tessaract ocr简介
Tesseract的历史
Tesseract是一个开源的OCR引擎,惠普公司的布里斯托尔实验室在1984-1994年开发完成。起初作为惠普的平板扫描仪的文字识别引擎。Tesseract在1995年UNLV OCR字符识别准确性测试中拔得头筹,受到广泛关注。后来HP放弃了OCR市场。在1994年以后,Tesseract的开发就停止了。
在2005年,HP将Tesseract贡献给开源社区。美国内华达州信息技术研究所获得该源码,同时,Google开始对Tesseract进行功能扩展及优化。目前,Tesseract作为开源项目发布在Google Project上,重获新生。Tesseract的最新版本是3.02,它支持60种以上的语言,提供一个引擎和一个命令行工具,官方下载地址:谷震平的传送门。
Tesseract架构解析
Tesseract引擎功能强大,概括地可以分为两部分:
图片布局分析
字符分割和识别
图片布局分析,是字符识别的准备工作。工作内容:通过一种混合的基于制表位检测的页面布局分析方法,将图像的表格、文本、图片等内容进行区分。
字符分割和识别是整个Tesseract的设计目标,工作内容最为复杂。首先是字符切割,Tesseract采用两步走战略:
利用字符间的间隔进行粗略的切分,得到大部分的字符,同时也有粘连字符或者错误切分的字符。这里会进行第一次字符识别,通过字符区域类型判定,根据判定结果对比字符库识别字符。
根据识别出来的字符,进行粘连字符的分割,同时把错误分割的字符合并,完成字符的精细切分。
当然,还有另一种说法—-细致地可以分为四个部分:
- 分析连通区域
- 找到块区域
- 找文本行和单词
- 得出(识别)文本
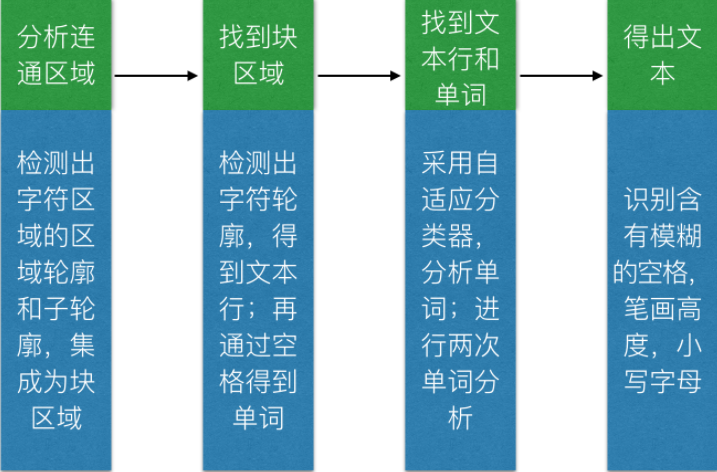
图 Tesseract主要四个部分(仅代表谷震平个人观点,请勿抄袭)
举个详细的例子:
PS:此例也是Ray Smith的文章(Adapting the Tesseract Open Source OCR Engine for Multilingual OCR)中给出的,具有代表性。
不想贴文字,直接上图:
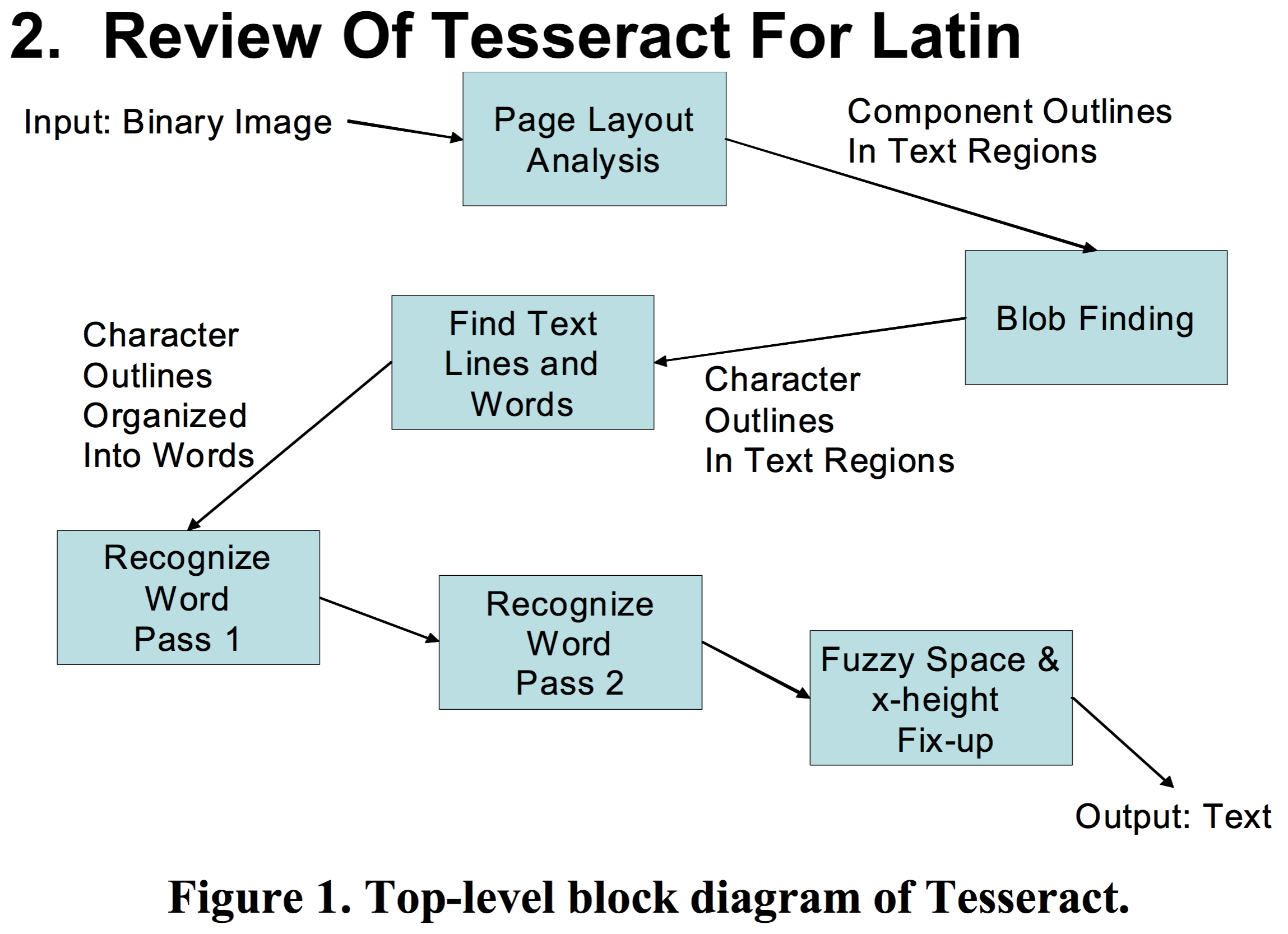
Tesseract的架构并不是我这三言两语能讲清楚地,欢迎留言补充纠正!谢谢合作!
Tesseract实现原理
原理这块相当复杂,这篇blog只谈TessBaseAPI相关的东西。后续系列再撰文补充。
TessBaseAPI是Tesseract引擎的一个核心类,关于这个类的源代码请戳这里:谷震平的传送门。我们来理解下这个类函数的运作机制,借此联想下Tesseract引擎的实现原理。机制如下:
- 调用Init()方法,即对引擎初始化
- 调用setImage()方法,设置图形流的信息
- 通过getUTF8Text()方法获得text信息
- 调用recognizedText类,判断text的正确性,然后输出。这里,会调用自有的trim()方法和length()方法做一些相应的处理。
---------------------
作者:谷震平
来源:CSDN
原文:https://blog.csdn.net/guzhenping/article/details/51019010
版权声明:本文为博主原创文章,转载请附上博文链接!
tessaract ocr简介的更多相关文章
- OCR简介及使用
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然后用字符识别方法将形状翻译 ...
- NET 2.0 OCR文字识别技术(Tesseract 引擎)[转]
一.OCR简介 参见http://baike.baidu.com/view/17761.htm?fr=ala0_1 大家参照,我第一次也是这么了解的,呵呵.高手见笑 现在市面上好多OCR 引擎,不 ...
