Redis集群方案应该怎么做
方案1:Redis官方集群方案 Redis Cluster
Redis Cluster是一种服务器sharding分片技术。Redis Cluster集群如何搭建请参考我的另一篇博文:http://www.cnblogs.com/xckk/p/6144447.html
Redis3.0版本开始正式提供,解决了多Redis实例协同服务问题,时间较晚,目前能证明在大规模生产环境下成功的案例还不是很多,需要时间检验。
Redis Cluster中,Sharding采用slot(槽)的概念,一共分成16384个槽。对于每个进入Redis的键值对,根据key进行散列,分配到这16384个slot中的某一个中。使用的hash算法也比较简单,CRC16后16384取模。
Redis Cluster中的每个node负责分摊这16384个slot中的一部分,也就是说,每个slot都对应一个node负责处理。例如三台node组成的cluster,分配的slot分别是0-5460,5461-10922,10923-16383,
M: 434e5ee5cf198626e32d71a4aee27bc4058b4e45 127.0.0.1: slots:- ( slots) master
M: 048a0c9631c87e5ecc97a4ce5834d935f2f938b6 127.0.0.1: slots:- ( slots) master M: 04ae4184b2853afb8122d15b5b2efa471d4ca251 127.0.0.1: slots:- ( slots) master
添加或减少节点时?
当动态添加或减少node节点时,需要将16384个slot重新分配,因此槽中的键值也要迁移。这一过程,目前处于半自动状态,需要人工介入。
节点发生故障时
如果某个node发生故障,那它负责的slots也就失效,整个Redis Cluster将不能工作。因此官方推荐的方案是将node都配置成主从结构,即一个master主节点,挂n个slave从节点。
这非常类似Redis Sharding场景下服务器节点通过Sentinel(哨兵)监控架构主从结构,只是Redis Cluster本身提供了故障转移容错的能力。
通信端口
Redis Cluster的新节点识别能力、故障判断及故障转移能力是通过集群中的每个node和其它的nodes进行通信,这被称为集群总线(cluster bus)。
通信端口号一般是该node端口号加10000。如某node节点端口号是6379,那么它开放的通信端口是16379。nodes之间的通信采用特殊的二进制协议。
对客户端来说,整个cluster被看重是一个整体,客户端可以连接任意一个node进行操作,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node。
如下。在127.0.0.1上部署了三台Redis实例,组成Redis cluster,端口号分别是7000,7001,7002。在端口号为7000的Redis node上设置<foo,hello>,foo对应的key值重定向到端口号为7002的node节点上。get foo命令时,也会重定向到7002上的node节点上去取数据,返回给客户端。
[root@centos1 create-cluster]# redis-cli -c -p 127.0.0.1:> set foo hello -> Redirected to slot [] located at 127.0.0.1: OK 127.0.0.1:> get foo -> Redirected to slot [] located at 127.0.0.1: "hello"
方案2:Redis Sharding集群
Redis Sharding是一种客户端Sharding分片技术。
Redis Sharding可以说是Redis Cluster出来之前,业界普遍使用的多Redis实例集群方法。主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。
这样,客户端就知道该向哪个Redis节点操作数据,需要说明的是,这是在客户端完成的。Sharding架构如图所示:
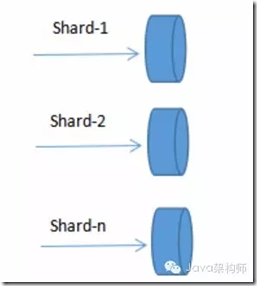
java redis客户端jedis,已支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool。Jedis的Redis Sharding实现具有如下特点:
1、采用一致性哈希算法(consistent hashing)
将key和节点name同时哈希,然后进行映射匹配,采用的算法是MURMUR_HASH。一致性哈希主要原因是当增加或减少节点时,不会产生由于重新匹配造成的rehashing。一致性哈希只影响相邻节点key分配,影响量小。更多一致性哈希算法介绍,可以参考:http://blog.csdn.net/cywosp/article/details/23397179/
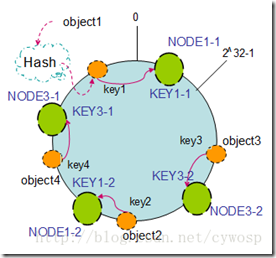
2、虚拟节点
ShardedJedis会对每个Redis节点,根据名字虚拟化出160个虚拟节点进行散列。用虚拟节点做映射匹配,可以在增加或减少Redis节点时,key在各Redis节点移动更分配更均匀,而不是只有相邻节点受影响。如图,Redis节点1虚拟化成NODE1-1和NODE1-2,散列中哈希环上。这样当object1、object2散列时,选取最近节点NODE1-1和NODE1-2,而NODE1-1和NODE1-2又是NODE节点的虚拟节点,即实际存储在NODE节点上。
增加虚拟节点,可以保证平衡性,即每台Redis机器,存储的数据都差不多,而不是一台机器存储的数据较多,其它的少。
3、ShardedJedis支持keyTagPattern模式
抽取key的一部分keyTag做sharding,这样通过合理命名key,可以将一组相关联的key放入同一Redis节点,避免跨节点访问。即客户端将相同规则的key值,指定存储在同一Redis节点上。
添加或减少节点时?
