关于Kafka Fetch Session的讨论
Kafka在1.1.0版本引入了fetch session的概念,旨在降低“无效”FETCH请求对集群带宽资源的占用。故事的背景是这样的:
众所周知,Kafka的broker和consumer都会定期地向leader broker发送FETCH请求去获取数据。对于分区数很多的topic而言,待发送的FETCH请求就会很大,从而整体上增加网络带宽占用。即使这些分区没有任何新的数据到来,follower和consumer构造的FETCH请求都需要显式地罗列出每个订阅分区的详细数据,这包括:分区号、该分区当前开始位移(log start offset)、位移以及能够请求的最大字节数。
下面我们以1.0.2版本为例查看一下一个普通的FETCH请求有多大?首先启动两台broker服务器,然后创建一个replcation factor是2且有1000个分区的topic:test,之后观察下列JMX指标的值,如下图所示:
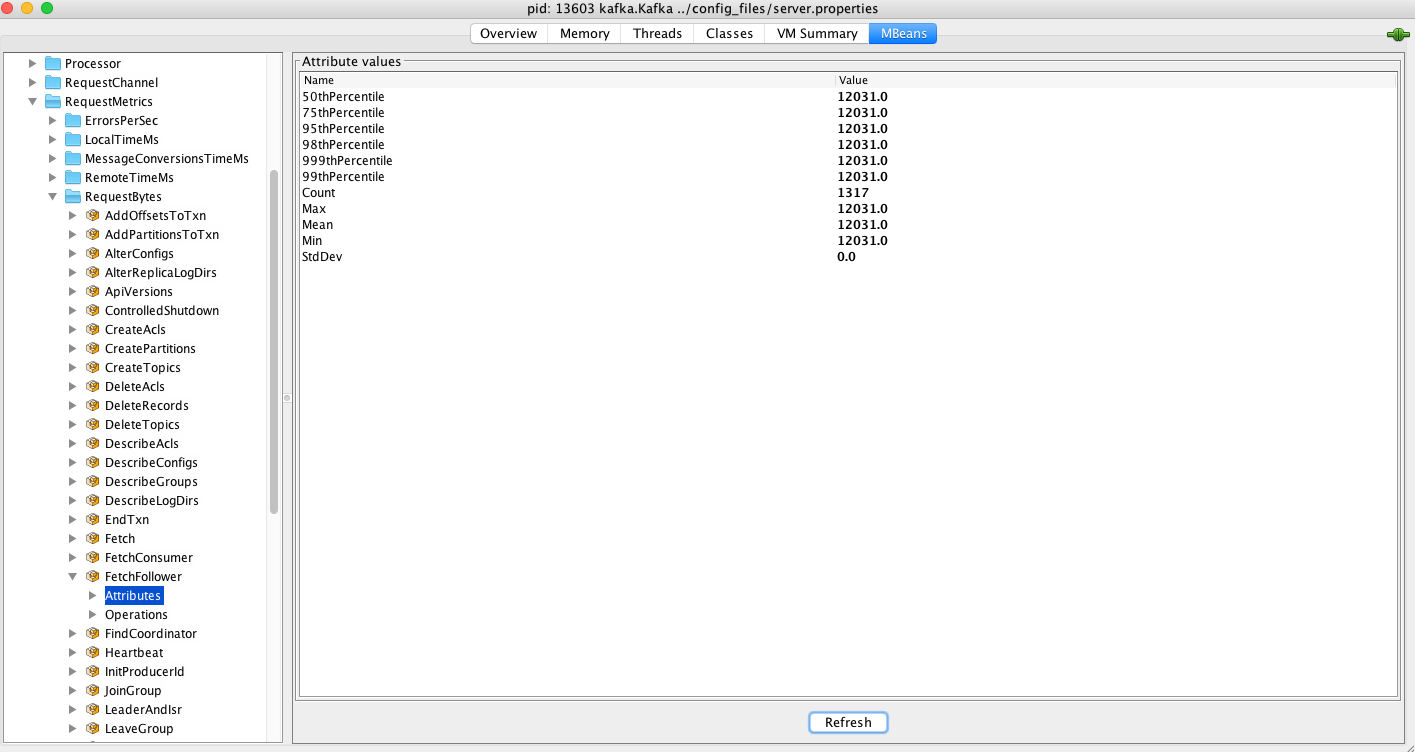
可以看出,对于这个有着1000个分区的topic而言,每台broker上接收到的FETCH请求大小固定是12031个字节,即大约12KB左右。即使我没有给这个topic发送过任何消息(即consumer没有可以消费的消息),FETCH请求都是这么大。
下面我们再用1.1.0版本重试一下这个测试,依然是启动两台1.1.0版本的broker服务器,然后创建一个replication-factor是2,有1000个分区的topic,然后再次查看FETCH请求的大小,如下图所示:
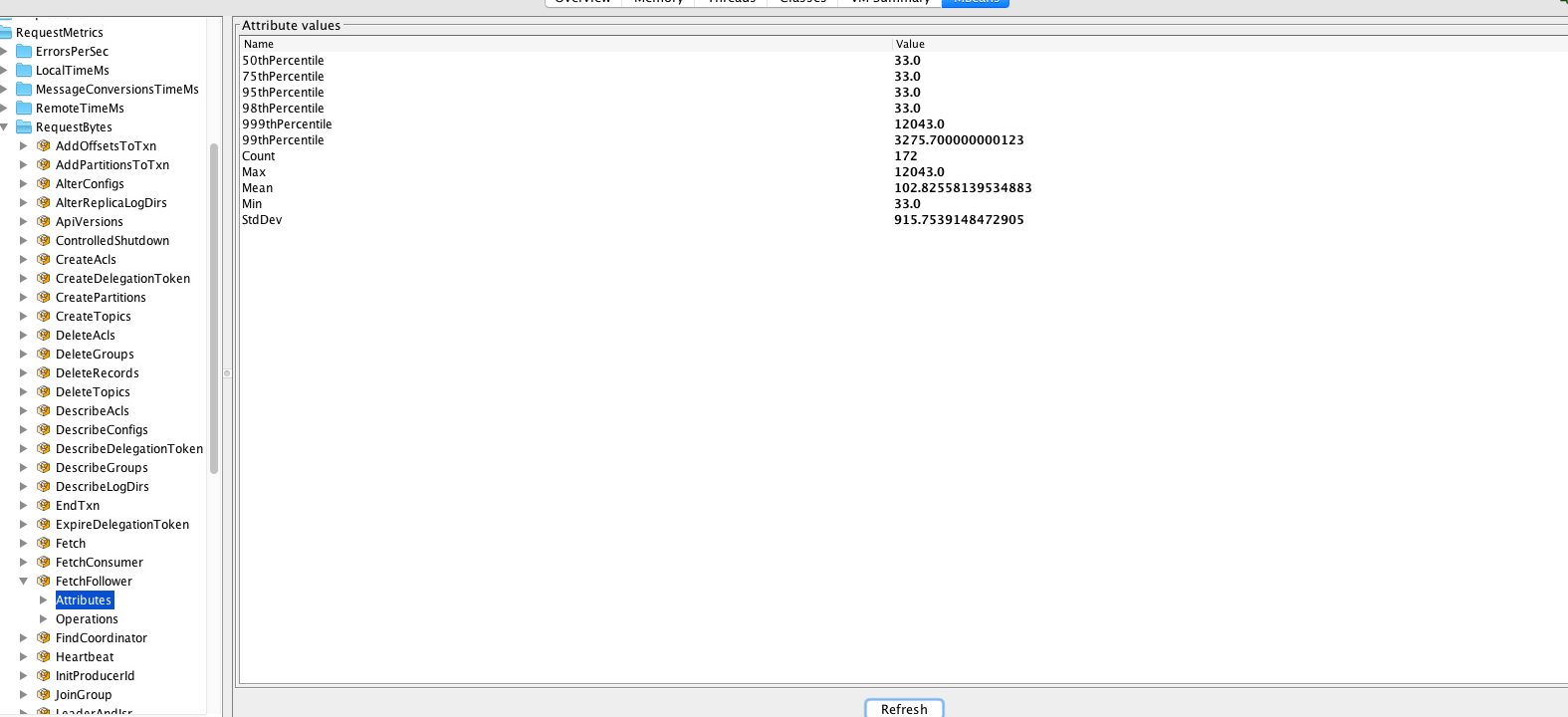
