storm架构及原理
storm 架构与原理
1 storm简介
1.1 storm是什么
如果只用一句话来描述 storm 是什么的话:分布式 && 实时 计算系统。按照作者 Nathan Marz 的说法,storm对于实时计算的意义类似于hadoop对于批处理的意义。
Hadoop(大数据分析领域无可争辩的王者)专注于批处理。这种模型对许多情形(比如为网页建立索引)已经足够,但还存在其他一些使用模型,它们需要来自高度动态的来源的实时信息。为了解决这个问题,就得借助 Nathan Marz 推出的 storm(现在已经被Apache孵化)storm 不处理静态数据,但它处理连续的流数据。
1.2 storm 与传统的大数据
storm 与其他大数据解决方案的不同之处在于它的处理方式。Hadoop 在本质上是一个批处理系统。数据被引入 Hadoop 文件系统 (HDFS) 并分发到各个节点进行处理。当处理完成时,结果数据返回到 HDFS 供始发者使用。storm 支持创建拓扑结构来转换没有终点的数据流。不同于 Hadoop 作业,这些转换从不停止,它们会持续处理到达的数据。
Hadoop 的核心是使用 Java™ 语言编写的,但支持使用各种语言编写的数据分析应用程序。而 Twitter Storm 是使用 Clojure语言实现的。
Clojure 是一种基于虚拟机 (VM) 的语言,在 Java 虚拟机上运行。但是,尽管 storm 是使用 Clojure 语言开发的,您仍然可以在 storm 中使用几乎任何语言编写应用程序。所需的只是一个连接到 storm 的架构的适配器。已存在针对 Scala,JRuby,Perl 和 PHP 的适配器,但是还有支持流式传输到 Storm 拓扑结构中的结构化查询语言适配器。
2 Hadoop 架构的瓶颈
- Hadoop是优秀的大数据离线处理技术架构,主要采用的思想是“分而治之”,对大规模数据的计算进行分解,然后交由众多的计算节点分别完成,再统一汇总计算结果。Hadoop架构通常的使用方式为批量收集输入数据,批量计算,然后批量吐出计算结果。然而Hadoop结构在处理实时性要求较高的业务时,却显得力不从心。本章内容对Hadoop架构这种瓶颈的产生原因进行了探究。 实时性不足(基于离线)
2.1 Hadoop架构简介
Hadoop架构的核心组成部分是HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)和MapReduce分布式计算框架。HDFS采用Master/Slave体系结构,在集群中由一个主节点充当NameNode,负责文件系统元数据的管理,其它多个子节点充当Datanode,负责存储实际的数据块。
MapReduce分布式计算模型由JobTracker和TaskTracker两类服务进程实现,JobTracker负责任务的调度和管理,TaskTracker负责实际任务的执行。
2.2 Hadoop架构的瓶颈
在手机阅读BI大屏时延项目中,业务需求为处理业务平台产生的海量用户数据,展现业务中PV(Page View,页面浏览量)、UV(Unique Visitor,独立访客)。营收和付费用户数等关键运营指标,供领导层实时了解运营状况,做出经营决策,在一期项目的需求描述中,允许的计算时延是15分钟。
根据需求,在一期项目的实施中,搭建了Hadoop平台与Hive数据仓库,通过编写Hive存储过程,来完成数据的处理,相当于是一个离线的批处理过程,不同的运营指标拥有不同的算法公式,各公式的复杂程度不同导致各运营指标算法复杂度不同,因此所需要的计算时延也各不相同,如PV指标的计算公式相对简单,可以在5分钟内完成计算,而页面访问成功率指标的计算公式相对复杂,需要10分钟以上才能完成计算。项目到达二期阶段时,对实时性的要求有了进一步提高,允许的计算时延减少到5分钟,在这种应用场景下,Hadoop架构已经不能满足需要,无法在指定的时延内完成所有运营指标的计算。
- 在以上的应用场景中,Hadoop的瓶颈主要体现在以下两点:
- 1) MapReduce计算框架初始化较为耗时,并不适合小规模的批处理计算。因为MapReduce框架并非轻量级框架,在运行一个作业时,需要进行很多 初始化 的工作,主要包括检查作业的输入输出路径,将作业的输入数据分块,建立作业统计信息以及将作业代码的Jar文件和配置文件拷贝到HDFS上,当输入数据的规模很大时,框架初始化所耗费的时间远远小于计算所耗费的时间,所以初始化的时间可以忽略不计;而当输入数据的规模较小时,初始化所耗费的时间甚至超过了计算所耗费的时间,导致计算效率低下,产生了性能上的瓶颈。
- 2) Reduce任务的计算速度较慢。有的运营指标计算公式较为复杂,为之编写的Hive存储过程经Hive解释器解析后产生了Reduce任务,导致无法在指定的时延内完成计算。这是由于Reduce任务的计算过程分为三个阶段,分别是copy阶段,sort阶段和reduce阶段。其中copy阶段要求每个计算节点从其它所有计算节点上抽取其所需的计算结果,copy操作需要占用大量的网络带宽,十分耗时,从而造成Reduce任务整体计算速度较慢。
3 storm 架构的优点
- storm的流式处理计算模式保证了任务能够只进行一次初始化,就能够持续计算,同时使用了ZeroMQ(Netty)作为底层消息队列,有效地提高了整体架构的数据处理效率,避免了Hadoop的瓶颈。
- Storm的适用场景:
- 1.流数据处理,Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去。
- 2.分布式rpc,由于storm的处理组件是分布式的,而且处理延迟极低,所以可以作为一个通用的分布式rpc框架来使用。
- 3.持续计算,任务一次初始化,一直运行,除非你手动kill它。
3.1 storm架构的设计
- 与Hadoop主从架构一样,Storm也采用Master/Slave体系结构,分布式计算由Nimbus和Supervisor两类服务进程实现,Nimbus进程运行在集群的主节点,负责任务的指派和分发,Supervisor运行在集群的从节点,负责执行任务的具体部分。
- 如图所示:
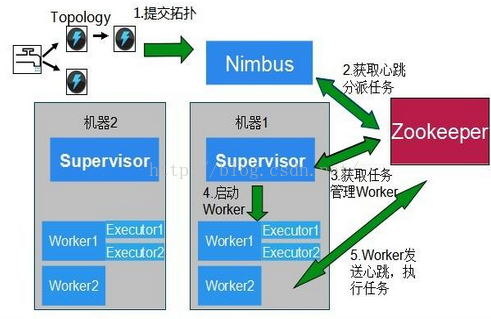
- Nimbus:负责资源分配和任务调度。
- Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。
- Worker:运行具体处理组件逻辑的进程。
- Task:worker中每一个spout/bolt的线程称为一个task。同一个spout/bolt的task可能会共享一个物理线程,该线程称为executor。
- storm架构中使用Spout/Bolt编程模型来对消息进行流式处理。消息流是storm中对数据的基本抽象,一个消息流是对一条输入数据的封装,源源不断输入的消息流以分布式的方式被处理,Spout组件是消息生产者,是storm架构中的数据输入源头,它可以从多种异构数据源读取数据,并发射消息流,Bolt组件负责接收Spout组件发射的信息流,并完成具体的处理逻辑。在复杂的业务逻辑中可以串联多个Bolt组件,在每个Bolt组件中编写各自不同的功能,从而实现整体的处理逻辑。
3.2 storm架构与Hadoop架构的对比
storm架构与Hadoop架构的总体结构相似。
结构 Hadoop Storm 主节点 JobTracker Nimbus 从节点 TaskTracker Supervisor 应用程序 Job Topology 工作进程名称 Child Worker 计算模型 Map / Reduce Spout / Bolt 在Hadoop架构中,主从节点分别运行JobTracker和TaskTracker进程,在storm架构中,主从节点分别运行Nimbus和Supervisor进程。在Hadoop架构中,应用程序的名称是Job,Hadoop将一个Job解析为若干Map和Reduce任务,每个Map或Reduce任务都由一个Child进程来运行,该Child进程是由TaskTracker在子节点上产生的子进程。
在Storm架构中,应用程序的名称是Topology,Storm将一个Topology划分为若干个部分,每部分由一个Worker进程来运行,该Worker进程是Supervisor在子节点上产生的子进程,在每个Worker进程中存在着若干Spout和Bolt线程,分别负责Spout和Bolt组件的数据处理过程。
