oracle sql小结(主要讲横列转换的例子)decode 以及case
--建表
create table kecheng
(
id NUMBER,
name VARCHAR2(20),
course VARCHAR2(20),
score NUMBER
);
--插入数据
insert into kecheng (id, name, course, score)
values (1, '张三', '语文', 67);
insert into kecheng (id, name, course, score)
values (1, '张三', '数学', 76);
insert into kecheng (id, name, course, score)
values (1, '张三', '英语', 43);
insert into kecheng (id, name, course, score)
values (1, '张三', '历史', 56);
insert into kecheng (id, name, course, score)
values (1, '张三', '化学', 11);
insert into kecheng (id, name, course, score)
values (2, '李四', '语文', 54);
insert into kecheng (id, name, course, score)
values (2, '李四', '数学', 81);
insert into kecheng (id, name, course, score)
values (2, '李四', '英语', 64);
insert into kecheng (id, name, course, score)
values (2, '李四', '历史', 93);
insert into kecheng (id, name, course, score)
values (2, '李四', '化学', 27);
insert into kecheng (id, name, course, score)
values (3, '王五', '语文', 24);
insert into kecheng (id, name, course, score)
values (3, '王五', '数学', 25);
insert into kecheng (id, name, course, score)
values (3, '王五', '英语', 8);
insert into kecheng (id, name, course, score)
values (3, '王五', '历史', 45);
insert into kecheng (id, name, course, score)
values (3, '王五', '化学', 1);
commit;
select * from KECHENG t;
--2.1、Decode方式
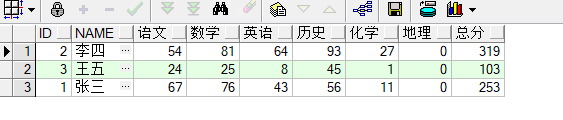
SELECT ID,NAME,
SUM(DECODE(course,'语文',score,0)) 语文,
SUM(DECODE(course,'数学',score,0)) 数学,
SUM(DECODE(course,'英语',score,0)) 英语,
SUM(DECODE(course,'历史',score,0)) 历史,
SUM(DECODE(course,'化学',score,0)) 化学,
sum(decode(course,'地理',score,0)) 地理,
sum(score) 总分
FROM kecheng
GROUP BY ID ,NAME
--2.2、Case方式
--这里使用max也可以,但是使用min和avg就不行了
SELECT ID,NAME,
MAX(CASE WHEN course='语文' THEN score ELSE 0 END) 语文,
MAX(CASE WHEN course='数学' THEN score ELSE 0 END) 数学,
MAX(CASE WHEN course='英语' THEN score ELSE 0 END) 英语,
MAX(CASE WHEN course='历史' THEN score ELSE 0 END) 历史,
MAX(CASE WHEN course='化学' THEN score ELSE 0 END) 化学,
max(case when course='' then score else 0 end ) 无课 ,
sum(score) 总分
FROM kecheng
GROUP BY ID ,NAME

--结果与上方一样
--2.3、wmsys.wm_concat行列转换函数(该函数只能在group by语句里)
SELECT ID,NAME,
wmsys.wm_concat(course || ':'||score) course
FROM kecheng
GROUP BY ID ,NAME;

--2.4、使用over(partition by t.u_id)用法
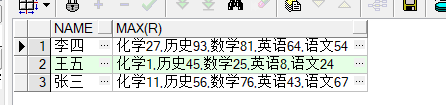
SELECT NAME, max(r) from (
SELECT name,wmsys.wm_concat(course ||score) OVER (PARTITION BY NAME order by course) r
FROM kecheng
) group by name
---三、动态转换
DECLARE
--存放最终的SQL
LV_SQL VARCHAR2(3000);
--存放连接的SQL
SQL_COMMOND VARCHAR2(3000);
--定义游标
CURSOR CUR IS
SELECT COURSE FROM KECHENG GROUP BY COURSE;
BEGIN
--定义查询开头
SQL_COMMOND := 'SELECT NAME ';
FOR I IN CUR LOOP
--将结果相连接
SQL_COMMOND := SQL_COMMOND || ' ,SUM(DECODE(course,''' || I.COURSE ||
''',score,0)) ' || I.COURSE;
DBMS_OUTPUT.PUT_LINE(SQL_COMMOND);
END LOOP;
SQL_COMMOND := SQL_COMMOND || ' from KECHENG group by name';
--LV_SQL := 'INSERT INTO temp_ss ' || SQL_COMMOND;
--DBMS_OUTPUT.PUT_LINE(LV_SQL);
-- EXECUTE IMMEDIATE LV_SQL;
END;