这次我们发现FETCH请求大小的最大值可以达到12043字节,而之后一定稳定在最小值33字节上。从这两组测试结果来看,显然1.1.0版本在某些情况下极大地减少了FETCH请求的大小,节省了网络带宽(针对我们这个测试topic而言,网络流量节省了将近365倍!)。那么这是怎么做到的呢?首先先从FETCH请求的协议格式开始说起。1.1.0之前最新的FETCH请求格式是V6版本,如下图所示:
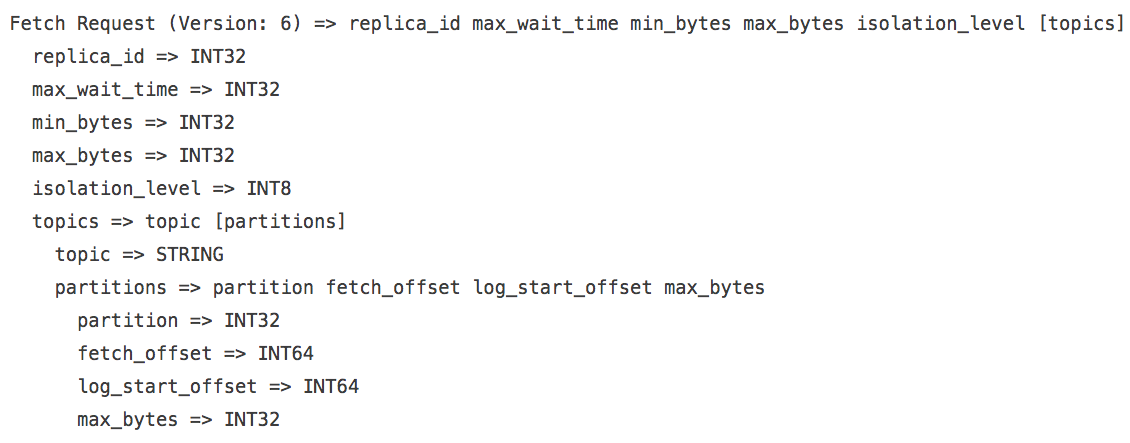
这里我不详细展开各个字段的含义了,因为这与本文要讨论的主题无关。不过我请各位再看下1.1.0版本引入的V7版本格式,如下图所示:
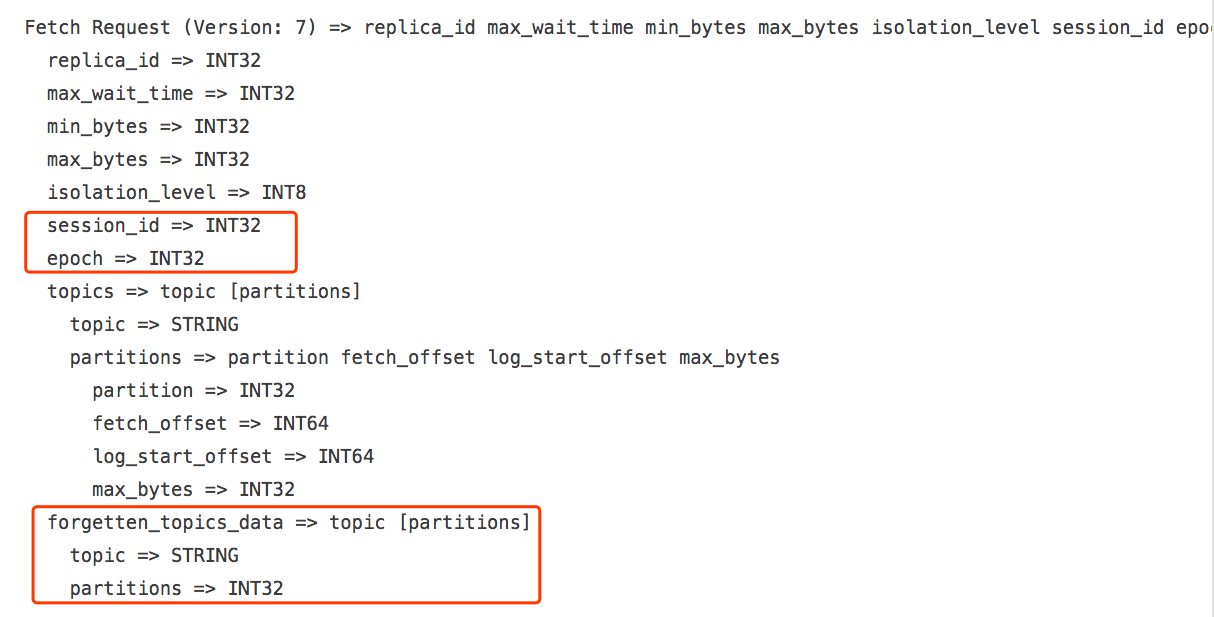
V7与V6版本的差异我已经用红框标识出来了,即在V7版本中新引入了3个主要的变化:session_id/epoch和forgetten_topics_data,其中session_id和epoch合称为fetch session元数据。这里面的fetch session即是1.1.0版本关于FETCH请求的最大变化。一个FETCH SESSION本质上封装了一个fetcher线程的状态,broker端会缓存若干个session在内存中,然后通过FETCH response把相应的状态发送给clients端,这样clients就能知晓当前这个fetcher的状态,从而避免每次FETCH请求中都重复性地请求无意义的数据。
在引入这个变化后,FETCH请求被分成了两类:FULL FETCH请求和Incremental FETCH请求。在首次发送FETCH请求或当session状态发生变化的时候,clients依然发送和以往类似的完整FETCH请求——也就是所谓的FULL FETCH请求,而一旦session稳定下来,且没有变更,那么clients就能安全地发送“瘦身后”的FETCH请求,即增量式FETCH请求,从而起到节省带宽的作用。
