【转载】 强化学习(三)用动态规划(DP)求解
原文地址:
https://www.cnblogs.com/pinard/p/9463815.html
-----------------------------------------------------------------------------------------------
在强化学习(二)马尔科夫决策过程(MDP)中,我们讨论了用马尔科夫假设来简化强化学习模型的复杂度,这一篇我们在马尔科夫假设和贝尔曼方程的基础上讨论使用动态规划(Dynamic Programming, DP)来求解强化学习的问题。
动态规划这一篇对应Sutton书的第四章和UCL强化学习课程的第三讲。
1. 动态规划和强化学习问题的联系
对于动态规划,相信大家都很熟悉,很多使用算法的地方都会用到。就算是机器学习相关的算法,使用动态规划的也很多,比如之前讲到的隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率,隐马尔科夫模型HMM(四)维特比算法解码隐藏状态序列, 都是动态规划的典型例子。
动态规划的关键点有两个:一是问题的最优解可以由若干小问题的最优解构成,即通过寻找子问题的最优解来得到问题的最优解。第二是可以找到子问题状态之间的递推关系,通过较小的子问题状态递推出较大的子问题的状态。而强化学习的问题恰好是满足这两个条件的。
我们先看看强化学习的两个基本问题。

那么如何找到动态规划和强化学习这两个问题的关系呢?
回忆一下上一篇强化学习(二)马尔科夫决策过程(MDP)中状态价值函数的贝尔曼方程:

从这个式子我们可以看出,我们可以定义出子问题求解每个状态的状态价值函数,同时这个式子又是一个递推的式子, 意味着利用它,我们可以使用上一个迭代周期内的状态价值来计算更新当前迭代周期某状态ssSSS的状态价值。可见,使用动态规划来求解强化学习问题是比较自然的。
2. 策略评估求解预测问题
首先,我们来看如何使用动态规划来求解强化学习的预测问题,即求解给定策略的状态价值函数的问题。这个问题的求解过程我们通常叫做策略评估(Policy Evaluation)。
策略评估的基本思路是从任意一个状态价值函数开始,依据给定的策略,结合贝尔曼期望方程、状态转移概率和奖励同步迭代更新状态价值函数,直至其收敛,得到该策略下最终的状态价值函数。

