C#Encoding
1、Encoding
(1)、如何生成一个Encoding即一种编码
Encoding位于System.Text命名空间下,是一个抽象类,它的派生类如下图:
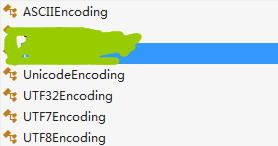
要实例化一个Encoding一共有以下两种方式:
a、通过实例化它的派生类,然后通过里式转换实例化一个Encoding,代码如下:
Encoding e=new UTF8Encoding();
b、通过Encoding的静态属性ASCII,Unicode,UTF32,UTF7,UTF8,Default来生成,代码如下:
Encoding e = Encoding.UTF8;
其实b中的静态属性无非是new了一个a中的派生类,有图为证

注:上面通过静态属性生成的Encoding实例,符合单例模式,但是并不适用在多线程环境下,所以当你的Encoding需要全局唯一时,请使用静态属性的方式,而不是通过new的方式。
(2)Encoding.Default
注意(1)中b,Encoding的静态属性中有一个Default,它没有对应的派生类,但是它返回的也是一个Encoding对象,至于返回那种语言的Encoding,取决于取决于你电脑里-->控制面板->区域和语言 里面的设置,也就是ANSI,比如我的电脑设置的是中文,那么对应的就是gb2312,但是如果你的代码不止在一个国家使用,那么就不要使用Encoding.Default,这样会造成乱码,最好使用Encoding.UTF8.
2、如何调用常用编码之外的编码,通过GetEncoding()和GetEncodings()
上面介绍了ASCII,Unicode,UTF32,UTF7,UTF8常规的5中编码方式,但是有一些编码如gb2312就没有对应的派生类,那么获取这类语言对应的Encoding只能通过GetEncoding()和GetEncodings()方法来获取
(1)、GetEncodings()
通过GetEncodings()可以获取所有的编码,代码如下:
EncodingInfo[] infos = Encoding.GetEncodings();
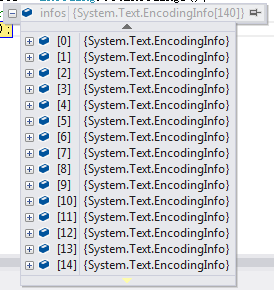
目前为止一共有140种,通过GetEncodings()方法你可以方便的查看所有语言的编码信息,本人开发了一个简单窗体应用程序,来查询不同的编码信息。点击下载
(2)、GetEncoding()
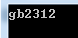
通过这个方法可以获取指定语言的Encoding,当然你必须给出一个codePage或者是name,代码如下:
Encoding ei=Encoding.GetEncoding(936);
Console.WriteLine(ei.WebName);
3、通过Encoding完成字节和字符之间的转换
(1)、GetBytes() 含多种重载方法
通过GetBytes()可以把一个字符串或者是字符串数组转换成字节,代码如下
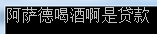
string str = "阿萨德喝酒啊是贷款";
byte[] bytes = Encoding.Unicode.GetBytes(str);
(2)、GetChars()含多种重载方法
通过GetChars()可以将字节数组转换成字符,代码如下
string str = "阿萨德喝酒啊是贷款";
byte[] bytes = Encoding.Unicode.GetBytes(str);
char[] a=Encoding.Unicode.GetChars(bytes);
Console.WriteLine(a);
(3)、GetByteCount()含多种重载方法
通过GetByteCount()可以获得将字符串或者字符串数组转换成字节数组的字节数组的长度,代码如下:
string str = "阿萨德喝酒啊是贷款";
int count= Encoding.Unicode.GetByteCount(str);
Console.WriteLine(count);

(4)、GetCharCount()含多种重载方法
通过GetCharCount()可以获得将字节数组转换成字符串或者字符数组的字符串长度,代码如下:
string str = "阿萨德喝酒啊是贷款";
byte[] bytes = Encoding.Unicode.GetBytes(str);
int count = Encoding.Unicode.GetCharCount(bytes);
Console.WriteLine(count);

