基于线程池技术的web服务器
前言:首先简单模拟一个场景,前端有一个输入框,有一个按钮,点击这个按钮可以实现搜索输入框中的相关的文本和图片(类似于百度、谷歌搜索).看似一个简单的功能,后端处理也不难,前端发起一个请求,后端接受到这个请求,获取前端输入的内容,然后用搜索服务查找相关的数据返回给前端。但是问题来了,可能不是一个用户在搜索,假如有一万个用户同时发起请求呢?后端如何处理?如果按照单机的 处理方式,很容易线程堵死,程序崩溃、数据库崩塌。本文来介绍一下如何通过线程池来处理前端的请求。
本篇博客的目录
一:线程池的优点
二:定义一个线程池
三: 线程池实现类
四:执行任务
五:总结
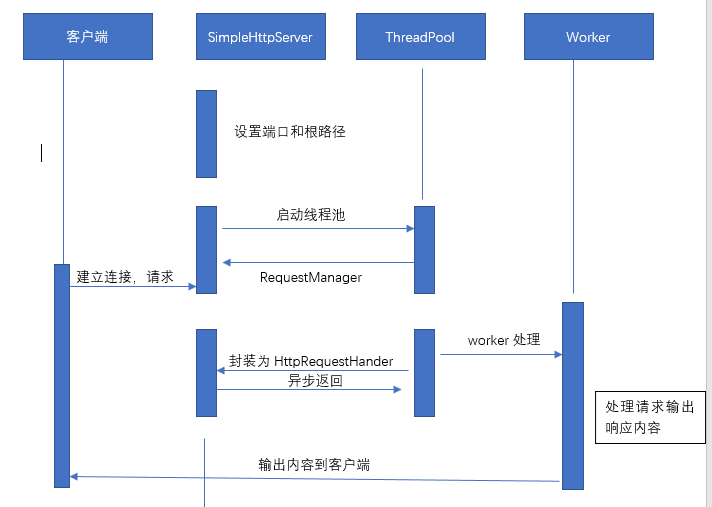
本篇博客技术总架构图:
一:线程池的好处
1.1:好处
1.1.1 线程池可以异步的执行任务,当任务进来的时候线程池首先会判断当前是否有存活可用的线程,如果有的话,线程会执行这个任务。但是任务此时可以立刻返回,并不一定必须等待任务执行完毕才会返回。假如是同步阻塞的话,当一个线程遇到Exception的时候,假如这个线程没有得到处理,那么就会造成线程堵塞,资源囤积,最终的结果只能是cpu资源耗尽,所有的任务无法处理。之前我们的线上就出现了很多dubbo服务访问超时问题,最后发现就是cpu资源耗尽,报了一个unable to create new Thread,这样就无法处理任务(最后我们进行了物理扩容并且合理限定了线程池的最大线程数量才解决这个问题)
1.1.2:线程池可以集中管理线程,可以控制线程的运行周期,这里包括动态添加线程或者移除线程。有一个很重要的点是这样的:线程的上下文切换是非常消耗性能的;假如来了一个任务,线程执行一次,然后立刻销毁;再来一个任务,再创建一个任务,用完再销毁这个线程。那么为什么不能对这个线程进行复用呢?
1.1.3:线程池的优势只有在高请求量才会体现出来,如果请求量比较好,需要处理的任务很少,那么使用线程池的作用并不明显。但是并不是线程数量越多越好,具体的数量需要评估每个任务的处理时间以及当前计算机的处理能力和数量,这个是有具体的数据体现的,我们来看一下实际数据比较:

二:定义一个线程池
2.1:首先我们来定义一个线程池的接口,其中包含线程池开始任务、关闭线程池,增加线程、减少线程,线程池的使命就是管理线程的生命周期,包括加、减少和删除线程,还有让线程开始执行任务,自身的关闭和开启!
