Spark RDD概念学习系列之RDD的容错机制(十七)
RDD的容错机制
RDD实现了基于Lineage的容错机制。RDD的转换关系,构成了compute chain,可以把这个compute chain认为是RDD之间演化的Lineage。在部分计算结果丢失时,只需要根据这个Lineage重算即可。
图1中,假如RDD2所在的计算作业先计算的话,那么计算完成后RDD1的结果就会被缓存起来。缓存起来的结果会被后续的计算使用。图中的示意是说RDD1的Partition2缓存丢失。如果现在计算RDD3所在的作业,那么它所依赖的Partition0、1、3和4的缓存都是可以使用的,无须再次计算。但是Partition2由于缓存丢失,需要从头开始计算,Spark会从RDD0的Partition2开始,重新开始计算。
内部实现上,DAG被Spark划分为不同的Stage,Stage之间的依赖关系可以认为就是Lineage。关于DAG的划分可以参阅第4章。
提到Lineage的容错机制,不得不提Tachyon。Tachyon包含两个维度的容错,一个是Tachyon集群的元数据的容错,它采用了类似于HDFS的Name Node的元数据容错机制,即将元数据保存到一个Image文件,并且保存了元数据变化的编辑日志(EditLog)。另外一个是Tachyon保存的数据的容错机制,这个机制类似于RDD的Lineage,Tachyon会保留生成文件数据的Lineage,在数据丢失时会通过这个Lineage来恢复数据。如果是Spark的数据,那么在数据丢失时Tachyon会启动Spark的Job来重算这部分内容。如果是Hadoop产生的数据,那么重新启动相应的Map Reduce Job就可以。现在Tachyon的容错机制的实现还处于开发阶段,并不推荐将这个机制应用于生产环境。不过,这并不影响Spark使用Tachyon。如果Spark保存到Tachyon的部分数据丢失,那么Spark会根据自有的容错机制来重算这部分数据。
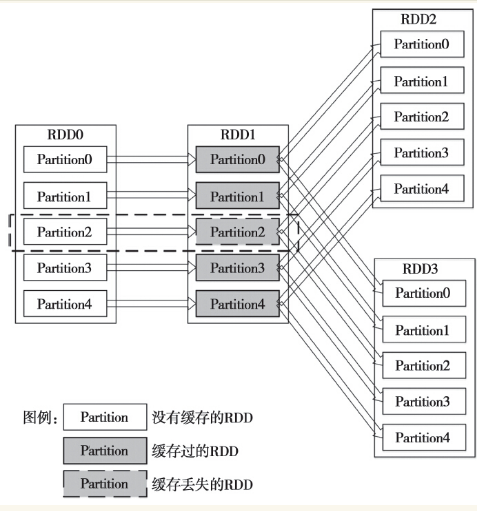
图1 RDD的部分缓存丢失的逻辑图
Spark RDD概念学习系列之RDD的容错机制(十七)的更多相关文章
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD的缺点(二)
RDD的缺点? RDD是Spark最基本也是最根本的数据抽象,它具备像MapReduce等数据流模型的容错性,并且允许开发人员在大型集群上执行基于内存的计算. 为了有效地实现容错,(详细见ht ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的操作(七)
RDD的操作 RDD支持两种操作:转换和动作. 1)转换,即从现有的数据集创建一个新的数据集. 2)动作,即在数据集上进行计算后,返回一个值给Driver程序. 例如,map就是一种转换,它将数据集每 ...
- Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的.详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark RDD概念学习系列之RDD与DSM的异同分析(十三)
RDD是一种分布式的内存抽象,下表列出了RDD与分布式共享内存(Distributed Shared Memory,DSM)的对比. 在DSM系统[1]中,应用可以向全局地址空间的任意位置进行读写操作 ...
随机推荐
- 认识基本的UI资源
什么是UI精灵(Sprite) 在制作UI时,经常将一些零碎的小的UI资源(比如,一个小箭头,一个按钮等)打包成一张大图,然后在使用时,只使用这个大图中的一部分,那么这一块"被切出来&quo ...
- DB天气安卓客户端测试计划
分辨率 屏幕ppi 网络环境 操作系统 os 用户类型 地点 组合总数 其他 samsung htc 小米 ...
- Java OCR tesseract 图像智能字符识别技术 Java实现
Java OCR tesseract 图像智能字符识别技术 Java代码实现 接着上一篇OCR所说的,上一篇给大家介绍了tesseract 在命令行的简单用法,当然了要继承到我们的程序中,还是需要代码 ...
- POJ 2492 A Bug's Life(并查集)
http://poj.org/problem?id=2492 题意 :就是给你n条虫子,m对关系,每一对关系的双方都是异性的,让你找出有没有是同性恋的. 思路 :这个题跟POJ1703其实差不多,也是 ...
- SPRING IN ACTION 第4版笔记-第四章ASPECT-ORIENTED SPRING-007-定义切面的around advice
一.注解@AspectJ形式 1. package com.springinaction.springidol; import org.aspectj.lang.ProceedingJoinPoint ...
- UAC新解(有非正常手段可以绕过)
360第一次注册是需要弹,可是以后就不弹了开机自启动不弹框,开机自启动不弹框 服务是system权限再说一句,一般程序也不需要过UAC系统启动项白名单.UAC有一个白名单机制.还有UAC也可以通过wu ...
- IBM Rational-完整的软件工程解决方案工具集
IBM,即国际商业机器公司,1911年创立于美国,是全球最大的信息技术和业务解决方案公司,其业务遍及全球170多个国家和地区.IBM软件分为五个部分,其中Rational系列是专门针对软件工程的软件工 ...
- 2016年中国500强利润率最高的公司,中国500强最赚钱的40家公司,ROE最高的公司
2016年中国500强利润率最高的公司 排名 公司名称 利润率 62 阿里巴巴集团控股有限公司 73.09% 87 百度股份有限公司 50.71% 195 国信证券股份有限公司 47.87% ...
- centos6.5安装vbox
cd /etc/yum.repos.d wget http://download.virtualbox.org/virtualbox/rpm/rhel/virtualbox.repo 下载跟CENTO ...
- php include include_once require require_once 的区别与联系
一.require 与 include 的区别: The require() function is identical to include(), except that it handles er ...