python各种模块,迭代器,生成器
从逻辑上组织python代码(变量,函数,类,逻辑:实现一个功能)
本质就是.py结尾的python文件(文件名:test.py,对应的模块名就是test)
包:用来从逻辑上组织模块的,本质就是一个目录(必须带有一个叫__init__.py文件),(package:包)
模块的分类
a.标准库(sys,os), lib 目录下(home 目录/pythonXX.XX/lib)
b.开源模块,第三方库, 在 lib 下的 site-packages 目录下
c.自定义模块
标准库:
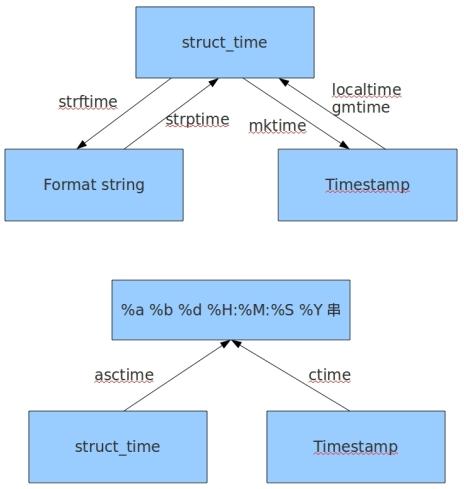
time
时间戳:timestamp(相对于1970.1.1 00:00:00至当前以秒计算,时间戳是惟一的):time.time()时间戳,time.sleep(),
格式化时间字符串:time.strftime('%Y-%m-%d %H:%M:%S'),time.strptime('1974-01-14 04:53:19','%Y-%m-%d %H:%M:%S')
元祖(struct_time)共九个元素:time.gmtime()把时间戳转换为UTC标准时间,time.localtime()把时间戳转换到本地时间UTC+8
time.mktime()把元祖形式装换为时间戳
python的time模块主要调用C库,所以各平台有所不同
UTC:世界标准时间,中国为UTC+8(比标准时间早8小时), DST:夏令时
print(time.gmtime(time.time()-86400))#将时间戳转化为struct_time,为UTC时间,与中国时间差8小时
print(time.strftime('%Y-%m-%d %H:%M:%S',time.gmtime()))#差8小时时间2018-05-26 14:20:54
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))#本地时间 x=time.localtime(1111999999)
print(x)
print(x.tm_year)
print('this is 2005 day :%d' %x.tm_yday) x=time.localtime(1111999999)
print(time.mktime(x)) x=time.localtime(1111999)
print(time.strftime('%Y-%m-%d %H:%M:%S',x))#返回本地时间,转化为字符串格式,展示:1970-01-14 04:53:19
print(time.strptime('1974-01-14 04:53:19','%Y-%m-%d %H:%M:%S'))#字符串转为时间对象,展示: time.struct_time(tm_year=1974, tm_mon=1, tm_mday=14, tm_hour=4, tm_min=53, tm_sec=19, tm_wday=0, tm_yday=14, tm_isdst=-1) print(time.asctime())#把元祖转换为格式化字符串
print(time.ctime())#把时间戳转换为格式化字符串,当前时间
print(time.ctime(time.time()-86400))#昨天时间 help(time)#帮助
help(time.gmtime())#帮助
Import datetime
print(datetime.date)#表示日期的类。常用的属性有year, month, day;
print(datetime.time)#表示时间的类。常用的属性有hour, minute, second, microsecond;
print(datetime.datetime.now())#当前日期时间
print(datetime.date.fromtimestamp(time.time() - 86400))#时间戳转化为日期格式
print(datetime.datetime.now()+datetime.timedelta(3))#当前时间+3天
print(datetime.datetime.now()+datetime.timedelta(-3)) #当前时间-3天
print(datetime.datetime.now()+datetime.timedelta(hours=-3))#当前时间+3小时
print(datetime.datetime.now()+datetime.timedelta(minutes=30))#当前时间+30分
print(datetime.datetime.now() + datetime.timedelta(weeks=1))#一周后
current_time = datetime.datetime.now()
print(current_time.replace(2018,5,2))#如指定日期就会替换当前日期,未指定输出当前日期
c_time = datetime.datetime.now()
print(c_time.replace(minute=3,hour=2)) #时间替换
格式参照
%a 本地(locale)简化星期名称
%A 本地完整星期名称
%b 本地简化月份名称
%B 本地完整月份名称
%c 本地相应的日期和时间表示
%d 一个月中的第几天(01 - 31)
%H 一天中的第几个小时(24小时制,00 - 23)
%I 第几个小时(12小时制,01 - 12)
%j 一年中的第几天(001 - 366)
%m 月份(01 - 12)
%M 分钟数(00 - 59)
%p 本地am或者pm的相应符 一
%S 秒(01 - 61) 二
%U 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。
%w 一个星期中的第几天(0 - 6,0是星期天)
%W 和%U基本相同,不同的是%W以星期一为一个星期的开始。
%x 本地相应日期
%X 本地相应时间
%y 去掉世纪的年份(00 - 99)
%Y 完整的年份
%Z 时区的名字(如果不存在为空字符)
%% ‘%’字符
时间关系转换
import random#(随机)
print (random.random())#生成一个0到1的随机符点数
print (random.randint(1,7)) #生成指定范围内的整数。
print (random.randrange(10,100,2)) #函数原型为:random.randrange([start], stop[, step])
# 从指定范围内,按指定基数递增的集合中 获取一个随机数
# random.randrange(10, 100, 2)在结果上与 random.choice(range(10, 100, 2) 等效。
print(random.choice('liukun')) #从序列中获取一个随机元素(选择)
# 其函数原型为:random.choice(sequence)。参数sequence表示一个有序类型,不是一种特定的类型,而是泛指一系列的类型
# 下面是使用choice的一些例子:list, tuple, 字符串,都属于sequence(顺序)
print(random.choice("学习Python"))
print(random.choice(["JGood","is","a","handsome","boy"]))
print(random.choice(("Tuple","List","Dict")))
print(random.sample([1,2,3,4,5,9],2))#(样品)
#函数原型为:random.sample(sequence, k),从指定序列中随机获取指定长度的片断,sample函数不会修改原有序列。
实际应用:
# 随机整数:
print(random.randint(0, 99)) # 随机选取0到100间的偶数:
print(random.randrange(0, 101, 2)) # 随机浮点数:
print(random.random())
print(random.uniform(1, 10))#( 规格一致的)
# 随机字符:
print(random.choice('abcdefg&#%^*f')) # 多个字符中选取特定数量的字符:
print(random.sample('abcdefghij', 3)) # 随机选取字符串:
print(random.choice(['apple', 'pear', 'peach', 'orange', 'lemon']))
# 洗牌#
items = [1, 2, 3, 4, 5, 6, 7]
print(items)
random.shuffle(items)(#洗牌)
print(items)
随机生成验证码
import random
checkcode=''#先定一个空的全局变量
for i in range(4):
current=random.randrange(0,4)#现在的
if current==i:
tmp=chr(random.randint(65,90))
else:
tmp=random.randint(0,9)
checkcode+=str(tmp)
print(checkcode) def ac(year):#判断一个年份是否为闰年
if year%4==0 and year%100!=0:
print('{}是瑞年'.format(year))
elif year%400==0:
print('{}是瑞年'.format(year))
else:
print('{}不是瑞年'.format(year))
ac(2020)
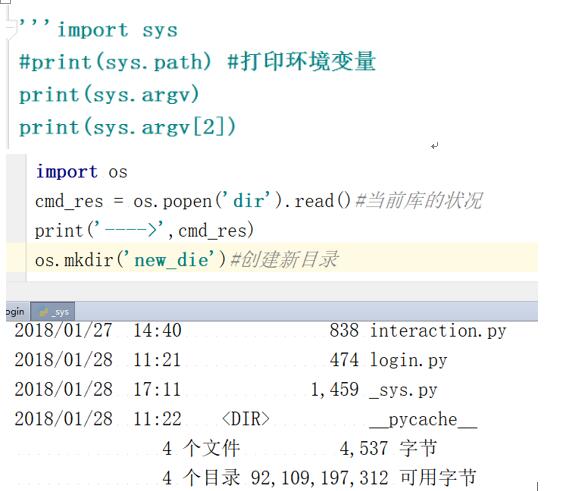
OS模块
import os#os模块系统级别的操作
print(os.getcwd())#类似Linux:pwd获取当前工作目录,即当前python脚本工作的目录路径
print(os.chdir(r"C:\Users"))#类似Linux:cd改变当前脚本工作目录,
print(os.chdir("C:\\Users\LLT\Desktop\python\第五周\module_test"))#同上
print(os.curdir)# 返回当前目录: ('.')
print(os.pardir)# 获取当前目录的父目录字符串名:('..')
print(os.makedirs(r"D:\Users\a\b\c"))#可生成多层递归目录
print(os.removedirs(r"D:\Users\a\b\c"))# 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
print(os.mkdir(r'D:a'))#生成单级目录;相当于shell中mkdir
print(os.rmdir(r'D:a'))#删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir
print(os.listdir('..'))# 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
print(os.remove())# 删除一个文件
print(os.rename("oldname","newname"))#重命名文件/目录
print(os.stat(r'D:a'))#获取文件/目录信息,加.st_size可以获取大小
print(os.sep)#重要 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
print(os.linesep)#重要 win下为"\r\n",Linux下为"\n"
print(os.pathsep)#重要 输出用于分割文件路径的字符串,win下为";",Linux下为":"
print(os.name)#输出字符串指示当前使用平台,win->'nt'; Linux->'posix'
print(os.system("ipconfig /all"))#运行shell命令,直接显示
print(os.environ)# 获取系统环境变量,(包围)
print(os.path.abspath('Path'))#返回path规范化的绝对路径
print(os.path.split('D:\LAMP.docx'))#将path分割成目录和文件名二元组返回
print(os.path.dirname('D:\LAMP.docx'))#返回path的目录。其实就是os.path.split(path)的第一个元素
print(os.path.basename('D:\LAMP.docx'))#返回path最后的文件名,如果path以/或\结尾,那么就会返回空值,即os.path.split(path)的第二个元素(就是文件名)
print(os.path.exists('path'))#如果path存在,返回True;如果path不存在,返回False
print(os.path.isabs('path'))#如果path是绝对路径,返回True,否则返回False,win->r'c:\a绝对',r'a相对'; Linux->r'/a/b绝对'win有多个根目录,Linux只有一个/为根目录
print(os.path.isfile('path'))#如果path是一个存在的文件,返回True,否则返回False
print(os.path.isdir('path'))#如果path是一个存在的目录,则返回True。否则返回False
print(os.path.join(r'c:',r'\a',r'\b'))#将多个路径组合后返回,第一个绝对路径之前的参数将被忽略,输出:c:\b
print(os.path.getatime('D:\\a'))#返回path所指向的文件或者目录的最后存取时间
print(os.path.getmtime('D:\\a'))#返回path所指向的文件或者目录的最后修改时间
创建目录函数:
import os# 引入模块
def mkdir(path):
path = path.strip()# 去除首位空格
path = path.rstrip("\\")# 去除尾部 \ 符号
isExists = os.path.exists(path)#判断一个目录是否存在,存在True,不存在False
if not isExists:# 判断结果
os.makedirs(path)# 创建目录操作函数,无父目录会自动创建父目录,创建多层目录
#os.mkdir(path)#创建目录操作函数,无父目录会提示路径不存在,创建目录
print (path + ' 创建成功')# 如果不存在则创建目录
return True
else:
print( path + ' 目录已存在')# 如果目录存在则不创建,并提示目录已存在
return False
mkpath = "E:\\test\\web2\\"# 定义要创建的目录
mkdir(mkpath)# 调用函数
Sys模块
import sys#解释器相关的模块
print(sys.argv)#命令行参数List,第一个元素是程序本身路径
print(sys.exit())#退出程序,正常退出时exit(0),exit(‘goodbye’)可以传值
print(sys.version)#获取Python解释程序的版本信息
print(sys.maxint)#最大的Int值,py2.7
print(sys.path)#返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
print(sys.platform)#返回操作系统平台名称
sys.stdout.write('please:') #sys模块下的标准输出
sys.stdin.readline()#文本输入
hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
哈希算法存,取之所以快,是因为其直接通过关键字key得到要存取的记录内存存储地址,从而直接对该地址进行读或写。
MD5
import hashlib
m = hashlib.md5()
m.update(b"Hello")#b :bytes 类型
print(m.hexdigest())#加密后16进制格式hash, #2进制格式hash
m.update("It's me你好".encode(encoding=‘utf-8’))#加汉字需加encode
print(m.hexdigest())#打印Hello加It's me的16进制,如下M2例子
m.update(b"It's been a long time")
print(m.hexdigest())#打印Hello加It's me加It's been a long time的16进制,如下M3例子 m = hashlib.md5(bytes('dsad232',encoding='utf-8'))
