(六)hadoop系列之__hadoop分布式集群环境搭建
配置hadoop(master,slave1,slave2)
说明:
NameNode: master
DataNode: slave1,slave2 --------------------------------------------------------
A. 修改主机的master 和 slaves
i. 配置slaves
# vi hadoop/conf/slaves
添加:192.168.126.20
192.168.126.30
...节点 ip ii. 配置master
添加:192.168.126.10
...主机 ip
-------------------------------------------------------- B. 配置master .xml文件
i. 配置core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/had/hadoop/data</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.126.10:9000</value>
</property>
</configuration> ii. 配置hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
</configuration> iii.mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.126.10:9001</value>
</property>
</configuration> -------------------------------------------------------------
C. 配置slave1,slave2 (同上)
i. core-site.xml
ii. mapred-site.xml
--------------------------------------------------------------- D. 配置 master,slave1,slave2的hadoop系统环境
$ vi /home/hadoop/.bashrc
添加:
export HADOOP_HOME=/home/hadoop/hadoop-0.20.2
export HADOOP_CONF_DIR=$HADOOP_HOME/conf
export PATH=/home/hadoop/hadoop-0.20.2/bin:$PATH
----------------------------------------------------------------

注意:有时候会出现以下错误信息
。。。
11/08/18 17:02:35 INFO ipc.Client: Retrying connect to server: localhost/192.168.126 .10:9000. Already tried 0 time(s).
Bad connection to FS. command aborted.
此时需要把根目录下的tmp文件里面的内容删掉,然后重新格式化即可。
启动Hadoop:

完成后进行测试:
测试 $ bin/hadoop fs -put ./README.txt test1
$ bin/hadoop fs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2013-07-14 00:51 /user/hadoop/test1
$hadoop jar hadoop-0.20.2-examples.jar wordcount /user/hadoop/test1/README.txt output1
结果出现以下问题
注:测试过程当中会有一些错误信息。一下是我在安装的过程当中碰到的几个问题。
1.org.apache.hadoop.ipc.RemoteException: org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot delete /home/hadoop/hadoop-datastore
/hadoop-hadoop/mapred/system/job_201307132331_0005. Name node is in safe mode.
关闭安全模式:
bin/hadoop dfsadmin -safemode leave
2.org.apache.hadoop.ipc.RemoteException: java.io.IOException: File /user/hadoop/test1/README.txt could only be replicated to 0 nodes,
instead of 1
情况1. hadoop.tmp.dir 磁盘空间不足。
解决方法: 换个足够空间的磁盘即可。
情况2. 查看防火墙状态
/etc/init.d/iptables status
/etc/init.d/iptables stop//关闭所有的防火墙
情况3.先后启动namenode、datanode(我的是这种情况)
参考文章:http://sjsky.iteye.com/blog/1124545
最后执行界面如下:
查看hdfs运行状态(web):http://192.168.126.10:50070/dfshealth.jsp

