Java利用IText导出PDF(更新)
我很久以前写的还是上大学的时候写的:https://www.cnblogs.com/LUA123/p/5108007.html ,今天心血来潮决定更新一波。
看了下官网(https://itextpdf.com/en),出来个IText 7,但是这个要收费的,怎么收费我也不清楚,为了避免不必要的麻烦,还是用IText5版本玩了。
正文
首先引入依赖:(目前最新版的)
<!-- https://mvnrepository.com/artifact/com.itextpdf/itextpdf -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.itextpdf/itext-asian -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext-asian</artifactId>
<version>5.2.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.itextpdf.tool/xmlworker -->
<dependency>
<groupId>com.itextpdf.tool</groupId>
<artifactId>xmlworker</artifactId>
<version>5.5.13.1</version>
</dependency>
示例一:HTML文件转PDF
web.html
<div style="text-align: center"><b><span style="font-size: large">Terms and Conditions</span></b></div>
<ul>
<li>Prices are in AED</li>
<li>All Credit Card transactions are subject to a 3.25% processing fee</li>
<li>In the event production is required per customer request, 50% of the entire bill will be due prior to start of production, and the balance due upon delivery.</li>
<li>All furniture will be delivered in A+ condition. In the event that the equipment is damaged, the renter shall be liable for all repair costs to restore the equipment to its state at the beginning of the rental period.</li>
<li>Equipment shall be utilized for the stated purpose and at the stated location only.</li>
</ul> <ul class="chinese" style="font-family: SimSun;" >
<li>价格以迪拉姆为单位</li>
<li>所有信用卡交易都要支付3.25%的手续费</li>
<li>如果客户要求生产,则应支付全部账单的50%</li>
<li>在开始生产之前,以及交货时的余额。所有家具将以+状态交付。如果设备损坏,承租人应承担所有维修费用,以将设备恢复至租期。</li>
<li>设备应仅用于规定用途和规定位置。</li>
</ul>
web.css
ul li {
color: #0ba79c;
}
.chinese li {
color: #ccc920;
}
代码
package com.demo.pdf; import com.itextpdf.text.Document;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Element;
import com.itextpdf.text.Utilities;
import com.itextpdf.text.pdf.PdfPCell;
import com.itextpdf.text.pdf.PdfPTable;
import com.itextpdf.text.pdf.PdfWriter;
import com.itextpdf.tool.xml.XMLWorker;
import com.itextpdf.tool.xml.XMLWorkerFontProvider;
import com.itextpdf.tool.xml.XMLWorkerHelper;
import com.itextpdf.tool.xml.css.CssFile;
import com.itextpdf.tool.xml.css.StyleAttrCSSResolver;
import com.itextpdf.tool.xml.html.CssAppliers;
import com.itextpdf.tool.xml.html.CssAppliersImpl;
import com.itextpdf.tool.xml.html.Tags;
import com.itextpdf.tool.xml.parser.XMLParser;
import com.itextpdf.tool.xml.pipeline.css.CSSResolver;
import com.itextpdf.tool.xml.pipeline.css.CssResolverPipeline;
import com.itextpdf.tool.xml.pipeline.end.PdfWriterPipeline;
import com.itextpdf.tool.xml.pipeline.html.HtmlPipeline;
import com.itextpdf.tool.xml.pipeline.html.HtmlPipelineContext; import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.Charset; /**
* HTML转PDF
*/
public class HTMLAndPDF {
public static final String PDF = "pdf/web.pdf";
public static final String PDF2 = "pdf/web2.pdf";
public static final String PDF3 = "pdf/web3.pdf";
public static final String PDF4 = "pdf/web4.pdf";
public static final String HTML = "pdf/web.html";
public static final String CSS = "pdf/web.css"; public static void main(String[] args) throws IOException, DocumentException {
File file = new File(PDF);
file.getParentFile().mkdirs();
new HTMLAndPDF().createPdf(PDF); file = new File(PDF2);
file.getParentFile().mkdirs();
new HTMLAndPDF().createPdf2(PDF2); file = new File(PDF3);
file.getParentFile().mkdirs();
new HTMLAndPDF().createPdf3(PDF3); file = new File(PDF4);
file.getParentFile().mkdirs();
new HTMLAndPDF().createPdf4(PDF4); } /**
* 原封不动转换
* @param file
* @throws IOException
* @throws DocumentException
*/
public void createPdf(String file) throws IOException, DocumentException {
// step 1
Document document = new Document();
// step 2
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(file));
writer.setInitialLeading(12);
// step 3
document.open();
// step 4
XMLWorkerHelper.getInstance().parseXHtml(writer, document,
new FileInputStream(HTML), Charset.forName("UTF-8"));
// step 5
document.close();
} /**
* 引入额外的css
* @param file
* @throws IOException
* @throws DocumentException
*/
public void createPdf2(String file) throws IOException, DocumentException {
// step 1
Document document = new Document();
// step 2
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(file));
writer.setInitialLeading(12);
// step 3
document.open();
// step 4
XMLWorkerHelper.getInstance().parseXHtml(writer, document,
new FileInputStream(HTML)); String html = Utilities.readFileToString(HTML);
String css = "ul { list-style: disc } li { padding: 10px }";
PdfPTable table = new PdfPTable(1);
table.setSpacingBefore(20);
PdfPCell cell = new PdfPCell();
for (Element e : XMLWorkerHelper.parseToElementList(html, css)) {
cell.addElement(e);
}
table.addCell(cell);
document.add(table);
// step 5
document.close();
} /**
* 引入外部css
* @param file
* @throws IOException
* @throws DocumentException
*/
public void createPdf3(String file) throws IOException, DocumentException {
// step 1
Document document = new Document(); // step 2
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(file));
writer.setInitialLeading(12.5f); // step 3
