caffe实际运行中遇到的问题
1、均值计算是否需要统一图像的尺寸?
在图像计算均值时,应该先统一图像的尺寸,否则会报出错误的。
粘贴一部分官方语言:
均值削减是数据预处理中常见的处理方式,按照之前在学习ufldl教程PCA的一章时,对于图像介绍了两种:第一种常用的方式叫做dimension_mean(个人命名),是依据输入数据的维度,每个维度内进行削减,这个也是常见的做法;第二种叫做per_image_mean,ufldl教程上说,在natural images上训练网络时;给每个像素(这里只每个dimension)计算一个独立的均值和方差是make little sense的;这是因为图像本身具有统计不变性,即在图像的一部分的统计特性和另一部分相同。作者最后建议,如果你训练你的算法在非natural images(如mnist,或者在白背景存在单个独立的物体),其他类型的规则化是值得考虑的。但是当在natural images上训练时,per_image_mean是一个合理的默认选择。
这段话意在告诉我们在训练的图像不同,我们均值采用的方法亦可发生变化。
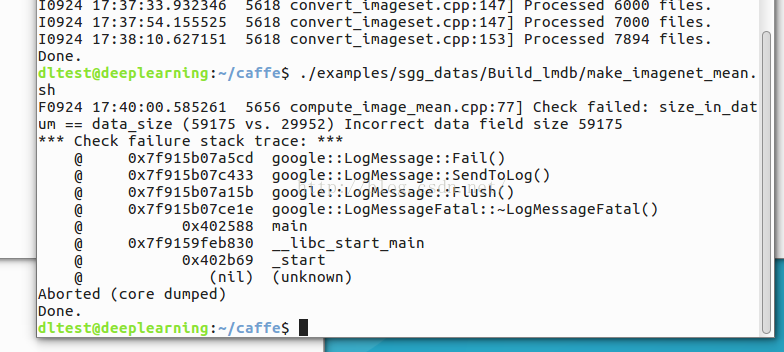
上图中很明显爆出了“size_in_datum == data_size ” 的错误。
下面是小编找到的问题原因:
在把图片转化到levelDB中遇到了Check failed: data.size() == data_size,归根究底还是源码没细看,找到出错的行在F0714 20:31:14.899121 26565 convert_imageset.cpp:84] convert_imageset.cpp中的第84行, CHECK_EQ(data.size(), data_size) << "Incorrect data field size " << data.size();就是说两个大小不一致,再看代码
- int data_size;
- bool data_size_initialized = false;
- for (int line_id = 0; line_id < lines.size(); ++line_id) {
- if (!ReadImageToDatum(root_folder + lines[line_id].first,lines[line_id].second, datum)) {
- continue;
- }
- if (!data_size_initialized) {
- data_size = datum.channels() * datum.height() * datum.width();
- data_size_initialized = true;
- } else {
- const string& data = datum.data();
- CHECK_EQ(data.size(), data_size) << "Incorrect data field size "
- << data.size();
- }
从上面的代码可知,第一次循环中,data_size_initialized=false,然后进入到if (!data_size_initialized) 中,把data_size设为了datum.channels() * datum.height() * datum.width(),同时把data_size_initialized=true,在以后的迭代中,都是执行else语句,从而加入图片大小不一致会报错,处理的办法可选的是,在转换到数据库levelDB前,让图片resize到一样的大小,或者把ReadImageToDatum改成ReadImageToDatum(root_folder + lines[line_id].first,lines[line_id].second,width,height ,datum)。
参考博文地址:http://blog.csdn.net/alan317/article/details/37772457
2、caffe实际运行中图像大小不一,放大缩小时都有可能失真,此时该如何处理数据?
如果处理的图像大小不一且过度放大或者过度缩小会造成图像严重失真且丢失信息,则不能直接对图像尺寸进行归一化。
措施:
可以采用一个居中的尺寸,例如统一图像的宽度为600,而高度根据宽度的大小按照比例进行缩放。处理完之后可以对图像进行切片处理,进而将图像尺寸进行归一化。
3、Crop_size的作用?
