B+树,B树,聚集索引,非聚集索引
简介:
B+树中只有叶子节点会带有指向记录的指针,而B树则所有节点都带有
B+树索引可以分为聚集索引和非聚集索引
mysql使用B+树,其中Myisam是非聚集索引,innoDB是聚集索引
聚簇索引索引的叶节点就是数据节点;而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
B树:

B+树:

B+ 树的特点:
(1)所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
(2)不可能在非叶子结点命中;
(3)非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;

如图所示,区别有以下两点:
结构上
- B+树中只有叶子节点会带有指向记录的指针,而B树则所有节点都带有,在内部节点出现的索引项不会再出现在叶子节点中。
- B+树中所有叶子节点都是通过指针连接在一起,而B树不会。
性能上(也即为什么说B+树比B树更适合实际应用中操作系统的文件索引和数据库索引?)
- 不同于B树只适合随机检索,B+树同时支持随机检索和顺序检索;
- B+树的磁盘读写代价更低。B+树的内部结点并没有指向关键字具体信息的指针,其内部结点比B树小,盘块能容纳的结点中关键字数量更多,一次性读入内存中可以查找的关键字也就越多,相对的,IO读写次数也就降低了。而IO读写次数是影响索引检索效率的最大因素。
- B+树的查询效率更加稳定。B树搜索有可能会在非叶子结点结束,越靠近根节点的记录查找时间越短,只要找到关键字即可确定记录的存在,其性能等价于在关键字全集内做一次二分查找。而在B+树中,顺序检索比较明显,随机检索时,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的查找路径长度相同,导致每一个关键字的查询效率相当。
- (数据库索引采用B+树的主要原因是,)B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。B+树的叶子节点使用指针顺序连接在一起,只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
为什么使用B+树原因:相对于B树,
(1)B+树空间利用率更高,可减少I/O次数,
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗。而因为B+树的内部节点只是作为索引使用,而不像B-树那样每个节点都需要存储硬盘指针。
也就是说:B+树中每个非叶节点没有指向某个关键字具体信息的指针,所以每一个节点可以存放更多的关键字数量,即一次性读入内存所需要查找的关键字也就越多,减少了I/O操作。
e.g.假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内 部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就 是 盘片旋转的时间)。
(2)增删文件(节点)时,效率更高,
因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
(3)B+树的查询效率更加稳定,
因为B+树的每次查询过程中,都需要遍历从根节点到叶子节点的某条路径。所有关键字的查询路径长度相同,导致每一次查询的效率相当。
为什么使用B-Tree(B+Tree)
二叉查找树进化品种的红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。为什么使用B-/+Tree,还跟磁盘存取原理有关。
局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
我们上面分析B-/+Tree检索一次最多需要访问节点:
h =
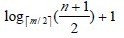
数据库系统巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-
Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logmN)。一般实际应用中,m是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
综上所述,用B-Tree作为索引结构效率是非常高的。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