document.open(); // step 4 // CSS
CSSResolver cssResolver = new StyleAttrCSSResolver();
CssFile cssFile = XMLWorkerHelper.getCSS(new FileInputStream(CSS));
cssResolver.addCss(cssFile); // HTML
HtmlPipelineContext htmlContext = new HtmlPipelineContext(null);
htmlContext.setTagFactory(Tags.getHtmlTagProcessorFactory()); // Pipelines
PdfWriterPipeline pdf = new PdfWriterPipeline(document, writer);
HtmlPipeline html = new HtmlPipeline(htmlContext, pdf);
CssResolverPipeline css = new CssResolverPipeline(cssResolver, html); // XML Worker
XMLWorker worker = new XMLWorker(css, true);
XMLParser p = new XMLParser(worker);
p.parse(new FileInputStream(HTML)); // step 5
document.close();
} /**
* 处理中文(引入外部字体文件)
* @param file
* @throws IOException
* @throws DocumentException
*/
public void createPdf4(String file) throws IOException, DocumentException {
// step 1
Document document = new Document(); // step 2
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(file));
writer.setInitialLeading(12.5f); // step 3
document.open(); // step 4 // CSS
CSSResolver cssResolver = new StyleAttrCSSResolver();
CssFile cssFile = XMLWorkerHelper.getCSS(new FileInputStream(CSS));
cssResolver.addCss(cssFile); // HTML
XMLWorkerFontProvider fontProvider = new XMLWorkerFontProvider(XMLWorkerFontProvider.DONTLOOKFORFONTS);
fontProvider.register("pdf/华庚少女字体.ttf", "girl"); // 字体别名,在web.html使用
CssAppliers cssAppliers = new CssAppliersImpl(fontProvider);
HtmlPipelineContext htmlContext = new HtmlPipelineContext(cssAppliers);
htmlContext.setTagFactory(Tags.getHtmlTagProcessorFactory()); // Pipelines
PdfWriterPipeline pdf = new PdfWriterPipeline(document, writer);
HtmlPipeline html = new HtmlPipeline(htmlContext, pdf);
CssResolverPipeline css = new CssResolverPipeline(cssResolver, html); // XML Worker
XMLWorker worker = new XMLWorker(css, true);
XMLParser p = new XMLParser(worker);
p.parse(new FileInputStream(HTML), Charset.forName("UTF-8"));
// step 5
document.close();
} }
第一个输出:

第二个输出:

第三个输出:

第四个输出:

大家可以看到中文的问题,注意点有两个:html文件指定 font-family;如果引入外部字体文件,别名要与font-family一致。文件:https://github.com/Mysakura/DataFiles
第四个要想成功,需要将web.html文件里的font-family修改

所以呢,如果你对字体没啥要求,那font-family就指定常用中文字体即可,宋体,雅黑什么的
这部分涉及的文件

注意!!!如果你外部字体为ttc文件,比如simsun.ttc,在引入的地方就要注意写法,如下:后面有个[,1]


合并PDF文件 & 嵌入外部字体
提示:如果你运行上面的例子,你可以发现我的输入输出文件都在工程根目录的pdf文件夹里。
代码
package com.demo.pdf; import com.itextpdf.text.Document;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Font;
import com.itextpdf.text.Paragraph;
import com.itextpdf.text.pdf.*; import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.RandomAccessFile; /**
* 合并文档 & 嵌入字体
*/
public class MergeAndAddFont {
public static final String FONT = "pdf/华庚少女字体.ttf";
public static final Integer FILE_NUM = 2; // 合并两个文件
public static final String[] FILE_A = {
"pdf/testA0.pdf", "pdf/testA1.pdf"
};
public static final String[] FILE_B = {
"pdf/testB0.pdf", "pdf/testB1.pdf"
};
public static final String[] FILE_C = {
"pdf/testC0.pdf", "pdf/testC1.pdf"
};
public static final String[] CONTENT = {
"琪亚娜·卡斯兰娜", "德丽莎·阿波卡利斯"
};
public static final String MERGED_A1 = "pdf/testA_merged1.pdf";
public static final String MERGED_A2 = "pdf/testA_merged2.pdf";
public static final String MERGED_B1 = "pdf/testB_merged1.pdf";
public static final String MERGED_B2 = "pdf/testB_merged2.pdf";
public static final String MERGED_C1 = "pdf/testC_merged1.pdf";
public static final String MERGED_C2 = "pdf/testC_merged2.pdf"; public static void main(String[] args) throws DocumentException, IOException { File file = new File(MERGED_A1);
file.getParentFile().mkdirs();
MergeAndAddFont app = new MergeAndAddFont(); // 测试一:嵌入字体;生成的文件仅仅包含用到的字形;智能合并;非智能合并
for (int i = 0; i < FILE_A.length; i++) {
app.createPdf(FILE_A[i], CONTENT[i], true, true);
}
app.mergeFiles(FILE_A, MERGED_A1,false);
app.mergeFiles(FILE_A, MERGED_A2, true); // 测试二:嵌入字体;生成的文件包含完整字体;智能合并;非智能合并
for (int i = 0; i < FILE_B.length; i++) {
app.createPdf(FILE_B[i], CONTENT[i], true, false);
}
app.mergeFiles(FILE_B, MERGED_B1,false);
app.mergeFiles(FILE_B, MERGED_B2, true); // 测试三:不嵌入字体;生成的文件包含完整字体;智能合并;手动嵌入字体
for (int i = 0; i < FILE_C.length; i++) {
app.createPdf(FILE_C[i], CONTENT[i], false, false);
}
app.mergeFiles(FILE_C, MERGED_C1, true);
app.embedFont(MERGED_C1, FONT, MERGED_C2);
} /**
*
* @param filename
* @param text
* @param embedded true在PDF中嵌入字体,false不嵌入
* @param subset true仅仅包含用到的字形,false包含完整字体
* @throws DocumentException
* @throws IOException
*/
public void createPdf(String filename, String text, boolean embedded, boolean subset) throws DocumentException, IOException {
// step 1
Document document = new Document();
// step 2
PdfWriter.getInstance(document, new FileOutputStream(filename));
// step 3
document.open();
// step 4
BaseFont bf = BaseFont.createFont(FONT, BaseFont.IDENTITY_H, embedded); // 生成文件大小与编码有关,如果你没有中文,那么编码用BaseFont.WINANSI就节约很多资源了。
bf.setSubset(subset);
Font font = new Font(bf, 12);
document.add(new Paragraph(text, font));
// step 5
document.close();
} /**
* 合并文件
* @param files
* @param result
* @param smart 智能Copy
* @throws IOException
