Mahout实现基于用户的协同过滤算法
Mahout中对协同过滤算法进行了封装,看一个简单的基于用户的协同过滤算法。
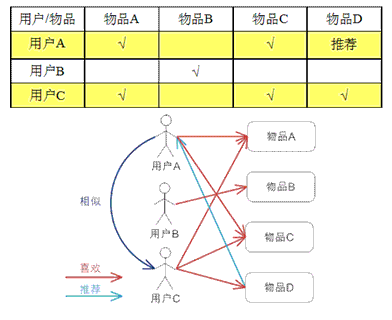
基于用户:通过用户对物品的偏好程度来计算出用户的在喜好上的近邻,从而根据近邻的喜好推测出用户的喜好并推荐。

{kind=link}
程序中用到的数据都存在MySQL数据库中,计算结果也存在MySQL中的对应用户表中。
package com.mahout.helloworlddemo; import java.sql.Connection;
import java.sql.DatabaseMetaData;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.HashSet;
import java.util.List; import org.apache.mahout.cf.taste.impl.model.jdbc.MySQLJDBCDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.model.JDBCDataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity; import com.mahout.util.DBUtil;
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource; /**
*
*@author wxisme
*@time 2015-9-13 下午6:25:26
*/
public class RecommenderIntroFromMySQL { public static void main(String[] args) throws Exception { //连接MySQL
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setServerName("localhost");
dataSource.setUser("root");
dataSource.setPassword("1234");
dataSource.setDatabaseName("mahoutdemo"); //获取数据模型
JDBCDataModel dataModel = new MySQLJDBCDataModel(dataSource, "taste_preferences", "user_id", "item_id", "preference","time"); DataModel model = dataModel; //计算相似度
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
//计算阈值
UserNeighborhood neighborhood = new NearestNUserNeighborhood(2,similarity,model); //推荐
Recommender recommender = new GenericUserBasedRecommender(model,neighborhood,similarity); Connection con = DBUtil.getConnection();
Statement stmt = con.createStatement(); //获取每个用户的推荐数据并存入数据库 for(int i=0; i<5; i++) {
List<RecommendedItem> recommendations = recommender.recommend(i, 3); String tableName = "user_" + i; for (RecommendedItem recommendation : recommendations) { //如果是第一次推荐就创建该用户的数据表
if(!doesTableExist(tableName)) { String createSQL = "create table " + tableName
+ " (item_id bigint primary key,value float);";
stmt.execute(createSQL);
} String insertSQL = "insert into " + tableName + " values ("
+ recommendation.getItemID() + "," + recommendation.getValue() + " );"; //插入用户的推荐数据
stmt.execute(insertSQL); System.out.println(recommendation);
}
} } /**
* 是否存在这个数据表
* @param tablename
* @return
* @throws SQLException
*/
public static Boolean doesTableExist(String tablename) throws SQLException {
HashSet<String> set = new HashSet<String>();
Connection con = DBUtil.getConnection();
DatabaseMetaData meta = con.getMetaData();
ResultSet res = meta.getTables(null, null, null,
new String[]{"TABLE"});
while (res.next()) {
set.add(res.getString("TABLE_NAME"));
}
DBUtil.close(res, con);
return set.contains(tablename);
} }
测试数据:
1,101,5
1,102,3
1,103,2.5
2,101,2
2,102,2.5
2,103,5
2,104,2
3,101,2.5
3,104,4
3,105,4.5
3,107,5
4,101,5
4,103,3
4,104,4.5
4,106,4
5,101,4
5,102,3
5,103,2
5,104,4
5,105,3.5
5,106,4
运行结果:

更多Mahout和协同过滤算法的介绍与分析:
http://www.cnblogs.com/dlts26/archive/2011/08/23/2150225.html
http://www.tuicool.com/articles/FzmQziz
http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
Mahout实现基于用户的协同过滤算法的更多相关文章
- 案例:Spark基于用户的协同过滤算法
https://mp.weixin.qq.com/s?__biz=MzA3MDY0NTMxOQ==&mid=2247484291&idx=1&sn=4599b4e31c2190 ...