从应用程序的比较中可以看明显地看到Hadoop和Storm架构的主要不同之处。在Hadoop架构中,应用程序Job代表着这样的作业:输入是确定的,作业可以在有限时间内完成,当作业完成时Job的生命周期走到终点,输出确定的计算结果;而在Storm架构中,Topology代表的并不是确定的作业,而是持续的计算过程,在确定的业务逻辑处理框架下,输入数据源源不断地进入系统,经过流式处理后以较低的延迟产生输出。如果不主动结束这个Topology或者关闭Storm集群,那么数据处理的过程就会持续地进行下去。
- 通过以上的分析,我们可以看到,storm架构是如何解决Hadoop架构瓶颈的:
- Storm的Topology只需初始化一次。在将Topology提交到Storm集群的时候,集群会针对该Topology做一次初始化的工作,此后,在Topology运行过程中,对于输入数据而言,是没有计算框架初始化耗时的,有效避免了计算框架初始化的时间损耗。
- Storm使用Netty作为底层的消息队列来传递消息,保证消息能够得到快速的处理,同时Storm采用内存计算模式,无需借助文件存储,直接通过网络直传中间计算结果,避免了组件之间传输数据的大量时间损耗。
3.3 storm的优点
- Storm 实现的一些特征决定了它的性能和可靠性的,Storm 使用 Netty 传送消息,这就消除了中间的排队过程,使得消息能够直接在任务自身之间流动,在消息的背后,是一种用于序列化和反序列化 Storm 的原语类型的自动化且高效的机制。
Storm 的一个最有趣的地方是它注重容错和管理,Storm 实现了有保障的消息处理,所以每个元组(Turple)都会通过该拓扑(Topology)结构进行全面处理;如果发现一个元组还未处理,它会自动从Spout处重发,Storm 还实现了任务级的故障检测,在一个任务发生故障时,消息会自动重新分配以快速重新开始处理。Storm 包含比 Hadoop 更智能的处理管理,流程会由zookeeper来进行管理,以确保资源得到充分使用。
- 总结一下,有以下优点:
- 简单编程,在大数据处理方面相信大家对hadoop已经耳熟能详,基于Google Map/Reduce来实现的Hadoop为开发者提供了map、reduce原语,使并行批处理程序变得非常地简单和优美。同样,Storm也为大数据的实时计算提供了一些简单优美的原语,这大大降低了开发并行实时处理的任务的复杂性,帮助你快速、高效的开发应用。
- 多语言支持,除了用java实现spout和bolt,你还可以使用任何你熟悉的编程语言来完成这项工作,这一切得益于Storm所谓的多语言协议。多语言协议是Storm内部的一种特殊协议,允许spout或者bolt使用标准输入和标准输出来进行消息传递,传递的消息为单行文本或者是json编码的多行。
- 支持水平扩展,在Storm集群中真正运行topology的主要有三个实体:工作进程、线程和任务。Storm集群中的每台机器上都可以运行多个工作进程,每个工作进程又可创建多个线程,每个线程可以执行多个任务,任务是真正进行数据处理的实体,我们开发的spout、bolt就是作为一个或者多个任务的方式执行的。因此,计算任务在多个线程,进程和服务器之间并行进行,支持灵活的水平扩展。
- 容错性强,如果在消息处理过程中出了一些异常,Storm会重新安排这个出问题的处理单元,Storm保证一个处理单元永远运行(除非你显式杀掉这个处理单元)。
- 可靠性的消息保证 Storm可以保证spout发出的每条消息都能被“完全处理”。
- 快速的消息处理,用Netty作为底层消息队列, 保证消息能快速被处理。
- 本地模式,支持快速编程测试。
4 其他大数据解决方案
- 自 Google 在 2004 年推出 MapReduce 范式以来,已诞生了多个使用原始 MapReduce 范式(或拥有该范式的质量)的解决方案。Google 对 MapReduce 的最初应用是建立万维网的索引。尽管此应用程序仍然很流行,但这个简单模型解决的问题也正在增多。
- 下标中提供了一个可用开源大数据解决方案的列表,包括传统的批处理和流式处理应用程序。在将 Storm 引入开源之前将近一年的时间里,Yahoo! 的 S4 分布式流计算平台已向 Apache 开源。S4 于 2010 年 10 月发布,它提供了一个高性能计算 (HPC) 平台,向应用程序开发人员隐藏了并行处理的复杂性。S4 实现了一个可扩展的、分散化的集群架构,并纳入了部分容错功能。