4、在网络配置文件中的 test_iter 值得确定
- # reduce the learning rate after 8 epochs (4000 iters) by a factor of 10
- # The train/test net protocol buffer definition
- net: "examples/cifar10/cifar10_quick_train_test.prototxt"
- # test_iter specifies how many forward passes the test should carry out.
- # In the case of MNIST, we have test batch size 100 and 100 test iterations,
- # covering the full 10,000 testing images.
- test_iter: 100
- # Carry out testing every 500 training iterations.
- test_interval: 100
- # The base learning rate, momentum and the weight decay of the network.
- base_lr: 0.001
- momentum: 0.9
- weight_decay: 0.004
- # The learning rate policy
- lr_policy: "fixed"
- # Display every 100 iterations
- display: 100
- # The maximum number of iterations
- max_iter: 4000
- # snapshot intermediate results
- snapshot: 4000
- snapshot_format: HDF5
- snapshot_prefix: "examples/cifar10/cifar10_quick"
- # solver mode: CPU or GPU
- solver_mode: CPU
在设置配置时,对于test_iter值的计算有一点模糊,不知是根据batch size 值与整体图像库(测试集合与训练集合)还是单独的某个图像集合数据计算获得。后来通过认真读给出的解释与实例,最终确定该值是batch size 值与测试图像集合计算获得的。若batch size 值为100,而训练集合含有6000幅图片,测试集含有1000幅图片,则test_iter值为1000/10,与训练集的图片量无关。
5、如何判断一个模型已经训练好,可以正常使用?
6、能否将caffe从Linux下导出,形成一个独立包?
7、Cannot copy param 0 weights from layer 'conv1'; shape mismatch.
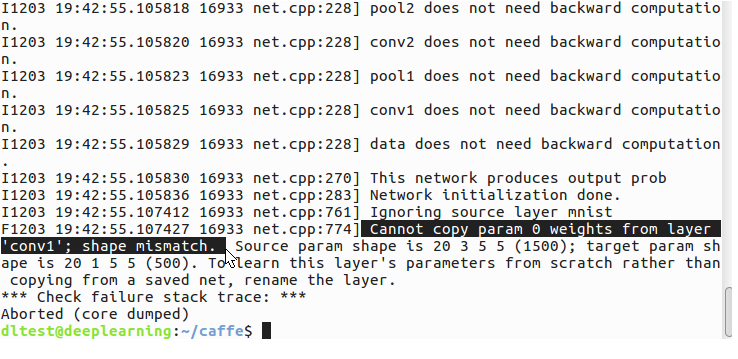
相关网页:http://stackoverflow.com/questions/37300317/caffe-error-cannot-copy-param-0-weights-from-layer-shape-mismatch
http://blog.csdn.net/ddqqfree123/article/details/52389337
http://blog.csdn.net/preston2006/article/details/53421889
网络上给出的解决方法:
|
|
Share the prototxt file that you used to train and test to pinpoint the issue. It should be mainly because the dimensions of the input image is not the same in both the test prototxt and train prototxt. Check the height, width and channel count of both the test and train prototxt
|
实际解决方法与解析:
“conv1” ; shape mismatch 已经很明确的给出了错误的原因,原始shape不一致,同时又很明确的指出了是cov1层出现的错误。所以直接找shape\cpnv1,之后才发现是训练模型文件与模型定义文件中的shape不相符,我训练时图像库中有的图像是一个通道,有的是使用的3个通道,所以默认使用三个通道,而我的模型定义文件中的shape,其通道数写的是1个通道,故出现错误。
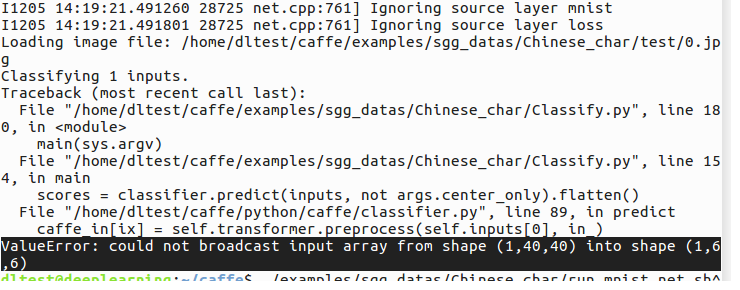
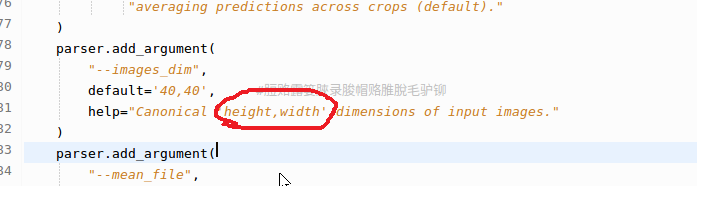
8、ValueError: could not broadcast input array from shape (1,40,40) into shape (1,6,6)
9、caffe 提示 build/examples/mnist/convert_mnist_data.bin: error while loading shared libraries: libprotobuf.so.8: cannot open shared object file: No such file or directory

解决方法:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/dell/local_install/lib如图所示:

10、在生成lmdb过程中提示:Check failed:mkdir( source.c_str() , 0744 ) == 0 ( -1 vs. 0 ) mkdir /home/dell/multiple_caffe/sgg_projects/codes/train_label_lmdb failed

从上述提示错误中很明显是 train_label_lmdb 出现错误。 所以从这点开始寻找突破点。最终找到的问题所在:在生成 lmdb 过程中,需要先删除原有的lmdb 文件,否则就会出现这种错误。在生成之前添加:
rm -rf $EXAMPLE/train_label_lmdb
11、生成均值文件时提示错误: Check failed: mdb_status == 0 (2 vs. 0) No such file or directory
小编出现这个错误是由于生成均值的文件中变量没有赋值正确,所以如果出现这个问题,现确定你的生成均值文件中的变量值都是正确的。
12、小编近期在使用caffe进行训练时,常出现 Check failed: error == cudaSuccess (2 vs. 0) out of memory 错误。
从错误提示可以看出是内存不够了。所以小编就加了一个8G 内存条(刚好手边有),可是加上了并没有多大的作用啊,还是照样报错。后来才找到解决方法。
解决方法:
batch_size太大了,一次性读入的图片太多了,所以就超出了显存。因此需要将train.prototxt中的文件train和test的batch_size调小一点。
参考博文:http://blog.csdn.net/qq_29596177/article/details/56692295
caffe实际运行中遇到的问题的更多相关文章
- Ubuntu16.04 faster-rcnn+caffe+gpu运行环境配置以及解决各种bug
https://blog.csdn.net/flygeda/article/details/78638824 本文主要是对近期参考的网上各位大神的博客的总结,其中,从安装系统到跑通程序过程中遇到的各种 ...
- android大项目运行中出现问题汇总
Android 项目中,特别是当项目文件和规模达到一定的程度后,会引发一些平常不常见的问题. 下面对遇到的一些问题做一个汇总和总结. scenario 1: 在项目中,我们采用了chromimum内核 ...
- 在linux下,查看一个运行中的程序, 占用了多少内存
1. 在linux下,查看一个运行中的程序, 占用了多少内存, 一般的命令有 (1). ps aux: 其中 VSZ(或VSS)列 表示,程序占用了多少虚拟内存. RSS列 表示, 程序占用了多少物 ...
- java中如何使正在运行中的线程退出
终止线程的三种方法 有三种方法可以使终止线程. 1. 使用退出标志,使线程正常退出,也就是当run方法完成后线程终止. 2. 使用stop方法强行终止线程(这个方法不 ...
