009 搭建Spark的maven本地windows开发环境以及测试
在看完下面的细节之后,就会发现,spark的开发,只需要hdfs加上带有scala的IDEA环境即可。
当run运行程序时,很快就可以运行结束。
为了可以看4040界面,需要将程序加上暂定程序,然后再去4040上看程序的执行。
新建的两种方式,第一种是当时老师教的,现在感觉有些土,但是毕竟是以前写的,不再删除,就自己在后面添加了第二种新建方式。
一:通过maven命令行命令创建一个最初步的scala开发环境
1.打开cmd
通过maven命令创建一个最初步的scala开发环境。
mvn archetype:generate -DarchetypeGroupId=org.scala-tools.archetypes -DarchetypeArtifactId=scala-archetype-simple -DremoteRepositories=http://scala-tools.org/repo-releases -DgroupId=com.ibeifeng.bigdata.spark.app -DartifactId=logs-analyzer -Dversion=1.0
分两个部分,前面是scala项目需要的插件,后面是确定一个maven工程。
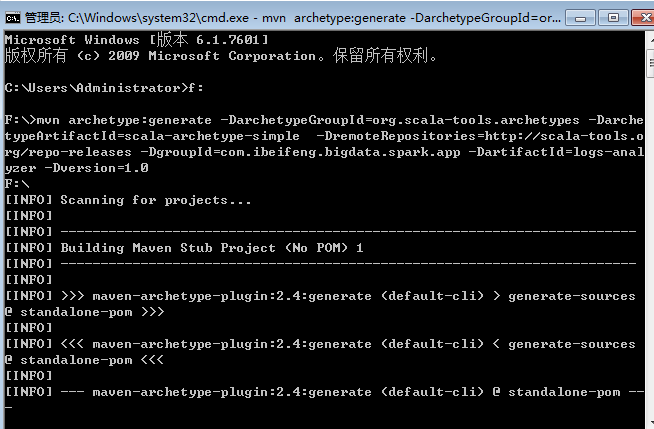
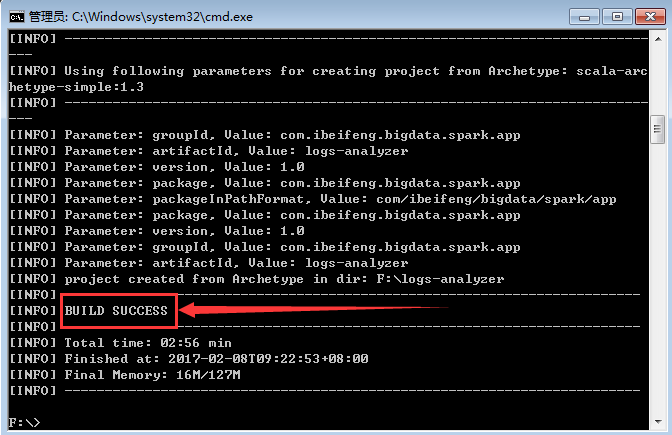
2.等待创建
这样就表示创建成功。
3.生成的项目在F盘
因为在cmd的时候,进入的是F盘。
4.使用open导入
一种IDEA的使用打开方式。
5.在pom.xml中添加dependency
HDFS ,Spark core ,Spark SQL ,Spark Streaming
这个里面重要的部分是有scala的插件。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>sacla</groupId>
<artifactId>scalaTest</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<maven.compiler.source>1.5</maven.compiler.source>
<maven.compiler.target>1.5</maven.compiler.target>
<encoding>UTF-8</encoding>
<spark.version>1.6.1</spark.version>
<hadoop.version>2.5.0</hadoop.version>
</properties> <dependencies>
<!-- Spark Core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