| 解决方案 | 开发商 | 类型 | 描述 |
|---|---|---|---|
| storm | 流式处理 | Twitter 的新流式大数据分析解决方案 | |
| S4 | Yahoo! | 流式处理 | 来自 Yahoo! 的分布式流计算平台 |
| Hadoop | Apache | 批处理 | MapReduce 范式的第一个开源实现 |
| Spark | UC Berkeley AMPLab | 批处理 | 支持内存中数据集和恢复能力的最新分析平台 |
| Disco | Nokia | 批处理 | Nokia 的分布式 MapReduce 框架 |
| HPCC | LexisNexis | 批处理 | HPC 大数据集群 |
5 storm基本概念
下面介绍Storm的基本概念和数据流模型。Storm是一个开源的实时计算系统,它提供了一系列的基本元素用于进行计算:Topology、Stream、Spout、Bolt等等。
Storm集群和Hadoop集群表面上看很类似。但是Hadoop上运行的是MapReduce jobs,而在Storm上运行的是拓扑(topology),这两者之间是非常不一样的,一个关键的区别是: 一个MapReduce job最终会结束, 而一个topology永远会运行(除非你手动kill掉)。
在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。控制节点上面运行一个叫Nimbus后台程序,它的作用类似Hadoop里面的JobTracker,Nimbus负责在集群里面分发代码,分配计算任务给机器,并且监控状态。每一个工作节点上面运行一个叫做Supervisor的进程。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程worker。每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在很多机器上的很多工作进程worker组成。(一个supervisor里面有多个workder,一个worker是一个JVM。可以配置worker的数量,对应的是conf/storm.yaml中的supervisor.slot的数量)
- Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成。另外,Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有的状态要么在zookeeper里面, 要么在本地磁盘上。这也就意味着你可以用kill -9来杀死Nimbus和Supervisor进程,然后再重启它们,就好像什么都没有发生过,这个设计使得Storm异常的稳定。
5.1 Topology
- 在Storm中,一个实时应用的计算任务被打包作为Topology发布,这同Hadoop的MapReduce任务相似。但是有一点不同的是:在Hadoop中,MapReduce任务最终会执行完成后结束;而在Storm中,Topology任务一旦提交后永远不会结束,除非你显示去停止任务。计算任务Topology是由不同的Spouts和Bolts,通过数据流(Stream)连接起来的图。下面是一个Topology的结构示意图:
- 其中包含有:
- Spout:Storm中的消息源,用于为Topology生产消息(数据),一般是从外部数据源(如Message Queue、RDBMS、NoSQL、Realtime Log )不间断地读取数据并发送给Topology消息(tuple元组)。
- Bolt:Storm中的消息处理者,用于为Topology进行消息的处理,Bolt可以执行过滤,聚合, 查询数据库等操作,而且可以一级一级的进行处理。
下图是Storm的数据交互图,可以看出两个模块Nimbus和Supervisor之间没有直接交互。状态都是保存在Zookeeper上,Worker之间通过Netty传送数据。Storm与Zookeeper之间的交互过程,暂时不细说了。重要的一点:storm所有的元数据信息保存在Zookeeper中!