* @throws DocumentException
*/
public void mergeFiles(String[] files, String result, boolean smart) throws IOException, DocumentException {
Document document = new Document();
PdfCopy copy;
if (smart)
copy = new PdfSmartCopy(document, new FileOutputStream(result));
else
copy = new PdfCopy(document, new FileOutputStream(result));
document.open();
PdfReader[] reader = new PdfReader[FILE_NUM];
for (int i = 0; i < files.length; i++) {
reader[i] = new PdfReader(files[i]);
copy.addDocument(reader[i]);
copy.freeReader(reader[i]);
reader[i].close();
}
document.close();
} /**
* 嵌入字体
* @param merged
* @param fontfile
* @param result
* @throws IOException
* @throws DocumentException
*/
private void embedFont(String merged, String fontfile, String result) throws IOException, DocumentException {
// the font file
RandomAccessFile raf = new RandomAccessFile(fontfile, "r");
byte fontbytes[] = new byte[(int)raf.length()];
raf.readFully(fontbytes);
raf.close();
// create a new stream for the font file
PdfStream stream = new PdfStream(fontbytes);
stream.flateCompress();
stream.put(PdfName.LENGTH1, new PdfNumber(fontbytes.length));
// create a reader object
PdfReader reader = new PdfReader(merged);
int n = reader.getXrefSize();
PdfObject object;
PdfDictionary font;
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream(result));
PdfName fontname = new PdfName(BaseFont.createFont(fontfile, BaseFont.WINANSI, BaseFont.NOT_EMBEDDED).getPostscriptFontName());
for (int i = 0; i < n; i++) {
object = reader.getPdfObject(i);
if (object == null || !object.isDictionary())
continue;
font = (PdfDictionary)object;
if (PdfName.FONTDESCRIPTOR.equals(font.get(PdfName.TYPE))
&& fontname.equals(font.get(PdfName.FONTNAME))) {
PdfIndirectObject objref = stamper.getWriter().addToBody(stream);
font.put(PdfName.FONTFILE2, objref.getIndirectReference());
}
}
stamper.close();
reader.close();
}
}
运行之后会生成12个文件。
直观一点的(看文件体积)
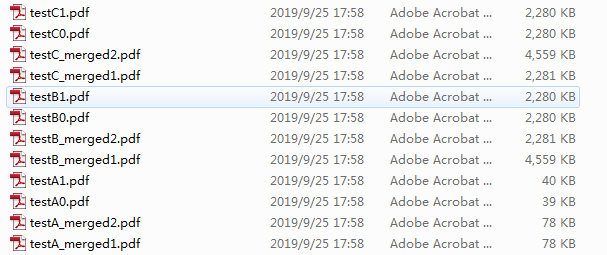
首先看A系列,因为它在创建文件的时候就指定包含用到的字形,所以独立文件的文件属性都是
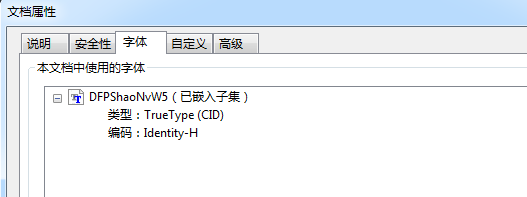
合并文件都是
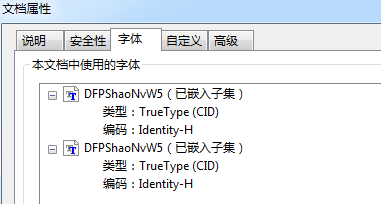
再来看B系列,因为它指定包含完整字体,所以体积很大。不同的是,合并1是非智能的,所以体积是智能的2倍。独立文件和合并文件的文件属性都是(已嵌入)

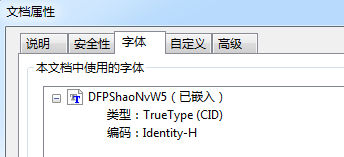
最后看C系列【这里中英文的出入比较大】,如果你是中文PDF,那么文档属性都是已嵌入并且手动嵌入的体积是其它的2倍。
如果你是英文文档,代码如下,只需要改动两处(1. 输入英文,中文不显示 2. 更改字体编码),生成的文件C系列大不一样。
package com.demo.pdf; import com.itextpdf.text.Document;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Font;
import com.itextpdf.text.Paragraph;
import com.itextpdf.text.pdf.*; import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.RandomAccessFile; /**
* 合并文档 & 嵌入字体
*/
public class MergeAndAddFont3 {
public static final String FONT = "pdf/华庚少女字体.ttf";
public static final Integer FILE_NUM = 2; // 合并两个文件
public static final String[] FILE_A = {
"pdf/en/testA0.pdf", "pdf/en/testA1.pdf"
};
public static final String[] FILE_B = {
"pdf/en/testB0.pdf", "pdf/en/testB1.pdf"
};
public static final String[] FILE_C = {
"pdf/en/testC0.pdf", "pdf/en/testC1.pdf"
};
// 英文PDF内容
public static final String[] CONTENT = {
"ABCD", "EFGK"
};
public static final String MERGED_A1 = "pdf/en/testA_merged1.pdf";
public static final String MERGED_A2 = "pdf/en/testA_merged2.pdf";
public static final String MERGED_B1 = "pdf/en/testB_merged1.pdf";
public static final String MERGED_B2 = "pdf/en/testB_merged2.pdf";
public static final String MERGED_C1 = "pdf/en/testC_merged1.pdf";
public static final String MERGED_C2 = "pdf/en/testC_merged2.pdf"; public static void main(String[] args) throws DocumentException, IOException { File file = new File(MERGED_A1);
file.getParentFile().mkdirs();
MergeAndAddFont3 app = new MergeAndAddFont3(); // 测试一:嵌入字体;生成的文件仅仅包含用到的字形;智能合并;非智能合并
for (int i = 0; i < FILE_A.length; i++) {
app.createPdf(FILE_A[i], CONTENT[i], true, true);
}
app.mergeFiles(FILE_A, MERGED_A1,false);
app.mergeFiles(FILE_A, MERGED_A2, true); // 测试二:嵌入字体;生成的文件包含完整字体;智能合并;非智能合并
for (int i = 0; i < FILE_B.length; i++) {
app.createPdf(FILE_B[i], CONTENT[i], true, false);
}
app.mergeFiles(FILE_B, MERGED_B1,false);
app.mergeFiles(FILE_B, MERGED_B2, true); // 测试三:不嵌入字体;生成的文件包含完整字体;智能合并;手动嵌入字体
for (int i = 0; i < FILE_C.length; i++) {
app.createPdf(FILE_C[i], CONTENT[i], false, false);
}
app.mergeFiles(FILE_C, MERGED_C1, true);
app.embedFont(MERGED_C1, FONT, MERGED_C2);
} /**
*
* @param filename
* @param text
* @param embedded true在PDF中嵌入字体,false不嵌入
* @param subset true仅仅包含用到的字形,false包含完整字体
* @throws DocumentException
* @throws IOException
*/
public void createPdf(String filename, String text, boolean embedded, boolean subset) throws DocumentException, IOException {
// step 1
Document document = new Document();
// step 2
PdfWriter.getInstance(document, new FileOutputStream(filename));
// step 3
document.open();
// 英文编码
BaseFont bf = BaseFont.createFont(FONT, BaseFont.WINANSI, embedded); // 生成文件大小与编码有关,如果你没有中文,那么编码用BaseFont.WINANSI就节约很多资源了。
bf.setSubset(subset);
Font font = new Font(bf, 12);
document.add(new Paragraph(text, font));
// step 5
document.close();
} /**
* 合并文件
* @param files
* @param result
* @param smart 智能Copy
* @throws IOException
* @throws DocumentException