m.update(bytes("Hello",encoding='utf-8'))
print(m.hexdigest())#使用这种方法(dsad232)对Hello二次加密(加严),推荐使用这种方法 m2 = hashlib.md5()
m2.update(b"HelloIt's me")
print(m2.hexdigest()) m3 = hashlib.md5()
m3.update(b"HelloIt's meIt's been a long time")
print(m3.hexdigest())
Sha1
s2=hashlib.sha1()#SSL证书的sha1已被淘汰,通用sha256()
s2.update(b"HelloIt's me")
print(s2.hexdigest())
Sha256
hash = hashlib.sha256()
hash.update(b"HelloIt's me")
print(hash.hexdigest())
Sha384
hash = hashlib.sha384()
hash.update(b"HelloIt's me")
print(hash.hexdigest())
Sha512
hash = hashlib.sha512()
hash.update(b"HelloIt's me")
print(hash.hexdigest())
MD5实现加密登录注册 import hashlib def md5(args):
ooo = hashlib.md5(bytes('dsfdsfsds',encoding='utf-8'))
ooo.update(bytes(args,encoding='utf-8'))
return ooo.hexdigest() def login(user,pwd):
with open('db','r',encoding='utf-8') as f:
for line in f:
u,p = line.strip().split('|')
if u == user and p == md5(pwd):
return True def register(user,pwd):
with open('db','a',encoding='utf-8') as f:
temp = user + '|' + md5(pwd)
f.write(temp) i = input('1,登录: 2,注册:')
if i == '':
user = input('用户名:')
pwd = input('密码:')
register(user,pwd)
elif i == '':
user = input('用户名:')
pwd = input('密码')
r = login(user,pwd)
if r:
print('登录成功')
else:
print('登录失败 ')
shutil模块
高级的 文件、文件夹、压缩包 处理模块
import shutil
f1=open('本节笔记',encoding='utf-8')
f2=open('笔记2','w',encoding='utf-8')
import shutil
shutil.copyfileobj(open('xo.xml', 'r'), open('new.xml', 'w'))# 将文件内容拷贝到另一个文件中
shutil.copyfileobj(f1,f2)#将文件内容拷贝到另一个文件中,可以部分内容
shutil.copyfile('笔记2','笔记3')#拷贝文件,笔记2拷贝到笔记3
shutil.copymode('笔记2','笔记3')#仅拷贝权限,内容、组、用户均不变
shutil.copystat('本节笔记','笔记3')#拷贝状态的信息,包括:mode bits, (atime访问时间), (mtime其时), (flags标示)
shutil.copy('笔记2','笔记3')#拷贝文件和权限
shutil.copy2('笔记2','笔记3')#拷贝文件和状态信息
shutil.copytree('test4','new_test4')#递归的去拷贝文件
shutil.rmtree('new_test4')#递归的去删除文件
shutil.move()#递归的去移动文件
shutil.make_archive('shutil_archive_test','zip','path路径')#创建压缩包并返回文件路径,例如:zip、tar
import zipfile#shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的
z=zipfile.ZipFile('day5.zip','w')#压缩
z.write('p_test.py')
print('-------')
z.write('笔记2')
z.close() z = zipfile.ZipFile('day5.zip', 'r')# 解压
z.extractall()
z.close()
shelve模块
import shelve
#shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
import datetime
d = shelve.open('shelve_test') # 打开一个文件
info={'age':22,'job':'it'}
name = ["alex", "rain", "test"]
d["name"] = name # 持久化列表
d["info"] = info # 持久化字典
d["date"] =datetime.datetime.now()
d.close() print(d.get('name'))#生成之后重新读取
print(d.get('info'))#生成之后重新读取
print(d.get('date'))#生成之后重新读取
模块追加:
'''
我是注释
'''
print(__doc__)#打印py文件的注释
print(__file__)#打印本身自己的路径
from 第一天.abc import bcd
print(bcd.__package__)#py文件所在的文件夹,当前文件为none,导入其它文件用.划分,输出:第一天.abc
print(bcd.__cached__)#缓冲
print(__name__)#执行文件会输出__main__,用在调用程序的入口,
print(bcd.__name__)#输出文件夹一级一级的路劲
# 执行文件时 __name__ == '__main__'执行程序,否则执行模块
#如果导入bcd模块的话name就不等于main就不执行下面的
主文件调用主函数时,必须增加判断,执行主函数if __name__ == '__main__':
bcd.foo() import os
import sys
#__file__获取绝对路径,使用os.path.join/os.path.dirname拼接两个路径
p1 = os.path.dirname(__file__)
p2 = 'lib'
mk_dir = os.path.join(p1,p2)
sys.path.append(mk_dir) __loader__#解释器加载,系统使用
__builtins__#放置所有内置函数
json与pickle模块数据序列化
json是所有语言都通用的,支持不同语言之间数据交互(如list、tuple、dict和string),只能处理简单的因为是跨语言的。 eval()函数将字符串转成相应的对象(如list、tuple、dict和string之间的转换) 也可利用反引号转换的字符串再反转回对象
>>> a = "[[1,2], [3,4], [5,6], [7,8], [9,0]]"
>>> b = eval(a)
>>> b
[[1, 2], [3, 4], [5, 6], [7, 8], [9, 0]] 在程序的运行过程中,所有的变量都是在内存中,变量在内存中来得快也去得快,需要将内存中的变量转化为可存储的对象或者可传输的对象,这样的过程就叫做序列化。
Python中提供了pickle模块来实现对象的序列化与反序列化,pickle.dumps()将任意的对象序列化成一个bytes。pickle.loads()实现反序列化,得到对象。
Json序列化
import json info={
'name':'zc',
'age':29,
}