5.2 数据模型Turple
storm使用tuple来作为它的数据模型。每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型,在我的理解里面一个tuple可以看作一个java对象。总体来看,storm支持所有的基本类型:字符串以及字节数组作为tuple的值类型。你也可以使用你自己定义的类型来作为值类型,只要你实现对应的序列化器(serializer)。
一个Tuple代表数据流中的一个基本的处理单元,它可以包含多个Field,每个Field表示一个属性。比如举例一个,三个字段(taskID:int; StreamID:String; ValueList: List):
Tuple是一个Key-Value的Map,由于各个组件间传递的tuple的字段名称已经事先定义好了,所以Tuple只需要按序填入各个Value,所以就是一个Value List。一个没有边界的,源源不断的,连续的Tuple序列就组成了Stream。
- topology里面的每个节点必须定义它要发射的tuple的每个字段。
5.3 worker(进程)
- 一个topology可能会在一个或者多个worker(工作进程)里面执行,每个worker是一个物理JVM并且执行整个topology的一部分。比如,对于并行度是300的topology来说,如果我们使用50个工作进程worker来执行,那么每个工作进程会处理其中的6个tasks。Storm会尽量均匀的工作分配给所有的worker,setBolt 的最后一个参数是你想为bolts的并行量。
5.4 Spouts
消息源spout是Storm里面一个topology里面的消息生产者。一般来说消息源会从一个外部源读取数据并且向topology里面发出消息:tuple。Spout可以是可靠的也可以是不可靠的,如果这个tuple没有被storm成功处理,可靠的消息源spouts可以重新发射一个tuple,但是不可靠的消息源spouts一旦发出一个tuple就不能重发了。
消息源可以发射多条消息流stream。使用OutputFieldsDeclarer。declareStream来定义多个stream,然后使用SpoutOutputCollector来发射指定的stream。代码上是这样的:collector.emit(new Values(str));
Spout类里面最重要的方法是nextTuple。要么发射一个新的tuple到topology里面或者简单的返回如果已经没有新的tuple。要注意的是nextTuple方法不能阻塞,因为storm在同一个线程上面调用所有消息源spout的方法。另外两个比较重要的spout方法是ack和fail。storm在检测到一个tuple被整个topology成功处理的时候调用ack,否则调用fail。storm只对可靠的spout调用ack和fail。
5.5 Bolts
所有的消息处理逻辑被封装在bolts里面。Bolts可以做很多事情:过滤,聚合,查询数据库等等。
Bolts可以简单的做消息流的传递(来一个元组,调用一次execute)。复杂的消息流处理往往需要很多步骤,从而也就需要经过很多bolts。比如算出一堆图片里面被转发最多的图片就至少需要两步:第一步算出每个图片的转发数量,第二步找出转发最多的前10个图片。(如果要把这个过程做得更具有扩展性那么可能需要更多的步骤)。
Bolts可以发射多条消息流, 使用OutputFieldsDeclarer.declareStream定义stream,使用OutputCollector.emit来选择要发射的stream。
Bolts的主要方法是execute,它以一个tuple作为输入,bolts使用OutputCollector来发射tuple(spout使用SpoutOutputCollector来发射指定的stream),bolts必须要为它处理的每一个tuple调用OutputCollector的ack方法,以通知Storm这个tuple被处理完成了,从而通知这个tuple的发射者spouts。一般的流程是: bolts处理一个输入tuple, 发射0个或者多个tuple, 然后调用ack通知storm自己已经处理过这个tuple了。storm提供了一个IBasicBolt会自动调用ack。
5.6 Reliability
- Storm保证每个tuple会被topology完整的执行。Storm会追踪由每个spout tuple所产生的tuple树(一个bolt处理一个tuple之后可能会发射别的tuple从而形成树状结构),并且跟踪这棵tuple树什么时候成功处理完。每个topology都有一个消息超时的设置,如果storm在这个超时的时间内检测不到某个tuple树到底有没有执行成功,那么topology会把这个tuple标记为执行失败,并且过一会儿重新发射这个tuple(超时的时间在storm0.9.0.1版本中是可以设置的,默认是30s)。
5.7 Tasks
