SparkStreaming之checkpoint检查点
一.简介
流应用程序必须保证7*24全天候运行,因此必须能够适应与程序逻辑无关的故障【例如:系统故障、JVM崩溃等】。为了实现这一点,SparkStreaming需要将足够的信息保存到容错存储系统中,以便它可以从故障中恢复。
检查点有两种类型。
1.元数据检查点
将定义流式计算的信息保存到容错存储系统【如HDFS等】。这用于从运行流应用程序所在的节点的故障中恢复。
元数据包括:
1.配置
用于创建流应用程序的配置。
2.DStream操作
定义流应用程序的DStream操作集。
3.不完整的批次
在任务队列中而尚未完成的批次。
2.数据检查点
将生成的RDD保存到可靠的存储系统。在一些跨多个批次组合数据的有状态转换中,这是必须的。在这种转换中,生成的RDD依赖于先前批次的RDD,这导致依赖关系链的长度随着时间而增加。为了避免恢复时间的这种无限增加【与依赖链成正比】,有状态变换的中间RDD周期性地检查以存储到可靠的存储系统中,以切断依赖链。
总而言之,元数据检查点主要用于从节点故障中恢复,而如果使用状态转换,即使对于基本功能也需要数据或RDD检查点。
二.需要设置检查点的情况
1.有状态转换的使用,如果在应用程序中使用了updateStateByKey或reduceByKeyAndWindow,则必须提供检查点以缓存之前批次的中间结果。
2.从运行应用程序的节点故障中恢复,元数据检查点用于使用进度信息进行恢复。
备注:在没有上述状态转换的简单流应用程序中可以不使用检查点。在这种情况下,节点故障的恢复将是部分性的【某些以接收但未处理的数据可能会丢失】。
三.配置检查点
可以通过在容错,可靠的文件系统【例如:HDFS、S3或Windows文件系统】中设置目录来启用检查点,检查点信息将保存到该文件系统中。使用:streamingContext.checkpoint(checkpointDirectory)来设置的。这将允许使用上述状态转换。此外,如果要使应用程序从节点故障中恢复,则应重写流应用程序以使其具有以下行为。
1.当程序首次启动时,它将创建一个新的StreamingContext,设置所有流后调用start()。
2.当程序在失败后重新启动时,它将从检查点目录中的检查点数据重新创建StreamingContext。
四.代码实现
package big.data.analyse.streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by zhen on 2019/8/15.
*/
object Checkpoint {
def functionToCreateContext():StreamingContext = {
val conf = new SparkConf().setMaster("local[2]").setAppName("StreaingTest")
val ssc = new StreamingContext(conf, Seconds(10))
val lines = ssc.socketTextStream("192.168.245.137", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word=>(word,1)).reduceByKey(_+_)
pairs.foreachRDD(row => row.foreach(println))
ssc.checkpoint("D:\\checkpoint")
ssc
}
def main(args: Array[String]) {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别
/**
* 获取入口及设置checkpoint检查点
*/
val ssc = StreamingContext.getOrCreate("D:\\checkpoint", functionToCreateContext _)
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
五.结果
入参:
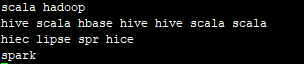
结果:

六.总结
1.需要确保节点进程在失败时会自动重启,这只能通过部署基础结构来完成。
2.检查点的默认间隔是批处理间隔的倍数,且至少为10秒。通常DStream的5~10个滑动间隔为检查点间隔是一个很好的设置。
SparkStreaming之checkpoint检查点的更多相关文章
- spark-streaming的checkpoint机制源码分析
转发请注明原创地址 http://www.cnblogs.com/dongxiao-yang/p/7994357.html spark-streaming定时对 DStreamGraph 和 JobS ...
- SparkStreaming使用checkpoint存在的问题及解决方案
sparkstreaming关于偏移量的管理 在 Direct DStream初始化的时候,需要指定一个包含每个topic的每个分区的offset用于让Direct DStream从指定位置读取数据. ...