*/
public void mergeFiles(String[] files, String result, boolean smart) throws IOException, DocumentException {
Document document = new Document();
PdfCopy copy;
if (smart)
copy = new PdfSmartCopy(document, new FileOutputStream(result));
else
copy = new PdfCopy(document, new FileOutputStream(result));
document.open();
PdfReader[] reader = new PdfReader[FILE_NUM];
for (int i = 0; i < files.length; i++) {
reader[i] = new PdfReader(files[i]);
copy.addDocument(reader[i]);
copy.freeReader(reader[i]);
reader[i].close();
}
document.close();
} /**
* 嵌入字体
* @param merged
* @param fontfile
* @param result
* @throws IOException
* @throws DocumentException
*/
private void embedFont(String merged, String fontfile, String result) throws IOException, DocumentException {
// the font file
RandomAccessFile raf = new RandomAccessFile(fontfile, "r");
byte fontbytes[] = new byte[(int)raf.length()];
raf.readFully(fontbytes);
raf.close();
// create a new stream for the font file
PdfStream stream = new PdfStream(fontbytes);
stream.flateCompress();
stream.put(PdfName.LENGTH1, new PdfNumber(fontbytes.length));
// create a reader object
PdfReader reader = new PdfReader(merged);
int n = reader.getXrefSize();
PdfObject object;
PdfDictionary font;
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream(result));
PdfName fontname = new PdfName(BaseFont.createFont(fontfile, BaseFont.WINANSI, BaseFont.NOT_EMBEDDED).getPostscriptFontName());
for (int i = 0; i < n; i++) {
object = reader.getPdfObject(i);
if (object == null || !object.isDictionary())
continue;
font = (PdfDictionary)object;
if (PdfName.FONTDESCRIPTOR.equals(font.get(PdfName.TYPE))
&& fontname.equals(font.get(PdfName.FONTNAME))) {
PdfIndirectObject objref = stamper.getWriter().addToBody(stream);
font.put(PdfName.FONTFILE2, objref.getIndirectReference());
}
}
stamper.close();
reader.close();
}
}
在英文C系列,独立文件和智能合并的文件属性都是
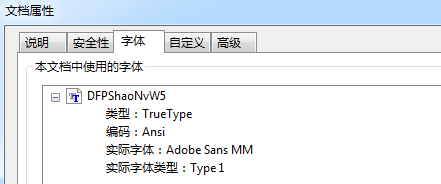
而手动嵌入字体的则是
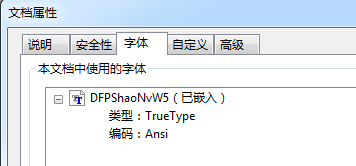
所以得出结论:
A系列相当于正常使用,基本都是默认值。对于嵌入字体需求的:
无论你是中文文档还是英文文档,就选择B系列,因为无论生成的独立文件还是合并文件都已嵌入字体。并且大小已是极限了。

C系列的话,注意除了手动嵌入方法,其它情况都不嵌入的。这意味着什么呢?【已嵌入子集】【已嵌入】,则表示你的字体不会发生变化。如果不带这个,就会造成:如果你换了个没有这种字体的系统,字体会显示为当前系统的默认字体。如下是我打开的
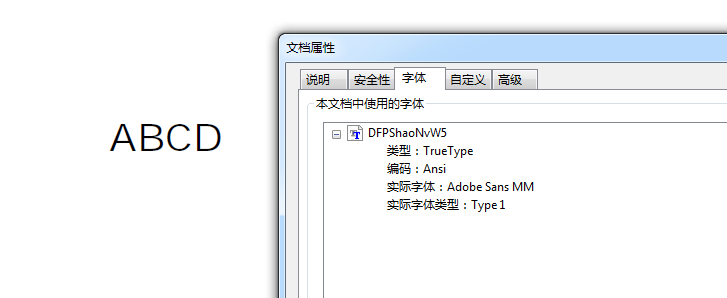
中文系列则应该是
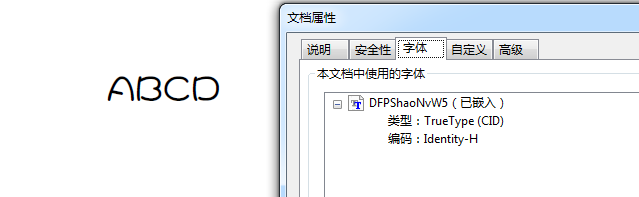
这仅仅对于有嵌入字体需求的,正常输出PDF的话不用考虑这么多,因为默认subset=true,PDF仅仅包含用到的字形。
还有一点,重复试验之后,发现只有你已使用的字体,才可以嵌入。PDF中未用到的字体是无法嵌入的。
package com.demo.pdf; import com.itextpdf.text.Document;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Font;
import com.itextpdf.text.Paragraph;
import com.itextpdf.text.pdf.*; import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.RandomAccessFile; /**
* 合并文档 & 嵌入字体
*/
public class MergeAndAddFont2 {
public static final String FONT = "pdf/华庚少女字体.ttf";
public static final String FONT_FILE = "pdf/simsun.ttc"; public static final String SRC_PDF = "pdf/testD0.pdf"; public static void main(String[] args) throws DocumentException, IOException { File file = new File(SRC_PDF);
file.getParentFile().mkdirs();
MergeAndAddFont2 app = new MergeAndAddFont2(); app.createPdf(SRC_PDF, "琪亚娜·卡斯兰娜", true, false); app.embedFont(SRC_PDF, FONT_FILE, "pdf/testD_embedded.pdf");
} public void createPdf(String filename, String text, boolean embedded, boolean subset) throws DocumentException, IOException {
// step 1
Document document = new Document();
// step 2
PdfWriter.getInstance(document, new FileOutputStream(filename));
// step 3
document.open();
// step 4
BaseFont bf = BaseFont.createFont(FONT, BaseFont.IDENTITY_H, embedded);
bf.setSubset(subset);
Font font = new Font(bf, 12);
document.add(new Paragraph(text, font));
// step 5
document.close();
} /**
* 嵌入字体
* @param src
* @param fontfile ttc文件地址(pdf/simsun.ttc)
* @param result
* @throws IOException
* @throws DocumentException
*/
private void embedFont(String src, String fontfile, String result) throws IOException, DocumentException {
// 读取字体文件
RandomAccessFile raf = new RandomAccessFile(fontfile, "r");
byte fontbytes[] = new byte[(int)raf.length()];
raf.readFully(fontbytes);
raf.close();
// 创建一个字体文件流
PdfStream stream = new PdfStream(fontbytes);
stream.flateCompress();
stream.put(PdfName.LENGTH1, new PdfNumber(fontbytes.length));
// 读取已有的PDF
PdfReader reader = new PdfReader(src);
int n = reader.getXrefSize();
PdfObject object;
PdfDictionary font;
// 添加额外的内容到已有的PDF中
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream(result));
// 这里的字体文件应该是PDF中已有的字体【正常来讲,这里声明的字体应该和待嵌入的一致】
PdfName fontname = new PdfName(BaseFont.createFont(FONT, BaseFont.WINANSI, BaseFont.NOT_EMBEDDED).getPostscriptFontName());
// 遍历源文件,找到 /FontDescriptor,以及对应的字体。嵌入字体
for (int i = 0; i < n; i++) {
object = reader.getPdfObject(i);
// 为空或者不是目录,跳过
if (object == null || !object.isDictionary())
continue;
font = (PdfDictionary)object;
// 目录类型和名称
System.out.println(font.get(PdfName.TYPE) + "\t" + font.get(PdfName.FONTNAME));
if (PdfName.FONTDESCRIPTOR.equals(font.get(PdfName.TYPE)) && fontname.equals(font.get(PdfName.FONTNAME))) {
PdfIndirectObject objref = stamper.getWriter().addToBody(stream);
font.put(PdfName.FONTFILE2, objref.getIndirectReference());
