七、spark核心数据集RDD
简介
spark RDD操作具体参考官网:http://spark.apache.org/docs/latest/rdd-programming-guide.html#overview
RDD全称叫做Resilient Distributed Datasets,直译为弹性分布式数据集,是spark中非常重要的概念。
首先RDD是一个数据的集合,这个数据集合被划分成了许多的数据分区,而这些分区被分布式地存储在不同的物理机器当中,如图:
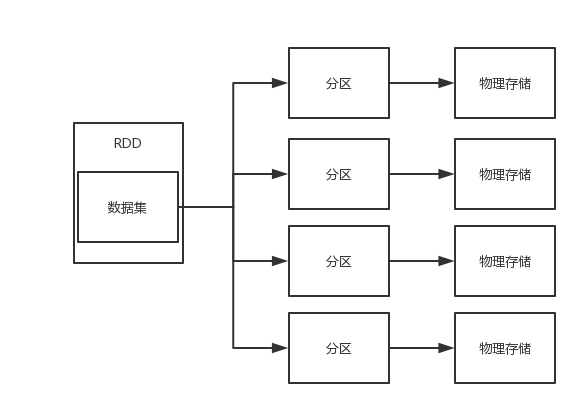
我们反过来想一下,RDD就是很多物理数据块的逻辑抽象。不仅如此,RDD还提供了一些列接口来操作这个逻辑抽象的数据集合。
我们把这些接口分成两大类:
1)transformation 转换
2)action 操作
transformation主要就是把一个RDD转换成另一个RDD,或者就是一开始把原始数据加载成为一个RDD;
注意:transformation并不会马上执行,只有等到action操作的时候才会执行。
action主要就是把一个RDD存储到硬盘,或者触发transformation的执行。
RDD转换和操作示例
我们先看一张图
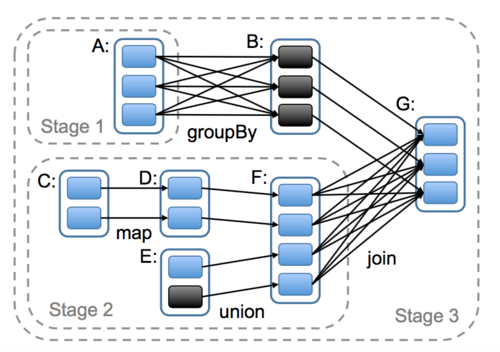
1)首先我们会从数据源中把数据加载成为RDD,也就是左边的RDDA和RDDC以及RDDE
2)RDDC经过map转换成为了RDDD
3)RDDE和RDDC经过union转换成为了RDDF
4)RDDA经过groupBy转换成为了RDDB
5)RDDB和RDDF经过join转换成为了RDDG
以上这些转换只是对整个过程进行一个描述,并没有立即执行,我们可以理解为对过程进行一个计划。直到我们调用一个saveAsSequenceFile持久化action操作的时候就会把上面的步骤催生出一个job,这个job根据是否shuffle(shuffle即宽依赖,下文提及)划分为了三个stage,并开始并行执行。
宽依赖和窄依赖
为了更加理解RDD,我们继续了解一下spark的核心原理
如图
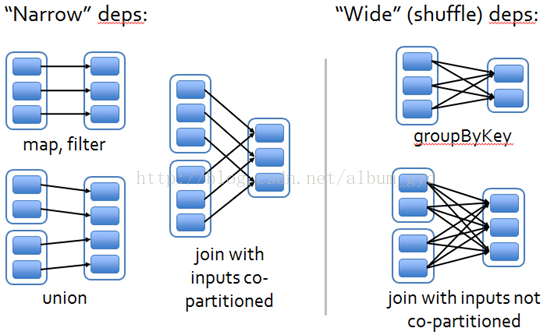
左边的部分是窄依赖,右边的部分是宽依赖即shuffle
上图的每一个蓝色块就是一个分区,而分区的集合就是一个RDD。同时RDD经过转换就会变成另一个RDD,那么也就会存在父子关系,由父RDD转换为子RDD。同时一个子RDD可能由多个父RDD转换而来。
那么,如果一个子RDD的每一个分区都只依赖于任意一个父RDD的其中一个分区,我们就认为它是窄依赖;
而,如果一个子RDD的任意一个分区都依赖于某一个父RDD的一个到多个的分区,我们就认为它是宽依赖。
我们的程序代码被解析成dag有向无环图以后,DagScheduler根据是否shuffle宽依赖来划分stage,每一个shuffle之前都是一个stage。
这么做的理由是这样划分的话,每一个stage的task都可以独立并行计算,而TaskScheduler也不用去了解stage的存在只需要知道task即可,然后TaskScheduler把task分发给WorkNode节点的executor去执行。
七、spark核心数据集RDD的更多相关文章
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark 核心概念RDD
文章正文 RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此, ...
