Redis读写分离(三)
1、redis高并发跟整个系统的高并发之间的关系
redis,要搞高并发的话,不可避免,要把底层的缓存搞得很好
mysql,高并发,做到了,那么也是通过一系列复杂的分库分表,订单系统,事务要求的,QPS到几万,比较高了
要做一些电商的商品详情页,真正的超高并发,QPS上十万,甚至是百万,一秒钟百万的请求量
光是redis是不够的,但是redis是整个大型的缓存架构中,支撑高并发的架构里面,非常重要的一个环节
首先,你的底层的缓存中间件,缓存系统,必须能够支撑的起那种高并发,其次,再经过良好的整体的缓存架构的设计(多级缓存架构、热点缓存),支撑真正的上十万,甚至上百万的高并发
2、redis不能支撑高并发的瓶颈在哪里?
单机
3、如果redis要支撑超过10万+的并发,那应该怎么做?
单机的redis几乎不太可能说QPS超过10万+,除非一些特殊情况,比如你的机器性能特别好,配置特别高,物理机,维护做的特别好,而且你的整体的操作不是太复杂
单机在几万
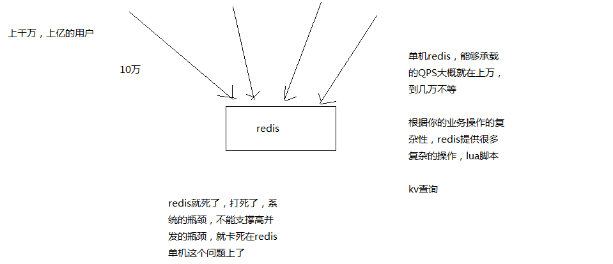
读写分离,对缓存,一般都是用来支撑读高并发的,写的请求是比较少的,可能写请求也就一秒钟几千,一两千
大量的请求都是读,一秒钟二十万次读
读写分离:一主多从
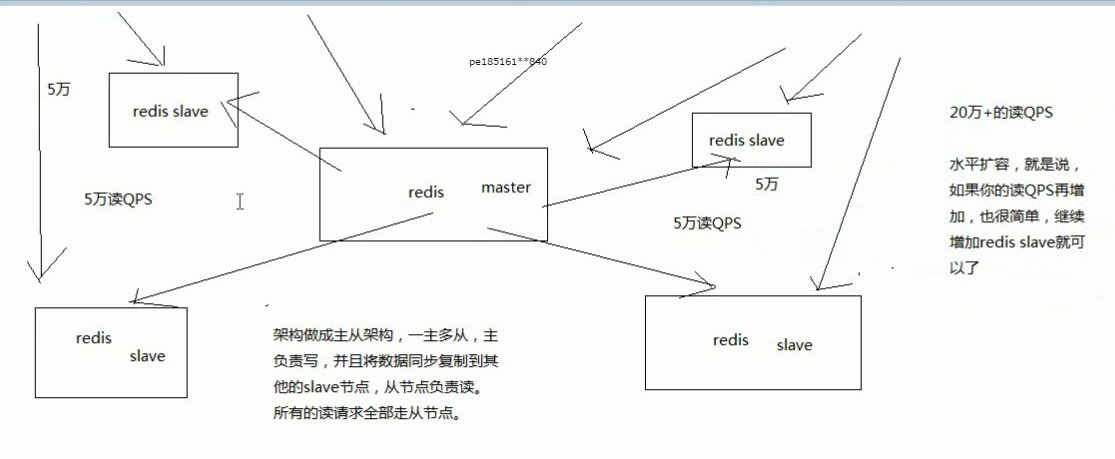
主从架构 -> 读写分离 -> 支撑10万+读QPS的架构
redis replication
redis主从架构 -> 读写分离架构 -> 可支持水平扩展的读高并发架构
2、redis replication的核心机制
(1)redis采用异步方式复制数据到slave节点,不过redis 2.8开始,slave node会周期性地确认自己每次复制的数据量
(2)一个master node是可以配置多个slave node的
(3)slave node也可以连接其他的slave node
(4)slave node做复制的时候,是不会block master node的正常工作的
(5)slave node在做复制的时候,也不会block对自己的查询操作,它会用旧的数据集来提供服务;
但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了
(6)slave node主要用来进行横向扩容,做读写分离,扩容的slave node可以提高读的吞吐量
slave,高可用性,有很大的关系
3、master持久化对于主从架构的安全保障的意义
如果采用了主从架构,那么建议必须开启master node的持久化!