public interface ThreadPool<Job extends Runnable> {
/**
* 线程池开始
*/
void execute(Job job);
/**
* 关闭线程池
*/
void shutDown();
/**
* 添加线程
* @param num
*/
void addWorkers(int num);
/**
* 减少线程
* @param num
*/
void removeWorker(int num);
/**
* 获取正在等待的线程数量
* @return
*/
int getJobSize();
}
三:线程池实现类
解释: 线程池的实现类,首先就是定义线程池的默认数量,为2*cpu核心数+1,这是比较合理的计算公式。最小数量定义为1,最大数量定义为10。还用一个LinkedList来作为工作线程的集合容器。这里为什么要用linkedList而不是ArrayList呢?因为linkedList是一个双向链表,双向链表可以实现先进先出或者后进先出等集合。然后我们定义了worker来封装具体执行任务的线程,用Job来封装要执行的任务。然后在构造方法里用initWorkers方法来初始化线程池,创建指定的默认数量的线程,指定名称(用AtomicLong:原子线程安全的)并添加到管理线程的集合workers中(这个list经过synchronizedList修饰它已经成为了一个同步的集合,所做的操作都是线程安全的)。在execute中,首先获取需要指定的任务(Job),为了保证线程安全,会锁住所有的任务集合(放心synchronized这个关键字的作用,它经过jdk1.7已经优化过了,性能消耗有质的提升)。这里为什么要锁住jobs这个集合呢,答案是:为了防止在多线程环境下,有多个job同时添到这个jobs里面,任务要一个个的执行,防止无法执行任务。接着再用addLast方法将任务添加到链表的最后一个,这里就是一个先进先出的队列(先进入的线程会优先被执行)再调用jobs的notify方法唤醒其他job。而在下面的添加线程或者移除线程的方法,都必须要锁住整个工作队列,这里为了防止,执行的时候突然发现job不见了,或者添加的时候取不到最新的job等多线程下的安全问题,并且在worker线程中增加了一个running字段,用于控制线程的运行或者停止(run方法是否执行的控制条件)
public class DefaultThreadPool<Job extends Runnable> implements ThreadPool<Job> {
private static final int MAX_WORKER_NUMBERS = 10;
private static final int DEFAULT_WORKERS_NUMBERS = 2 * (Runtime.getRuntime().availableProcessors()) + 1;
private static final int MIN_WORDER_NUMBERS = 1;
private final LinkedList<Job> jobs = new LinkedList<Job>();
//管理工作线程的集合
private final List<Worker> workers = Collections.synchronizedList(new ArrayList<Worker>());
private int workerNum = DEFAULT_WORKERS_NUMBERS;
private AtomicLong threadNum = new AtomicLong();
/**
* 线程开始运行
*/
public DefaultThreadPool() {
initWorkers(DEFAULT_WORKERS_NUMBERS);
}
public DefaultThreadPool(int num) {
workerNum = num > MAX_WORKER_NUMBERS ? MAX_WORKER_NUMBERS : num < MIN_WORDER_NUMBERS ? MIN_WORDER_NUMBERS : num;
}
/**
* 初始化线程
*
* @param defaultWorkersNumbers
*/
private void initWorkers(int defaultWorkersNumbers) {
for (int i = 0; i < defaultWorkersNumbers; i++) {
Worker worker = new Worker();
workers.add(worker);
Thread thread = new Thread(worker, "ThreadPool-worker" + threadNum.incrementAndGet());
thread.start();
}
}
/**
* 执行任务
*
* @param job
*/
@Override
public void execute(Job job) {
if (job != null) {
synchronized (jobs) {
jobs.addLast(job);
jobs.notify();
}
}
}
/**
* 关闭线程
*/
@Override
public void shutDown() {
for (Worker worker : workers) {
if (worker != null) {
worker.shutDown();
}
}
}
/**
* 添加线程
*
* @param num
*/
@Override
public void addWorkers(int num) {
synchronized (jobs) {
if (num + this.workerNum > MAX_WORKER_NUMBERS) {
num = MAX_WORKER_NUMBERS - this.workerNum;
}
initWorkers(num);
this.workerNum += num;
}
}
/**
* 移除线程
*
* @param num
*/
@Override
public void removeWorker(int num) {
synchronized (jobs) {
if (num > workerNum) {
throw new IllegalArgumentException("much workNum");
}
int count = 0;
while (count < num) {
Worker worker = workers.get(count);
if (workers.remove(worker)) {
worker.shutDown();
count++;
}
}
this.workerNum -= count;
}
}
/**
* 获取工作线程的数量
*
* @return
*/
@Override
public int getJobSize() {
return jobs.size();
}
/**
* 工作线程
*/
public class Worker implements Runnable {
private volatile boolean running = false;
@Override
public void run() {
while (running) {
Job job = null;
synchronized (jobs) {
while (jobs.isEmpty()) {
try {
jobs.wait();
} catch (InterruptedException ex) {
ex.printStackTrace();
Thread.currentThread().interrupt();
return;
}
}
job = jobs.removeFirst();
}
if (job != null) {
try {
job.run();
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
}
public void shutDown() {
this.running = false;
}
}
}
四:简易的web http处理线程池
4.1:定义一个类,叫做SimlpeHttpHandler,其中维护着一个叫做HttpRequestHandler的job,这个job的作用就是通过socket监听固定的端口(8080),然后通过流读取web目录中的文件,根据不同的文件格式封装打印返回
public class SimleHttpHandler {