下面我们用一个具体的例子来说明策略评估的过程。
3. 策略评估求解实例

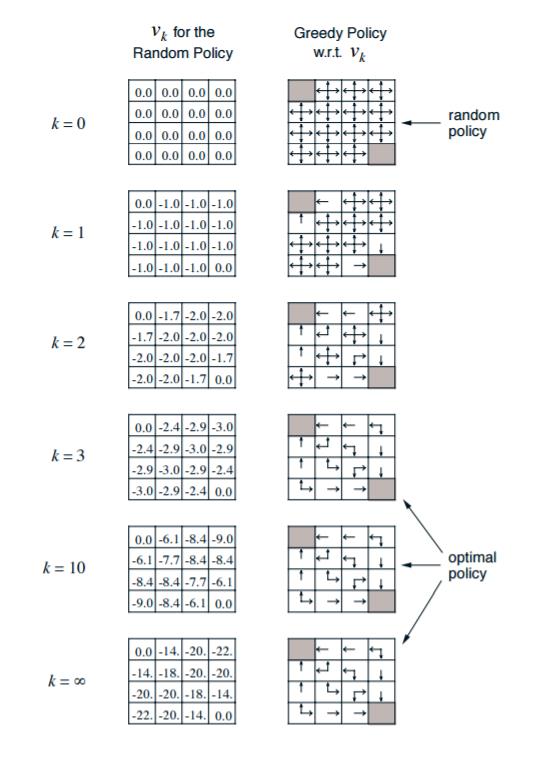

可以看到,动态规划的策略评估计算过程并不复杂,但是如果我们的问题是一个非常复杂的模型的话,这个计算量还是非常大的。
4. 策略迭代求解控制问题
上面我们将了使用策略评估求解控制问题,现在我们再来看如何使用动态规划求解强化学习的第二个问题控制问题。一种可行的方法就是根据我们之前基于任意一个给定策略评估得到的状态价值来及时调整我们的动作策略,这个方法我们叫做策略迭代(Policy Iteration)。
如何调整呢?最简单的方法就是贪婪法。考虑一种如下的贪婪策略:个体在某个状态下选择的行为是其能够到达后续所有可能的状态中状态价值最大的那个状态。还是以第三节的例子为例,如上面的图右边。当我们计算出最终的状态价值后,我们发现,第二行第一个格子周围的价值分别是0,-18,-20,此时我们用贪婪法,则我们调整行动策略为向状态价值为0的方向移动,而不是随机移动。也就是图中箭头向上。而此时第二行第二个格子周围的价值分别是-14,-14,-20, -20。那么我们整行动策略为向状态价值为-14的方向移动,也就是图中的向左向上。
如果用一副图来表示策略迭代的过程的话,如下图:
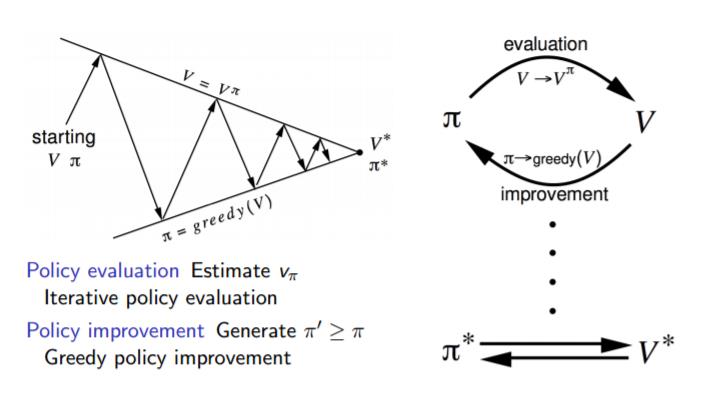

5. 价值迭代求解控制问题

和上一节相比,我们没有等到状态价值收敛才调整策略,而是随着状态价值的迭代及时调整策略, 这样可以大大减少迭代次数。此时我们的状态价值的更新方法也和策略迭代不同。现在的贝尔曼方程迭代式子如下:

可见由于策略调整,我们现在价值每次更新倾向于贪婪法选择的最优策略对应的后续状态价值,这样收敛更快。
6. 异步动态规划算法
在前几节我们讲的都是同步动态规划算法,即每轮迭代我会计算出所有的状态价值并保存起来,在下一轮中,我们使用这些保存起来的状态价值来计算新一轮的状态价值。
另一种动态规划求解是异步动态规划算法,在这些算法里,每一次迭代并不对所有状态的价值进行更新,而是依据一定的原则有选择性的更新部分状态的价值,这类算法有自己的一些独特优势,当然有额会有一些额外的代价。
常见的异步动态规划算法有三种:
第一种是原位动态规划 (in-place dynamic programming), 此时我们不会另外保存一份上一轮计算出的状态价值。而是即时计算即时更新。这样可以减少保存的状态价值的数量,节约内存。代价是收敛速度可能稍慢。
第二种是优先级动态规划 (prioritised sweeping):该算法对每一个状态进行优先级分级,优先级越高的状态其状态价值优先得到更新。通常使用贝尔曼误差来评估状态的优先级,贝尔曼误差即新状态价值与前次计算得到的状态价值差的绝对值。这样可以加快收敛速度,代价是需要维护一个优先级队列。
第三种是实时动态规划 (real-time dynamic programming):实时动态规划直接使用个体与环境交互产生的实际经历来更新状态价值,对于那些个体实际经历过的状态进行价值更新。这样个体经常访问过的状态将得到较高频次的价值更新,而与个体关系不密切、个体较少访问到的状态其价值得到更新的机会就较少。收敛速度可能稍慢。
7. 动态规划求解强化学习问题小结
动态规划是我们讲到的第一个系统求解强化学习预测和控制问题的方法。它的算法思路比较简单,主要就是利用贝尔曼方程来迭代更新状态价值,用贪婪法之类的方法迭代更新最优策略。
动态规划算法使用全宽度(full-width)的回溯机制来进行状态价值的更新,也就是说,无论是同步还是异步动态规划,在每一次回溯更新某一个状态的价值时,都要回溯到该状态的所有可能的后续状态,并利用贝尔曼方程更新该状态的价值。这种全宽度的价值更新方式对于状态数较少的强化学习问题还是比较有效的,但是当问题规模很大的时候,动态规划算法将会因贝尔曼维度灾难而无法使用。因此我们还需要寻找其他的针对复杂问题的强化学习问题求解方法。
下一篇我们讨论用蒙特卡罗方法来求解强化学习预测和控制问题的方法。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
-------------------------------------------------------------------------------------------------------------
【转载】 强化学习(三)用动态规划(DP)求解的更多相关文章
- David Silver强化学习Lecture3:动态规划
课件:Lecture 3: Planning by Dynamic Programming 视频:David Silver强化学习第3课 - 动态规划(中文字幕) 动态规划 动态(Dynamic): ...
- 强化学习三:Dynamic Programming
1,Introduction 1.1 What is Dynamic Programming? Dynamic:某个问题是由序列化状态组成,状态step-by-step的改变,从而可以step-by- ...
- 【转载】 强化学习(四)用蒙特卡罗法(MC)求解
原文地址: https://www.cnblogs.com/pinard/p/9492980.html ------------------------------------------------ ...
- 强化学习(四)用蒙特卡罗法(MC)求解
在强化学习(三)用动态规划(DP)求解中,我们讨论了用动态规划来求解强化学习预测问题和控制问题的方法.但是由于动态规划法需要在每一次回溯更新某一个状态的价值时,回溯到该状态的所有可能的后续状态.导致对 ...
- 强化学习 3—— 使用蒙特卡洛采样法(MC)解决无模型预测与控制问题
一.问题引入 回顾上篇强化学习 2 -- 用动态规划求解 MDP我们使用策略迭代和价值迭代来求解MDP问题 1.策略迭代过程: 1.评估价值 (Evaluate) \[v_{i}(s) = \sum_ ...
- 【转】强化学习(一)Deep Q-Network
原文地址:https://www.hhyz.me/2018/08/05/2018-08-05-RL/ 1. 前言 虽然将深度学习和增强学习结合的想法在几年前就有人尝试,但真正成功的开端就是DeepMi ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 强化学习(三)用动态规划(DP)求解
在强化学习(二)马尔科夫决策过程(MDP)中,我们讨论了用马尔科夫假设来简化强化学习模型的复杂度,这一篇我们在马尔科夫假设和贝尔曼方程的基础上讨论使用动态规划(Dynamic Programming, ...
- 【转载】 强化学习(五)用时序差分法(TD)求解
原文地址: https://www.cnblogs.com/pinard/p/9529828.html ------------------------------------------------ ...
随机推荐
- ActiveMQ 到底是推还是拉?
http://activemq.apache.org/destination-options.html 1. consumer 的配置参数如下图: 配置consumer的示例: public void ...
- TLS 改变密码标准协议(Change Cipher Spec Protocol) 就是加密传输中每隔一段时间必须改变其加解密参数的协议
SSL修改密文协议的设计目的是为了保障SSL传输过程的安全性,因为SSL协议要求客户端或服务器端每隔一段时间必须改变其加解密参数.当某一方要改变其加解密参数时,就发送一个简单的消息通知对方下一个要传送 ...
- 安天透过北美DDoS事件解读IoT设备安全——Mirai的主要感染对象是linux物联网设备,包括:路由器、网络摄像头、DVR设备,入侵主要通过telnet端口进行流行密码档暴力破解,或默认密码登陆,下载DDoS功能的bot,运行控制物联网设备
安天透过北美DDoS事件解读IoT设备安全 安天安全研究与应急处理中心(安天CERT)在北京时间10月22日下午启动高等级分析流程,针对美国东海岸DNS服务商Dyn遭遇DDoS攻击事件进行了跟进分析. ...
- Qt Widgets——工具栏和状态栏
本文主要涉及QSizeGrip ,QStatusBar ,QToolBar QToolBar 工具栏默认位于菜单栏下方,其上添加一个个action按钮,用于执行动作 绝大多谢以前都涉及过,只列出 QT ...
- shiro过滤器解释类
anon -- org.apache.shiro.web.filter.authc.AnonymousFilter authc -- org.apache.shiro.web.filter.authc ...
- js中如何返回一个存放对象的数组?
我这边需要返回后台数据的形式是这样的 {[ { ", }, { ", }, { ", }, { ", }, { ", } ]} 页面是通过循环去获取每 ...
- install the Mondo Rescue utility in Ubuntu 12.04 or 12.10.
1. Open a terminal window. 2. Type in the following commands, then hit Enter after each. wget ft ...
- 转【面向代码】学习 Deep Learning(二)Deep Belief Nets(DBNs)
[面向代码]学习 Deep Learning(二)Deep Belief Nets(DBNs) http://blog.csdn.net/dark_scope/article/details/9447 ...
- Android 音视频深入 四 录视频MP4(附源码下载)
本篇项目地址,名字是<录音视频(有的播放器不能放,而且没有时长显示)>,求star https://github.com/979451341/Audio-and-video-learnin ...
- nginx:负载均衡实战(一)
1.负载均衡说明 2.准备 我自己在电脑布置了两台虚拟机,两台都有nginx和tomcat,两台虚拟机布置的ip分别是37以及54,我在tomcat的首页动了点手脚,方便自己看是来自哪个ip的 接着在 ...