.NET 内存基础(通过内存体验类型、传参、及装箱拆箱)
该随笔受启发于《CLR Via C#(第三版)》第四章4.4运行时的相互联系
一、内存分配的几个区域
1、线程栈
局部变量的值类型 和 局部变量中引用类型的指针(或称引用)会被分配到该区域上(引用类型的一部分内存被分配到该区域内)。
该区域由系统管控,不受垃圾收集器的控制。当所在方法执行完毕后,局部变量会自动释放(引用类型只释放指针,而不释放指针指向的数据)。
堆栈的执行效率很高,但容量有限。
2、GC Heap(回收堆)
用于分配小对象(引用类型),如果引用类型的实例大小 小于85000个字节,则会被分配到该区域上。
3、LOH(Large Object Heap)
超过 85000个字节的大对象(引用类型)会被分配到该区域上。
LOH 和 GC Heap区别在于:当有内存分配或者回收时,垃圾收集器可能会对GC Heap进行压缩,而 LOH 不会被压缩,只是在垃圾回收时被回收。
二、栈桢(stack frame)
栈桢是实现函数调用的数据结构,从逻辑上看,栈桢是一个函数执行的环境(上下文),包括:函数参数、返回地址和函数局部变量。
注意:上述的“返回地址” 不是函数的返回值,而是完成函数调用后的CPU接下来要执行的代码的位置。
更多参见: 维基百科 call stack
三、浅拷贝 和 深拷贝(Clone、或克隆)
浅拷贝和深拷贝是内存拷贝的两种方式,在传参的过程中通常会发生内存拷贝并且是浅拷贝,比如下面代码、两个参数就是两次浅拷贝。
- public void Test1()
- {
- string name = "test1";
- int size = 1;
- Test2(name, size);// 两次浅拷贝
- }
- public void Test2(string pName, int pSize)
- {
- }
浅拷贝 前后的内存结果如下图所示:
浅拷贝对于值类型(例如:int),拷贝的是栈中的具体值。
浅拷贝对于引用类型(例如:string),拷贝的是栈中的引用、其新引用 所指向的 托管堆中的地址 还是原来的地址。
深拷贝和浅拷贝的区别在于对 堆中数据(即对象)的处理:
浅拷贝只拷贝栈中的引用,不拷贝堆中的对象,新引用指向原有对象。
深拷贝会拷贝栈中的引用,并且会在堆中创建新的对象,新对象的属性值 “可能” 来源于原有对象(因为、在C#中实现深拷贝需要自己编写额外的代码,
即实现 ICloneable 接口,深拷贝的结果是不确定的。不过建议大家尽可能避免使用该接口),新引用地址指向新的对象。因此,深拷贝只针对于引用类型,
对于值类型没有太多的意义。
四、Demo
如果说前三项是做铺垫,那么该Demo算是正文了。
事先已经定义好的如下类:
- public class Data
- {
- public string Name;
- public int Size;
- }
假设代码即将调用Test1函数:
- public void Test1()
- {
- string name = "test1";