聚集索引,非聚集索引
根本区别
聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致。
聚集索引
聚集索引表记录的排列顺序和索引的排列顺序一致,所以查询效率快,只要找到第一个索引值记录,其余就连续性的记录在物理也一样连续存放。聚集索引对应的缺点就是修改慢,因为为了保证表中记录的物理和索引顺序一致,在记录插入的时候,会对数据页重新排序。
非聚集索引
非聚集索引制定了表中记录的逻辑顺序,但是记录的物理和索引不一定一致,两种索引都采用B+树结构,非聚集索引的叶子层并不和实际数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针方式。非聚集索引层次多,不会造成数据重排。
例子对比两种索引
聚集索引就类似新华字典中的拼音排序索引,都是按顺序进行,例如找到字典中的“爱”,就里面顺序执行找到“癌”。而非聚集索引则类似于笔画排序,索引顺序和物理顺序并不是按顺序存放的。
mysql使用B+树,其中Myisam是非聚集索引,innoDB是聚集索引
1. MyISAM索引实现:
1)主键索引:
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM主键索引的原理图:
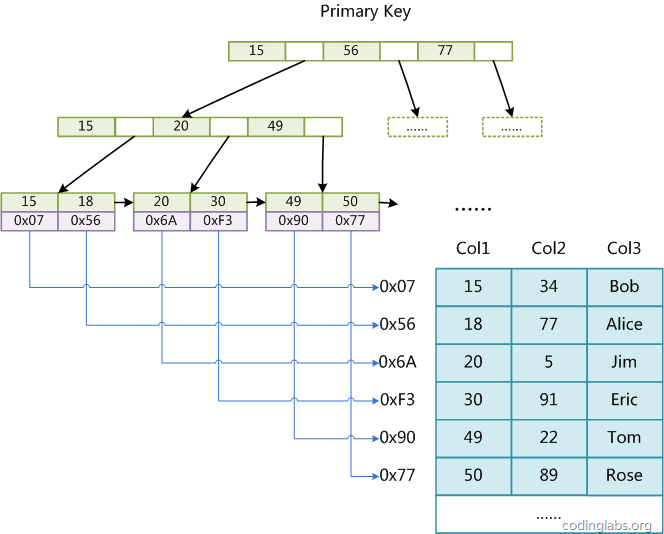
(图myisam1)
这里设表一共有三列,假设我们以Col1为主键,图myisam1是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。
2)辅助索引(Secondary key)
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
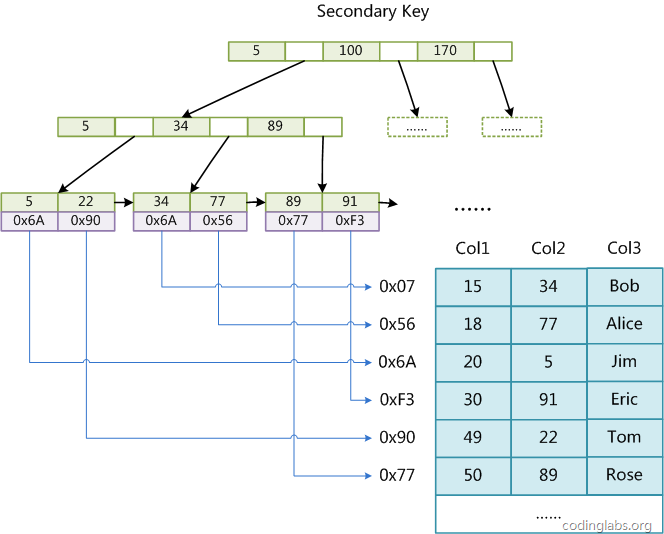
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
2. InnoDB索引实现
然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同.
1)主键索引:
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
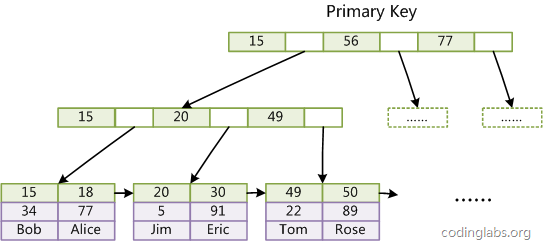
(图inndb主键索引)
(图inndb主键索引)是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
2). InnoDB的辅助索引
InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
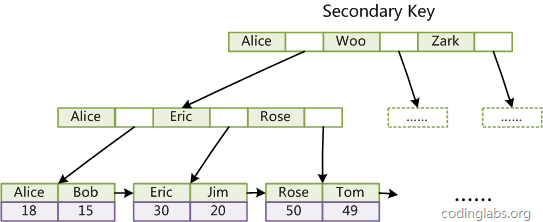
InnoDB 表是基于聚簇索引建立的。因此InnoDB
的索引能提供一种非常快速的主键查找性能。不过,它的辅助索引(Secondary Index, 也就是非主键索引)也会包含主键列,所以,如果主键定义的比较大,其他索引也将很大。如果想在表上定义 、很多索引,则争取尽量把主键定义得小一些。InnoDB 不会压缩索引。
文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
InnoDB索引和MyISAM索引的区别:
一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别。
https://blog.csdn.net/mine_song/article/details/63251546?utm_source=copy
https://blog.csdn.net/jiadajing267/article/details/54581262?utm_source=copy
B+树,B树,聚集索引,非聚集索引的更多相关文章
- 数据库索引--------B/B+树、聚集、非聚集、符合索引
摘录自博客:http://www.cnblogs.com/morvenhuang/archive/2009/03/30/1425534.html 一.引言 对数据库索引的关注从未淡出我的们的讨论,那么 ...
- Mysql 索引实现原理. 聚集索引, 非聚集索引
Mysql索引实现: B-tree,B是balance,一般用于数据库的索引.使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度.而B+tree是B-tree的一个变种,My ...