oracle sql小结(主要讲横列转换的例子)decode 以及case的更多相关文章
- oracle sql小结(主要讲横列转换的例子)group by以及wmsys.wm_concat()的使用
---计算九月每个电厂的数量select f_dcname,count(f_dcname) as 九月份的数量 from W_EC_PLACESTATION_COLLECT twhere f_coll ...
- Oracle sql 查询结果某一列字段合并成为一条数据
使用oracle中自带函数 wmsys.wm_concat(需合并列的字段名) 用法如下: select code,name,wmsys.wm_concat(baname) from tab gro ...
- SQL Server SQL性能优化之--pivot行列转换减少扫描计数优化查询语句
原文出处:http://www.cnblogs.com/wy123/p/5933734.html 先看常用的一种表结构设计方式: 那么可能会遇到一种典型的查询方式,主子表关联,查询子表中的某些(或者全 ...
- Oracle sql语句中不支持boolean类型(decode&case)
[转自] http://blog.csdn.net/t0nsha/article/details/7828538 Oracle sql语句中不支持boolean类型(decode&case) ...
- SQL入门(2): Oracle内置函数-字符/数值/日期/转换/NVL/分析函数与窗口函数/case_decode
本文介绍Oracle 的内置函数. 常用! 一. 字符函数 ASCII 码与字符的转化函数 chr(n) 例如 select chr(65) || chr(66) || chr(67) , ch ...
- (转载)SQL语句,纵列转横列
SQL语句,纵列转横列 Feed: 大富翁笔记 Title: SQL语句,纵列转横列 Author: wzmbox Comments sTable.db库位 货物编号 库存数1 0101 501 01 ...
- Oracle sql 中的字符(串)替换与转换[转载]
1.REPLACE 语法:REPLACE(char, search_string,replacement_string) 用法:将char中的字符串search_string全部转换为字符串repla ...
- fixed Oracle SQL报错 #ORA-01460: 转换请求无法实施或不合理
最近遇到一个oracle错误,之前并没有遇到过,并不是select in超过1000个导致的,通过网上资料说是oracle版本导致,也有的说是oracle SQL过长导致. 然后通过自己实践应该说是o ...
- 【总结】Oracle sql 中的字符(串)替换与转换
1.REPLACE 语法:REPLACE(char, search_string,replacement_string) 用法:将char中的字符串search_string全部转换为字符串repla ...
随机推荐
- 调用百度云Api实现从百度云盘自动下载文件
一.注册账号 要从百度云下载文件,首先,注册一个百度云账号,现在可能都要注册手机号啦,当然,如果你已经注册过,很幸运,就可以省略掉此步骤啦. 如图登录后所示: 点击Access Key,即显示上面的图 ...
- python3之文件操作
一 打开文件 根目录在d盘的文件名为‘学习资料.txt’的文件 a)绝对路径(最开始的,根目录文件)例: e:\学习资料.txt 相对路径 直接用文件名字 b)操作方式 只读 只 ...
- zouxy09-图像卷积与滤波的一些知识点
原文地址 图像卷积与滤波的一些知识点 zouxy09@qq.com http://blog.csdn.net/zouxy09 之前在学习CNN的时候,有对卷积进行一些学习和整理,后来就烂尾了,现在稍微 ...
- 三剑客之grep
简介 grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它 ...
- Linux上强制踢出其他正在登录的用户
一.查看当前在线用户有几个 w命令 [root@pa1 nginx]#w 13:36:00 up 79 days, 23:50, 3 users, load average: 0.10, 0.07, ...
- centos linux7的一些操作
进入centos7的一些界面后,按ctrl+alt+F2,则可进入全shell界面,不过要登录root的密码: 从全shell转为gnome 界面窗口,按alt+F1: *************** ...
- WIN7/XP用注册表关联指定后缀名和打开程序(手动【图文】和C编程两种实现)
前言: 本文是基本原理介绍和手动的操作.程序实现该功能在http://blog.csdn.net/arvon2012/article/details/7839556,同时里面有完整代码的下载. 今天在 ...
- Processing-基础小坑-
x 坑A:) 新建一个"Walker"项目,Walker.pde,必须在Walker文件夹下... 刚开始以为如果一个文件需要引用另外一个文件中的类,只要把这两个文件放一个文件夹下 ...
- POJ 1655 - Balancing Act - [DFS][树的重心]
链接:http://poj.org/problem?id=1655 Time Limit: 1000MS Memory Limit: 65536K Description Consider a tre ...
- [No0000B6]C#中 ==与equals的区别
using System; internal class Person { public Person(string name) { Name = name; } public string Name ...