f=open('test.txt','w')
f.write(json.dumps(info))#【废物】,将python基本数据类型装换为字符串
f.close() s = ['zc','zc1','zc2']
s1 = json.dumps(s)
print(s1,type(s))#输出:["zc", "zc1", "zc2"] <class 'str'>
Json反序列化
import json
f=open('test.txt','r')
data=json.loads(f.read())#【负载】,用于将字典,列表,元祖形式的字符串转换成相应的字典列表元祖
print(data['age']) s = '{"desc":"nihao","avg":20}'#注意单双引号
re = json.loads(s)
print(re,type(re)) Python内置的json模块提供了完备的Python对象到JSON格式的转换。将Python对象变为一个JSON:
"""
利用json模块序列化与反序列化
"""
import json
di = dict(name='BOb', age=20, score=93) >>> json.dumps(di)
'{"name": "BOb", "age": 20, "score": 93}' 同理,将JSON反序列化为Python对象:
json_str = '{"name": "BOb", "age": 20, "score": 93}' >>> json.loads(json_str)
{'score': 93, 'name': 'BOb', 'age': 20}
Pickle序列化
(只可以在python中使用)它可以序列化任何对象并保存到磁盘中,并在需要的时候读取出来, 功能比json强大
import pickle
def sayhi(name):
print('hello',name)
info={
'name':'zc',
'age':29,
'func':sayhi
}
f=open('test.txt','wb')
f.write(pickle.dumps(info))#【腌菜】 完全等于 pickle.dump(info,f)
f.close()
Pickle反序列化
import pickle
def sayhi(name):
print('hello',name) f=open('test.txt','rb')
data=pickle.loads(f.read())#【负载】 完全等于 data=pickle.load(f)
print(data['func']('zc'))
Pickle模块最常用函数:
(1)pickle.dump(obj, file, [,protocol])
函数的功能:将obj对象序列化存入已经打开的file中。
· obj:想要序列化的obj对象。
· file:文件名称。
· protocol:序列化使用的协议。如果该项省略,则默认为0。如果为负值或HIGHEST_PROTOCOL,则使用最高的协议版本。
(2)pickle.load(file)
函数的功能:将file中的对象序列化读出。
参数讲解:
· file:文件名称。
(3)pickle.dumps(obj[, protocol])
函数的功能:将obj对象序列化为string形式,而不是存入文件中。
· obj:想要序列化的obj对象。
· protocal:如果该项省略,则默认为0。如果为负值或HIGHEST_PROTOCOL,则使用最高的协议版本。
(4)pickle.loads(string)
函数的功能:从string中读出序列化前的obj对象。
· string:文件名称。
【注】 dump() 与 load() 相比 dumps() 和 loads() 还有另一种能力:dump()函数能一个接着一个地将几个对象序列化存储到同一个文件中,2.5里面调用load()来以同样的顺序反序列化读出这些对象。3.0里面只能load()一次。写程序最好dump()一次load()一次。
第三方模块安装:
# 第三方模块按装方法:
# 1.软件管理工具 pip3,安装pip3依赖于setuptools,需先安装它,py3自带有pip3,将增加环境变量E:\Python36\Scripts,
# pip3 install requests
# 2.源码安装 下载源码安装
#下载源码>解压>进入win终端目录>执行python setup.py
install
Requests
import requests#发送http请求,获取请求返回值(用py模拟浏览器浏览网页)
response = requests.get('https://www.hao123.com/')
response.encoding = 'utf-8'
result = response.text #返回内容
print(result)
判断qq是否在线:
import requests #使用第三方模块requests发送http请求,或者XML格式内容(局部xml内容)
"""
该程序依赖于QQ的端口程序
返回数据:String,Y = 在线;N = 离线;E = QQ号码错误;A = 商业用户验证失败;V = 免费用户超过数量
"""
url0 = 'http://www.webxml.com.cn/webservices/qqOnlineWebService.asmx/qqCheckOnline?qqCode='
url1 = input('请输入QQ号码:')
url = url0 + str(url1)
r = requests.get(url)
result = r.text #字符串类型
print(result) from xml.etree import ElementTree as ET
# 解析XML格式内容
# XML接收一个参数,字符串, 格式化为特殊的对象
node = ET.XML(result)
#获取内容
if node.text == 'Y':
print('在线')
elif node.text == 'N':
print('离线')
elif node.text == 'E':
print('QQ号码错误')
elif node.text == 'A':
print('商业用户验证失败')
else:
print('免费用户超过数量')
获取列车时刻表:
import urllib
import requests
from xml.etree import ElementTree as ET # 使用内置模块urllib发送HTTP请求,或者XML格式内容(局部xml内容) # f = urllib.request.urlopen('http://www.webxml.com.cn/WebServices/TrainTimeWebService.asmx/getDetailInfoByTrainCode?TrainCode=G666&UserID=')
# result = f.read().decode('utf-8') # 使用第三方模块requests发送HTTP请求,或者XML格式内容(局部xml内容)
r = requests.get('http://www.webxml.com.cn/WebServices/TrainTimeWebService.asmx/getDetailInfoByTrainCode?TrainCode=k448&UserID=')
result = r.text
# 解析XML格式内容
root = ET.XML(result)
for node in root.iter('TrainDetailInfo'):#iter迭代循环所有内容中的TrainDetailInfo
# print(node.tag, )#获取头部
# print(node.attrib)#获得整个属性
print(node.find('TrainStation').text,node.find('StartTime').text)
Xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,在json还没出现时,只能选择用xml,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式代码如下,就是通过<>节点来区别数据结构的
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