Redis Sharding采用客户端Sharding方式,服务端的Redis还是一个个相对独立的Redis实例节点。同时,我们也不需要增加额外的中间处理组件,这是一种非常轻量、灵活的Redis多实例集群方案。
当然,这种轻量灵活方式必然在集群其它能力方面做出妥协。比如扩容,当想要增加Redis节点时,尽管采用一致性哈希,那么不同的key分布到不同的Redis节点上。
当我们需要扩容时,增加机器到分片列表中。这时候客户端根据key算出来落到跟原来不同的机器上,这样如果要取某一个值,会出现取不到的情况。
对于这一种情况,一般的作法是取不到后,直接从后端数据库重新加载数据,但有些时候,击穿缓存层,直接访问数据库层,会对系统访问造成很大压力。
Redis作者给出了一个办法--presharding。
是一种在线扩容的方法,原理是将每一台物理机上,运行多个不同端口的Redis实例,假如三个物理机,每个物理机运行三个Redis实例,那么我们的分片列表中实际有9个Redis实例,当我们需要扩容时,增加一台物理机,步骤如下:
1、在新的物理机上运行Redis-server
2、该Redis-server从属于(slaveof)分片列表中的某一Redis-Server(假设叫RedisA)。
3、主从复制(Replication)完成后,将客户端分片列表中RedisA的IP和端口改为新物理机上Redis-Server的IP和端口。
4、停止RedisA
这样相当于将某一Redis-Server转移到了一台新机器上。但还是很依赖Redis本身的复制功能,如果主库快照数据文件过大,这个复制的过程也会很久,同时也会给主Redis带来压力,所以做这个拆分的过程最好选择业务访问低峰时段进行。
节点发生故障时
并不是只有增删Redis节点引起键值丢失问题,更大的障碍来自Redis节点突然宕机。
为不影响Redis性能,尽量不开启AOF和RDB文件保存功能,因此需架构Redis主备模式,主Redis宕机,备Redis留有备份,数据不会丢失。
Sharding演变成如下:
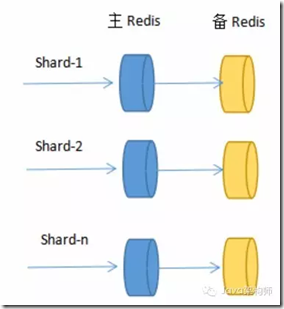
这样,我们的架构模式变成一个Redis节点切片包含一个主Redis和一个备Redis,主备共同组成一个Redis节点,通过自动故障转移,保证了节点的高可用性.
Redis Sentinel哨兵
提供了主备模式下Redis监控、故障转移等功能,达到系统的高可用性。
读写分离
高访问时量下,即使采用Sharding分片,一个单独节点还是承担了很大的访问压力,这时我们还需要进一步分解。
通常情况下,读常常是写的数倍,这时我们可以将读写分离,读提供更多的实例数。利用主从模式实现读写分离,主负责写,从负责只读,同时一主挂多个从。在Redis Sentinel监控下,还可以保障节点故障的自动监测。
方案3:利用代理中间件实现大规模Redis集群
上面分别介绍了基于客户端Sharding的Redis Sharding和基于服务端sharding的Redis Cluster。
客户端Sharding技术
优势:服务端的Redis实例彼此独立,相互无关联,非常容易线性扩展,系统灵活性很强。
不足:1、由于sharding处理放到客户端,规模扩大时给运维带来挑战。
2、服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整。
3、连接不能共享,当应用规模增大时,资源浪费制约优化。
服务端Sharding技术
优势:服务端Redis集群拓扑结构变化时,客户端不需要感知,客户端像使用单Redis服务器一样使用Redis Cluster,运维管理也比较方便。
不足:Redis Cluster正式版推出时间不长,系统稳定性、性能等需要时间检验,尤其中大规模使用场景。
能不能结合二者优势?既能使服务端各实例彼此独立,支持线性可伸缩,同时sharding又能集中处理,方便统一管理?