4、BOM 判断文件的编码方式
这个BOM并不是Html中的BOM,而是一种字节顺序标记,BOM的全称是全称是Byte Order Mark,是一段二进制,用于标识一个文本是用什么编码的,比如当用Notepad打开一个文本时,如果文本里包括这一段BOM,那么它就能判断是采用哪一种编码方式,并用相应的解码方式,就会正确打开文本不会有乱码.如果没有这一段BOM,Notepad会默认以ANSI打开,这种会有乱码的可能性.
下面是通过BOM来判断文件编码的一段工具方法,代码如下:

public static Encoding GetFileEncoding(string filePath)
{
Encoding Result = null;
FileInfo info = new FileInfo(filePath);
FileStream fs = default(FileStream);
try
{
fs = info.OpenRead();
Encoding[] unicodeEncodings =
{
Encoding.BigEndianUnicode,
Encoding.Unicode,
Encoding.UTF8,
Encoding.UTF32,
Encoding.UTF7,
new UTF32Encoding(true,true)
};
for (int i = 0; Result == null && i < unicodeEncodings.Length; i++)
{
fs.Position = 0;
byte[] preamble = unicodeEncodings[i].GetPreamble();
bool isEqual = true;
for (int j = 0; isEqual && j < preamble.Length; j++)
{
isEqual = preamble[j] == fs.ReadByte();
}
if (isEqual)
Result = unicodeEncodings[i]; }
}
catch (IOException ex)
{
throw ex;
}
finally
{
if (fs != null)
{
fs.Close();//包括了Dispose,并通过GC强行释放资源
}
}
if (object.ReferenceEquals(null, Result))
{
Result = Encoding.Default;
}
return Result;
}
5、Encoder和Decoder
(1)、Encoder是一个抽象类,它在Encoding中以一个虚方法的形式出现,调用该方法,会返回一个指定编码的编码器

代码如下:
string str = "Encoder测试";
int charCount=str.Length;
Encoding ed=Encoding.UTF8;
char[] chars = str.ToCharArray();
int maxByteCount=ed.GetEncoder().GetByteCount(chars,0,charCount,false);//通过GetEncoder()获得的UFF8编码器获得str转换成byte数组的长度
byte[] result=new byte[maxByteCount];
ed.GetEncoder().GetBytes(chars, 0, charCount, result, 0, false);//通过GetEncoder()获得的UTF8编码器对str进行加密,并将加密后的字节数组赋给result
for (int i = 0; i < result.Length; i++)
{
if (i != result.Length-1)
Console.Write("{0:X}-", result[i]);//以16进制输出
else
Console.Write("{0:X}", result[i]);
}
Console.ReadLine();

(2)、Decoder也是一个抽象类,它在Encoding中也是以一个虚方法的形式出现,调用该方法,会返回一个指定编码的解码器
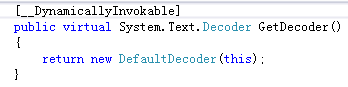
代码如下:
string str = "Encoder测试";
int charCount=str.Length;
Encoding ed=Encoding.UTF8;
char[] chars = str.ToCharArray();
int maxByteCount=ed.GetEncoder().GetByteCount(chars,0,charCount,false);
byte[] result=new byte[maxByteCount];
ed.GetEncoder().GetBytes(chars, 0, charCount, result, 0, false);
char[] resultChars=new char[ed.GetDecoder().GetCharCount(result,0,maxByteCount)];
ed.GetDecoder().GetChars(result, 0, result.Length, resultChars,0,false);
for (int i = 0; i < resultChars.Length; i++)
{
if (i != resultChars.Length - 1)
Console.Write("{0}-", resultChars[i]);
else
Console.Write("{0}", resultChars[i]);
}
Console.ReadLine();

通过分析上面两端发现,其实它们的作用和单纯的调用Encoding的静态属性进行编解码并没有什么区别,而且使用Encoding进行编解码更加的便捷,就不需要创建额外的Encoder和Decoder对象实例,现在就来讲解Encoder和Decoder真正的作用!
(3)、通过一个特殊的需求来说明GetDecoder和GetEncoder()的作用
通过Encoding的静态属性对(字符串或者字符数组)的整个片段进行编解码时,并不会出现任何问题,代码如下:
string str = "Encoding博客系列";
byte[] bytes = Encoding.UTF8.GetBytes(str);
char[] result = Encoding.UTF8.GetChars(bytes);
Console.WriteLine(result);