</data> import xml.etree.ElementTree as ET
tree=ET.parse('Xml模块.xml')
root=tree.getroot()
print(root.tag)#打印开头标签内存地址 for child in root:#遍历xml文档
print(child.tag,child.attrib)#打印开头标签属性
for i in child:
print(i.tag,i.text) for node in root.iter('year'):#只遍历year节点
print(node.tag,node.text) import xml.etree.ElementTree as ET
tree = ET.parse("xml模块.xml")
root = tree.getroot()
修改 for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated_by", "zc")#修改的是内存数据,需要重新创建文件写入
tree.write("xml模块.xml")
删除 for country in root.findall('country'):#root.findall可以找出所有country
rank = int(country.find('rank').text)#判断country下的rank
if rank > 50:#
root.remove(country)
tree.write('output.xml')
创建
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")#根节点
personinfo = ET.SubElement(new_xml, "personinfo", attrib={"enrolled": "yes"})#personinfo为new_xml子节点,节点名:name,属性:attrib
name = ET.SubElement(personinfo,'name')
name.text='zc'
age = ET.SubElement(personinfo, "age", attrib={"checked": "no"})#age为personinfo的子节点,其它同上
sex = ET.SubElement(personinfo, "sex")#同上
age.text = ''#age赋值
personinfo2 = ET.SubElement(new_xml, "personinfo2", attrib={"enrolled": "no"})
name = ET.SubElement(personinfo2,'name')
name.text='zc1'
age = ET.SubElement(personinfo2, "age")
age.text = ''
et = ET.ElementTree(new_xml) # 生成文档对象
et.write("test.xml", encoding="utf-8", xml_declaration=True)#xml_declaration声明为xml格式
ET.dump(new_xml) # 打印生成的格式 from xml.etree import ElementTree as ET
############ 解析方式一 ############
str_xml = open('xo.xml', 'r').read()# 打开文件,读取XML内容
root = ET.XML(str_xml)# 将字符串解析成xml特殊对象,root代指xml文件的根节点 ############ 解析方式二 ############
# 直接解析xml文件
tree = ET.parse("xo.xml")# 获取xml文件的根节点
root = tree.getroot()### 操作
print(root.tag)# 顶层标签
for node in root.iter('year'):# 遍历XML中所有的year节点
print(node.tag, node.text)# 节点的标签名称和内容 from xml.etree import ElementTree as ET#etree文件夹
tree = ET.parse('xo.xml')#直接解析xml文件
# ####### 一切皆对象 #########
#对象都由类创建,对象的所有功能都在与其相关的类中
#tree
#1.ElementTree类创建
#2.getroot()获取xml跟节点
#3.write()内存中的xml写入文件中
root = tree.getroot()#或许xml文件根节点,Element类型
#Element类创建的对象
#print(root.tag)
#print(root.attrib)
#print(root.text)
# ##########方式1###########
# son = root.makeelement('tt',{'kk':'vv'})#创建节点Element类型
# s = son.makeelement('tt',{'kk':'123'})
# ##########方式2###########
son = ET.Element('tt',{'kk':'十一'})
ele2 = ET.Element('tt',{'kk':''})#里面的数字必须带引号
# ##########方式3(可以直接保存写入)###########
'''
ET.SubElement(root,'family',{'age':'19'})
son = ET.SubElement(root,'family',{'age':'11'})
ET.SubElement(son,'family',{'age':'十一'})
'''
son.append(ele2)
root.append(son)
tree.write('out.xml',encoding='utf-8',xml_declaration=True)#使用tree.write保存写入,编码格式,申明 常用的几种属性:
# tag # attrib # find # iter # set # get #text
带缩进的xml格式:
from xml.etree import ElementTree as ET
from xml.dom import minidom#带缩进的xml
def prettify(elem):
"""将节点转换成字符串,并添加缩进。
"""
rough_string = ET.tostring(elem, 'utf-8')
reparsed = minidom.parseString(rough_string)
return reparsed.toprettyxml(indent="\t")
root = ET.Element("famliy")# 创建根节点
# 创建大儿子
# son1 = ET.Element('son', {'name': '儿1'})
son1 = root.makeelement('son', {'name': '儿1'}) # 创建小儿子
# son2 = ET.Element('son', {"name": '儿2'})
son2 = root.makeelement('son', {"name": '儿2'}) # 在大儿子中创建两个孙子
# grandson1 = ET.Element('grandson', {'name': '儿11'})
grandson1 = son1.makeelement('grandson', {'name': '儿11'})
# grandson2 = ET.Element('grandson', {'name': '儿12'})
grandson2 = son1.makeelement('grandson', {'name': '儿12'})
son1.append(grandson1)
son1.append(grandson2)
# 把儿子添加到根节点中
root.append(son1)
root.append(son1)
raw_str = prettify(root)
f = open("xxxoo.xml",'w',encoding='utf-8')
f.write(raw_str)
f.close()
ymal模块
Python也可以很容易的处理ymal文档格式,只不过需要安装一个模块(python 。。。 install),然后导入from yaml import load, dump
