Paper Reading - Show and Tell: A Neural Image Caption Generator ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1411.4555
Main Points:
- A generative model ( NIC, GoogLeNet + LSTM ) based on a deep recurrent architecture: the model is trained to maximize the likelihoodP(S|I) of the target description sentence given the training image I. S = { S1, S2, ... } is the target sequence of words and each word St comes from a given dictionary, that describes the image adequately.
- The authors use a CNN as an image "encoder", by first pre-training it for an image classification task and using the last hidden layer as an input to the RNN decoder that generates sentences. They call this model the Neural Image Caption, or NIC.
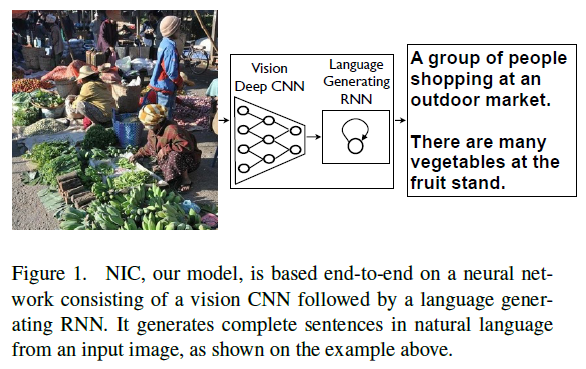
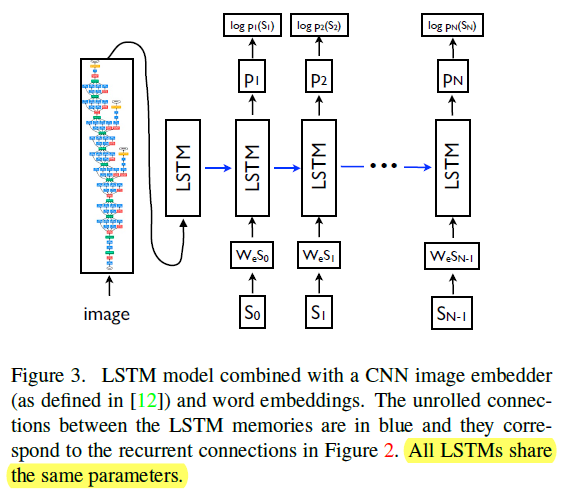
Other Key Points:
- A description must capture not only the objects contained in an image, but it also must express how these objects relate to each other as well as their attributes and the activities they are involved in.
- The inspiration of Image Captioning could come from advances in Machine Translation.
- There are multiple approaches that can be used to generate a sentence given an image, with NIC. The first one is Sampling where the authors just sample the first word according to p1, then provide the corresponding embedding as input and sample p2, continuing like this until we sample the special end-of-sentence token or some maximum length. The second one is Beamsearch: iteratively consider the set of the k best sentences up to time t as candidates to generate sentences of size t+1, and keep only the resulting best k of them. This better approximates S = arg maxS' p(S'|I).
Paper Reading - Show and Tell: A Neural Image Caption Generator ( CVPR 2015 )的更多相关文章
- [Paper Reading] Show and Tell: A Neural Image Caption Generator
论文链接:https://arxiv.org/pdf/1411.4555.pdf 代码链接:https://github.com/karpathy/neuraltalk & https://g ...
- Paper Reading - Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ( ICML 2015 )
Link of the Paper: https://arxiv.org/pdf/1502.03044.pdf Main Points: Encoder-Decoder Framework: Enco ...
- [Paper Reading] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
论文链接:https://arxiv.org/pdf/1502.03044.pdf 代码链接:https://github.com/kelvinxu/arctic-captions & htt ...
- Paper Reading - Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation ( CVPR 2015 )
Link of the Paper: https://ieeexplore.ieee.org/document/7298856/ A Correlative Paper: Learning a Rec ...
- [Paper Reading] Image Captioning using Deep Neural Architectures (arXiv: 1801.05568v1)
Main Contributions: A brief introduction about two different methods (retrieval based method and gen ...
- Paper Reading - Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge
Link of the Paper: https://arxiv.org/abs/1609.06647 A Correlative Paper: Show and Tell: A Neural Ima ...
- 论文:Show and Tell: A Neural Image Caption Generator-阅读总结
Show and Tell: A Neural Image Caption Generator-阅读总结 笔记不能简单的抄写文中的内容,得有自己的思考和理解. 一.基本信息 标题 作者 作者单位 发表 ...
- Paper Reading: Stereo DSO
开篇第一篇就写一个paper reading吧,用markdown+vim写东西切换中英文挺麻烦的,有些就偷懒都用英文写了. Stereo DSO: Large-Scale Direct Sparse ...
- CVPR 2016 paper reading (6)
1. Neuroaesthetics in fashion: modeling the perception of fashionability, Edgar Simo-Serra, Sanja Fi ...
随机推荐
- 客户端对象模型之Excel数据导入到列表
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <t ...
- 小程序发微信红包后端Nodejs实现
前提条件 1.有一个微信开放平台 https://open.weixin.qq.com/ 2.有一个微信公众平台 https://mp.weixin.qq.com 并且开通微信支付 3.有一个微信小 ...
- pl/sql下载
详解Oracle客户端工具:PL/SQL工具下载: 下载地址:http://www.oraclejsq.com/article/010100114.html
- c#网络传输
接着前面简单讲的,给大家聊聊服务开发. 网络传输 先说网络传输开发,总体来说,可以看成4中模型 我们把传输过程看做网线,那么在通过传输的过程中.2边就涉及池化问题,也就是我们常见的异步传输. 在业务端 ...
- 关于javascript中call()和apply()方法的总结
前段时间在使用javascript的过程中遇到了继承的问题,自己顺便就对call()和apply()方法进行了了解. 两个方法的共同之处:这两个方法作用相同,都用来改变当前函数调用的对象,即改变thi ...
- vim插件管理 - vim-plug
vim-plug是一款轻量的vim插件管理工具. GitHub:https://github.com/junegunn/vim-plug 插件的安装 unix curl -fLo ~/.vim/aut ...
- SpringAOP的自定义注解实践
springaop属于spring的重要属性,在java中有相当广泛的用途,大家一般都接触过aop实现事务的管理,在xml里配好声明式事务,然后直接在service上直接加上相应注解即可, 今天我们来 ...
- PHP && ,and ,||,or 的区别
PHP中的逻辑“与”运算有两种形式:AND 和 &&,同样“或”运算也有OR和||两种形式. 如果是单独两个表达式参加的运算,两种形式的结果完全相同,例如 $a AND $b和$a & ...
- 远程查看java虚拟机内存使用情况jconsole
jconsole 查看虚拟机使用情况 1.在远程机的tomcat的catalina.sh中加入配置: JAVA_OPTS="$JAVA_OPTS -Djava.rmi.server.host ...
- 2.Hadoop集群安装进阶
Hadoop进阶 1.配置SSH免密 (1)修改slaves文件 切换到master机器,本节操作全在master进行. 进入/usr/hadoop/etc/hadoop目录下,找到slaves文件, ...