不建议用slave node作为master node的数据热备,因为那样的话,如果你关掉master的持久化,可能在master宕机重启的时候数据是空的,然后可能一经过复制,salve node数据也丢了
master -> RDB和AOF都关闭了 -> 全部在内存中
master就会将空的数据集同步到slave上去,所有slave的数据全部清空
100%的数据丢失
master节点,必须要使用持久化机制
master的各种备份方案,要不要做,万一说本地的所有文件丢失了; 从备份中挑选一份rdb去恢复master; 这样才能确保master启动的时候,是有数据的
slave node可以自动接管master node,但是也可能sentinal还没有检测到master failure,master node就自动重启了,还是可能导致上面的所有slave node数据清空故障
1、主从架构的核心原理
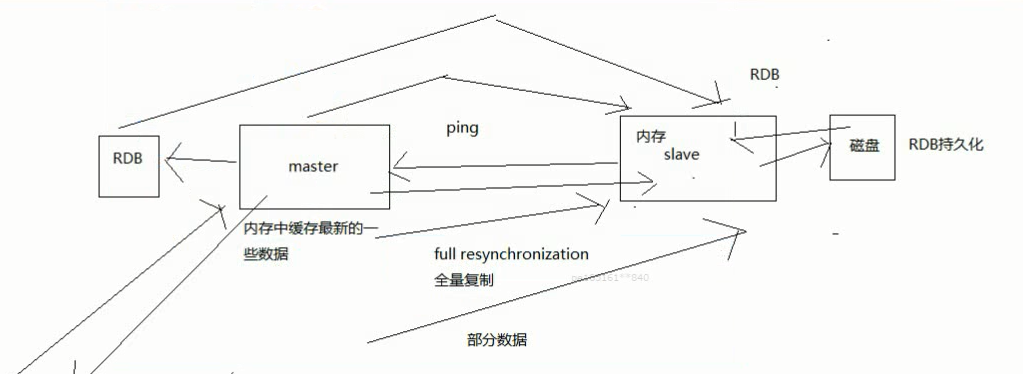
当启动一个slave node的时候,它会发送一个PSYNC命令给master node
如果这是slave node重新连接master node,那么master node仅仅会复制给slave部分缺少的数据;
否则如果是slave node第一次连接master node,那么会触发一次full resynchronization
开始full resynchronization的时候,master会启动一个后台线程,开始生成一份RDB快照文件,同时还会将从客户端收到的所有写命令缓存在内存中。
RDB文件生成完毕之后,master会将这个RDB发送给slave,slave会先写入本地磁盘,然后再从本地磁盘加载到内存中。
然后master会将内存中缓存的写命令发送给slave,slave也会同步这些数据。
slave node如果跟master node有网络故障,断开了连接,会自动重连。master如果发现有多个slave node都来重新连接,仅仅会启动一个rdb save操作,用一份数据服务所有slave node。
2、主从复制的断点续传
从redis 2.8开始,就支持主从复制的断点续传,如果主从复制过程中,网络连接断掉了,那么可以接着上次复制的地方,继续复制下去,而不是从头开始复制一份
master node会在内存中常见一个backlog,master和slave都会保存一个replica offset还有一个master id,offset就是保存在backlog中的。如果master和slave网络连接断掉了,slave会让master从上次的replica offset开始继续复制
但是如果没有找到对应的offset,那么就会执行一次resynchronization
3、无磁盘化复制
master在内存中直接创建rdb,然后发送给slave,不会在自己本地落地磁盘了
repl-diskless-sync
repl-diskless-sync-delay,等待一定时长再开始复制,因为要等更多slave重新连接过来
4、过期key处理
slave不会过期key,只会等待master过期key。如果master过期了一个key,或者通过LRU淘汰了一个key,那么会模拟一条del命令发送给slave。
5.复制的完整流程
(1)slave node启动,仅仅保存master node的信息,包括master node的host和ip,但是复制流程没开始
master host和ip是从哪儿来的,redis.conf里面的slaveof配置的
(2)slave node内部有个定时任务,每秒检查是否有新的master node要连接和复制,如果发现,就跟master node建立socket网络连接
(3)slave node发送ping命令给master node
(4)口令认证,如果master设置了requirepass,那么salve node必须发送masterauth的口令过去进行认证
(5)master node第一次执行全量复制,将所有数据发给slave node
(6)master node后续持续将写命令,异步复制给slave node