- Linux显示所有运行中的进程
Linux显示所有运行中的进程 youhaidong@youhaidong-ThinkPad-Edge-E545:~$ ps aux | less USER PID %CPU %MEM VSZ RSS ...
- 在linux下,怎么去查看一个运行中的程序, 到底是占用了多少内存
1. 在linux下,查看一个运行中的程序, 占用了多少内存, 一般的命令有 (1). ps aux: 其中 VSZ(或VSS)列 表示,程序占用了多少虚拟内存. RSS列 表示, 程序占用了多少物 ...
- Docker学习笔记 - 在运行中的容器内启动新进程
docker psdoker top dc1 # 容器情况# 在运行中的容器内启动新进程docker exec [-d] [-i] [-t] 容器名 [command] [args]docker ex ...
- 如何修改运行中的docker容器的端口映射和挂载目录
在docker run创建并运行容器的时候,可以通过-p指定端口映射规则.但是,我们经常会遇到刚开始忘记设置端口映射或者设置错了需要修改.当docker start运行容器后并没有提供一个-p选项或设 ...
- 教你如何修改运行中的docker容器的端口映射
在docker run创建并运行容器的时候,可以通过-p指定端口映射规则.但是,我们经常会遇到刚开始忘记设置端口映射或者设置错了需要修改.当docker start运行容器后并没有提供一个-p选项或设 ...
随机推荐
- MyEclipse 2015反编译插件安装
本文转自 MyEclipse 2015反编译插件安装 分享一下下载插件的地址,百度网盘:链接:http://pan.baidu.com/s/1nturiAH 密码:yk73 其次:我来说下具体操作步骤 ...
- js字符串截取为数组
var str="hello,word,java,eclipse,jsp"; //字符串截取为数组 var strArr=str.split(","); for ...
- 深度学习Bible学习笔记:第一章 前言
写在前面:请务必踏踏实实看书,结合笔记或视频来理解学习,任何技术,啃砖头是最扎实最系统的,为避免知识碎片化,切忌抛却书本的学习!!! 一 什么是深度学习 1 关于AI: AI系统必须具备从原始数据提取 ...
- django----对model查询扩展
基于对象关联查询 一对多查询(Book--Publish): 正向查询,按字段: (从关联的表中查询) book_obj.publish : 与这本书关联的出版社对象 book_obj.publish ...
- 树链剖分边权模板spoj375
树链剖分是树分解成多条链来解决树上两点之间的路径上的问题 如何求出树链:第一次dfs求出树上每个结点的大小和深度和最大的儿子,第二次dfs就能将最大的儿子串起来并hash(映射)到线段树上(或者其他数 ...
- 传统DOM事件处理程序
传统DOM事件处理程序与比HTML事件处理程序相比,优点:可以将HTML和JS脚本分离. 它的操作形式如下 : <body> <div>传统DOM事件处理程序与比HTML事件处 ...
- SpringMVC异常处理器
本节内容: 异常处理思路 自定义异常类 自定义异常处理器 异常处理器配置 错误页面 异常测试 springmvc在处理请求过程中出现异常信息交由异常处理器进行处理,自定义异常处理器可以实现一个系统的异 ...
- Ckeditor一种很方便的文本编辑器
ckeditor官网:http://ckeditor.com/ 这里介绍ckeditor的其中一个的用法,自己做小项目练手非常的适合,上手非常的快. 首先去官网下载这个东西,链接:http://pan ...
- [转] css自定义字体font-face的兼容和使用
@Font-face目前浏览器的兼容性: Webkit/Safari(3.2+) TrueType/OpenType TT (.ttf) .OpenType PS (.otf): Opera (10+ ...
- gulp初探
很多人都在用grunt和gulp,我现在连github都不用..为了说自己是个前端,还是搞搞gulp吧 nodejs很多人都会安装,这个不是问题 npm模块现在好像是自带的..我忘了.. 先全局安装下 ...