- 转 SQL Server中关于的checkpoint使用说明
在SQL Server中有一个非常重要的命令就是CheckPoint,它主要作用是把缓存中的数据写入mdf文件中. 其实在我们进行insert, update, delete时,数据并没有直接写入数据 ...
- 数据库事务故障恢复undo日志检查点
checkpoint 检查点 checkpoint,即检查点.在undolog中写入检查点,表示在checkpoint前的事务都已经完成commit或者rollback 了,也就是检查点前面的事务 ...
- Checkpoint 和Breakpoint
参考:http://www.cnblogs.com/qiangshu/p/5241699.htmlhttp://www.cnblogs.com/biwork/p/3366724.html 1. Che ...
- 在sparkStreaming实时存储时的问题
1.实时插入mysql时遇到的问题,使用的updateStaeBykey有状态的算子 必须设置checkpoint 如果报错直接删掉checkpoint 在创建的时候自己保存偏移量即可 再次启动时读 ...
- mysql的checkpoint
上一章的结尾我们留下了一个问题,就是在上一章所介绍的模型中,恢复管理器必须要通过全篇扫描整个undolog进行日志恢复,这样做显然是没有太大必要的,因为系统中断肯定是在最后几个事务受到影响,前面的事务 ...
- Checkpoint & cache & persist
checkpoint checkpoint(检查点)是Spark为了避免长链路,大计算量的Rdd不可用时,需要长时间恢复而引入的.主要就是将通过大量计算而获得的这类Rdd的数据直接持久化到外部可靠的存 ...
- FusionInsight大数据开发---SparkStreaming概述
SparkStreaming概述 SparkStreaming是Spark核心API的一个扩展,它对实时流式数据的处理具有可扩展性.高吞吐量.可容错性等特点. SparkStreaming原理 Spa ...
随机推荐
- emacs第一天
emacsbinw64.sourceforge.net windows的emacs下载地方(绿色软件) 学习快速入门 C-h t 快速入门的帮助文档 C-h 是prefix key 光标移动快捷键 ...
- 网络协议 9 - TCP协议(下)
上次了解了 TCP 建立连接与断开连接的过程,我们发现,TCP 会通过各种“套路”来保证传输数据的安全.除此之外,我们还大概了解了 TCP 包头格式所对应解决的五个问题:顺序问题.丢包问题.连接维护. ...
- PATA1012The Best Rank(25分)
To evaluate the performance of our first year CS majored students, we consider their grades of three ...
- html规范思维导图(仅限于自己)
- cad.net 图层隐藏 IsHidden 用法 eDuplicateRecordName 报错
提要:影响图层显示的主要有:关闭 isOff冻结 IsFrozen 图层隐藏 isHidden视口冻结 FreezeLayersInViewport 今天小博发现了一件事情 ...
- magic模块 :Exception Value:failed to find libmagic. Check your installation
原因 缺少安装依赖: magic 安装依赖: https://github.com/ahupp/python-magic#dependencies windows下解决方法: https://gith ...
- .Net Core 基于 SnmpSharpNet 开发
SNMP简介(百度百科): SNMP 是专门设计用于在 IP 网络管理网络节点(服务器.工作站.路由器.交换机及HUBS等)的一种标准协议,它是一种应用层协议. SNMP 使网络管理员能够管理网络效能 ...
- SQL Server ----- 备份数据库 生成(.bak)文件
转移数据库 备份数据库 选中数据库 进入后界面如图 选择合适位置进行备份 注意:选择配置好保存位置的 成功后出现 如果出现错误. 还有一种可能是哪个文件夹中已经有了一个 把文件家中的那个删了 还原 ...
- php开始,html应用的一些不错收藏
来源:http://happymc.iteye.com/link?tag=%E4%B8%AA%E4%BA%BA%E6%94%B6%E8%97%8F%E7%9A%84%E5%A5%BD%E7%BD%91 ...
- sql中筛选第一条记录【分组排序】
问题描述 我们现在有一张表titles,共有4个字段,分别是emp_no(员工编号),title(职位),from_date(起始时间),to_date(结束时间),记录的是员工在某个时间段内职位名称 ...