6、数据同步相关的核心机制
指的第一次slave连接msater的时候,执行的全量复制
(1)master和slave都会维护一个offset
master会在自身不断累加offset,slave也会在自身不断累加offset
slave每秒都会上报自己的offset给master,同时master也会保存每个slave的offset
主要是master和slave都要知道各自的数据的offset,才能知道互相之间的数据不一致的情况
(2)backlog
master node有一个backlog,默认是1MB大小
master node给slave node复制数据时,也会将数据在backlog中同步写一份
backlog主要是用来做全量复制中断时候的增量复制的
(3)master run id
info server,可以看到master run id
如果根据host+ip定位master node,是不靠谱的,如果master node重启或者数据出现了变化,那么slave node应该根据不同的run id区分,run id不同就做全量复制
如果需要不更改run id重启redis,可以使用redis-cli debug reload命令
(4)psync
从节点使用psync从master node进行复制,psync runid offset
master node会根据自身的情况返回响应信息,可能是FULLRESYNC runid offset触发全量复制,可能是CONTINUE触发增量复制
3、全量复制
(1)master执行bgsave,在本地生成一份rdb快照文件
(2)master node将rdb快照文件发送给salve node,如果rdb复制时间超过60秒(repl-timeout),那么slave node就会认为复制失败,可以适当调节大这个参数
(3)对于千兆网卡的机器,一般每秒传输100MB,6G文件,很可能超过60s
(4)master node在生成rdb时,会将所有新的写命令缓存在内存中,在salve node保存了rdb之后,再将新的写命令复制给salve node
(5)client-output-buffer-limit slave 256MB 64MB 60,如果在复制期间,内存缓冲区持续消耗超过64MB,或者一次性超过256MB,那么停止复制,复制失败
(6)slave node接收到rdb之后,清空自己的旧数据,然后重新加载rdb到自己的内存中,同时基于旧的数据版本对外提供服务
(7)如果slave node开启了AOF,那么会立即执行BGREWRITEAOF,重写AOF
rdb生成、rdb通过网络拷贝、slave旧数据的清理、slave aof rewrite,很耗费时间
如果复制的数据量在4G~6G之间,那么很可能全量复制时间消耗到1分半到2分钟
4、增量复制
(1)如果全量复制过程中,master-slave网络连接断掉,那么salve重新连接master时,会触发增量复制
(2)master直接从自己的backlog中获取部分丢失的数据,发送给slave node,默认backlog就是1MB
(3)msater就是根据slave发送的psync中的offset来从backlog中获取数据的
5、heartbeat
主从节点互相都会发送heartbeat信息
master默认每隔10秒发送一次heartbeat,salve node每隔1秒发送一个heartbeat
6、异步复制
master每次接收到写命令之后,现在内部写入数据,然后异步发送给slave node
Redis读写分离(三)的更多相关文章
- Redis读写分离技术解析
背景 云数据库Redis版不管主从版还是集群规格,replica作为备库不对外提供服务,只有在发生HA的时候,replica提升为master后才承担读写流量.这种架构读写请求都在master上完成, ...
- redis读写分离及可用性设计
Redis缓存架构设计 对于下面两个架构图,有如下想法: 1)redis主从复制模式,为了解决master读写压力,对master进行写操作,对slave进行读操作. 2)而在分片集群中,如果对部分分 ...