static ThreadPool<HttpRequestHandler> threadPool = new DefaultThreadPool<HttpRequestHandler>(1);
public String basePath;
private ServerSocket serverSocket;
@Resource
private HttpRequestHandler httpRequstHandler;
int port = 8080;
/**
* 设置端口
*
* @param port
*/
public void setPort(int port) {
if (port > 0) {
this.port = port;
}
}
/**
* 设置基本路径
*
* @param basePath
*/
public void setBasePath(String basePath) {
if (basePath != null) {
boolean exist = new File(basePath).exists();
boolean directory = new File(basePath).isDirectory();
if (exist && directory) {
this.basePath = basePath;
}
}
}
/**
* 开始线程
*
* @throws Exception
*/
public void start() throws Exception {
serverSocket = new ServerSocket(port);
Socket socket = null;
while ((socket = serverSocket.accept()) != null) {
try {
threadPool.execute(new HttpRequestHandler(socket, basePath));
} catch (Exception ex) {
ex.printStackTrace();
} finally {
serverSocket.close();
}
}
}
}
4.2:定义一个类叫做HttpRequestHandler实现Runnable接口,然后构造进入socket和路径,在run方法中调用具体的处理方法:我将具体的业务封装到
ServerRequestManager中,然后调用它的dealRequest方法进行具体的业务处理:
@Component
public class HttpRequestHandler implements Runnable { private Socket socket; private String basePath; @Resource
private ServerRequestManager serverRequestManager; public HttpRequestHandler(Socket socket, String basePath) {
this.basePath = basePath;
this.socket = socket;
} @Override
public void run() {
serverRequestManager.dealRequest(basePath);
}
}
4.3:服务器的具体处理逻辑,这里就是根据当前的路径用流读取路径中的文件,一旦检测到文件的后缀是.jpg或者ico,就将其输出为http的内容类型为img类型的图片,否则输出为text类型。最后用colse方法来关闭流
*/
@Component
public class ServerRequestManager { private Socket socket;
public static final String httpOK = "HTTP/1.1 200 ok";
public static final String molly = "Server:Molly";
public static final String contentType = "Content-Type:";
/**
* 处理请求
*
* @param basePath
*/
public void dealRequest(String basePath) {
String content = null;
BufferedReader br = null;
BufferedReader reader = null;
PrintWriter out = null;
InputStream in = null;
try {
reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String header = reader.readLine();
String filePath = basePath + header.split(" ")[1];
out = new PrintWriter(socket.getOutputStream());
if (filePath.endsWith("jpg") || filePath.endsWith("ico")) {
in = new FileInputStream(filePath);
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
int index = 0;
while ((index = in.read()) != -1) {
byteArrayOutputStream.write(index);
}
byte[] array = byteArrayOutputStream.toByteArray();
out.print(httpOK);
out.print(molly);
out.println(contentType + " image/jpeg");
out.println("Content-Length" + array.length);
out.print("");
socket.getOutputStream().write(array, 0, array.length);
} else {
br = new BufferedReader(new InputStreamReader(new FileInputStream(filePath)));
out = new PrintWriter(socket.getOutputStream());
out.print(httpOK);
out.print(molly);
out.print(contentType + "text/html; Charset =UTF-8");
out.print("");
while ((content = br.readLine()) != null) {
out.print(content);
}
}
out.flush();
} catch (final Exception ex) {
ex.printStackTrace();
out.println("HTTP/1.1 500");
out.println("");
out.flush();
} finally {
close(br, in, out, socket);
}
} /**
* 关闭流
*
* @param closeables
*/
public static void close(Closeable... closeables) {
if (closeables != null) {
for (Closeable closeable : closeables) {
try {
closeable.close();
} catch (Exception ex) {
ex.printStackTrace();
}
}
} }
}
五:总结
本篇博客总结了如何开发一个简单的线程池,当然功能不够齐全,比不上jdk的线程池,没有阻塞队列和超时时间和拒绝策略等;然后会用socket监听8080端口,获取web根目录读取目录下的文件,然后输出对应的格式内容。实现的功能很简单,没有什么复杂的,不过我觉的这篇这篇博客能让我学习的地方就是线程池的使用方法,在处理高并发的请求时,线程池技术基本是必不可少的。
参考资料《java并发编程的艺术》
*假如你想学习java,或者看本篇博客有任务问题,可以添加java群:618626589
基于线程池技术的web服务器的更多相关文章
- 基于SmartThreadPool线程池技术实现多任务批量处理
一.多线程技术应用场景介绍 本期同样带给大家分享的是阿笨在实际工作中遇到的真实业务场景,请跟随阿笨的视角去如何采用基于开源组件SmartThreadPool线程池技术实现多任务批量处理.在工作中您是否 ...