但是当处理部分片段,并且片段中有多字节字符或者字符串(如中文),就会出现乱码的情况,代码如下:
假设我们需要的在后处理一个特殊文件流,要求每次只处理4个字节,代码如下:
string path = Path.GetTempFileName();//创建临时文件,并返回该文件的路径
File.WriteAllText(path, "Encoding博客系列", new UTF8Encoding(false));//覆盖上面的临时文件,并向文件中追加一段字符串,采用UTF8编码
using (FileStream stream = File.OpenRead(path))
{
byte[] buffer = new byte[4];
int size;
while ((size = stream.Read(buffer, 0, 4)) > 0)
{
char[] chars = Encoding.UTF8.GetChars(buffer, 0, size);
if (chars.Length != 0)
{
Console.Write("{0,-6}", new string(chars));
Console.Write("字节:");
for (int i = 0; i < size; i++)
{
Console.Write("{0:X2} ", buffer[i]);//将单个字节以2位16进制输出
}
Console.WriteLine();
}
Thread.Sleep(1000);
}
}
Console.Read();
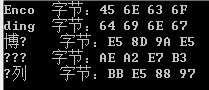
目前我不清楚为什么出现这个问题的原因,由于时间问题,我也不想深究下去,如果有兴趣,你可以去解读下Encoding的源码。
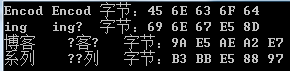
so,为了解决这个问题,就只能使用调用UTF8的解码器,对字符或者字符数组进行解码,修正代码如下:
string path = Path.GetTempFileName();//创建临时文件,并返回该文件的路径
File.WriteAllText(path, "Encoding博客系列", new UTF8Encoding(false));//覆盖上面的临时文件,并向文件中追加一段字符串,采用UTF8编码
Decoder dr = Encoding.UTF8.GetDecoder();
using (FileStream stream = File.OpenRead(path))
{
byte[] buffer = new byte[5];
int size;
while ((size = stream.Read(buffer, 0, 5)) > 0)
{
char[] charsDecoder = new char[dr.GetCharCount(buffer, 0, size)];
dr.GetChars(buffer, 0, size, charsDecoder, 0);
char[] chars = Encoding.UTF8.GetChars(buffer, 0, size);
if (chars.Length != 0)
{
Console.Write("{0,-6}", new string(charsDecoder));
Console.Write("{0,-6}", new string(chars));
Console.Write("字节:");
for (int i = 0; i < size; i++)
{
Console.Write("{0:X2} ", buffer[i]);//将单个字节以2位16进制输出
}
Console.WriteLine();
}
Thread.Sleep(1000);
}
}
Console.Read();
Encoder和Decoder 维护对 GetBytes() 和GetChars()的连续调用间的状态信息,因此它可以正确地对跨块的字符序列进行编码。Encoder 还保留数据块结尾的尾部字符并将这些尾部字符用在下一次编码操作中。例如,一个数据块的末尾可能是一个不匹配的高代理项,而与其匹配的低代理项则可能位于下一个数据块中。因此,Decoder 和 Encoder 对网络传输和文件操作很有用,这是因为这些操作通常处理数据块而不是完整的数据流。StreamReader和SteamWriter关于读和书的就是用Decoder和Encoder。
综上所述:
1. CLR中字符串都是Unicode 16 编码
2. 尽量调用Encoding的静态属性UTF8,Unicode等,而不是去实例它们
3. 尽量避免用Encoding.Defalut
4. BOM是用来识别哪一种编码的,默认是带有的,如果不需要,那么调用它们的带有参数的构造器,找到相应参数传false
5. 在对文件流和网络流操作时,应该用Encoder和Decoder
本文参考自:http://www.cnblogs.com/criedshy/archive/2012/08/07/2625358.html
C#Encoding的更多相关文章
- javac -encoding utf8 in linux
由于另外负责编码的同事用的是utf-8,我用的默认的编码格式gbk,在提交代码时,为了迁就他,我打算把格式用工具转成utf-8. 转化成果后,然后在make一下,发现javac -encoding u ...
- 创建Odoo8数据库时的“new encoding (UTF8) is incompatible with the encoding of the template database (SQL_ASCII)“问题
Odoo8创建数据库时,显示如下错误信息: DataError: new encoding (UTF8) is incompatible with the encoding of the templa ...