- Redis读写分离的简单配置
Master进行写操作,可能只需要一台Master.进行写操作,关闭数据持久化. Slave进行读操作,可能需要多台Slave.进行读操作,打开数据持久化. 假设初始配置有Master服务器为A,sl ...
- 在 Istio 中实现 Redis 集群的数据分片、读写分离和流量镜像
Redis 是一个高性能的 key-value 存储系统,被广泛用于微服务架构中.如果我们想要使用 Redis 集群模式提供的高级特性,则需要对客户端代码进行改动,这带来了应用升级和维护的一些困难.利 ...
- redis 主从复制+读写分离+哨兵
1.redis读写分离应用场景 当数据量变得庞大的时候,读写分离还是很有必要的.同时避免一个redis服务宕机,导致应用宕机的情况,我们启用sentinel(哨兵)服务,实现主从切换的功能.redis ...
- Redis的读写分离
1.概述 随着企业业务的不断扩大,请求的并发量不断增长,Redis可能终会出现无法负载的情况,此时我们就需要想办法去提升Redis的负载能力. 读写分离(主从复制)是一个比较简单的扩展方案,使用多台机 ...
- MYSQL数据库性能调优之七:其他(读写分离、分表等)
一.分表 水平划分 垂直划分 二.读写分离 三.选择合理的数据类型 特别是主键 四.文件.图片等大文件使用文件系统存储 五.数据库参数配置 注意:max_connections最大连接数一般设置在10 ...
- redis主从复制 从而 数据备份和读写分离
蜗牛Redis系列文章目录http://www.cnblogs.com/tdws/tag/NoSql/ 爬虫转载注明地址本文地址—博客园蜗牛 http://www.cnblogs.com/tdws/p ...
- Redis学习笔记~Redis主从服务器,读写分离
回到目录 Redis这个Nosql的存储系统一般会被部署到linux系统中,我们可以把它当成是一个数据服务器,对于并发理大时,我们会使用多台服务器充当Redis服务器,这时,各个Redis之间也是分布 ...
随机推荐
- python 判断元素是否在一个列表中
import random val= data=[,,,,] : find=False val=int(input('请输入查找键值(1-9),输入-1离开:')) for i in data: if ...
- Review of Semantic Segmentation with Deep Learning
In this post, I review the literature on semantic segmentation. Most research on semantic segmentati ...
- 简单find命令的实现
贴代码: /*实现一个简单的find命令:*//*程序思路:首先,用一个单链表将所需要的信息存储起来:其次根据所传入的参数信息,改变节点的状态(若有这个状态,证明该节点就是我们所需要的)最后将所需要的 ...
- c语言用指针定义一个类型进行输入输出
1 整型数组 // #include "stdafx.h" #include "stdlib.h" int _tmain(int argc, _TCHAR* a ...
- [Beta阶段]第四次Scrum Meeting
Scrum Meeting博客目录 [Beta阶段]第四次Scrum Meeting 基本信息 名称 时间 地点 时长 第四次Scrum Meeting 19/05/06 大运村寝室6楼 30min ...
- Spring Boot打war包和jar包的目录结构简单讲解
Spring Boot项目可以制作成jar包和war包,其目录结构是不一样的,具体的如下所示: 1.war包目录结构分析WAR(Web Archivefile)网络应用程序文件,是与平台无关的文件格式 ...
- Java编程思想之五初始化与清理
随着计算机革命的发展,"不安全"的编程方式已经逐渐称为编程代价高昂的主因之一. 初始化和清理正是涉及安全的两个问题. 5.1 用构造器确保初始化 通过提供构造器,类的设计者可确保每 ...
- KMS服务器激活
https://blog.csdn.net/weixin_42588262/article/details/81120403 http://kms.cangshui.net/ https://kms. ...
- EChart 标题 title 样式,x轴、y轴坐标显示,调整图表位置等
示例里工作一般情况是够用了,更复杂的可以查询教程: title 官方解说:http://echarts.baidu.com/option.html#title 坐标相关: X轴:http://echa ...
- python快速搭建http服务
在Windows 7/10或Ubuntu上可以通过python2.x或python3.x来快速搭建一个简单的HTTP服务器. 如果python为2.x,则可执行:$ python -m SimpleH ...