- 每一个spout和bolt会被当作很多task在整个集群里执行。每一个executor对应到一个线程,在这个线程上运行多个task,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。你可以调用TopologyBuilder类的setSpout和setBolt来设置并行度。SetSpout里面的并行度参数含义:parallelism_hint the number of tasks that should be assigned to execute this spout. Each task will run on a thread in a process somwehere around the cluster。(执行这个spout安排了N个tasks。每个task是一个线程,他们都在同一个进程中。)setBolt的参数含义也是一样的。
6 Storm数据流模型
- 数据流(Stream)是Storm中对数据进行的抽象,它是时间上无界的tuple元组序列。在Topology中,Spout是Stream的源头。负责为Topology从特定数据源发射Stream;Bolt可以接收任意多个Stream作为输入,然后进行数据的加工处理过程,如果需要,Bolt还可以发射出新的Stream给下级Bolt进行处理。下面是一个Topology内部Spout和Bolt之间的数据流关系:
- Topology中每一个计算组件(Spout和Bolt)都有一个并行执行度,在创建Topology时可以进行指定,Storm会在集群内分配对应并行度个数的线程来同时执行这一组件。那么,有一个问题:既然对于一个Spout或Bolt,都会有多个task线程来运行,那么如何在两个组件(Spout和Bolt)之间发送tuple元组呢?Storm提供了若干种数据流分发(Stream Grouping)策略用来解决这一问题。在Topology定义时,需要为每个Bolt指定接收什么样的Stream作为其输入(注:Spout并不需要接收Stream,只会发射Stream)。目前Storm中提供了以下7种Stream Grouping策略:Shuffle Grouping、Fields Grouping、All Grouping、Global Grouping、Non Grouping、Direct Grouping、Local or shuffle grouping。
6.1 Stream groupings
- Storm里面有7种类型的stream grouping
- Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
- Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task。而不同的userid则会被分配到不同的bolts里的task。
- All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
- Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task,再具体一点就是分配给id值最低的那个task。
- Non Grouping:不分组,这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果。有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
- Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程worker中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
6.2 storm 记录级容错
相比于s4, puma等其他实时计算系统,storm最大的亮点在于其记录级容错和能够保证消息精确处理的事务功能,下面就重点来看一下这两个亮点的实现原理。
Storm记录级容错的基本原理。首先来看一下什么叫做记录级容错?storm允许用户在spout中发射一个新的源tuple时为其指定一个message id,这个message id可以是任意的object对象。多个源tuple可以共用一个message id,表示这多个源 tuple对用户来说是同一个消息单元。storm中记录级容错的意思是说,storm会告知用户每一个消息单元是否在指定时间内被完全处理了。那什么叫做完全处理呢,就是该message id绑定的源tuple及由该源tuple后续生成的tuple经过了topology中每一个应该到达的bolt的处理。举个例子。如下图,在spout由message 1绑定的tuple1和tuple2经过了bolt1和bolt2的处理生成两个新的tuple,并最终都流向了bolt3。当这个过程完成处理完时,称message 1被完全处理了。
- 在storm的topology中有一个系统级组件,叫做acker。这个acker的任务就是追踪从spout中流出来的每一个message id绑定的若干tuple的处理路径,如果在用户设置的最大超时时间内这些tuple没有被完全处理,那么acker就会告知spout该消息处理失败了,相反则会告知spout该消息处理成功了。在刚才的描述中,我们提到了”记录tuple的处理路径”,如果曾经尝试过这么做的同学可以仔细地思考一下这件事的复杂程度。但是storm中却是使用了一种非常巧妙的方法做到了。在说明这个方法之前,我们来复习一个数学定理。
A xor A = 0.