- 深入理解Spark(一):Spark核心概念RDD
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD
http://blog.csdn.net/pipisorry/article/details/53257188 弹性分布式数据集RDD(Resilient Distributed Dataset) 术 ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- Spark核心—RDD初探
本文目的 最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken).感觉需要记录点什么,才对得起自己.下面的内容主要是关于Spark核心-RDD的相关 ...
- Spark弹性分布式数据集RDD
RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现.RDD是Spark最核心 ...
- 1.spark核心RDD特点
RDD(Resilient Distributed Dataset) Spark源码:https://github.com/apache/spark abstract class RDD[T: C ...
- Spark计算模型-RDD介绍
在Spark集群背后,有一个非常重要的分布式数据架构,即弹性分布式数据集(Resilient Distributed DataSet,RDD),它是逻辑集中的实体,在集群中的多台集群上进行数据分区.通 ...
随机推荐
- leetcode 84. 柱状图中最大的矩形 JAVA
题目: 给定 n 个非负整数,用来表示柱状图中各个柱子的高度.每个柱子彼此相邻,且宽度为 1 . 求在该柱状图中,能够勾勒出来的矩形的最大面积. 以上是柱状图的示例,其中每个柱子的宽度为 1,给定的高 ...
- php中mvc框架总结1(7)
1.代码结构的划分: 目前的目录结构: /站点根目录 /application/应用程序目录 Model/模型目录 View/视图目录 Back/后台 front/ test/测试平台 Control ...
- JavaScript一个页面中有多个audio标签,其中一个播放结束后自动播放下一个,audio连续播放
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- IIS发布好的网页突然不显示图片了
按以下步骤把地址加到ie的本地intranet就好了
- sublime text 显示 typescript高亮
用ionic angular2写东西,还是用我的sublime 发现ts文件不识别,没有高亮.搜呗. 搜索出来的博客地址:http://www.cnblogs.com/happen-/p/638553 ...
- vue + ElementUI 表格筛选框的高度设置,超出一定高度,显示滚动条
相信有很多小伙伴遇到过这个问题,首先还是来看图片,筛选框我做了处理,所以和官网的有点小差别 官方网站和个人网站对比图如下: 代码如下:(F12找到该元素的class,设置高度) .el-table-f ...
- [转] Cisco路由器DNS配置
禁用Web服务 Cisco路由器还在缺省情况下启用了Web服务,它是一个安全风险.如果你不打算使用它,最好将它关闭.举例如下: Router(config)# no ip http server 配置 ...
- python自学之第一章 —— 变量
1.变量的命名(): (1).可以包含数字.字母.下划线‘_’,但只能以字母和下划线‘_’开头,不能以数字开头! (2).变量的命名不能包含空格. (3).不能将python中的关键字(reserve ...
- 网络请求及各类错误代码含义总结(包含AFN错误码大全)
碰见一个很奇葩的问题, 某些手机在设置了不知什么后, 某些 APP 死活 HTTPS 请求失败, 例如以 UMeng 统计HTTP 请求失败为例, Log如下: UMLOG: (Error App ...
- jquery插件制作,下拉菜单
要求输入框点击出现下拉菜单,并实现以下功能: 1.首先点击地点标签页,选择好地点: 2.自动显示相应节点标签页显示节点信息,选择好节点 3.自动显示相应的连接点,选择连接点,连接点被选中并被传送的输入 ...