}
}
stamper.close();
reader.close();
}
}
打印输出:
可以看到,源文件只有一种字体,就是 少女字体。而我们也成功的把宋体文件写进入了,至少表面上看是这样的。如下:

我们打开源文件
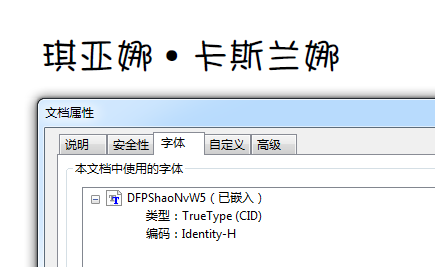
再来看我们期望的PDF文件,到底宋体进没进去呢。
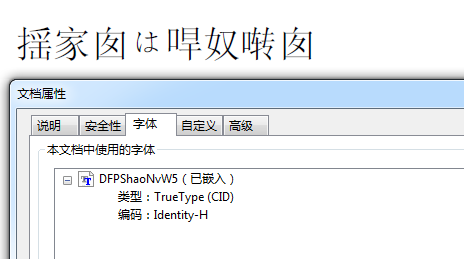
可以看到,虽然PDF体积增加了,但是字体文件并没有进去,还造成了乱码。所以,手动嵌入字体仅仅针对那些,已使用了某个字体,但是没有嵌入的情况。
BaseFont bf = BaseFont.createFont(FONT, BaseFont.IDENTITY_H, embedded); // 正常使用的话,embedded为true就能满足日常需求,subset使用默认值即可,不需设置。
条形码
package com.demo.pdf; import com.itextpdf.text.*;
import com.itextpdf.text.pdf.*; import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException; /**
* 条形码
*/
public class SmallTable {
public static final String FONT = "pdf/华庚少女字体.ttf";
public static final String DEST = "pdf/small_table.pdf"; public static void main(String[] args) throws IOException, DocumentException {
File file = new File(DEST);
file.getParentFile().mkdirs();
new SmallTable().createPdf(DEST);
}
public void createPdf(String dest) throws IOException, DocumentException {
Rectangle small = new Rectangle(290,100);
BaseFont bf = BaseFont.createFont(FONT, BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
Font font = new Font(bf, 12);
Document document = new Document(small, 5, 5, 5, 5);
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(dest));
document.open();
PdfPTable table = new PdfPTable(2);
table.setTotalWidth(new float[]{ 160, 120 });
table.setLockedWidth(true);
PdfContentByte cb = writer.getDirectContent();
// first row
PdfPCell cell = new PdfPCell(new Phrase("条形码", font));
cell.setFixedHeight(30);
cell.setBorder(Rectangle.NO_BORDER);
cell.setColspan(2);
cell.setHorizontalAlignment(PdfPCell.ALIGN_CENTER);
table.addCell(cell);
// second row
Barcode128 code128 = new Barcode128();
code128.setCode("14785236987541");
code128.setCodeType(Barcode128.CODE128);
Image code128Image = code128.createImageWithBarcode(cb, null, null);
cell = new PdfPCell(code128Image, true);
cell.setColspan(2);
cell.setHorizontalAlignment(PdfPCell.ALIGN_CENTER);
cell.setBorder(Rectangle.NO_BORDER);
cell.setFixedHeight(30);
table.addCell(cell); document.add(table);
document.close();
}
}
输出:
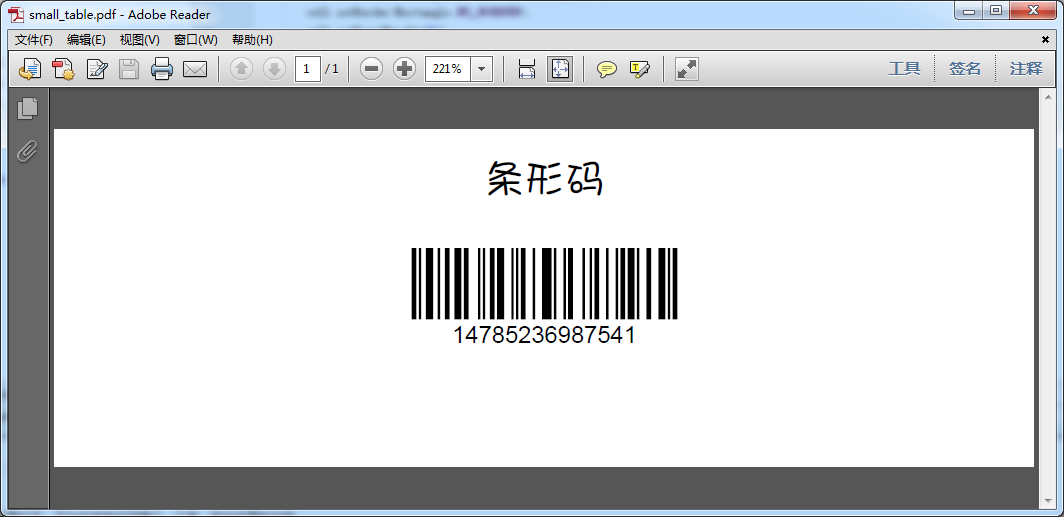
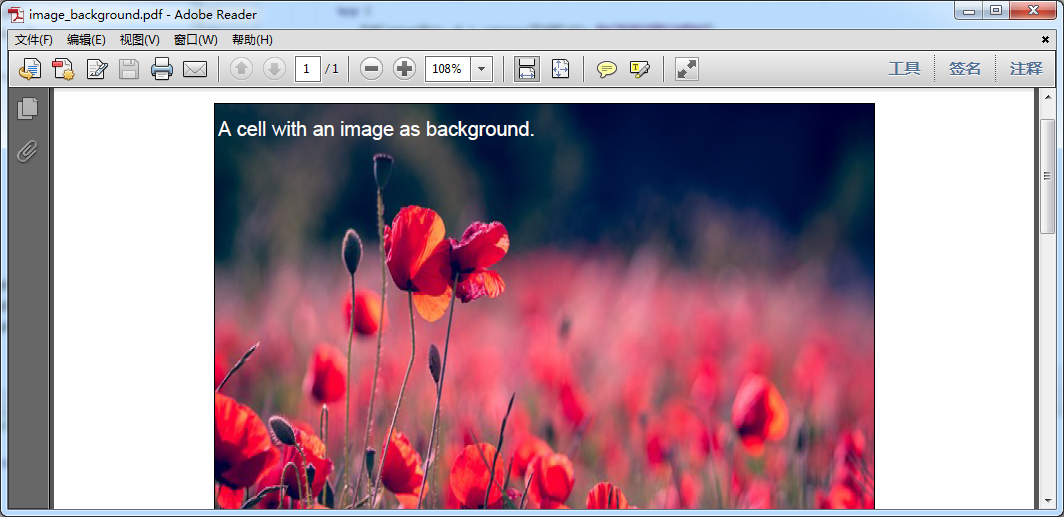
单元格以图片为背景
package com.demo.pdf; import com.itextpdf.text.*;
import com.itextpdf.text.pdf.*; import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException; /**
* 单元格图片背景
*/
public class ImageBackground {
class ImageBackgroundEvent implements PdfPCellEvent { protected Image image; public ImageBackgroundEvent(Image image) {
this.image = image;
} public void cellLayout(PdfPCell cell, Rectangle position, PdfContentByte[] canvases) {
try {
PdfContentByte cb = canvases[PdfPTable.BACKGROUNDCANVAS];
image.scaleAbsolute(position);
image.setAbsolutePosition(position.getLeft(), position.getBottom());
cb.addImage(image);
} catch (DocumentException e) {
throw new ExceptionConverter(e);
}
}
} public static final String DEST = "pdf/image_background.pdf";
public static final String IMG1 = "pdf/bruno.jpg"; public static void main(String[] args) throws IOException, DocumentException {
File file = new File(DEST);
file.getParentFile().mkdirs();
new ImageBackground().createPdf(DEST);
} public void createPdf(String dest) throws IOException, DocumentException {
Document document = new Document();
PdfWriter.getInstance(document, new FileOutputStream(dest));
document.open();
PdfPTable table = new PdfPTable(1);
table.setTotalWidth(400);
table.setLockedWidth(true);
PdfPCell cell = new PdfPCell();
Font font = new Font(Font.FontFamily.HELVETICA, 12, Font.NORMAL, GrayColor.GRAYWHITE);
Paragraph p = new Paragraph("A cell with an image as background.", font);
cell.addElement(p);
Image image = Image.getInstance(IMG1);
cell.setCellEvent(new ImageBackgroundEvent(image));
cell.setFixedHeight(600 * image.getScaledHeight() / image.getScaledWidth());
table.addCell(cell);
document.add(table);
document.close();
}
}
输出:
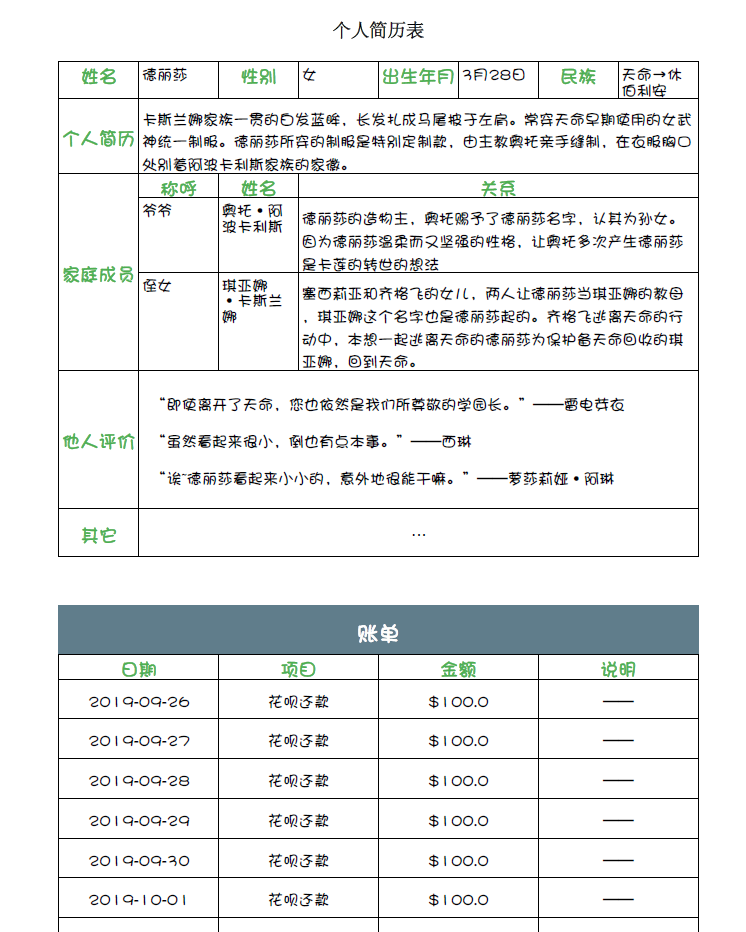
小示例(本人不才,简单画了个表格)
package com.demo.pdf; import com.itextpdf.text.*;
import com.itextpdf.text.pdf.BaseFont;
import com.itextpdf.text.pdf.PdfPCell;
import com.itextpdf.text.pdf.PdfPTable;
import com.itextpdf.text.pdf.PdfWriter; import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter; /**
* 一些示例
*/
public class Tables {
public static final String FONT = "pdf/华庚少女字体.ttf";
public static final String DEST = "pdf/tables.pdf"; public static void main(String[] args) throws IOException, DocumentException {
File file = new File(DEST);
file.getParentFile().mkdirs();
new Tables().createPdf(DEST);
}
public void createPdf(String dest) throws IOException, DocumentException {
Document document = new Document();
PdfWriter.getInstance(document, new FileOutputStream(dest));
document.open(); // 使用语言包字体
BaseFont abf = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H",BaseFont.NOT_EMBEDDED);
// 外部字体
BaseFont bf = BaseFont.createFont(FONT, BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
Font titleFont = new Font(bf, 12, Font.BOLD);
titleFont.setColor(new BaseColor(76,175,80));
Font font = new Font(bf, 10); Paragraph p = new Paragraph("个人简历表", new Font(abf, 12, Font.BOLD));
