Java+大数据开发——Hadoop集群环境搭建(一)
1集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
本集群搭建案例,以3节点为例进行搭建,角色分配如下:
hdp-node- NameNode SecondaryNameNode ResourceManager
hdp-node- DataNode NodeManager
hdp-node- DataNode NodeManager
2服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
▨ Vmware 12.0
▨ Centos 7.0 64bit
3网络环境准备
▨ 采用NAT方式联网
▨ 网关地址:192.168.33.1
▨ 3个服务器节点IP地址:192.168.33.101、192.168.33.102、192.168.33.103
▨ 子网掩码:255.255.255.0
4服务器系统设置
▨ 添加HADOOP用户
▨ 为HADOOP用户分配sudoer权限
▨ 同步时间
▨ 设置主机名
◈ hdp-node-01
◈ hdp-node-02
◈ hdp-node-03
▨ 配置内网域名映射:
◈ 192.168.33.101 hdp-node-01
◈ 192.168.33.102 hdp-node-02
◈ 192.168.33.103 hdp-node-03
▨ 配置ssh免密登陆
▨ 配置防火墙
5JDK环境安装
▨ 上传jdk安装包
▨ 规划安装目录 /home/hadoop/apps/jdk_1.7.65
▨ 解压安装包
▨ 配置环境变量 /etc/profile
6HADOOP安装部署
▨ 上传HADOOP安装包
▨ 规划安装目录 /home/hadoop/apps/hadoop-2.6.5
▨ 解压安装包 tar –zxvf hadoop-2.6.5 –C apps/
▨ 修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:
vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/home/hadoop/apps/jdk1..0_45
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-node-01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/HADOOP/apps/hadoop-2.6.5/tmp</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hdp-node-01:50090</value>
</property>
</configuration>
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
vi salves
hdp-node-02
hdp-node-03
7启动集群
初始化HDFS
bin/hadoop namenode -format
启动HDFS
sbin/start-dfs.sh
启动YARN
sbin/start-yarn.sh
查看集群状态
jps
bin/hdfs dfsadmin -report
8测试——运行一个mapreduce程序
在HADOOP安装目录下,运行一个示例mr程序
cd $HADOOP_HOME/share/hadoop/mapreduce/
hadoop jar mapredcue-example-2.6.5.jar wordcount /wordcount/input /wordcount/output
9HDFS使用
1、查看集群状态
命令: hdfs dfsadmin –report
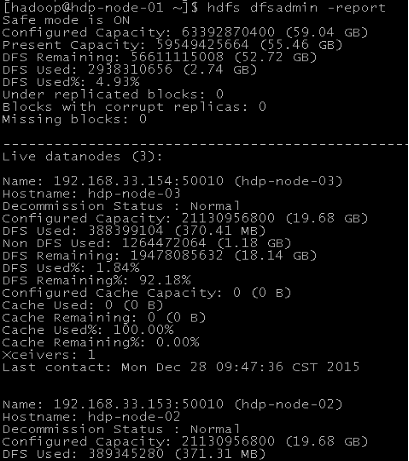
可以看出,集群共有3个datanode可用
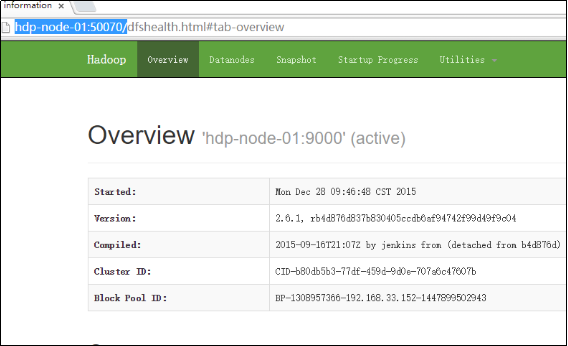
也可打开web控制台查看HDFS集群信息,在浏览器打开http://hdp-node-01:50070/
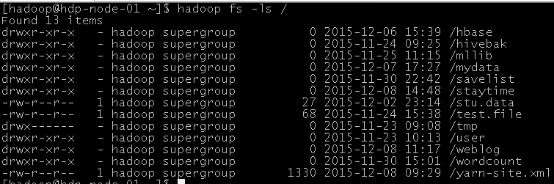
2、上传文件到HDFS
▣ 查看HDFS中的目录信息
命令: hadoop fs –ls /
▣ 上传文件
命令: hadoop fs -put ./ scala-2.10.6.tgz to /

出处:http://www.cnblogs.com/jerehedu/
版权声明:本文版权归烟台杰瑞教育科技有限公司和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
技术咨询:

Java+大数据开发——Hadoop集群环境搭建(一)的更多相关文章
- Java+大数据开发——Hadoop集群环境搭建(二)
1. MAPREDUCE使用 mapreduce是hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序 2. Demo开发--wo ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- 朝花夕拾之--大数据平台CDH集群离线搭建
body { border: 1px solid #ddd; outline: 1300px solid #fff; margin: 16px auto; } body .markdown-body ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
随机推荐
- python用来生成的包含电话号码的python代码
# -*- coding:utf-8 -*-#用python生产包含电话号码的代码temp = """arr = %sindex = %stel = ''for i in ...
- 【ES】代码例子
#!/usr/bin/env python #coding=utf-8 from elasticsearch import Elasticsearch from elasticsearch_dsl i ...
- java 运算符 与(&)、非(~)、或(|)、异或(^)逻辑操作符 与(&&) 或(||) 非(!)
按位与&: 只要对应的二个二进位都为1时,结果位就为1 按位或|:只要对应的二个二进位有一个为1时,结果位就为1 按位异或^:0⊕0=0,1⊕0=1,0⊕1=1,1⊕1=0(同为0,异为1) ...
- mongosync同步1,oplog同步会读取其他集合同步
使用mongosync同步数据 注意: 我下面的这个mongodb版本较低(3.2.16), 还可以用这个工具来同步数据.工具不支持更高版本的mongodb了. 使用方法: https://g ...
- day8--socket文件传输
FTP server 1.读取文件名 2.检测文件是否存在 3.打开文件 4.检测文件大小(告诉客户端发送文件的大小) 5.发送文件大小和MD5值给客户端,MD5 6.等待客户端确认(防止粘包) 7. ...
- [转]硬盘的那些事(主分区、扩展分区、逻辑分区、活动分区、系统分区、启动分区、引导扇区、MBR等)
http://xu3stones.blog.163.com/blog/static/205957136201210309424303 主分区,扩展分区,逻辑分区,活动分区,系统分区,启动分区..... ...
- Hadoop Yarn环境配置
抄一个可行的Hadoop Yarn环境配置.用的官方的2.2.0版本. http://www.jdon.com/bigdata/yarn.html Hadoop 2.2新特性 将Mapreduce框架 ...
- zstu 4247-萌新的旅行
题目大意: zstu的萌新们准备去自助旅行,他们租了一辆吉普车,然后选择了n个城市作为游览地点.然后他们惊喜的发现他们选择的城市刚好绕城一个环. 也就是说如果给所有城市按照0,1,2,……,n-1编号 ...
- 007 关于Spark下的第二种模式——standalone搭建
一:介绍 1.介绍standalone Standalone模式是Spark自身管理资源的一个模式,类似Yarn Yarn的结构: ResourceManager: 负责集群资源的管理 NodeMan ...
- 记录一个mysql的case when用法
SELECT wle.*, CASE WHEN '2017-08-10 14:00:00' > wle.et THEN '回看' WHEN wle.st >= '2017-08-10 14 ...