python爬虫之requests库
在python爬虫中,要想获取url的原网页,就要用到众所周知的强大好用的requests库,在2018年python文档年度总结中,requests库使用率排行第一,接下来就开始简单的使用requests库吧.
配置好python环境后,python配置大家应该都会,至于path路径下载安装界面右下角就有add to path 很简便,这里主要是window环境下的使用,至于Linux环境,我暂时还没有深入了解,用yum install或者 wget命令都是可行的.
在window环境下,推荐是用pip进行安装,因为便捷而且不用考虑文件的解压路径:
pip install requests
首先requests有文档说明,requests文档 多观察库文档,有利于我们了解该库创建者的意图,现在可以尝试使用requests库获取一个网页的源代码了:代码如下
import requests url='https://www.cnblogs.com/hxms/p/10412179.html' response=requests.get(url) print(respones.text)
requests code
但是为了更好获取源代码,还需要对该代码进行一定的优化,比如是否考虑statue_code==200,响应码是否正常,正常还可以请求该网页,否则返回错误原因,代码如下:
import requests
def get_page():
try:
url="https://www.cnblogs.com/hxms/p/10412179.html"
response=requests.get(url)
if response.status_code==200:
return response.text
except requests.ConnectionError:
return None
get_page()
requests Codes
运用了get_page的函数,对requests的方法进行优化,最后还可以添加main函数进行打印输出
def main():
data=get_page()
print(data)
if __name__ == "__main__":
main()
进行如下
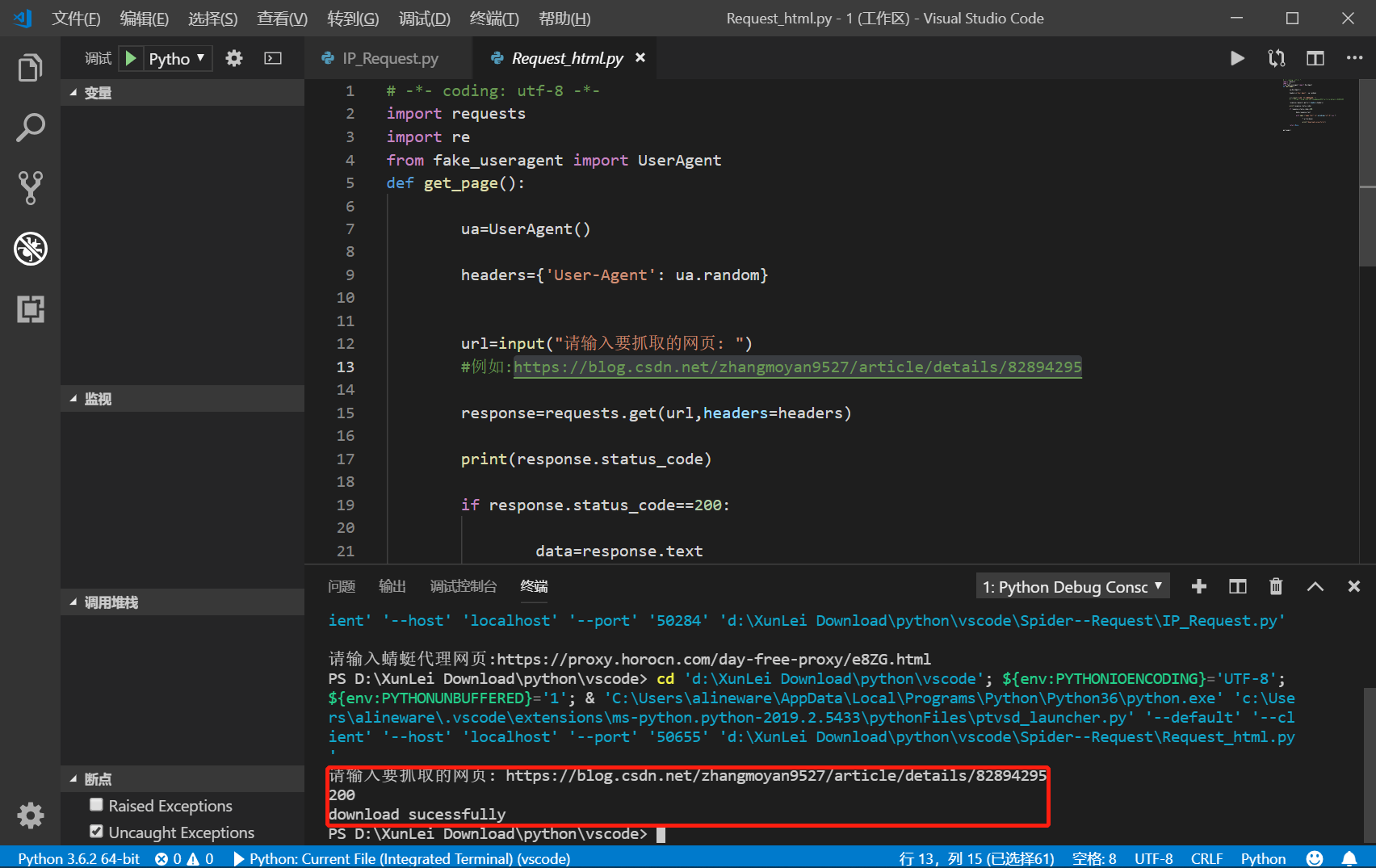

这样就可以简单的获取网页的源代码了,但是在现实过程中,网页是经过js渲染的,即可以理解为该HTML只是个空体,只是引用了某个js文本,这样就会造成requests请求的源代码出现错误,造成后期抓不到想要的数据,不过没有关系,F12提供了强大的抓包工具,无论是Ajax或者是直接js渲染的网页,我们都有相应的解决方法,例如利用selenium库进行自动化运行,抑或是xhr文件里的json字典格式化存储,都是可以解决这些问题的.