p.setAlignment(Paragraph.ALIGN_CENTER);
document.add(p); PdfPTable table = new PdfPTable(8);
table.setSpacingBefore(16f); PdfPCell cell = new PdfPCell(new Phrase("姓名", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
table.addCell(cell);
cell = new PdfPCell(new Phrase("德丽莎", font));
table.addCell(cell);
cell = new PdfPCell(new Phrase("性别", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
table.addCell(cell);
cell = new PdfPCell(new Phrase("女", font));
table.addCell(cell);
cell = new PdfPCell(new Phrase("出生年月", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
table.addCell(cell);
cell = new PdfPCell(new Phrase("3月28日", font));
table.addCell(cell);
cell = new PdfPCell(new Phrase("民族", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
table.addCell(cell);
cell = new PdfPCell(new Phrase("天命→休伯利安", font));
table.addCell(cell); cell = new PdfPCell(new Phrase("个人简历", titleFont));
cell.setVerticalAlignment(Element.ALIGN_MIDDLE);
table.addCell(cell);
cell = new PdfPCell();
cell.setColspan(7);
cell.addElement(new Paragraph("卡斯兰娜家族一贯的白发蓝眸,长发扎成马尾披于左肩。常穿天命早期使用的女武神统一制服。德丽莎所穿的制服是特别定制款,由主教奥托亲手缝制,在衣服胸口处别着阿波卡利斯家族的家徽。", font));
table.addCell(cell); cell = new PdfPCell(new Phrase("家庭成员", titleFont));
cell.setVerticalAlignment(PdfPCell.ALIGN_MIDDLE);
cell.setRowspan(3);
table.addCell(cell);
cell = new PdfPCell(new Phrase("称呼", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
table.addCell(cell);
cell = new PdfPCell(new Phrase("姓名", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
table.addCell(cell);
cell = new PdfPCell(new Phrase("关系", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setColspan(5);
table.addCell(cell); cell = new PdfPCell(new Phrase("爷爷", font));
table.addCell(cell);
cell = new PdfPCell(new Phrase("奥托·阿波卡利斯", font));
table.addCell(cell);
cell = new PdfPCell();
cell.addElement(new Paragraph("德丽莎的造物主,奥托赐予了德丽莎名字,认其为孙女。因为德丽莎温柔而又坚强的性格,让奥托多次产生德丽莎是卡莲的转世的想法", font));
cell.setColspan(5);
table.addCell(cell); cell = new PdfPCell(new Phrase("侄女", font));
table.addCell(cell);
cell = new PdfPCell(new Phrase("琪亚娜·卡斯兰娜", font));
table.addCell(cell);
cell = new PdfPCell();
cell.addElement(new Paragraph("塞西莉亚和齐格飞的女儿,两人让德丽莎当琪亚娜的教母,琪亚娜这个名字也是德丽莎起的。齐格飞逃离天命的行动中,本想一起逃离天命的德丽莎为保护备天命回收的琪亚娜,回到天命。", font));
cell.setColspan(5);
table.addCell(cell); cell = new PdfPCell(new Phrase("他人评价", titleFont));
cell.setVerticalAlignment(Element.ALIGN_MIDDLE);
table.addCell(cell);
cell = new PdfPCell();
cell.setColspan(7);
cell.setPaddingLeft(8f);
cell.setPaddingRight(8f);
cell.setPaddingBottom(16f);
// 配置行间距
cell.addElement(new Paragraph(24, "“即使离开了天命,您也依然是我们所尊敬的学园长。”——雷电芽衣\n" +
"“虽然看起来很小,倒也有点本事。”——西琳 \n" +
"“诶~德丽莎看起来小小的,意外地很能干嘛。”——萝莎莉娅·阿琳", font));
table.addCell(cell); cell = new PdfPCell(new Phrase("其它", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setVerticalAlignment(Element.ALIGN_MIDDLE);
table.addCell(cell);
cell = new PdfPCell(new Phrase("···"));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setVerticalAlignment(Element.ALIGN_MIDDLE);
cell.setFixedHeight(32f);
cell.setColspan(7);
table.addCell(cell);
document.add(table); // ------------------------------------------------ table = new PdfPTable(4);
table.setSpacingBefore(32f); Font titleFont2 = new Font(bf, 14, Font.BOLD);
titleFont2.setColor(new BaseColor(255,255,255)); cell = new PdfPCell(new Phrase("账单", titleFont2));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setVerticalAlignment(Element.ALIGN_MIDDLE);
cell.setColspan(4);
cell.setFixedHeight(32f);
cell.setBackgroundColor(new BaseColor(96, 125, 139));
cell.setBorder(Rectangle.NO_BORDER);
table.addCell(cell); cell = new PdfPCell(new Phrase("日期", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
table.addCell(cell);
cell = new PdfPCell(new Phrase("项目", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
table.addCell(cell);
cell = new PdfPCell(new Phrase("金额", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
table.addCell(cell);
cell = new PdfPCell(new Phrase("说明", titleFont));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
table.addCell(cell); LocalDateTime dt = LocalDateTime.now();
for (int i = 0; i < 10; i++){
dt = dt.plusDays(1L);
cell = new PdfPCell(new Phrase(dt.format(DateTimeFormatter.ofPattern("yyyy-MM-dd")), font));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setPadding(8f);
table.addCell(cell);
cell = new PdfPCell(new Phrase("花呗还款", font));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setPadding(8f);
table.addCell(cell);
cell = new PdfPCell(new Phrase("$100.0", font));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setPadding(8f);
table.addCell(cell);
cell = new PdfPCell(new Phrase("——", font));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setPadding(8f);
table.addCell(cell);
}
document.add(table); // ------------------------------------------------ document.newPage();
document.add(new Paragraph("芒种\n\n" +
"一想到你我就\n" +
"wu~~~~\n" +
"空恨别梦久\n" +
"wu~~~~\n" +
"烧去纸灰埋烟柳\n" +
"\n" +
"于鲜活的枝丫\n" +
"凋零下的无暇\n" +
"是收获谜底的代价\n" +
"\n" +
"余晖沾上 远行人的发\n" +
"他洒下手中牵挂\n" +
"于桥下\n" +
"前世迟来者~~~(擦肩而过)\n" +
"掌心刻~~~~~(来生记得)\n" +