- MYSQL的全表扫描,主键索引(聚集索引、第一索引),非主键索引(非聚集索引、第二索引),覆盖索引四种不同查询的分析
文章出处:http://inter12.iteye.com/blog/1430144 MYSQL的全表扫描,主键索引(聚集索引.第一索引),非主键索引(非聚集索引.第二索引),覆盖索引四种不同查询的分 ...
- SQL SERVER 聚集索引 非聚集索引 区别
转自http://blog.csdn.net/single_wolf_wolf/article/details/52915862 一.理解索引的结构 索引在数据库中的作用类似于目录在书籍中的作用,用来 ...
- 温故知新-Mysql索引结构&页&聚集索引&非聚集索
文章目录 摘要 索引 索引概述 索引优势劣势 索引结构 BTREE 结构 B+TREE 结构 页 索引分类 索引语法 索引设计原则 聚触索引 & 非聚触索引 你的鼓励也是我创作的动力 Post ...
- SQL Server索引 - 非聚集索引 <第七篇>
一.非聚集索引维护 非聚集索引的行定位器值保持相同的聚集索引值,即使该聚集索引列物理上重新定位后,也是如此. 为了优化这个维护开销,SQL Server添加一个指向旧数据页的指针,以在页面分割之后指向 ...
- oracle索引原理(b-tree,bitmap,聚集,非聚集索引)
B-TREE索引 一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点. 可以用下图一来描述B树索引的结构.其中,B表示分支节点,而L表示叶子节点. 对于分支节点块(包括根节点块)来说,其所 ...
- mysql 聚集和非聚集索引 解析
一.聚集索引(聚簇索引) 1. 什么是聚集索引? 比如要查找'hello',则直接找内容为hello的行,我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”. 聚集索引的叶子节点 ...
- sqlserver 聚集索引 非聚集索引
聚集索引是一种对磁盘上实际数据重新组织以按指定的一列或者多列值排序.像我们用到的汉语字典,就是一个聚集索引.换句话说就是聚集索引会改变数据库表中数据的存放顺序.非聚集索引不会重新组织表中的数据,而是对 ...
- mysql 区间锁 对于没有索引 非唯一索引 唯一索引 各种情况
The locks are normally next-key locks that also block inserts into the "gap" immediately b ...
随机推荐
- windows下net命令失败
D:\apache-tomcat-7.0.57\bin>net start mysql57发生系统错误 5. 拒绝访问. 以管理员身份运行 run as administrator 打开cmd. ...
- static方法
http://www.cnblogs.com/dolphin0520/p/3799052.html 方便在没有创建对象的情况下来进行调用(方法/变量). 虽然在静态方法中不能访问非静态成员方法和非静态 ...
- ubuntu美化 mac风格
安装tweak sudo apt install gnome-tweak-tool sudo apt install chrome-gnome-shell https://extensions.gno ...
- shell 学习笔记二
一.break命令 break命令允许跳出所有循环(终止执行后面的所有循环). 下面的例子中,脚本进入死循环直至用户输入数字大于5.要跳出这个循环,返回到shell提示符下,就要使用break命令. ...
- js條件結構和循環結構
條件結構: if(語句1) if(語句1)else(語句2) if(語句1)elseif(語句2)else(語句3) switch結構: switch() { case 1: break: case ...
- Java之Date Time API (Java 8 新特性)
Java 8 – Date Time API Java 8 comes with a much improved and much required change in the way date an ...
- 在Python中调用C++模块
一.一般调用流程 http://www.cnblogs.com/huangshujia/p/4394276.html 二.Python读取图像并传入C++函数,再从C++返回结果图像给Python h ...
- BZOJ4408&4299[Fjoi 2016]神秘数——主席树
题目描述 一个可重复数字集合S的神秘数定义为最小的不能被S的子集的和表示的正整数.例如S={1,1,1,4,13},1 = 1 2 = 1+1 3 = 1+1+1 4 = 4 5 = 4+1 6 = ...
- BZOJ2159 Crash的文明世界(树形dp+斯特林数)
根据组合意义,有nk=ΣC(n,i)*i!*S(k,i) (i=0~k),即将k个有标号球放进n个有标号盒子的方案数=在n个盒子中选i个将k个有标号球放入并且每个盒子至少有一个球. 回到本题,可以令f ...
- jenkins和sonar的几个问题
错误1:有个pom文件内容错了,但是在jenkins上面编译的时候,控制台将这个错误信息给打出来了,maven的编译也打印了failed with error,但是jenkins的job并没有因此而停 ...