- 【Java TCP/IP Socket】基于线程池的TCP服务器(含代码)
了解线程池 在http://blog.csdn.net/ns_code/article/details/14105457(读书笔记一:TCP Socket)这篇博文中,服务器端采用的实现方式是:一个客 ...
- requests模块session处理cookie 与基于线程池的数据爬取
引入 有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们想要的目的,例如: #!/usr/bin/ ...
- Python网络爬虫之cookie处理、验证码识别、代理ip、基于线程池的数据爬去
本文概要 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 引入 有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时, ...
- 用 ThreadPoolExecutor/ThreadPoolTaskExecutor 线程池技术提高系统吞吐量(附带线程池参数详解和使用注意事项)
1.概述 在Java中,我们一般通过集成Thread类和实现Runnnable接口,调用线程的start()方法实现线程的启动.但如果并发的数量很多,而且每个线程都是执行很短的时间便结束了,那样频繁的 ...
- 基于线程池的多并发Socket程序的实现
Socket“服务器-客户端”模型的多线程并发实现效果的大体思路是:首先,在Server端建立“链接循环”,每一个链接都开启一个“线程”,使得每一个Client端都能通过已经建立好的线程来同时与Ser ...
- java线程池技术
1.线程池的实现原理?简介: 多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力.假设一个服务器完成一项任务所需时间为:T1 创建线程时间, ...
- Java线程池技术以及实现
对于服务端而言,经常面对的是客户端传入的短小任务,需要服务端快速处理并返回结果.如果服务端每次接受一个客户端请求都创建一个线程然后处理请求返回数据,这在请求客户端数量少的阶段看起来是一个不错的选择,但 ...
- 设计模式:基于线程池的并发Visitor模式
1.前言 第二篇设计模式的文章我们谈谈Visitor模式. 当然,不是简单的列个的demo,我们以电商网站中的购物车功能为背景,使用线程池实现并发的Visitor模式,并聊聊其中的几个关键点. 一,基 ...
随机推荐
- TPO-17 C1 Find materials for an opera paper
TPO-17 C1 Find materials for an opera paper production n. 成果:产品:生产:作品 第 1 段 1.Listen to a conversati ...
- 7.hdfs工作流程及机制
1. hdfs基本工作流程 1. hdfs初始化目录结构 hdfs namenode -format 只是初始化了namenode的工作目录 而datanode的工作目录是在datanode启动后自己 ...
- redis rdb aof比较
Redis中数据存储模式有2种:cache-only,persistence; cache-only即只做为“缓存”服务,不持久数据,数据在服务终止后将消失,此模式下也将不存在“数据恢复”的手段,是一 ...
- Python Pygame (3) 界面显示
显示模式: 之前使display模块的set_mode()的方法用来指定界面的大小,并返回一个Surface对象. set_mode()的原型如下: display.set_mode(resoluti ...
- C# string 常用方法
string.ToString().Contains() String str="abcd" str.ToString().Contains("a"); //t ...
- a7
组员:陈锦谋 今日内容: PS学习.抠图.图标像素调整 明日计划: PS学习 困难: 不够细心.耐心
- POJ2528的另一种解法(线段切割)
题目:Mayor's posters 原文地址 首先本题题意是:有一面墙,被等分为1QW份,一份的宽度为一个单位宽度.现在往墙上贴N张海报,每张海报的宽度是任意 的,但是必定是单位宽度的整数倍,且&l ...
- OC创建对象并访问成员变量
1.创建一个对象 Car *car =[Car new] 只要用new操作符定义的实体,就会在堆内存中开辟一个新空间 [Car new]在内存中 干了三件事 1)在堆中开辟一段存储空间 2)初始化成员 ...
- HDFS shell命令行常见操作
hadoop学习及实践笔记—— HDFS shell命令行常见操作 附:HDFS shell guide文档地址 http://hadoop.apache.org/docs/r2.5.2/hadoop ...
- beta-review阶段贡献分分配
小组名称:飞天小女警 项目名称:礼物挑选小工具 小组成员:沈柏杉(组长).程媛媛.杨钰宁.谭力铭 bera-review阶段各组员的贡献分分配如下: 姓名 团队贡献分 程媛媛 5.8 沈柏杉 6.1 ...