"你眼中烟波滴落一滴墨 wo~~~\n" +
"若佛说~~~~~(无牵无挂)\n" +
"放下执着~~~~~(无相无色)\n" +
"我怎能 波澜不惊 去附和\n" +
"\n" +
"一想到你我就\n" +
"wu~~~~~\n" +
"恨情不寿 总于苦海囚\n" +
"wu~~~~~\n" +
"新翠徒留 落花影中游\n" +
"wu~~~~~\n" +
"相思无用 才笑山盟旧\n" +
"wu~~~~~\n" +
"谓我何求\n" +
"\n" +
"种一万朵莲花\n" +
"在众生中发芽\n" +
"等红尘一万种解答\n" +
"\n" +
"念珠落进 时间的泥沙\n" +
"待 割舍诠释慈悲\n" +
"的读法\n" +
"\n" +
"前世迟来者~~~(擦肩而过)\n" +
"掌心刻~~~~~(来生记得)\n" +
"你眼中烟波滴落一滴墨 wo~~~\n" +
"若佛说~~~~~(无牵无挂)\n" +
"放下执着~~~~~(无相无色)\n" +
"我怎能 波澜不惊 去附和", font)); document.close();
}
}
输出

页眉页脚
package com.demo.pdf; import com.itextpdf.text.*;
import com.itextpdf.text.pdf.*; import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Random; /**
* 页眉页脚
*/
public class PageNumber {
class Header extends PdfPageEventHelper { @Override
public void onStartPage(PdfWriter writer, Document document) {
PdfPTable table = new PdfPTable(1);
try {
Font font = new Font(BaseFont.createFont(FONT, BaseFont.IDENTITY_H, BaseFont.EMBEDDED), 10);
table.setTotalWidth(PageSize.A4.getWidth()); // A4大小
table.getDefaultCell().setFixedHeight(20);
PdfPCell cell = new PdfPCell(new Phrase("XXX生活支出明细", font));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setBorder(Rectangle.BOTTOM);
cell.setPaddingBottom(6f);
table.addCell(cell); PdfContentByte canvas = writer.getDirectContent();
table.writeSelectedRows(0, -1, ((document.right() + document.rightMargin())-PageSize.A4.getWidth())/2, document.top()+25, canvas);
} catch (DocumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} } @Override
public void onEndPage(PdfWriter writer, Document document) {
PdfPTable table = new PdfPTable(1);
try {
Font font = new Font(Font.FontFamily.SYMBOL, 10);
table.setTotalWidth(PageSize.A4.getWidth()); // A4大小
table.getDefaultCell().setFixedHeight(20);
table.getDefaultCell().setHorizontalAlignment(Element.ALIGN_CENTER);
table.getDefaultCell().setBorder(Rectangle.NO_BORDER);
table.addCell(new Phrase(writer.getPageNumber()+"", font)); PdfContentByte canvas = writer.getDirectContent();
table.writeSelectedRows(0, -1, ((document.right() + document.rightMargin())-PageSize.A4.getWidth())/2, document.bottom(), canvas);
} catch (Exception e) {
e.printStackTrace();
}
}
} public static final String DEST = "pdf/pdf_with_head_foot.pdf";
public static final String FONT = "pdf/华庚少女字体.ttf"; public static void main(String[] args) throws IOException, DocumentException {
File file = new File(DEST);
file.getParentFile().mkdirs();
new PageNumber().createPdf(DEST);
} public void createPdf(String dest) throws IOException, DocumentException {
Font font = new Font(BaseFont.createFont(FONT, BaseFont.IDENTITY_H, BaseFont.EMBEDDED), 10);
Document document = new Document(PageSize.A4.rotate());
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(dest));
writer.setPageEvent(new Header());
document.open();
PdfDictionary parameters = new PdfDictionary();
parameters.put(PdfName.MODDATE, new PdfDate());
PdfPTable table = new PdfPTable(3);
table.setTotalWidth(PageSize.A4.getWidth());
// 锁定宽度
table.setLockedWidth(true);
table.setWidths(new int[]{4, 4, 2});
PdfPCell cell = new PdfPCell(new Phrase("去向", font));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setPadding(8f);
table.addCell(cell);
cell = new PdfPCell(new Phrase("金额", font));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setPadding(8f);
table.addCell(cell);
cell = new PdfPCell(new Phrase("备注", font));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setPadding(8f);
table.addCell(cell); Random random = new Random();
for (int i = 0; i < 30; i++){
cell = new PdfPCell(new Phrase("花呗还款", font));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setPadding(8f);
table.addCell(cell);
cell = new PdfPCell(new Phrase("$" + random.nextInt(500), font));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setPadding(8f);
table.addCell(cell);
cell = new PdfPCell(new Phrase("——", font));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setPadding(8f);
table.addCell(cell);
}
document.add(table);
document.close();
} }
输出:
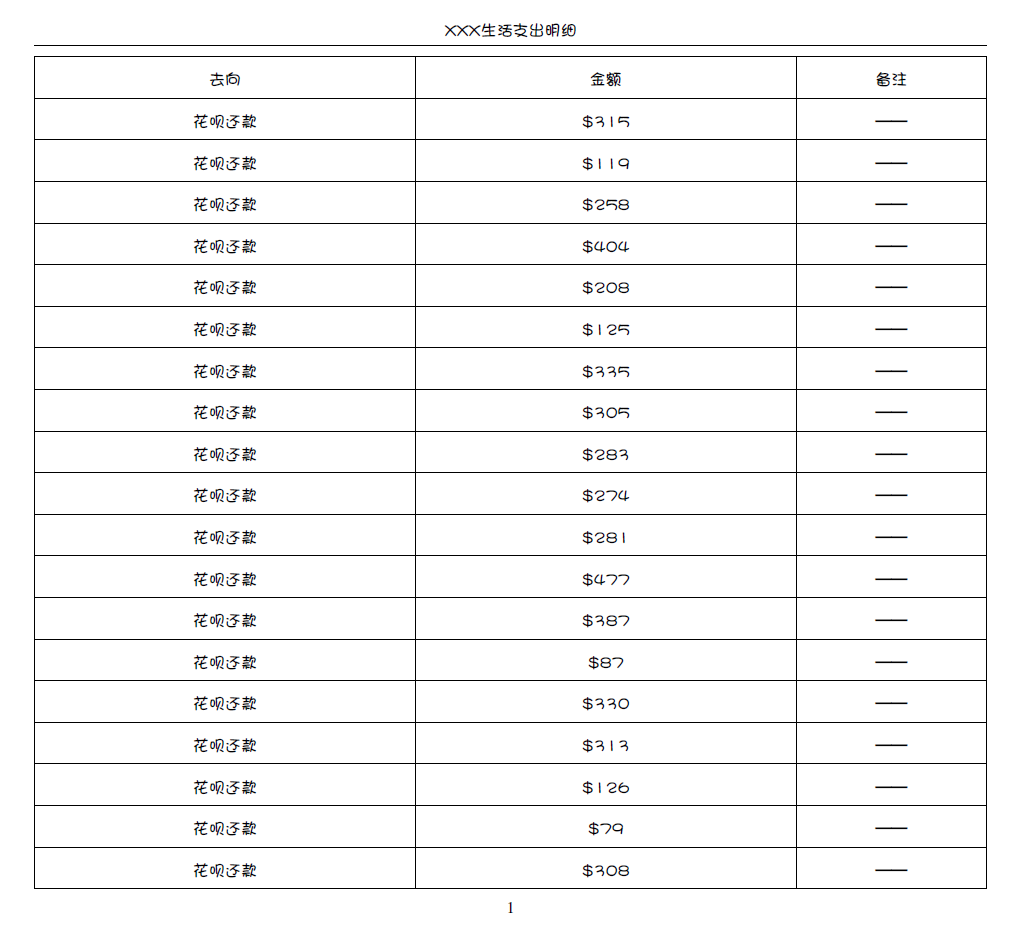
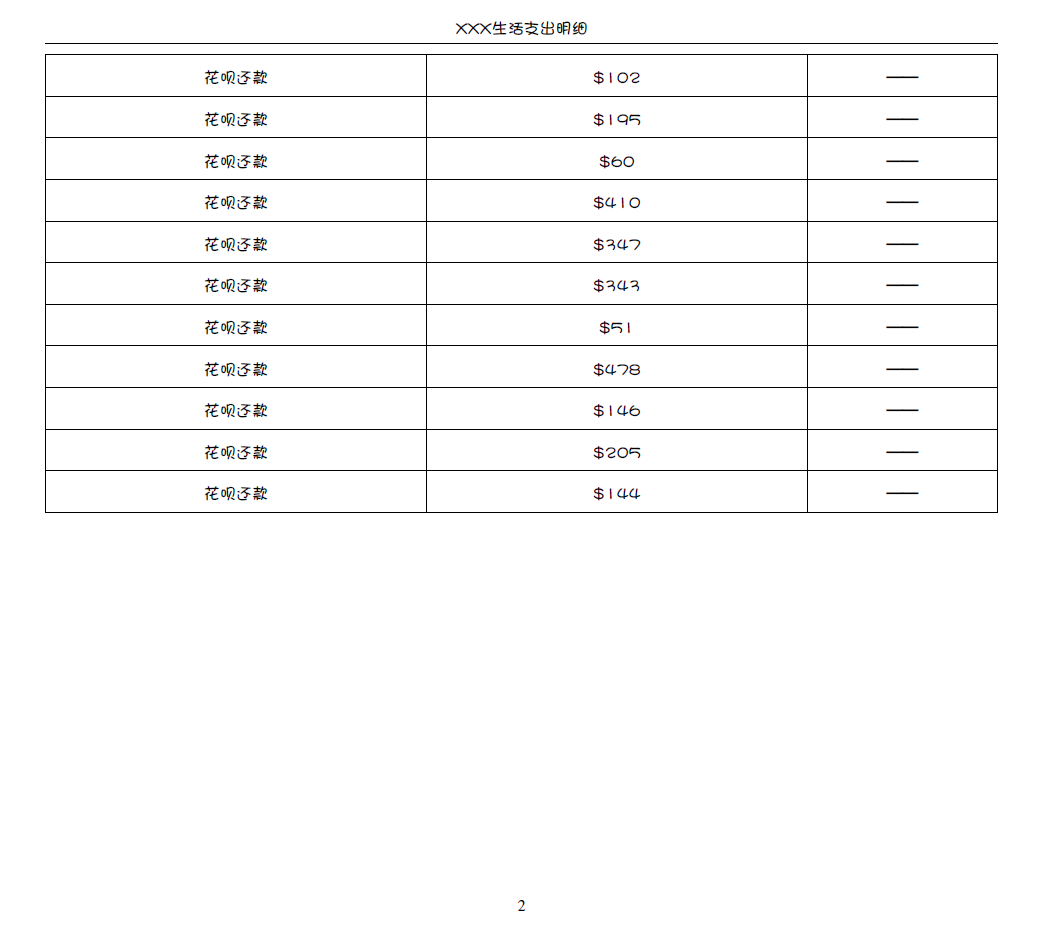
每一页具有相同的标题行或者页脚行
package com.demo.pdf; import com.itextpdf.text.*;
import com.itextpdf.text.pdf.GrayColor;
import com.itextpdf.text.pdf.PdfPCell;
import com.itextpdf.text.pdf.PdfPTable;
import com.itextpdf.text.pdf.PdfWriter; import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException; /**
* 跨页表格,每一页都有相同的页脚页眉行。
*/
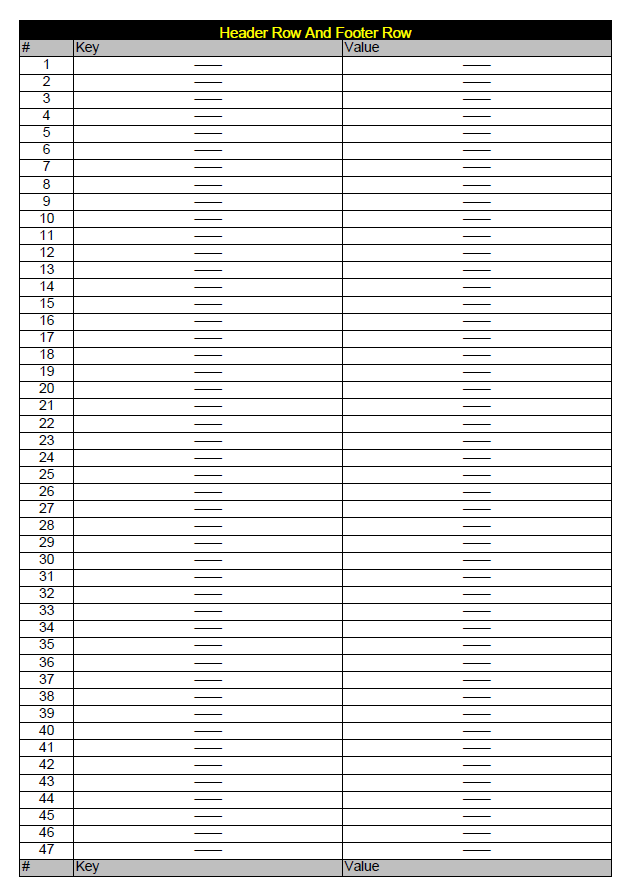
public class HeaderRowsTable {
public static final String DEST = "pdf/header_row_table.pdf"; public static void main(String[] args) throws IOException, DocumentException {
File file = new File(DEST);
file.getParentFile().mkdirs();
new HeaderRowsTable().createPdf(DEST);
}
public void createPdf(String dest) throws IOException, DocumentException {
Document document = new Document();
PdfWriter.getInstance(document, new FileOutputStream(dest));
document.open();
Font f = new Font(Font.FontFamily.HELVETICA, 13, Font.NORMAL, BaseColor.YELLOW); float[] columnWidths = {1, 5, 5};
PdfPTable table = new PdfPTable(columnWidths);
table.setWidthPercentage(100);
