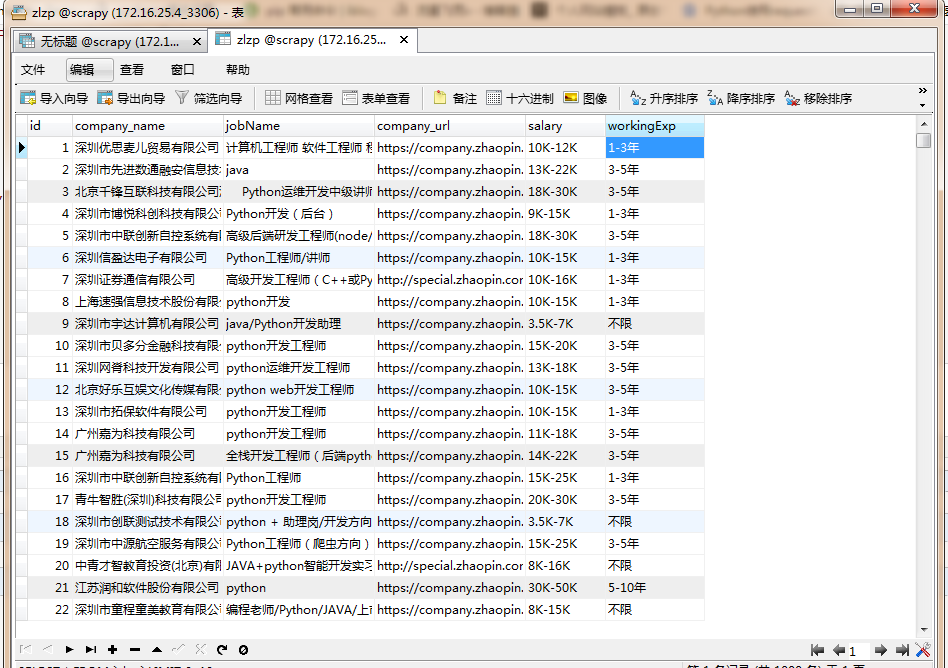
done。
scrapy框架爬取智联招聘网站上深圳地区python岗位信息。的更多相关文章
- 用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫. 操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化 1.数据爬取 job = "通信工程师&qu ...
- scrapy项目2:爬取智联招聘的金融类高端岗位(spider类)
---恢复内容开始--- 今天我们来爬取一下智联招聘上金融行业薪酬在50-100万的职位. 第一步:解析解析网页 当我们依次点击下边的索引页面是,发现url的规律如下: 第1页:http://www. ...
- node.js 89行爬虫爬取智联招聘信息
写在前面的话, .......写个P,直接上效果图.附上源码地址 github/lonhon ok,正文开始,先列出用到的和require的东西: node.js,这个是必须的 request,然发 ...
- 用生产者消费模型爬取智联招聘python岗位信息
爬取python岗位智联招聘 这里爬取北京地区岗位招聘python岗位,并存入EXECEL文件内,代码如下: import json import xlwt import requests from ...
- Python+selenium爬取智联招聘的职位信息
整个爬虫是基于selenium和Python来运行的,运行需要的包 mysql,matplotlib,selenium 需要安装selenium火狐浏览器驱动,百度的搜寻. 整个爬虫是模块化组织的,不 ...
- python爬取智联招聘职位信息(多进程)
测试了下,采用单进程爬取5000条数据大概需要22分钟,速度太慢了点.我们把脚本改进下,采用多进程. 首先获取所有要爬取的URL,在这里不建议使用集合,字典或列表的数据类型来保存这些URL,因为数据量 ...
- python爬取智联招聘职位信息(单进程)
我们先通过百度搜索智联招聘,进入智联招聘官网,一看,傻眼了,需要登录才能查看招聘信息 没办法,用账号登录进去,登录后的网页如下: 输入职位名称点击搜索,显示如下网页: 把这个URL:https://s ...
- scrapy 爬取智联招聘
准备工作 1. scrapy startproject Jobs 2. cd Jobs 3. scrapy genspider ZhaopinSpider www.zhaopin.com 4. scr ...
- 『Scrapy』爬取腾讯招聘网站
分析爬取对象 初始网址, http://hr.tencent.com/position.php?@start=0&start=0#a (可选)由于含有多页数据,我们可以查看一下这些网址有什么相 ...
随机推荐
- Min-Max容斥及其推广和应用
概念 Min-Max容斥,又称最值反演,是一种对于特定集合,在已知最小值或最大值中的一者情况下,求另一者的算法. 例如: $$max(a,b)=a+b-min(a,b) \\\ max(a,b,c)= ...
- spring中RequestBody注解接收参数时用JSONField转参数名无效问题
问题: 在springboot项目中使用@RequestBody注解接收post请求中body里的json参数的情况.即: @RequestMapping(value = "/get-use ...
- win7下IntelliJ IDEA使用curl
curl是利用URL语法在命令行方式下工作的开源文件传输工具 curl命令可以在开发web应用时,模拟前端发起的HTTP请求 1.下载curl https://curl.haxx.se/downloa ...
- imagettftext(): Could not read font
imagettftext(): Could not read font 1 确认FreeType Version ( 2以上版本) 2 确认字体路径,要是绝对路径的 3 确认 php.ini 配置 开 ...
- java知识精要(一)
一.java数组 (疯狂java讲义 第4.5 ~ 4.6章节) 1) 声明形式: type[] arrayName; 推荐方式 type arrayName[]; 2) 初始化: 方式一: type ...
- zookeeper从入门到精通视频教程(含网盘下载地址)
Zookeeper视频教程链接:https://pan.baidu.com/s/1V9YZN5F3sTKQJOhiDt9hnA 提取码:rtgl
- spring Boot 学习(二、Spring Boot与缓存)
一.概述1. 大多应用中,可通过消息服务中间件来提升系统异步通信.扩展解耦能力 2. 消息服务中两个重要概念: 消息代理(message broker)和目的地(destination) 当消息发送者 ...
- 对于解决VS2015启动界面卡在白屏的处理方法
有时候会遇到这种情况,仅供参考 找到devenv.exe所在文件夹,按住Shift,在空白地方右键,选择“在此处打开命令窗口”,在打开的窗口中输入devenv /ResetSettings 重新设置V ...
- .Net MVC生成二维码并前端展示
简介: 二维码又称二维条码,常见的二维码为QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar Code条形码能存更多的信息,也能表示更 ...
- C# vb .net实现棕褐色效果特效滤镜
在.net中,如何简单快捷地实现Photoshop滤镜组中的棕褐色效果呢?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码: 设置授权 第一 ...