上面测试场景中第二张图的MAX值就是FULL FETCH请求的大小(即12043B),如果我们和图1的FETCH请求大小(12031B)做比较会发现V7版本中FULL FETCH请求比之前V6版本的多了12字节(12043 - 12031),这12个字节就是session_id(4B), epoch(4B)和空forgetten_topics_data数组(4B)所占用的内存空间。
FULL FETCH请求的完整格式如下:
{replica_id=1,max_wait_time=500,min_bytes=1,max_bytes=10485760,isolation_level=0,session_id=0,epoch=0,topics=[{topic=test,partitions=[
{partition=0,fetch_offset=0,log_start_offset=0,max_bytes=1048576},
{partition=1,fetch_offset=0,log_start_offset=0,max_bytes=1048576},
...
{partition=999,fetch_offset=0,log_start_offset=0,max_bytes=1048576}
]}], forgotten_topics_data=[]}
由此可见在FULL FETCH请求中session_id和session的epoch都是0。一旦发现这些分区的FETCH session没有变化,clients会自动切换成发送增量式FETCH请求,其格式如下:
{replica_id=1,max_wait_time=500,min_bytes=1,max_bytes=10485760,isolation_level=0,session_id=1253124317,epoch=1,topics=[],forgotten_topics_data=[]}
如果我们验证增量式FETCH请求的大小,可以很容易地计算出其大小=4B(replica_id) + 4B(max_wait_time) + 8B(min_bytes&max_bytes)+ 1B(isolation_level)+ 4B (session_id) + 4B(epoch) + 4B(空topics数组) + 4B(空forgotten_topics_data数组)=33字节,与图2中稳定后的FETCH请求大小正好吻合!
综上所说,Kafka在1.1.0版本引入了FETCH session的概念以期望减少FETCH请求对于网络带宽的占用,从实际使用角度而言,这种减少对于超大规模的集群是有明显提升的,而对于一般的小集群其优化的效果则并非那么显著。不过鉴于这是对用户透明的性能提升,故总然是一件好事情~~
关于Kafka Fetch Session的讨论的更多相关文章
- Kafka Fetch Session剖析
1.概述 最近有同学留言在使用Kafka的过程中遇到一些问题,比如在拉取的Topic中的数据时会抛出一些异常,今天笔者就为大家来分享一下Kafka的Fetch流程. 2.内容 2.1 背景 首先,我们 ...
- Kafka设计解析(二十三)关于Kafka监控方案的讨论
转载自 huxihx,原文链接 关于Kafka监控方案的讨论 目前Kafka监控方案看似很多,然而并没有一个“大而全”的通用解决方案.各家框架也是各有千秋,以下是我了解到的一些内容: 一.Kafka ...