table.getDefaultCell().setUseAscender(true);
table.getDefaultCell().setUseDescender(true);
PdfPCell cell = new PdfPCell(new Phrase("Header Row And Footer Row", f));
cell.setBackgroundColor(GrayColor.GRAYBLACK);
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setColspan(3);
table.addCell(cell);
table.getDefaultCell().setBackgroundColor(new GrayColor(0.75f));
// 每个页面出现的页眉+页脚行数
for (int i = 0; i < 2; i++) {
table.addCell("#");
table.addCell("Key");
table.addCell("Value");
}
// 设置标题行数。只有将表添加到文档并且表跨页时,此配置才有意义。
table.setHeaderRows(3);
// 设置页脚行数。页眉行数 = 标题行数 - 页脚行数。比如此例子:每一页表格都有两行页眉行(3-1=2)和一行页脚行。
table.setFooterRows(1);
table.getDefaultCell().setBackgroundColor(GrayColor.GRAYWHITE);
table.getDefaultCell().setHorizontalAlignment(Element.ALIGN_CENTER);
for (int counter = 1; counter < 51; counter++) {
table.addCell(String.valueOf(counter));
table.addCell("—— ");
table.addCell("—— ");
}
document.add(table); document.newPage();
table = new PdfPTable(columnWidths);
table.setSpacingBefore(32f);
table.setWidthPercentage(100);
table.getDefaultCell().setUseAscender(true);
table.getDefaultCell().setUseDescender(true);
cell = new PdfPCell(new Phrase("Only Have Header Row", f));
cell.setBackgroundColor(GrayColor.GRAYBLACK);
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setColspan(3);
table.addCell(cell);
table.getDefaultCell().setBackgroundColor(new GrayColor(0.75f));
// 每个页面出现的页眉+页脚行数
for (int i = 0; i < 1; i++) {
table.addCell("#");
table.addCell("Key");
table.addCell("Value");
}
// 也可以仅仅设置页眉行
table.setHeaderRows(2);
table.getDefaultCell().setBackgroundColor(GrayColor.GRAYWHITE);
table.getDefaultCell().setHorizontalAlignment(Element.ALIGN_CENTER);
for (int counter = 1; counter < 51; counter++) {
table.addCell(String.valueOf(counter));
table.addCell("—— ");
table.addCell("—— ");
}
document.add(table); document.newPage();
table = new PdfPTable(columnWidths);
table.setSpacingBefore(32f);
table.setWidthPercentage(100);
table.getDefaultCell().setUseAscender(true);
table.getDefaultCell().setUseDescender(true);
table.getDefaultCell().setBackgroundColor(new BaseColor(133,148,6));
// 每个页面出现的页眉+页脚行数(数量与setHeaderRows(2)一致。为什么前面示例都是少1呢?因为前面示例已经单独添加了一行主标题)
for (int i = 0; i < 2; i++) {
table.addCell(new Phrase("#", f));
table.addCell(new Phrase("Key", f));
table.addCell(new Phrase("Value", f));
}
table.setHeaderRows(2);
table.setFooterRows(1);
table.getDefaultCell().setBackgroundColor(GrayColor.GRAYWHITE);
table.getDefaultCell().setHorizontalAlignment(Element.ALIGN_CENTER);
for (int counter = 1; counter < 51; counter++) {
table.addCell(String.valueOf(counter));
table.addCell("—— ");
table.addCell("—— ");
}
document.add(table); document.close();
}
}
结果:(一共三种示例,自行去比较)
Java利用IText导出PDF(更新)的更多相关文章
- java利用itext导出pdf
项目中有一功能是导出历史记录,可以导出pdf和excel,这里先说导出pdf.在网上查可以用那些方式导出pdf,用itext比较多广泛. 导出pdf可以使用两种方式,一是可以根据已有的pdf模板,进行 ...
- 新知识:Java 利用itext填写pdf模板并导出(昨天奋战到深夜四点,知道今天两点终于弄懂)
废话少说,不懂itext干啥用的直接去百度吧. ***************制作模板******************* 1.先用word做出界面 2.再转换成pdf格式 3.用Adobe Acr ...
- 利用itext导出PDF的小例子
我这边使用的jar包: itext-2.1.7.jar itextasian-1.5.2.jar 代码,简单的小例子,导出pdf: PdfService.java: package com.cy.se ...
- Itext导出PDF,word,图片案例
iText导出pdf.word.图片 一.前言 在企业的信息系统中,报表处理一直占比较重要的作用,本文将介绍一种生成PDF报表的Java组件--iText.通过在服务器端使用Jsp或JavaBean生 ...
- 利用FR导出PDF汉字乱码的处理
利用FR导出pdf,然后在unigui中显示,发现汉字乱码,改成gb2312,不乱码,但不自动折行,最后是改成DefaultCharSet搞定.FR版本:5.4.6 后记:有的浏览器中还是乱码,把字体 ...
- java根据模板导出PDF(利用itext)
一.制作模板 1.下载Adobe Acrobat 9 Pro软件(pdf编辑器),制作模板必须使用该工具. 2.下载itextpdf-5.5.5.jar.itext-asian-5.2.0.j ...
- Java利用模板生成pdf并导出
1.准备工作 (1)Adobe Acrobat pro软件:用来制作导出模板 (2)itext的jar包 2.开始制作pdf模板 (1)先用word做出模板界面 (2)文件另存为pdf格式文件 (3) ...
- iText导出PDF(图片,水印,页眉,页脚)
项目需要导出PDF,导出的内容包含图片和文本,而且图片的数量不确定,在网上百度发现大家都在用iText,在官网发现可以把html转换为PDF,但是需要收费,那就只能自己写了. 在开始之前先在网上百度了 ...
- iText导出pdf、word、图片
一.前言 在企业的信息系统中,报表处理一直占比较重要的作用,本文将介绍一种生成PDF报表的Java组件--iText.通过在服务器端使用Jsp或JavaBean生成PDF报表,客户端采用超级连接显示或 ...
随机推荐
- Python基础14
P73. 内嵌函数的讲解介绍 内部函数,书中讲的应用较简单,后面找篇具体的文章学习下
- Tp5 空模块、空控制器、空方法的处理
1.空模块处理 如果是开启了路由 可直接找到route.php文件,具体的位置看个人放置的位置,在里面新增一个语句 '__miss__' => ['portal/index/errorMsg', ...
- Caml 多表关联查询
using (SPSite site = new SPSite(SiteUrl)) { using (SPWeb web = site.RootWeb) { SPQuery query = new S ...
- Jira未授权SSRF漏洞复现(CVE-2019-8451)
0x00 漏洞背景 Jira的/plugins/servlet/gadgets/makeRequest资源存在SSRF漏洞,原因在于JiraWhitelist这个类的逻辑缺陷,成功利用此漏洞的远程攻击 ...
- mysql中的where和having的区别
下面以一个例子来具体的讲解: 1. where和having都可以使用的场景 1)select addtime,name from dw_users where addtime> 1500000 ...
- MySQL的select多表查询
select 语句: select 语句一般用法为: select 字段名 from tb_name where 条件 ; select 查询语句类型一般分为三种: 单表查询,多表查询,子查询 最简 ...
- 可变lambda, lambda使用mutable关键字
关于lambda的捕获和调用 C++ primer上对可变lambda举的例子如下: size_t v1=42; auto f=[v1] () mutable{return ++v1; }; v1=0 ...
- 12-cmake语法-内部变量-系统信息
系统信息 CMAKE_MAJOR_VERSION CMAKE 主版本号,比如 2.4.6 中的 2 CMAKE_MINOR_VERSION CMAKE 次版本号,比如 2.4.6 中的 4 CMAKE ...
- 【java】new Date什么样
Thu Nov 21 10:39:40 GMT+08:00 2019 getDate() 从 Date 对象返回一个月中的某一天 (1 ~ 31).getDay() 从 Date 对象返回一周中的某一 ...
- 使用plv8+ shortid npm包构建一个短唯一id服务
plv8 是一个很强大的pg 扩展插件,我们可以直接额使用js 增强sql ,shortid 是一个用来生成短连接id 很方便的类库 因为shortid 是一个npm 模块,我们需要使用一种方法使用r ...