- OCR识别的Android端实现
1.OCR简介OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然后用字符识别 ...
- 谈谈调用腾讯云【OCR-通用印刷体识别】Api踩的坑
一.写在前面 最近做项目需要用到识别图片中文字的功能,本来用的Tesseract这个写的,不过效果不是很理想. 随后上网搜了一下OCR接口,就准备使用腾讯云.百度的OCR接口试一下效果.不过这个腾讯云 ...
- 【OCP、OCM、高可用等】小麦苗课堂网络班招生简章(从入门到专家)--课程大纲
[OCP.OCM.高可用等]小麦苗课堂网络班招生简章(从入门到专家)--课程大纲 小麦苗信息 我的个人信息 网名:小麦苗 QQ:646634621 QQ群:618766405 我的博客:http:// ...
- OpenCV在字符提取中进行的预处理(转)
OCR简介熟悉OCR的人都了解,OCR大致分为两个部分: -文字提取text extractor -文字识别text recognition 其中,第一部分是属于图像处理部分,涉及到图像分割的知识,而 ...
- OCR(光学字符识别)技术简介
OCR技术起源 OCR最早的概念是由德国人Tausheck最先提出的,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字.早在60.70年代,世界各国就开始有OC ...
- atitit。ocr框架类库大全 attilax总结
atitit.ocr框架类库大全 attilax总结 Tesseract Asprise JavaOCR 闲来无事,发现百度有一个OCR文字识别接口,感觉挺有意思的,拿来研究一下. 百度服务简介:文字 ...
- 【转】腾讯OCR—自动识别技术,探寻文字真实的容颜
文字,一种信息记录的图像符号,千年来承载了太多的人类文明印记.OCR,一种自动解读这种图像符号的技术,一直以来都备受关注.尤其在信息时代的今天,数字图像纷繁复杂,如何便捷高效的获取其中的文字信息,更有 ...
随机推荐
- fullstack
fullstack https://www.fullstack.io/ https://www.fullstack.io/write-a-book https://github.com/fullsta ...
- Delphi的关键字
Constructor;构造器,定义构造函数使用Constructor关键字
- html 類 class
為html元素設置類,相同的類使用相同的樣式.一般元素都能使用,可以在<div>和<span>中使用,同一個class可以被個<div>或<span>使 ...
- BZOJ2215[Poi2011]Conspiracy——2-SAT+tarjan缩点
题目描述 Byteotia的领土被占领了,国王Byteasar正在打算组织秘密抵抗运动.国王需要选一些人来进行这场运动,而这些人被分为两部分:一部分成为同谋者活动在被占领区域,另一部分是后勤组织在未被 ...
- Codeforces Round #276 (Div. 1) E. Sign on Fence (二分答案 主席树 区间合并)
链接:http://codeforces.com/contest/484/problem/E 题意: 给你n个数的,每个数代表高度: 再给出m个询问,每次询问[l,r]区间内连续w个数的最大的最小值: ...
- c# 对象存cookie
下载并引用Newtonsoft.Json.dll 对象转json,然后存cookies string xxx= Newtonsoft.Json.JsonConvert.SerializeObject( ...
- MT【19】舒尔不等式设计理念及证明
评:舒尔的想法是美妙的,当然他本身也有很多意义,在机械化证明的理念里,它也占据了一方田地.
- Luogu 2679 子串 (动态规划)
Luogu 2679 NOIP 2015 子串 (动态规划) Description 有两个仅包含小写英文字母的字符串 A 和 B.现在要从字符串 A 中取出 k 个互不重叠的非空子串,然后把这 k ...
- (转)搭建Maven私服(使用Nexus)
搭建私服可以做什么? 1.如果公司开发组的开发环境全部内网,这时如何连接到在互联网上的Maven中央仓库呢? 2.如果公司经常开发一些公共的组件,如何共享给各个开发组,使用拷贝方式吗?如果这样,公共库 ...
- BAPC2017
Benelux Algorithm Programming Contest 2017 参考资料: https://blog.csdn.net/sizaif/article/details/798586 ...