- int size = 1;
- Data data = new Data() { Name = "test1", Size = 1 };
- Test2(name, size, data);
- object obj = size;
- int temp = (int)obj;
- }
- public void Test2(string pName, int pSize, Data pData)
- {
- pName = "test2";
- pSize = 2;
- pData.Name = "test2";
- pData.Size = 2;
- pData = new Data() { Name = "test3", Size = 3 };
- }
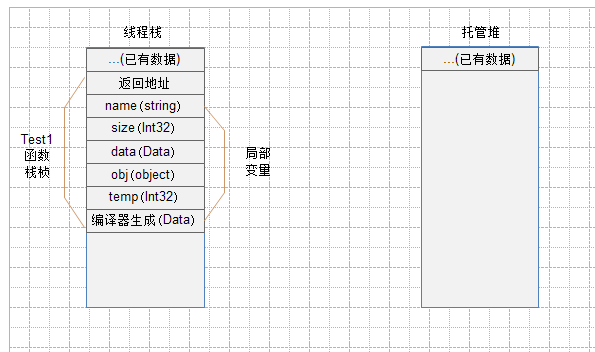
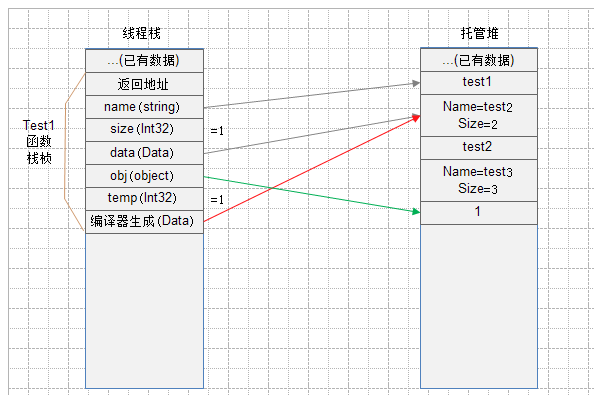
此时线程栈和托管堆内的情况如下图所示(图1):
1、开始调用Test1函数,这时会向栈中压入一个栈桢(stack frame)。
栈桢包含3部分数据:
1)函数参数,当然Test1函数没有参数。
2)返回地址,在Test1函数中,以当前代码环境为例该地址没有什么实际意义不作说明。
3)函数局部变量,此时Test1函数中的所有的局部变量都会被压入栈。 有如下五个局部变量会被压入栈:
string name, int32 size, Data data, object obj, int32 temp。(当然实际是六个局部变量,第六个是编译器自动生成的,在随笔结尾处再做解释。)
压入一个栈桢后,内存结果如下图所示(图2):
2、接下来执行Test1函数的代码,给name赋值,给size赋值,给data赋值。内存结果将会如下图所示(图3):
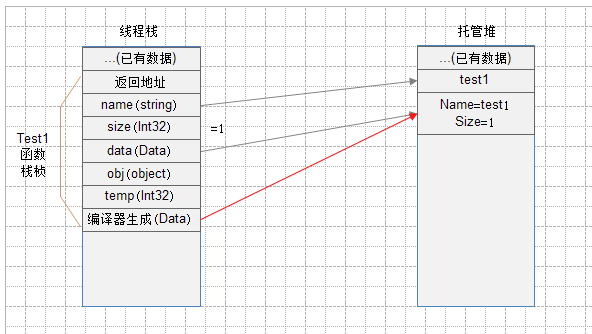
上图中的红线和编译器生成的变量 将在随笔结尾出做解释。
3、接下来将调用Test2函数,这时还会向栈中压入一个栈桢。
栈桢包含3部分数据:
1)函数参数,Test2函数有三个参数,三个参数都是浅拷贝。
2)返回地址,该地址为调用Test2函数代码位置的下一行(或者称下一个指令)的位置,即:
- obj = size; // 在调用Test1函数压入栈桢的时候已经完成了 object obj; 的操作
完成函数调用后,将执行上述代码。
3)函数局部变量,编译器会自动生成一个变量(随笔结尾处,将做出解释)
故,此时的内存结果如下图所示(图4):
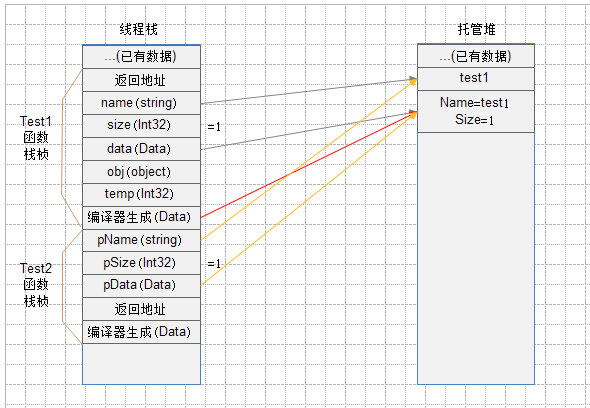
两条橙色线是参数浅拷贝的结果。
4、 在执行完Test2函数的函数体,未返回Test1函数之前,内存结果如下图所示(图5):
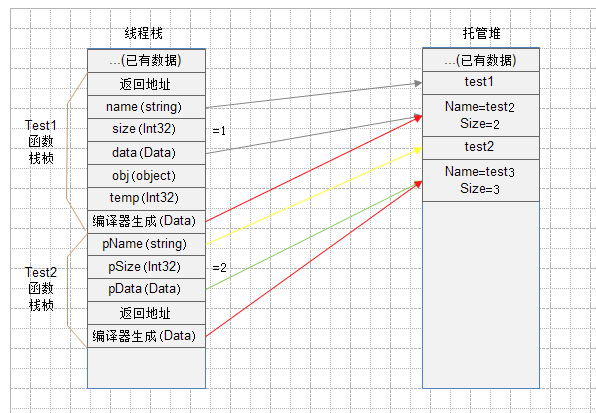
红线 将在随笔结尾处做解释。
黄线 需要注意,string是特殊的引用类型,其外在表现和值类型一致,但其本质上还是引用类型。由于string的不可变性,对string的每一次赋值
