pytorch中调整学习率的lr_scheduler机制
有的时候需要我们通过一定机制来调整学习率,这个时候可以借助于torch.optim.lr_scheduler类来进行调整;一般地有下面两种调整策略:(通过两个例子来展示一下)
两种机制:LambdaLR机制和StepLR机制;
(1)LambdaLR机制:
optimizer_G = torch.optim.Adam([{'params' : optimizer_G.parameters() , 'initial_lr' : train_opt.lr}] , lr = train_opt.lr , betas = (train_opt.betal , 0.999))
lambda_G = lambda epoch : 0.5 ** (epoch // 30)
schduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G.parameters() , lambda_G , last_epoch = 29);
scheduler.step()
lr = schduler.get_lr()[0]; //这里记得加一个[0]的索引!
for param_group in optimizer_G.param_groups():
param_group['lr'] = lr
解释:last_epoch是开始的前一个epoch的索引值,这里为29表示从epoch = 30开始(其中scheduler类中的epoch从last_epoch + 1开始,每次step操作epoch加1),学习率调整为lr * (0.5 ** (epoch // 30));另外注意的是:定义optimizer_G类时,需要写成上述那种形式,不要写成以前常见的“optimizer_G = torch.optim.Adam(params = optimizer_G.parameters()...)”,要像这里一样写成字典形式;否则lr_scheduler类会报“没有initial_lr的错误”
(2)StepLR机制:
schduler_G = torch.optim.lr_scheduler.StepLR(optimizer_G.parameters() , step_size = 30 , gamma = 0.1 , last_epoch = 29)
其他的和上面类似,这里的调整策略如下:
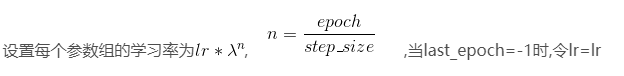
pytorch中调整学习率的lr_scheduler机制的更多相关文章
- 【转载】 Pytorch中的学习率调整lr_scheduler,ReduceLROnPlateau
原文地址: https://blog.csdn.net/happyday_d/article/details/85267561 ------------------------------------ ...
- pytorch中的学习率调整函数
参考:https://pytorch.org/docs/master/optim.html#how-to-adjust-learning-rate torch.optim.lr_scheduler提供 ...
- caffe中的学习率的衰减机制
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/Julialove102123/article/details/79200158 根据 caffe/ ...
- pytorch 动态调整学习率 重点
深度炼丹如同炖排骨一般,需要先大火全局加热,紧接着中火炖出营养,最后转小火收汁.本文给出炼丹中的 “火候控制器”-- 学习率的几种调节方法,框架基于 pytorch 1. 自定义根据 epoch 改变 ...
- Pytorch中的自动求梯度机制和Variable类
自动求导机制是每一个深度学习框架中重要的性质,免去了手动计算导数,下面用代码介绍并举例说明Pytorch的自动求导机制. 首先介绍Variable,Variable是对Tensor的一个封装,操作和T ...
- pytorch识别CIFAR10:训练ResNet-34(自定义transform,动态调整学习率,准确率提升到94.33%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 前面通过数据增强,ResNet-34残差网络识别CIFAR10,准确率达到了92.6. 这里对训练过程 ...
- [pytorch笔记] 调整网络学习率
1. 为网络的不同部分指定不同的学习率 class LeNet(t.nn.Module): def __init__(self): super(LeNet, self).__init__() self ...
- 深度学习训练过程中的学习率衰减策略及pytorch实现
学习率是深度学习中的一个重要超参数,选择合适的学习率能够帮助模型更好地收敛. 本文主要介绍深度学习训练过程中的6种学习率衰减策略以及相应的Pytorch实现. 1. StepLR 按固定的训练epoc ...
- Pytorch调整学习率
每隔一定的epoch调整学习率 def adjust_learning_rate(optimizer, epoch): """Sets the learning rate ...
随机推荐
- lambda 函数的用法
lambda函数又叫匿名函数, 匿名函数就是没有名字的函数,不使用def语句声明的函数.如果要声名,则需要使用lambda关键字进行声明. 一般用来定义简单的函数. 1.声明一个简单的加法匿名函数: ...
- LightOJ - 1095 - Arrange the Numbers(错排)
链接: https://vjudge.net/problem/LightOJ-1095 题意: Consider this sequence {1, 2, 3 ... N}, as an initia ...
- linux服务器初始化(防火墙、内核优化、时间同步、打开文件数)
#!/bin/bash read -p 'enter the network segment for visiting the server:' ips # 关闭firewalld和selinux s ...
- SIGAI机器学习第二十集 AdaBoost算法1
讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用 AdaBo ...
- Phoenix 简单介绍
转载自:https://blog.csdn.net/carolzhang8406/article/details/79455684 1. Phoenix定义 Phoenix最早是saleforce的一 ...
- 阿里开源线上应用调试利器 Arthas的背后
Arthas是一个功能非常强大的诊断工具,功能点很多,例如:jvm信息.线程信息.搜索类中的方法.跟踪代码执行.观测方法的入参和返回参数等等. 作为有追求的程序员,你不仅要知道它能做什么,更要思考它是 ...
- Cogs 1708. 斐波那契平方和(矩阵乘法)
斐波那契平方和 ★★☆ 输入文件:fibsqr.in 输出文件:fibsqr.out 简单对比 时间限制:0.5 s 内存限制:128 MB [题目描述] ,对 1000000007 取模.F0=0, ...
- 【概率论】5-7:Gama分布(The Gamma Distributions Part I)
title: [概率论]5-7:Gama分布(The Gamma Distributions Part I) categories: - Mathematic - Probability keywor ...
- Mujin Programming Challenge 2017题解
传送门 \(A\) 似乎并不难啊然而还是没想出来-- 首先我们发现对于一个数\(k\),它能第一个走到当且仅当对于每一个\(i<k\)满足\(x_i\geq 2i-1\),这样我们就可以把所有的 ...
- 安装php的oracle扩展
PHP 版本5.5 Windows下 1.首先下载OCI8的扩展 http://pecl.php.net/package/o... 我这里下的版本是5.5 Thread Safe (TS) x86 版 ...