A xor B…xor B xor A = 0,其中每一个操作数出现且仅出现两次。 - storm中使用的巧妙方法就是基于这个定理。具体过程是这样的:在spout中系统会为用户指定的message id生成一个对应的64位整数,作为一个root id。root id会传递给acker及后续的bolt作为该消息单元的唯一标识。同时无论是spout还是bolt每次新生成一个tuple的时候,都会赋予该tuple一个64位的整数的id。Spout发射完某个message id对应的源tuple之后,会告知acker自己发射的root id及生成的那些源tuple的id。而bolt呢,每次接受到一个输入tuple处理完之后,也会告知acker自己处理的输入tuple的id及新生成的那些tuple的id。Acker只需要对这些id做一个简单的异或运算,就能判断出该root id对应的消息单元是否处理完成了。下面通过一个图示来说明这个过程。
- 第1步:初始化 spout中绑定message 1生成了两个源tuple,id分别是0010和1011。
- 第2步:计算一个turple达到第1个bolt。bolt1处理tuple 0010时生成了一个新的tuple,id为0110。
- 第3步:计算一个turple达到第2个bolt,bolt2处理tuple 1011时生成了一个新的tuple,id为0111。
- 第4步:消息到达最后一个bolt。
- 可能有些细心的同学会发现,容错过程存在一个可能出错的地方,那就是,如果生成的tuple id并不是完全各异的,acker可能会在消息单元完全处理完成之前就错误的计算为0。这个错误在理论上的确是存在的,但是在实际中其概率是极低极低的,完全可以忽略。
6.3 Storm的事务拓扑
- 事务拓扑(transactional topology)是storm0.7引入的特性,在0.8版本以后的版本中已经被封装为Trident,提供了更加便利和直观的接口。因为篇幅所限,在此对事务拓扑做一个简单的介绍。
- 事务拓扑的目的是为了满足对消息处理有着极其严格要求的场景,例如实时计算某个用户的成交笔数,要求结果完全精确,不能多也不能少。Storm的事务拓扑是完全基于它底层的spout/bolt/acker原语实现的。通过一层巧妙的封装得出一个优雅的实现。
- 事务拓扑简单来说就是将消息分为一个个的批(batch),同一批内的消息以及批与批之间的消息可以并行处理,另一方面,用户可以设置某些bolt为committer,storm可以保证committer的finishBatch()操作是按严格不降序的顺序执行的。用户可以利用这个特性通过简单的编程技巧实现消息处理的精确。
7 并法度的理解
7.1 Example of a running topology
- The following illustration shows how a simple topology would look like in operation. The topology consists of three components: one spout called BlueSpout and two bolts called GreenBolt and YellowBolt. The components are linked such that BlueSpout sends its output to GreenBolt, which in turns sends its own output to YellowBolt.
- 总结:
- 一个Topology可以包含多个worker ,一个worker只能对应于一个topology。worker process是一个topology的子集。
- 一个worker可以包含多个executor,一个executor只能对应于一个component(spout或者bolt)。
- Task就是具体的处理逻辑,一个executor线程可以执行一个或多个tasks。线程就是资源,task就是要运行的任务。
7.2 并发度的配置有效的顺序
- Storm currently has the following order of precedence for configuration settings:
defaults.yaml < storm.yaml < topology-specific configuration < internal component-specific configuration < external component-specific configuration。
storm架构及原理的更多相关文章
- Storm概念、原理详解及其应用(一)BaseStorm
本文借鉴官文,添加了一些解释和看法,其中有些理解,写的比较粗糙,有问题的地方希望大家指出.写这篇文章,是想把一些官文和资料中基础.重点拿出来,能总结出便于大家理解的话语.与大多数“wordcount” ...