中间件sharding分片技术
twemproxy就是一种中间件sharding分片的技术,处于客户端和服务器的中间,将客户端发来的请求,进行一定的处理后(如sharding),再转发给后端真正的Redis服务器。
也就是说,客户端不直接访问Redis服务器,而是通过twemproxy代理中间件间接访问。
tweproxy中间件的内部处理是无状态的,起源于twitter,不仅支持redis,同时支持memcached。
使用了中间件,twemproxy可以通过共享与后端系统的连接,降低客户端直接连接后端服务器的连接数量。同时,它也提供sharding功能,支持后端服务器集群水平扩展。统一运维管理也带来了方便。
当然,由于使用了中间件,相比客户端直辖服务器方式,性能上肯定会有损耗,大约降低20%左右。
另一个知名度较高的实现是 Codis,由豌豆荚的团队开发。感兴趣的读者可以搜索相关资料。
总结:几种方案如何选择。
上面大致讲了三种集群方案,主要根据sharding在哪个环节进行区分
1、服务端实现分片
官方的 Redis Cluster 实现就是采用这种方式,在这种方案下,客户端请求到达错误节点后不会被错误节点代理执行,而是被错误节点重定向至正确的节点。
2、客户端实现分片
分区的逻辑在客户端实现,由客户端自己选择请求到哪个节点。方案可参考一致性哈希,基于 Memcached 的 cache 集群一般是这么做,而这种方案通常适用于用户对客户端的行为有完全控制能力的场景。
3、中间件实现分片
有名的例子是 Twitter 的 Twemproxy,Redis 作者对其评价较高。一篇较旧的博客如下:Twemproxy, a Redis proxy from Twitter
另一个知名度较高的实现是 Codis,由豌豆荚的团队开发,作者 @go routine 刘老师已经在前面的答案中推荐过了。
那么,如何选择呢?
显然在客户端做分片是自定义能力最高的。
优势在于,在不需要客户端服务端协作,以及没有中间层的条件下,每个请求的 roundtrip 时间是相对更小的,搭配良好的客户端分片策略,可以让整个集群获得很好的扩展性。
当然劣势也很明显,用户需要自己对付 Redis 节点宕机的情况,需要采用更复杂的策略来做 replica,以及需要保证每个客户端看到的集群“视图”是一致的。
中间件的方案对客户端实现的要求是最低的,客户端只要支持基本的 Redis 通信协议即可,至于扩容、多副本、主从切换等机制客户端都不必操心,因此这种方案也很适合用来做“缓存服务”。
官方推出的协作方案也完整地支持了分片和多副本,相对于各种 proxy,这种方案假设了客户端实现是可以与服务端“协作”的,事实上主流语言的 SDK 都已经支持了。
所以,对于大部分使用场景来说,官方方案和代理方案都够用了,其实没必要太纠结谁更胜一筹,每种方案都有很多靠谱的公司在用。
此文主要参考了以下文章:
https://www.zhihu.com/question/21419897
http://blog.csdn.net/freebird_lb/article/details/7778999
秀才坤坤出品
转载请注明来源http://www.cnblogs.com/xckk/p/6134655.html
Redis集群方案应该怎么做的更多相关文章
- Redis集群方案怎么做?大牛给你介绍五种方案!
Redis集群方案 Redis数据量日益增大,而且使用的公司越来越多,不仅用于做缓存,同时趋向于存储这块,这样必促使集群的发展,各个公司也在收集适合自己的集群方案,目前行业用的比较多的是下面几种集群架 ...
- Redis集群方案怎么做?
转载自:https://www.jianshu.com/p/1ecbd1a88924 Redis集群方案 Redis数据量日益增大,而且使用的公司越来越多,不仅用于做缓存,同时趋向于存储这块,这样必促 ...