- Node.js Base64 Encoding和Decoding
如何在Node.js中encode一个字符串呢?是否也像在PHP中使用base64_encode()一样简单? 在Node.js中有许多encoding字符串的方法,而不用像在JavaScript中那 ...
- java Properties异常:Malformed \uxxxx encoding.
昨天项目中遇到一个 java.lang.IllegalArgumentException: Malformed \uxxxx encoding.这样的一个异常,debug了一下发现是读取propert ...
- svn: Can't convert string from 'UTF-8' to native encoding 的解决办法(转)
http://www.cnblogs.com/xuxm2007/archive/2010/10/26/1861223.html svn 版本库中有文件是以中文字符命名的,在 Linux 下 check ...
- C# 字符编码类Encoding
在网络通信中,很多情况下都是将字符信息转成字节序列进行传输.将字符序列转为字节序列的过程称为编码.当这些字节传送到接收方,接收方需要逆向将字节序列转为字符序列.这个过程就是解码. 常见编码有ASCII ...
- 字符集和字符编码(Charset & Encoding)
字符集和字符编码(Charset & Encoding)[转] 1.基础知识 计算机中储存的信息都是用二进制数表示的:而我们在屏幕上看到的英文.汉字等字符是二进制数转换之后的结果.通俗的说,按 ...
- 使用英文版eclipse保存代码,出现some characters cannot be mapped using "Cp1251" character encoding.
some characters cannot be mapped using "Cp1251" character encoding. 解决办法:方案一: eclipse-> ...
- <?xml version="1.0" encoding="UTF-8"?> 的作用?
version="1.0" 声明用的xml版本是1.0 encoding="UTF-8" 声明用xml传输数据的时候的字符编码,假如文档里面有中文,编码方式不是 ...
- 关于Unicode和URL encoding入门的一切以及注意事项
本文同时也发表在我另一篇独立博客 <关于Unicode和URL encoding入门的一切以及注意事项>(管理员请注意!这两个都是我自己的原创博客!不要踢出首页!不是转载!已经误会三次了! ...
随机推荐
- 原生态JDBC问题的总结
package com.js.ai.modules.aiyq.testf; import java.sql.Connection; import java.sql.DriverManager; imp ...
- solr删除全部索引数据
SOLR 删除全部索引数据: <delete><query>*:*</query></delete><commit/>
- uva-11111-栈
注意输入和输出的结果 -9 -7 -2 2 -3 -2 -1 1 2 3 7 9 -9 -7 -2 2 -3 -1 -2 2 1 3 7 9-9 -7 -2 2 -3 -1 -2 3 2 1 7 9- ...
- probably another instance of uWSGI is running on the same address (127.0.0.1:9090). bind(): Address already in use
probably another instance of uWSGI is running on the same address (127.0.0.1:9090). bind(): Address ...
- js格式化时间 js格式化时间戳
一个js格式化时间和js格式化时间戳的例子. 代码:/** * 时间对象的格式化; */Date.prototype.format = function(format) { /* * eg:forma ...
- xml 注释中不允许出现字符串“--“(再也不要来坑爹了,好么,XML)
转自:https://blog.csdn.net/randomnet/article/details/18708575?utm_source=blogxgwz3 关于xml文件时出现中文注释出错的一个 ...
- 彻底禁止win10更新
关闭win10自动更新: 可以用下面方法关闭: 1.首先在服务界面关闭Windows Update服务并设置为禁用并在恢复界面全部如下图设置为无操作. 2.只关闭了Windows Update服务发现 ...
- Navigation and Pathfinding
[Navigation and Pathfinding] 术语: 1)NavMesh 2)NavMesh Agent 3)Off-Mesh Link 4)NavMesh Obstacle A comm ...
- Python_01-入门基础
以后我会发表一系列python脚本的学习资料,python版本为2.x. 目录: 1 Python入门基础 1.1 学习资源 1.2 所有语言的入门程序---Hello World! 1.3 帮助函 ...
- java把流抛给浏览器下载时,当下载的文件文件名为中文时,出现中文名被替换为“----------”的情况
比如说,下载的文件名为: 软件分析报告.docx,当使用流抛给浏览器下载时,浏览器下载的文件为:-----------.docx 出现这种情况的原因:大体的原因就是header中只支持ASCII,所以 ...