关于requests库还有许多参数没用上,比如proxies(代理,抓取数量过大时会导致该请求网址对我们的IP进行封禁,导致304请求失败),headers(头请求),现在许多网页会设置反爬虫设置,如果你不加请求头的话,服务器是不会返回任何信息给你的,但是requests库为你提供了伪装浏览器的方法,运用User-Agent;host等运用字典添加进去,更容易获取我们想要的信息.更多方法可以参考上面的requests文档.
python爬虫之requests库的更多相关文章
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
- Python爬虫:requests 库详解,cookie操作与实战
原文 第三方库 requests是基于urllib编写的.比urllib库强大,非常适合爬虫的编写. 安装: pip install requests 简单的爬百度首页的例子: response.te ...
- Python爬虫之requests库的使用
requests库 虽然Python的标准库中 urllib模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests宣传是 "HTTP for ...
- 【Python爬虫】Requests库的基本使用
Requests库的基本使用 阅读目录 基本的GET请求 带参数的GET请求 解析Json 获取二进制数据 添加headers 基本的POST请求 response属性 文件上传 获取cookie 会 ...
- python爬虫(1)requests库
在pycharm中安装requests库的一种方法 首先找到设置 搜索然后安装,蓝色代表已经安装 requests库中的get请求 与HTTP协议相对应,requests库也有七种请求方式. 获取ur ...
- python爬虫之requests库介绍(二)
一.requests基于cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们 ...
- Python爬虫之Requests库的基本使用
import requests response = requests.get('http://www.baidu.com/') print(type(response)) print(respons ...
- Python爬虫系列-Requests库详解
Requests基于urllib,比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 实例引入 import requests response = requests.get( ...
- python下载安装requests库
一.python下载安装requests库 1.到git下载源码zip源码https://github.com/requests/requests 2.解压到python目录下: 3.“win+R”进 ...
随机推荐
- PAT——1053. 住房空置率
在不打扰居民的前提下,统计住房空置率的一种方法是根据每户用电量的连续变化规律进行判断.判断方法如下: 在观察期内,若存在超过一半的日子用电量低于某给定的阈值e,则该住房为“可能空置”: 若观察期超过某 ...
- 【51nod 1685】 第K大区间2
题目描述: 定义一个长度为奇数的区间的值为其所包含的的元素的中位数.现给出n个数,求将所有长度为奇数的区间的值排序后,第K大的值为多少. 样例解释: [l,r]表示区间的值 [1]:3 [2]:1 [ ...
- 《Android应用测试与调试实战》读书笔记
一 本书概述 自动化测试篇:Android应用可以使用Java语言配合SDK,也可以使用HTML5技术,还可以用C/C++语言配合NDK技术编写,本书中涵盖了针对这三种技术编写的应用所采用的测试技术. ...
- Android的JNI调用(一)
Android提供NDK开发包来提供Android平台的C++开发,用来扩展Android SDK的功能.主要包括Android NDK构建系统和JNI实现与原生代码通信两部分. 一.Android ...
- SSIS中出现数据流数据源假死状态的解决办法
相信开发过Sql Server SSIS的人都遇到过在数据流中数据源假死的问题,特别是Excel Source特别容易假死,当job执行到数据流中的Excel Source时,既不报错也不执行,也没有 ...
- G1 GC日志:Application time: 0.8766273 seconds
启动日志一直循环: 1.159: Application time: 0.8766273 seconds 1.160: Total time for which application threads ...
- CentOS 7.0 防火墙操作
CentOS 7.0默认使用的是firewall作为防火墙,之前版本是使用iptables.所以在CentOS 7执行下面命令是无法查看防火墙状态的. [root@localhost ~]# serv ...
- Ubuntu16.04测网速
wget https://www.python.org/ftp/python/3.7.0/Python-3.7.0b4.tar.xz tar -xvJf Python-3.7.0b4.tar.xz c ...
- 事务与MVCC
前言 关于事务,是一个很重要的知识点,大家在面试中也会被经常问到这个问题: 数据库事务有不同的隔离级别,不同的隔离级别对锁的使用是不同的,**锁的应用最终导致不同事务的隔离级别 **:在上一篇文章中我 ...
- redis应用场景:实现简单计数器-防止刷单
redis应用场景:实现计数器-防止刷单 最近由于双11要来临,公司需要在接口请求上,做一下并发限制的处理,或者做一个防止刷单的安全拦截:比如:一个接口请求,限制每秒请求总数为200次,超过200次就 ...