- 关于Kafka broker IO的讨论
Apache Kafka是大量使用磁盘和页缓存(page cache)的,特别是对page cache的应用被视为是Kafka实现高吞吐量的重要因素之一.实际场景中用户调整page cache的手段并 ...
- 关于Kafka high watermark的讨论2
之前写过一篇关于Kafka High watermark的文章,引起的讨论不少:有赞扬之声,但更多的是针对文中的内容被challenge,于是下定决心找个晚上熬夜再看了一遍,昨晚挑灯通读了一遍确实发现 ...
- 关于Kafka监控方案的讨论
之前在知乎上尝试过回答这个问题,后来问的人挺多,干脆在博客里面保存一下. 目前Kafka监控方案看似很多,然而并没有一个"大而全"的通用解决方案.各家框架也是各有千秋,以下是我了解 ...
- Kafka官方文档V2.7
1.开始 1.1 简介 什么是事件流? 事件流相当于人体的中枢神经系统的数字化.它是 "永远在线 "世界的技术基础,在这个世界里,业务越来越多地被软件定义和自动化,软件的用户更是软 ...
- JavaWeb项目架构之Kafka分布式日志队列
架构.分布式.日志队列,标题自己都看着唬人,其实就是一个日志收集的功能,只不过中间加了一个Kafka做消息队列罢了. kafka介绍 Kafka是由Apache软件基金会开发的一个开源流处理平台,由S ...
- Kafka单节点及集群配置安装
一.单节点 1.上传Kafka安装包到Linux系统[当前为Centos7]. 2.解压,配置conf/server.property. 2.1配置broker.id 2.2配置log.dirs 2. ...
- kafka channle的应用案例
kafka channle的应用案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 最近在新公司负责大数据平台的建设,平台搭建完毕后,需要将云平台(我们公司使用的Ucloud的 ...
随机推荐
- winform 中 给DataGridView的表头添加CheckBox
在C/S架构中,给DataGridView的表头添加CheckBox控件: 添加类: /// <summary> /// 给DataGridView添加全选 / ...
- js实现的map方法
/** * * 描述:js实现的map方法 * @returns {Map} */ function Map(){ var struct = function(key, value) { this.k ...
- grep 多行 正则匹配
https://stackoverflow.com/questions/2686147/how-to-find-patterns-across-multiple-lines-using-grep I ...
- 登录sqlplus 后,显示问号 ????
登录sqlplus 后,显示 ???? SYS@orcl>startup ORACLE instance started. Total System Global Area 3290345472 ...
- 【FTP】FTP服务器的搭建
记录一下FTP服务器的搭建首先打开 程序和功能>打开或关闭Windows功能 进入到Windows功能界面:勾选FTP服务器.然后再在IIS界面,新建一个网站.右键网站,选择“添加到FTP发布” ...
- 解决ScrollView嵌套RecyclerView的显示及滑动问题
项目中时常需要实现在ScrollView中嵌入一个或多个RecyclerView.这一做法通常会导致如下几个问题 页面滑动卡顿 ScrollView高度显示不正常 RecyclerView内容 ...
- 分析各种Android设备屏幕分辨率与适配 - 使用大量真实安卓设备采集真实数据统计
一. 数据采集 源码GitHub地址 : -- SSH : git@github.com:han1202012/DisplayTest.git; -- HTTP : https://github.co ...
- python 列表排序方法sort、sorted技巧篇
Python list内置sort()方法用来排序,也可以用python内置的全局sorted()方法来对可迭代的序列排序生成新的序列. 1)排序基础 简单的升序排序是非常容易的.只需要调用sorte ...
- 专访图书作者祁宇:C++11让程序更简洁、更现代、更强大
日前CSDN采访了祁宇,请他解读C++11的新标准.C++的现状以及未来的发展前景. CSDN:怎么会想到编写<深入应用C++11:代码优化与工程级应用>这本书的?有没有什么故事可以分享下 ...
- RNN,LSTM,GRU简单图解:
一篇经典的讲解RNN的,大部分网络图都来源于此:http://colah.github.io/posts/2015-08-Understanding-LSTMs/ 每一层每一时刻的输入输出:https ...