- 基于用户的协同过滤的电影推荐算法(tensorflow)
数据集: https://grouplens.org/datasets/movielens/ ml-latest-small 协同过滤算法理论基础 https://blog.csdn.net/u012 ...
- 【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
好早的时候就打算写这篇文章,可是还是參加阿里大数据竞赛的第一季三月份的时候实验就完毕了.硬生生是拖到了十一假期.自己也是醉了... 找工作不是非常顺利,希望写点东西回想一下知识.然后再攒点人品吧,仅仅 ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法.ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通 ...
- 推荐召回--基于用户的协同过滤UserCF
目录 1. 前言 2. 原理 3. 数据及相似度计算 4. 根据相似度计算结果 5. 相关问题 5.1 如何提炼用户日志数据? 5.2 用户相似度计算很耗时,有什么好的方法? 5.3 有哪些改进措施? ...
- 基于用户的协同过滤电影推荐user-CF python
协同过滤包括基于物品的协同过滤和基于用户的协同过滤,本文基于电影评分数据做基于用户的推荐 主要做三个部分:1.读取数据:2.构建用户与用户的相似度矩阵:3.进行推荐: 查看数据u.data 主要用到前 ...
- (数据挖掘-入门-3)基于用户的协同过滤之k近邻
主要内容: 1.k近邻 2.python实现 1.什么是k近邻(KNN) 在入门-1中,简单地实现了基于用户协同过滤的最近邻算法,所谓最近邻,就是找到距离最近或最相似的用户,将他的物品推荐出来. 而这 ...
- 基于用户的协同过滤(UserCF)
随机推荐
- Java上的jQuery?解析HTML利器—Jsoup
也许大家有过在java运行平台上解析html的经历,通常的方式是将HTML以XML的形式进行结点解析,调用java本身的xml解析类库.这样的方式很容易理解并且很方便,但习惯用jQuery的各位是否在 ...
- win 10 桌面路径还原到C盘拒绝访问
解决: 问是否更改那里 点 否 即可 题外话: win10桌面注册表路径 HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Exp ...
- 将hive的hql执行结果保存到变量中
这里分别针对shell脚本和python脚本举例: shell脚本如下: 注意:在hive语句左右两边使用的是ESC键下面的点号,不是单引号. #!/usr/bin/env bash test1=`h ...
- ubuntu 12.10 默认安装php5-fpm无监听9000端口,nginx无法链接php5-fpm修正
升级php5的时候,发现nginx无法链接到php5,怀疑是php5端口的问题. netstat -an未发现监听9000端口. 查看/var/log/php5-fpm.log一切正常. 随后查看/e ...
- Nginx下轻松开启Drupal简洁链接
大家都知道Drupal在apache环境下使用简洁链接是件很轻松的事,因为官方已经把写好的.htaccess文件附在源代码里,一般在配置里直接就可以打开了.但在Nginx下却没有那么简单,但不用担心, ...
- js本地图片预览,兼容ie[6-9]、火狐、Chrome17+、Opera11+、Maxthon3
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- mongo 内存限制wiredTigerCacheSizeGB = 10
[root@iZ2zed126f44v90yv59ht3Z rabbitmq]# cat /usr/local/mongodb/mongodb.confport = 27017dbpath = /us ...
- 解决Spring框架的Dao层改用@Repository注解,无法使用JdbcDaoSupport的问题
解决Spring框架的Dao层改用@Repository注解,无法使用JdbcDaoSupport的问题 Alternatively, create an own implementation of ...
- Understand:高效代码静态分析神器详解(一)
Understand:高效代码静态分析神器详解(一) Understand 之前用Windows系统,一直用source insight查看代码非常方便,但是年前换到mac下面,虽说很多东西都方便 ...
- Zookeeper 工作流
一旦ZooKeeper集合启动,它将等待客户端连接.客户端将连接到ZooKeeper集合中的一个节点.它可以是leader或follower节点.一旦客户端被连接,节点将向特定客户端分配会话ID并向该 ...