<scope>compile</scope>
</dependency>
<!-- Spark SQL -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>${spark.version}</version>
<scope>compile</scope>
</dependency>
<!-- Spark Streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>${spark.version}</version>
<scope>compile</scope>
</dependency>
<!-- HDFS Client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>compile</scope>
</dependency> <!-- Test -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.8.1</version>
<scope>test</scope>
</dependency> </dependencies> <build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.6</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<!-- If you have classpath issue like NoDefClassError,... -->
<!-- useManifestOnlyJar>false</useManifestOnlyJar -->
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
</plugins>
</build> </project>
二:第二种方式
这种方式,比较实用。
1.直接新建一个Maven工程
需要在pom中添加scala的插件。
2.新建scala文件夹
原本生成的maven项目只有java与resources。
在project Stucture中新建scala文件夹,然后将scala文件夹编程sources。
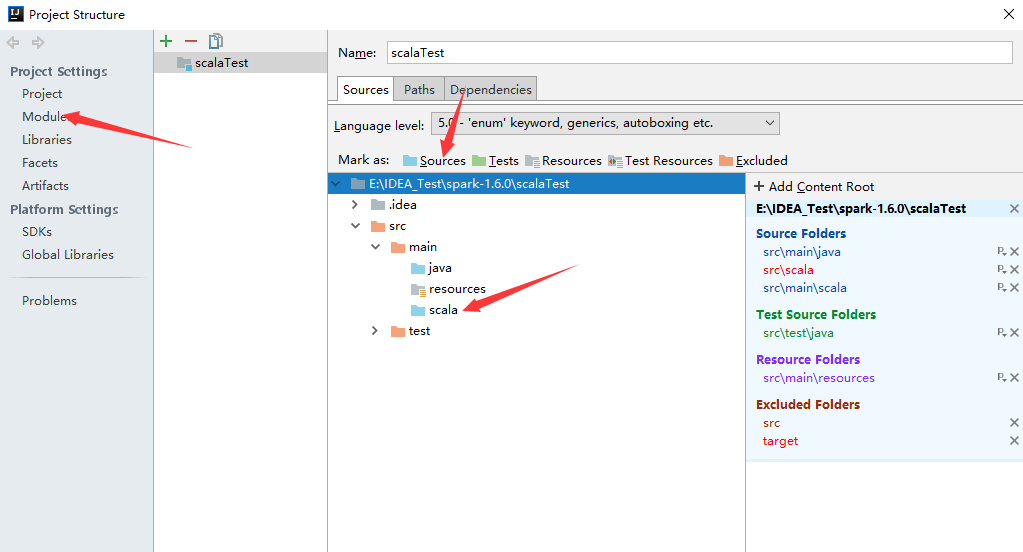
3.完成
这个截图还是第一种方式下的截图,但是意思没问题。

4.在resources中拷贝配置文件
需要连接到HDFS的配置文件。
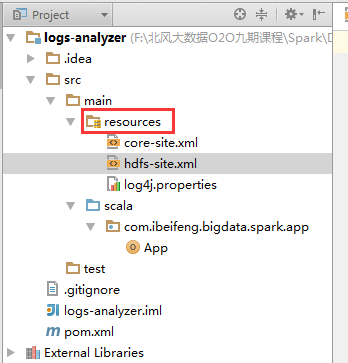
5.新建包
6.新建类
因为有了scala插件,就可以直接新建scala 的 object。
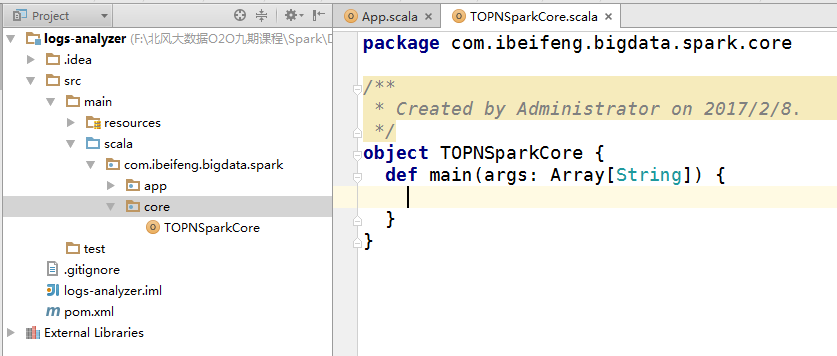