都会产生一个新的对象(如果新对象不存在),所以导致了黄线的出现。
浅绿线 我想这条线应该没有问题吧。
5、 完成Test2函数的调用,代码将返回到 Test2函数栈桢返回地址所示位置,在这一过程中 Test2函数栈桢 将被弹出,结果如下图所示(图6):
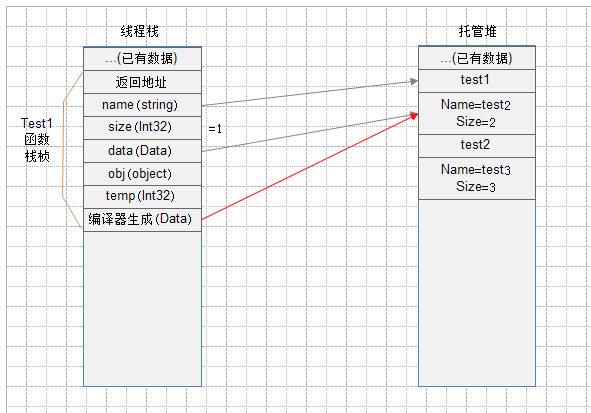
托管堆中的不被使用的对象将由GC进行自动回收,被回收的时间不确定。
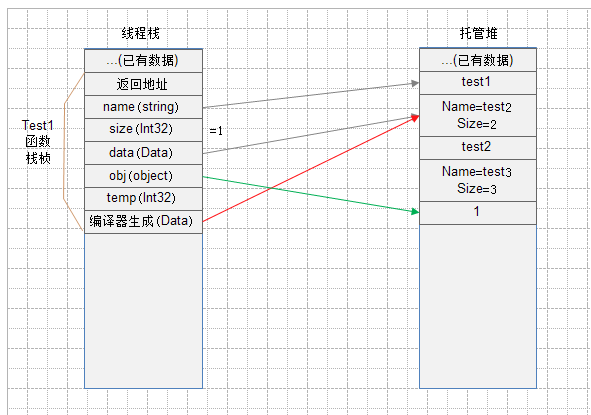
6、 由3可以知,接下来将执行 obj = size; 的操作——装箱,从字面上可以这样理解:将值类型装进引用类型的箱子里。
大致的操作过程如下:
1)首先、在堆中创建一个新的对象。(由于该操作导致装箱操作的性能降低)
2)将size的值复制到对象中。
3)最后将obj的引用指向新创建的对象。
最后的结果如下图所示(图7):
7、最后一个操作——拆箱。
装箱,是将值类型装进引用类型的箱子里,在这一过程中,发生对象创建和内存复制。
然而拆箱,并没有那么复杂,也没有类似的“拆”的过程,只是将对象中的值类型读取出来(最耗时的操作应该是寻找值类型所在的内存地址的操作),相对于装箱,其性能要好很多。
最终结果如下图所示(图8):
五、 语法糖——对象初始化器
如下的两个代码片段是完全等效的:
- Data temp = new Data(); // 编译器自动生成的变量名不一定叫temp
- temp.Name = "test1";
- temp.Size = 1;
- data = temp;
- data = new Data() { Name = "test1", Size = 1 };
第二种写法,可以看作是一种简写,编译器在编译的时候会将第二种写法的代码进行转化,转化成第一种写法。所以对象初始化器,C#3.0的语法新特性,
完全是一种语法糖,CLR没有起到任何作用。
当看到这的时候,再想想上面的红线 一切迎刃而解。
.NET 内存基础(通过内存体验类型、传参、及装箱拆箱)的更多相关文章
- java基础1.5版后新特性 自动装箱拆箱 Date SimpleDateFormat Calendar.getInstance()获得一个日历对象 抽象不要生成对象 get set add System.arrayCopy()用于集合等的扩容
8种基本数据类型的8种包装类 byte Byte short Short int Integer long Long float Float double Double char Character ...
- Java String引起的常量池、String类型传参、“==”、“equals”、“hashCode”问题 细节分析
在学习javase的过程中,总是会遇到关于String的各种细节问题,而这些问题往往会出现在Java攻城狮面试中,今天想写一篇随笔,简单记录下我的一些想法.话不多说,直接进入正题. 1.String常 ...