主要用来做配置文件的
Configparser模块
用于生成和修改常见配置文档
写入
import configparser#py2里面ConfigParser
config = configparser.ConfigParser()#调configparser对象进来
config["DEFAULT"] = {'ServerAliveInterval': '',#第一个节点
'Compression': 'yes',
'CompressionLevel': ''} config['bitbucket.org'] = {}#第二个节点
config['bitbucket.org']['User'] = 'hg' config['topsecret.server.com'] = {}#第三个节点
config['topsecret.server.com']
config['topsecret.server.com']['Host Port'] = ''
config['topsecret.server.com']['ForwardX11'] = 'no' config['DEFAULT']['ForwardX11'] = 'yes'#第一个节点增加 with open('example.ini', 'w') as configfile:#写入
config.write(configfile)
读取
import configparser
conf=configparser.ConfigParser()
conf.read('example.ini')
print(conf.defaults())
print(conf.sections())
print(conf['bitbucket.org']['User'])
for key in conf['bitbucket.org']:#循环读出来
print(key)
删
sec = conf.remove_section('bitbucket.org')
conf.write(open('example.cfg', "w"))
增
sec = conf.add_section('zc1')#增加
conf.write(open('example.cfg', "w"))
获取所有节点:
import configparser
config = configparser.ConfigParser()
config.read('xxxooo', encoding='utf-8')
ret = config.sections()
print(ret)
获取指定节点下所有键值对:
config = configparser.ConfigParser()
config.read('xxxooo', encoding='utf-8')
ret = config.items('section1')
print(ret)
获取指定节点下所有的键:
config = configparser.ConfigParser()
config.read('xxxooo', encoding='utf-8')
ret = config.options('section1')
print(ret)
获取指定节点下指定key值
config = configparser.ConfigParser()
config.read('xxxooo', encoding='utf-8')
v = config.get('section1', 'k1')
print(v)
检查节点是否存在
config = configparser.ConfigParser()
config.read('xxxooo', encoding='utf-8')
has_sec = config.has_section('section1')
print(has_sec)#返回True
hmac模块
散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别密钥K来鉴别消息的真伪;一般用于网络通信中消息加密,前提是双方先要约定好key,就像接头暗号一样,然后消息发送把用key把消息加密,接收方用key + 消息明文再加密,哪加密后的值 跟 发送者的相对比是否相等,这样就能验证消息的真实性,及发送者的合法性了。
import hmac
s2 =hmac.new(b"","我放假".encode(encoding="utf-8"))#可以运行 并顺利加密,
s2 =hmac.new(b"jkhj","我放假".encode(encoding="utf-8"))#可以运行并顺利加密
s2 =hmac.new("网址之王".encode(encoding="utf-8"))#可以运行 并且顺利加密
s2 =hmac.new("网址之王","我放假".encode(encoding="utf-8")) #不可以运行 出错
print(s2.hexdigest())#py3.6为演示成功
subprocess模块
import subprocess#用于python执行系统命令
ret = subprocess.call('ipconfig')#执行命令返回状态码
ret = subprocess.check_output('ipconfig')#执行命令如果是0返回执行结果,否则抛异常
print(ret)
logging模块
import logging
logging.basicConfig(filename='log.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=logging.INFO,)
'''
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0
'''
logging.debug('debug')
logging.info('info')
logging.warning('warning')
logging.error('error')
logging.critical('critical')
logging.log(logging.INFO,'log')
注:只有【当前写等级】大于【日志等级】时,日志文件才被记录。 日志记录在多个文件中:
定义文件
import logging
file_1_1 = logging.FileHandler('l1_1.log', 'a', encoding='utf-8')
fmt = logging.Formatter(fmt="%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s")
file_1_1.setFormatter(fmt)
file_1_2 = logging.FileHandler('l1_2.log', 'a', encoding='utf-8')
fmt = logging.Formatter()
file_1_2.setFormatter(fmt)
# 定义日志
logger1 = logging.Logger('s1', level=logging.ERROR)
logger1.addHandler(file_1_1)
logger1.addHandler(file_1_2)
# 写日志
logger1.critical('')
迭代器与生成器
Generator 生成器,
生成器:1.只有在调用的时候才会生成相应的数据,调用哪次就生成哪次,2.只记录当前位置,3.只有一个_next_()调用下一次方法,py2是next()方法
列表生成式使代码更简洁
m=[i*2 for i in range(10)]
print (m) a=[]#这个要三行
for i in range(10):
a.append(i*2)
print (a) b=(i*2 for i in range(10))
for i in b:
print(i)
生成器
生成器函数(函数内部有yield关键字)yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次从它离开的地方继续执行
生成器小结:
1.是可迭代对象
2.实现了延迟计算,省内存
3.生成器本质和其他的数据类型一样,都是实现了迭代器协议,只不过生成器附加了一个延迟计算省内存的好处,其余的可迭代对象可没有这点好处! 通过函数做的一个生成器
def fib(max):
n,a,b=0,0,1
while n<max:
yield b # (带有yield为生成器)
a,b=b,a+b
n=n+1
f=fib(10)
print(f.__next__())
print('------')#可以让程序想进想出,随时停止的优点
print(f.__next__())
print('++++++')
print(f.__next__())
for i in f:#循环打印后面的数据
print (i)
抓取异常
def fib(max):
n,a,b=0,0,1
while n<max:
yield b#保存了函数的中断状态
a,b=b,a+b
n=n+1
return 'done'#生成器不需要带return,打印异常消息的时候需要带
f=fib(6)
while True:
try:
x=next(f)#内置的方法,下一个。和这个_next_()意思一样,
print('f:',x)
except StopIteration as e:
print('value:',e.value)
break def range(n):
start = 0
while True:
if start >n:
return
yield start
start += 1
obj = range(5)
n1 = obj.__next__()#生成器的__next__方法,执行函数寻找下一个yield
n2 = obj.__next__()#obj叫做生成器,具有生成能力
n3 = obj.__next__()
n4 = obj.__next__()
n5 = obj.__next__()
n6 = obj.__next__()
print(n1,n2,n3,n4,n5,n6) 单线程下的并行(也叫协程)
线程包含于进程,协程包含于线程。只要内存足够,一个线程中可以有任意多个协程,但某一时刻只能有一个协程在运行,多个协程分享该线程分配到的计算机资源。
import time
def consumer(name):#消费者
print('%s 准备吃包子'%name)
while True:
baozi=yield
print('包子[%s]来了,被[%s]吃了'%(baozi,name)) c=consumer('zhangchao')
c.__next__()
b1='肉包子'
c.send(b1)#唤醒生成器并传值给它
c.__next__() def producer(name):#生产者
c=consumer('A')
c2=consumer('B')
c.__next__()
c2.__next__()
print('生产包子')
for i in range(10):
time.sleep(1)
print('做了2个包子')
c.send(i)
c2.send(i)
producer('zc')
迭代器
1.迭代需要重复进行某一操作,
2.本次迭代的要依赖上一次的结果继续往下做,如果中途有任何停顿,都不能算是迭代.
迭代器优点:
1.节约内存,2.不依赖索引取值,3.实现惰性计算(什么时候需要,在取值出来计算) # 非迭代,仅仅只是在重复一件事结果并不依赖上一次出的值
count = 0
while count < 10:
print("hello world")
count += 1
# 迭代,重复+继续
count = 0
while count < 10:
print(count)
count += 1
# from collections import Iterable #收集,可迭代的
# isinstance()#判断一个对象是否是Iterable对象
# isinstance([],Iterable)
# isinstance({},Iterable)
# isinstance('ABC',Iterable)
# isinstance(100,Iterable)#整数不是可迭代对象 #可以直接作用于for循环的数据类型
# 1.集合数据类型:list,tuple,dict,set,str等
# 2.generator,包括生成器和带yield的generator function
# 可作用于for循环的对象统称为可迭代对象 #生成器可以作用于for循环,还可以被_next_()函数不断调用并返回下一个值,直到抛出StopIteration 无法继续返回下一个值
#可以被_next_()函数调用并不断返回下一个值得对象称为迭代器,Iterator,迭代器,有_next_()方法才称为迭代器
#生成器是迭代器因为它有_next_()方法,迭代器不一定是生成器
#生成器是Iterator对象,但list,dict,str虽然是Iterable,却不是Iterator。
#把list,dict,str等Iterable变成Iterator可以使用iter()函数。》内置函数
#python的迭代器对象是一个数据流(有序序列),可以被next()函数调用不断返回下一个数据,直到没有数据的时候抛出StopIteration
#错误,提前不知道序列长度,只能通过next()函数按需计算下一个数据,迭代器计算是惰性(走到这一步才计算)的,只有在需要返回
# 下一个数据时它才会计算,
#迭代器可以表示一个无限大数据流,如全体自然数,list是由开头结尾的不可能存储全体自然数
#作用于for循环的对象是Iterable类型
#作用于next()函数的对象是Iterator类型,表示一个惰性计算序列 #isinstance(iter([]),Iterator)
#isinstance(iter('abc'),Iterator) it=iter([1,2,3,4,5])
while True:
try:
x=next(it)
except StopIteration:
break
print (x) a=[1,2,3]
print (dir(a))#查看所有调用方法 from collections import Iterator
print (isinstance((x for x in range(5)),Iterator))#生成器,生成器本身就是迭代器
高级的 文件、文件夹、压缩包 处理模块
import shutil
f1=open('本节笔记',encoding='utf-8')
f2=open('笔记2','w',encoding='utf-8')
import shutil
shutil.copyfileobj(open('xo.xml', 'r'), open('new.xml', 'w'))# 将文件内容拷贝到另一个文件中
shutil.copyfileobj(f1,f2)#将文件内容拷贝到另一个文件中,可以部分内容
shutil.copyfile('笔记2','笔记3')#拷贝文件,笔记2拷贝到笔记3
shutil.copymode('笔记2','笔记3')#仅拷贝权限,内容、组、用户均不变
shutil.copystat('本节笔记','笔记3')#拷贝状态的信息,包括:mode bits, (atime访问时间), (mtime其时), (flags标示)
shutil.copy('笔记2','笔记3')#拷贝文件和权限
shutil.copy2('笔记2','笔记3')#拷贝文件和状态信息
shutil.copytree('test4','new_test4')#递归的去拷贝文件
shutil.rmtree('new_test4')#递归的去删除文件
shutil.move()#递归的去移动文件
shutil.make_archive('shutil_archive_test','zip','path路径')#创建压缩包并返回文件路径,例如:zip、tar
import zipfile#shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的
z=zipfile.ZipFile('day5.zip','w')#压缩
z.write('p_test.py')
print('-------')
z.write('笔记2')
z.close()
z = zipfile.ZipFile('day5.zip', 'r')# 解压
z.extractall()
z.close()
python各种模块,迭代器,生成器的更多相关文章
- python杂记-4(迭代器&生成器)
#!/usr/bin/env python# -*- coding: utf-8 -*-#1.迭代器&生成器#生成器#正确的方法是使用for循环,因为generator也是可迭代对象:g = ...