- Redis集群方案
Redis集群方案 前段时间搞了搞Redis集群,想用做推荐系统的线上存储,说来挺有趣,这边基础架构不太完善,因此需要我们做推荐系统的自己来搭这个存储环境,就自己折腾了折腾.公司所给机器的单机性能其实 ...
- 大厂们的 redis 集群方案
redis 集群方案主要有两类,一是使用类 codis 的架构,按组划分,实例之间互相独立: 另一套是基于官方的 redis cluster 的方案:下面分别聊聊这两种方案: 类 codis 架构 这 ...
- Redis集群方案收集
说明: 如果不考虑客户端分片去实现集群,那么市面上基本可以说就三种方案最成熟,它们分别如下所示: 系统 贡献者 是否官方Redis实现 编程语言 Twemproxy Twitter 是 C Redis ...
- Redis集群方案(来自网络)
参考: https://www.zhihu.com/question/21419897 http://www.cnblogs.com/haoxinyue/p/redis.html 为什么集群? 通常, ...
- Redis集群方案介绍
由于Redis出众的性能,其在众多的移动互联网企业中得到广泛的应用.Redis在3.0版本前只支持单实例模式,虽然现在的服务器内存可以到100GB.200GB的规模,但是单实例模式限制了Redis没法 ...
- Redis集群方案总结
Redis集群方案总结 Redis集群方案总结Codis其余方案Redis cluster 目前,Redis中目前集群有以下几种方案: 主从复制 哨兵模式 redis cluster 代理 codis ...
- Redis 集群方案介绍
由于Redis出众的性能,其在众多的移动互联网企业中得到广泛的应用.Redis在3.0版本前只支持单实例模式,虽然现在的服务器内存可以到100GB.200GB的规模,但是单实例模式限制了Redis没法 ...
随机推荐
- java基础知识整理:
一, Java中的继承: 1. final关键字(最终的,不可修改的不可变化的,可以修饰类,方法,变量等): 如果final修饰类的话,这个类不可以被继承: 如果修饰方法的话,这个方法不可以被子类覆盖 ...
- C语言预处理运算符
转自C语言预处理运算符 预处理还需要运算符?有没有搞错? ^_^, 没有搞错,预处理是有运算符,而且还不止一个: #(单井号) -- 字符串化运算符. ##(双井号 )-- 连接运算符 #@ ...
- Ubuntu 14.04 开启启动器图标最小化功能
转自Ubuntu 14.04 怎样开启启动器图标最小化功能 前本站报道过 Ubuntu 14.04 终于加入了启动器图标最小化功能,这个功能默认是不开启的,要怎么开启呢? 之前报道的原文阅读:Ubun ...
- unity 引入 ios 第三方sdk
原地址:http://blog.csdn.net/u012085988/article/details/17785023 unity开发中ios应用时,要想成功引入第三方sdk,首先得知道c#与obj ...
- php 获取图片、swf的尺寸大小
PHP获取图片大小函数. getimagesize() 能够得到图片及flash(swf)的大小. 语法 1 list($width, $height, $type, $attr) = getima ...
- thinkphp 调用函数
1,定义为Common.php文件.自动加载. 2,配置文件config.php文件里配置'LOAD_EXT_FILE'=>'function'.则会自动加载function.php文件 3,使 ...
- WCF 绑定(Binding)
绑定包含多个绑定元素 ,它 们描述了所有绑定要求 .可以创建自定义绑定 ,也可以使用下表中的其中一个预定义绑定 : 不同的绑定支持不同的功能.以Ws开头的绑定独立于平台 ,支持 Web服务规范. 以 ...
- WCF大数据量传输解决方案
文章内容列表:1. 场景:2. 解决方案3. WCF契约与服务实现设计静态图4. WCF契约与服务实现设计详细说明6. 服务端启动服务代码:7. 客户端代码8. WCF大数据量传输解决方案源码下载 ...
- LinkedList源码解析
LinkedList是基于链表结构的一种List,在分析LinkedList源码前有必要对链表结构进行说明.1.链表的概念链表是由一系列非连续的节点组成的存储结构,简单分下类的话,链表又分为单向链表和 ...
- Python:变量与字符串
变量 使用dos页面进行命令的输入如下变量,进行打印: 同时,相同两个变量书写在同一行,中间用英文的“;”隔开 python中区分大小写变量 字符串 简单的说,字符串就是双引号,单引号,或者三 ...