- 6个重要的.NET概念:栈,堆,值类型,引用类型,装箱,拆箱
引言 本篇文章主要介绍.NET中6个重要的概念:栈,堆,值类型,引用类型,装箱,拆箱.文章开始介绍当你声明一个变量时,编译器内部发生了什么,然后介绍两个重要的概念:栈和堆:最后介绍值类型和引用类型,并 ...
- NET中的类型和装箱/拆箱原理
谈到装箱拆箱,DebugLZQ相信给位园子里的博友一定可以娓娓道来,大概的意思就是值类型和引用类型的相互转换呗---值类型到引用类型叫装箱,反之则叫拆箱.这当然没有问题,可是你只知道这么多,那么Deb ...
- C#基础精华03(常用类库StringBuilder,List<T>泛型集合,Dictionary<K , V> 键值对集合,装箱拆箱)
常用类库StringBuilder StringBuilder高效的字符串操作 当大量进行字符串操作的时候,比如,很多次的字符串的拼接操作. String 对象是不可变的. 每次使用 System. ...
- [No0000136]6个重要的.NET概念:栈,堆,值类型,引用类型,装箱,拆箱
引言 本篇文章主要介绍.NET中6个重要的概念:栈,堆,值类型,引用类型,装箱,拆箱.文章开始介绍当你声明一个变量时,编译器内部发生了什么,然后介绍两个重要的概念:栈和堆:最后介绍值类型和引用类型,并 ...
- C#基础复习(2) 之 装箱拆箱
参考资料 [1] @只增笑耳Jason的回答 https://www.zhihu.com/question/57208269 [2] <C# 捷径教程> 疑难解答 装箱和拆箱是什么? 何时 ...
- 深入C#内存管理来分析值类型&引用类型,装箱&拆箱,堆栈几个概念组合之间的区别
C#初学者经常被问的几道辨析题,值类型与引用类型,装箱与拆箱,堆栈,这几个概念组合之间区别,看完此篇应该可以解惑. 俗话说,用思想编程的是文艺程序猿,用经验编程的是普通程序猿,用复制粘贴编程的是2B程 ...
- 以Integer类型传参值不变来理解Java值传参
最近在写代码的时候出了一个错误,由于对值引用理解的不深,将Integer传入方法中修改,以为传入后直接修改Integer中的值就不用写返回值接收了,虽然很快发现了问题,但还是来总结一下 首先是代码: ...
随机推荐
- ABP理论学习之SignalR集成
返回总目录 本篇目录 介绍 安装 建立连接 内置功能 你自己的SignaR代码 介绍 Abp.Web.SignalR 使得在基于ABP的应用程序中使用 SignalR相当容易.查看SignalR文档获 ...
- 剑指Offer面试题:26.字符串的排列
一.题目:字符串的排列 题目:输入一个字符串,打印出该字符串中字符的所有排列.例如输入字符串abc,则打印出由字符a.b.c所能排列出来的所有字符串abc.acb.bac.bca.cab和cba. 二 ...
- MySQL KEY分区
200 ? "200px" : this.width)!important;} --> 介绍 KEY分区和HASH分区相似,但是KEY分区支持除text和BLOB之外的所有数 ...
- Got the Best Employee of the year 2015 Star Award
Got "The Best Employee of the year 2015 Star Award" from the company, thanks to all that h ...
- 抛开flash,自己开发实现C++ RTMP直播流播放器
抛开flash,自己开发实现C++ RTMP直播流播放器 众所周知,RTMP是以flash为客户端播放器的直播协议,主要应用在B/S形式的场景中.本人研究并用C++开发实现了RTMP直播流协议的播放器 ...
- 《Entity Framework 6 Recipes》中文翻译系列 (36) ------ 第六章 继承与建模高级应用之TPC继承映射
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 6-12 TPC继承映射建模 问题 你有两张或多张架构和数据类似的表,你想使用TP ...
- 《Spark快速大数据分析》—— 第三章 RDD编程
- 在微软伪静态处理机制下action导致伪静态的地址重现的问题
伪静态前的地址:/sc/ProductList.aspx?pClass=0&descType=2&minPrice=1&maxPrice=11 伪静态后的地址:/product ...
- bootstrap-modal 学习笔记 源码分析
Bootstrap是Twitter推出的一个开源的用于前端开发的工具包,怎么用直接官网 http://twitter.github.io/bootstrap/ 我博客的定位就是把这些年看过的源码给慢慢 ...
- Pipedata3d - Welding Neck Flange
Pipedata3d - Welding Neck Flange eryar@163.com Abstract. Pipedata3d show piping component data in ta ...