- python中的迭代器&&生成器&&装饰器
迭代器iterator 迭代器是访问集合元素的一种方式.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束. 迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退.另外, ...
- python装饰器,迭代器,生成器,协程
python装饰器[1] 首先先明白以下两点 #嵌套函数 def out1(): def inner1(): print(1234) inner1()#当没有加入inner时out()不会打印输出12 ...
- python基础6 迭代器 生成器
可迭代的:内部含有__iter__方法的数据类型叫可迭代的,也叫迭代对象实现了迭代协议的对象 运用dir()方法来测试一个数据类型是不是可迭代的的. 迭代器协议是指:对象需要提供next方法,它要么返 ...
- Python入门之迭代器/生成器/yield的表达方式/面向过程编程
本章内容 迭代器 面向过程编程 一.什么是迭代 二.什么是迭代器 三.迭代器演示和举例 四.生成器yield基础 五.生成器yield的表达式形式 六.面向过程编程 ================= ...
- python中的迭代器 生成器 装饰器
什么迭代器呢?它是一个带状态的对象,他能在你调用next()方法的时候返回容器中的下一个值,任何实现了__iter__和__next__()(python2中实现next())方法的对象都是迭代器,_ ...
- Python函数系列-迭代器,生成器
一 迭代器 一 迭代的概念 #迭代器即迭代的工具,那什么是迭代呢?#迭代是一个重复的过程,每次重复即一次迭代,并且每次迭代的结果都是下一次迭代的初始值 while True: #只是单纯地重复,因而不 ...
- Python学习 :迭代器&生成器
列表生成式 列表生成式的操作顺序: 1.先依次来读取元素 for x 2.对元素进行操作 x*x 3.赋予变量 Eg.列表生成式方式一 a = [x*x for x in range(10)] pri ...
- python第四周迭代器生成器序列化面向过程递归
第一节装饰器复习和知识储备------------ 第一节装饰器复习和知识储备------------ def wrapper(*args,**kwargs): index(*args,**kwa ...
随机推荐
- Java知多少(94)键盘事件
键盘事件的事件源一般丐组件相关,当一个组件处于激活状态时,按下.释放或敲击键盘上的某个键时就会发生键盘事件.键盘事件的接口是KeyListener,注册键盘事件监视器的方法是addKeyListene ...
- Why you should use async tasks in .NET 4.5 and Entity Framework 6
Improve response times and handle more users with parallel processing Building a web application usi ...
- Springboot学习笔记(二)-定时任务
springboot中要使用定时任务需要在配置类或启动类上标注注解@EnableScheduling,并在定时执行的无参方法上标注注解@Scheduled,程序启动后会根据@Scheduled所提供的 ...
- [UFLDL] Linear Regression & Classification
博客内容取材于:http://www.cnblogs.com/tornadomeet/archive/2012/06/24/2560261.html Deep learning:六(regulariz ...
- [Bayes] Improve HMM step by step
以下是HMM,当emission probability变为高斯时,只需改变其中相关部分即可,也就是下图最后一行. 如下可见,在优化过程中套路没有太大的影响,但变为高斯后表达变得更精确了呢. 当然,这 ...
- oracle 学习笔记(2)创建表空间及用户授权
原文:http://www.cnblogs.com/smartvessel/archive/2009/07/06/1517690.html Oracle安装完后,其中有一个缺省的数据库,除了这个缺省的 ...
- 【netcore基础】MVC API接口权限控制Attribute
效果: 通过Attribute来简单控制某个方法的访问权限 例如: 下面api只能角色id是[001,002,999]的登录用户才能访问 /// <summary> /// 管理用户列表 ...
- 【问题集】redis.clients.jedis.exceptions.JedisDataException: ERR value is not an integer or out of range
redis.clients.jedis.exceptions.JedisDataException: ERR value is not an integer or out of range incrm ...
- 用CSS里的 viewport-fit 标签应对iPhone X 的刘海
iPhone X 配备一个覆盖整个手机的全面屏,顶部的“刘海”为相机和其他组件留出了空间.然而结果就是会出现一些尴尬的情景:网站被限制在一个“安全区域”,在两侧边缘会出现白条儿.移除这个白条儿也不难, ...
- [JavaScript] 配置JavaScript BUILD
<project name="eForm" default="concatenate"> <tstamp> <format pro ...