7.启动hdfs
因为需要hdfs上的文件,不建议使用本地的文件进行数据处理。
8.书写程序
这是一个简单的单词统计。
重点的地方有两个,一个是setMaster,一个是setAppName。如果没有设置,将会直接报错。
package com.scala.it
import org.apache.spark.{SparkConf, SparkContext}
object TopN {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setMaster("local[*]")
.setAppName("top3");
val sc=new SparkContext(conf)
val path="/user/beifeng/mapreduce/wordcount/input/wc.input"
val rdd=sc.textFile(path)
val N=3
val topN=rdd
.filter(_.length>0)
.flatMap(_.split(" ").map((_,1)))
.reduceByKey((a,b)=>a+b)
.top(N)(ord = new Ordering[(String,Int)] {
override def compare(x: (String, Int), y: (String, Int)) : Int={
val tmp=x._2.compareTo(y._2)
if (tmp==0)x._1.compareTo(y._1)
else tmp
}
})
topN.foreach(println)
sc.stop()
}
}
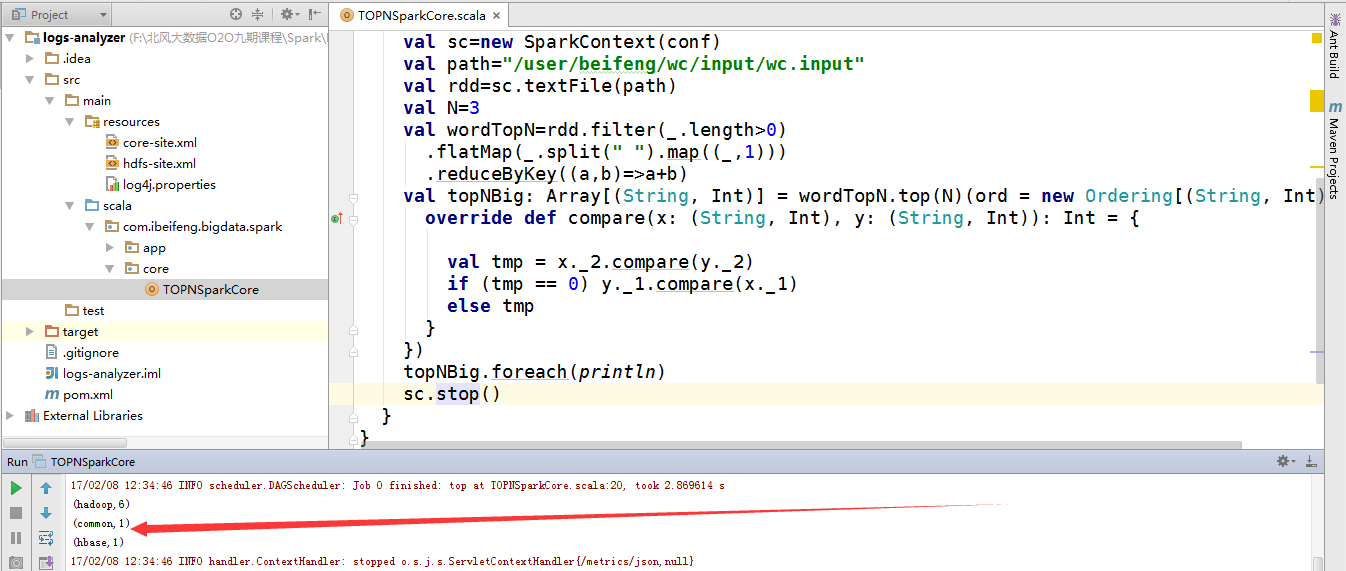
9.直接运行的结果
因为是local模式,所以不需要启动关于spark的服务。
又因为hdfs的服务已经启动。
所以,直接运行run即可。
二:注意的问题
1.path问题
程序中的path默认是hdfs路径。
当然,可以使用windows本地文件,例如在D盘下有abc.txt文件,这时候path="file:///D:/abc.txt"
009 搭建Spark的maven本地windows开发环境以及测试的更多相关文章
- windows下搭建hadoop-2.6.0本地idea开发环境
概述 本文记录windows下hadoop本地开发环境的搭建: OS:windows hadoop执行模式:独立模式 安装包结构: Hadoop-2.6.0-Windows.zip - cygwinI ...
- 实验室中搭建Spark集群和PyCUDA开发环境
1.安装CUDA 1.1安装前工作 1.1.1选取实验器材 实验中的每台计算机均装有双系统.选择其中一台计算机作为master节点,配置有GeForce GTX 650显卡,拥有384个CUDA核心. ...
- Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder': —— windows 开发环境使用spark 无法访问hdfs 问题解决
## 错误: ## 解决方案: 下载 hadoop 的可执行tar包,解压放在windows 本地,并配置环境变量. 在 解压后的文件夹的bin目录下放入两个文件: winutils.exe, had ...
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
http://blog.csdn.net/xiefu5hh/article/details/51707529 Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例[附 ...
- 使用Maven搭建Struts2+Spring3+Hibernate4的整合开发环境
做了三年多的JavaEE开发了,在平时的JavaEE开发中,为了能够用最快的速度开发项目,一般都会选择使用Struts2,SpringMVC,Spring,Hibernate,MyBatis这些开源框 ...
- 在Windows上搭建PhoneGAP(crodova)的开发环境
PhoneGAP是一个可以将web应用打包成移动应用的开源框架,使用它可以迅速的将HTML.CSS和JavaScript开发的web应用打包成跨平台的移动应用程序,而Apache Cordova是Ph ...
- 使用Vagrant搭建本地python开发环境
使用Vagrant搭建本地python开发环境 关于vagrant:Vagrant是一个基于Ruby的工具,用于创建和部署虚拟化开发环境,它使用Oracle的开源VirtualBox虚拟化系统也可以使 ...
- 使用Git下载Hadoop的到本地Eclipse开发环境
使用Git下载Hadoop的到本地Eclipse开发环境 博客分类: Hadoop *n*x MacBook Air hadoopgitmaveneclipsejava 问题场景 按照官网http: ...
- 如何搭建Visual Studio的内核编程开发环境
最近正在看<寒江独钓——Windows内核安全编程>这本书,感觉这本书非常好,有兴趣的朋友可以买来看看,有关这本书的信息请参考:http://www.china-pub.com/19559 ...
随机推荐
- ettercap中间人攻击--参数介绍
攻击和嗅探 -M, --mitm ARP欺骗,参数 -M arp remote # 双向模式,同时欺骗通信双方,-M arp:remote. oneway #单向模式,只arp欺骗第一个 ...
- JavaScript之JS单线程|事件循环|事件队列|执行栈
本博文基于知乎"JavaScript作用域问题?"一问,而引起了对JavaScript事件循环和单线程等概念与实践上的研究.深入理解. 一.概念 0.关键词:JavaScript单 ...
- Error while executing topic command : Replication factor: 2 larger than available brokers: 0.
[root@hdp1 /mnt/software/maxwell-1.19.4]#kafka-topics.sh --zookeeper hdp1,hdp2,hdp3:2181 --create -- ...
- python - class类 (七) 三大特性 - 封装 结尾
封装: # 封装 #第一层,类就是麻袋,本身就是一种封装 #第二层,类中定义私有的,至在类的内部使用,外部无法访问 #第三层,封装在于明确区分内外,使得类实现者可以修改封装内的东西二不影响外部调用者 ...
- Python 入门基础19 --面向对象、封装
2019.04.17 一.面向对象与面向过程 二.名称空间操作 三.类与对象的概念 四.语法 五.对象查找属性的顺序 2019.04.18 1.类与对象的所有概念:__init__方法 2.类的方法与 ...
- 在Spring(4.3.22)中集成Hibernate(5.4.0)
(1)pom中添加相关依赖 <dependency> <groupId>org.hibernate</groupId> <artifactId>hibe ...
- python3之协程
1.协程的概念 协程,又称微线程,纤程.英文名Coroutine. 线程是系统级别的它们由操作系统调度,而协程则是程序级别的由程序根据需要自己调度.在一个线程中会有很多函数,我们把这些函数称为子程序, ...
- NMS和soft-nms算法
非极大值抑制算法(nms) 1. 算法原理 非极大值抑制算法(Non-maximum suppression, NMS)的本质是搜索局部极大值,抑制非极大值元素. 2. 3邻域情况下NMS的实现 3邻 ...
- nodejs async waterfull 小白向
async.waterfall([function(callback){var a=3+5;callback(null,a);},function(n,callback) { callback(nul ...
- python根据服务名获取服务启动路径
#coding=utf8 import _winreg as winreg class Win32Environment: """Utility class to get ...