- 资源管理与调度系统-YARN的基本架构与原理
资源管理与调度系统-YARN的基本架构与原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 为了能够对集群中的资源进行统一管理和调度,Hadoop2.0引入了数据操作系统YARN. ...
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- SQL Server AlwaysOn架构及原理
SQL Server AlwaysOn架构及原理 SQL Server2012所支持的AlwaysOn技术集中了故障转移群集.数据库镜像和日志传送三者的优点,但又不相同.故障转移群集的单位是SQL实例 ...
- 爱莲(iLinkIT)的架构与原理
随着移动互联网时代的到来,手机正在逐步替代其他的设备,手机是电话.手机是即时通讯,手机是相机,手机是导航仪,手机是钱包,手机是音乐播放器……. 除此之外,手机还是一个大大的U盘,曾几何时,我们用一根长 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- [转帖]万字详解Oracle架构、原理、进程,学会世间再无复杂架构
万字详解Oracle架构.原理.进程,学会世间再无复杂架构 http://www.itpub.net/2019/04/24/1694/ 里面的图特别好 数据和云 2019-04-24 09:11:59 ...
- HDFS架构及原理
原文链接:HDFS架构及原理 引言 进入大数据时代,数据集的大小已经超过一台独立物理计算机的存储能力,我们需要对数据进行分区(partition)并存储到若干台单独的计算机上,也就出现了管理网络中跨多 ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
随机推荐
- php--------网页开发实现微信JS的(定位,地图显示,照片选择功能)
今天说说微信网页开发中一下JS的功能,分享一下,希望对各位有所帮助. 前提:要有公众号,和通过微信认证,绑定域名,得到相应信息,appid,appsecret等. 微信开发文档:https://mp. ...
- fatal error LNK1112: 模块计算机类型“X86”与目标计算机类型“x64”冲突——我的解决方案
本文转载于:http://blog.csdn.net/tfy1028/article/details/8660823 win7 下,安装的VS2010,然后搭配opencv2.4.3运行,报错为:fa ...
- Leetcode 33
//这题真的很有思维难度啊,前前后后弄了2个小时才写完.//一定要首先将连续的一段找出来,如果target在里面就在里面找,如果不在连续段里就在另一部分找.//如果后面二分到都是连续段也是没事了,我们 ...
- curl使用记录
$header = array("Connection: Keep-Alive", "Accept: text/html,application/xhtml+xml,ap ...
- bzoj4129
题解: 树上+可修改莫队 莫队的每一块 可以用一个栈 每一次dfs个数>sqrt(n)(自己选的)的时候就可以跳出了 然后不要忘记分出来最后一块 代码: #include<bits/std ...
- Halcon12新特性之VS可视化调试插件
当我们用VC\C#调试halcon代码的时候,通常会遇到一个头痛的问题,我们无法看到halcon变量的调试信息 如下图:什么鬼...什么鬼 比如我们想看一个double数值变量,我们需要 doub ...
- New Concept English Two 7
$课文14 你会讲英语吗? 133. I had an amusing experience last year. 去年我有过一次有趣的经历. 134. After I had left a smal ...
- Centos 7 系统详解
安装CentOS 7系统后,变化竟然这么大? 一.Runlevel首先一条,原来一直用的CentOS-6.5-x86_64-minimal.iso光盘镜像(400M左右无图形系统小巧便捷),而7目 ...
- 使用eclipse启动系统时报错“ java.lang.OutOfMemoryError: PermGen space”问题的解决
转载请注明出处:http://blog.csdn.net/dongdong9223/article/details/76571611 本文出自[我是干勾鱼的博客] 有的时候,使用eclipse启动系统 ...
- js base64 转成图片上传
直接上代码,要点就是把base64转成Blob,添加到FormData传递给后台程序,跟选择图片文件上传时一样的了. var dataurl = canvas.toDataURL('image/png ...