查看map-reduce信息(web):http://192.168.126.10:50030/jobtracker.jsp
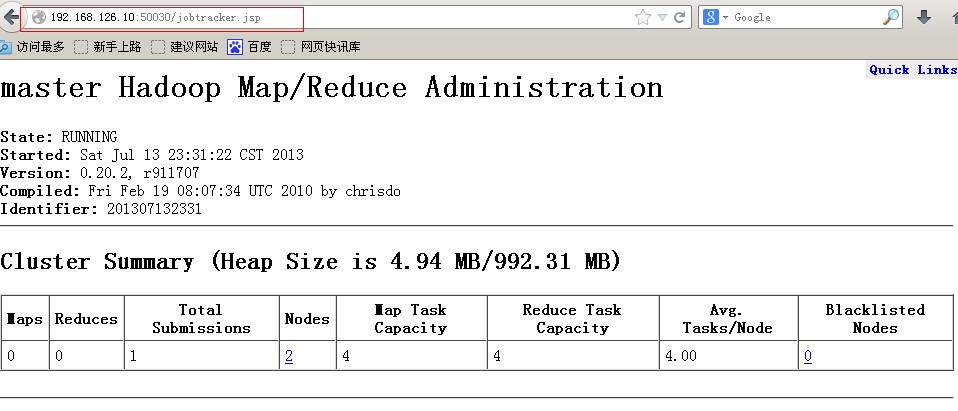
整个Hadoop集群搭建结束。
(六)hadoop系列之__hadoop分布式集群环境搭建的更多相关文章
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- ZooKeeper 完全分布式集群环境搭建
1. 搭建前准备 示例共三台主机,主机IP映射信息如下: 192.168.32.101 s1 192.168.32.102 s2 192.168.32.103 s3 2.下载ZooKeeper, 以 ...
- Kafka 完全分布式集群环境搭建
思路: 先在主机s1上安装配置,然后远程复制到其它两台主机s2.s3上, 并分别修改配置文件server.properties中的broker.id属性. 1. 搭建前准备 示例共三台主机,主机IP映 ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- Hadoop+HBase+ZooKeeper分布式集群环境搭建
一.环境说明 集群环境至少需要3个节点(也就是3台服务器设备):1个Master,2个Slave,节点之间局域网连接,可以相互ping通,下面举例说明,配置节点IP分配如下: Hostname IP ...
- Hadoop学习(一):完全分布式集群环境搭建
1. 设置免密登录 (1) 新建普通用户hadoop:useradd hadoop(2) 在主节点master上生成密钥对,执行命令ssh-keygen -t rsa便会在home文件夹下生成 .ss ...
- Spark 2.2.0 分布式集群环境搭建
集群机器: 1台 装了 ubuntu 14.04的 台式机 1台 装了ubuntu 16.04 的 笔记本 (机器更多时同样适用) 1.需要安装好Hadoop分布式环境 参照:Hadoop分类 ...
随机推荐
- 20155222 2016-2017-2 《Java程序设计》第3周学习总结
20155222 2016-2017-2 <Java程序设计>第3周学习总结 教材学习内容总结 要产生对象必须先定义类,类是对象的设计图,对象是类的实例. 数组一旦建立,长度就固定了. 字 ...
- 20155320 实验二 Java面向对象程序设计
20155320 实验二 Java面向对象程序设计 实验内容 初步掌握单元测试和TDD 理解并掌握面向对象三要素:封装.继承.多态 初步掌握UML建模 熟悉S.O.L.I.D原则 了解设计模式 实验步 ...
- 20155328 2016-2017-2 《Java程序设计》 第十周学习内容总结
20155328 2016-2017-2 <Java程序设计>第十周学习总结 教材学习内容总结 JAVA和ANDROID开发学习指南 第22章 网络概览 两台计算机用于通信的语言叫做&qu ...
- 通过unixODBC访问PostgreSQL数据库
磨砺技术珠矶,践行数据之道,追求卓越价值回到上一级页面:PostgreSQL基础知识与基本操作索引页 回到顶级页面:PostgreSQL索引页[作者 高健@博客园 luckyjackgao@g ...
- 1178: [Apio2009]CONVENTION会议中心
1178: [Apio2009]CONVENTION会议中心 https://lydsy.com/JudgeOnline/problem.php?id=1178 分析: set+倍增. 首先把所有有包 ...
- 【jQuery学习】用JavaScript写一个输出多选框的个数报错:Cannot set property 'onclick' of null"
说明:代码段来源于:<锋利的jQuery> 根据代码段我补充的代码如下: <!DOCTYPE html> <html> <head> <meta ...
- iOS 播放音频文件
// 播放音乐 NSString *path = [[NSBundle mainBundle] pathForResource:@"1670" ofType:@&qu ...
- Elasticsearch.Net 异常:[match] query doesn't support multiple fields, found [field] and [query]
用Elasticsearch.Net检索数据,报异常: )); ElasticLowLevelClient client = new ElasticLowLevelClient(settings); ...
- JavaScript学习笔记(一)——JS速览
第一章 JS速览 1 限制时间处理事件 <script> setTomeout(wakeUpUser,5000); function wakeUpUser() { alert(" ...
- Viper--方便好用的Golang 配置库
前言 本文主要是为读者介绍一个轻便好用的Golang配置库viper 正文 viper 的功能 viper 支持以下功能: 1. 支持Yaml.Json. TOML.HCL 等格式的配置 ...