python 全栈开发,Day14(列表推导式,生成器表达式,内置函数)
一、列表生成式
生成1~100的列表
li = []
for i in range(1,101):
li.append(i) print(li)
执行输出:
[1,2,3...]
生成python1期~11期
li = []
for i in range(1,12):
li.append('python'+str(i)+'期') print(li)
执行输出:
['python1期', 'python2期', 'python3期'...]
第二种写法
li = []
for i in range(1,12):
li.append('python%s' % i)
print(li)
执行输出,效果同上
上面的代码,可以一行搞定
用列表推导式就可以了
用列表推导式能构建的任何列表,用别的都可以构建,比如for循环
特点:
1.一行,简单,感觉高端,但是不易排错
使用debug模式,没法依次查看每一个值。
第一个例子
li = [i for i in range(1,101)]
print(li)
第二个例子
li = ['python%s期' %i for i in range(1,12)]
print(li)
循环模式
[经过加工的i for i in 可迭代对象]
比如python1期~python12期,是加工的
也可以不加工,比如1~100
1~10平方结果
li = [i ** 2 for i in range(1,11)]
print(li)
执行输出:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
筛选模式
[经过加工的i for i in 可迭代对象 if 条件 筛选]
30以内所有能被3整除的数
l3 = [i for i in range(1,31) if i % 3 == 0]
print(l3)
执行输出:
[3, 6, 9, 12, 15, 18, 21, 24, 27, 30]
30以内所有能被3整除的数的平方
li = [i**2 for i in range(1,31) if i % 3 == 0]
print(li)
执行输出:
[9, 36, 81, 144, 225, 324, 441, 576, 729, 900]
找到嵌套列表中名字含有两个'e'的所有名字
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],
['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
l4 = [name for i in names for name in i if name.count('e') == 2 ]
print(l4)
执行输出:
['Jefferson', 'Wesley', 'Steven', 'Jennifer']
列表推导式,最多不超过3个for循环
判断只能用一个
常用的是列表推导式
字典推导式
将一个字典的key和value对调
mcase = {'a': 10, 'b': 34}
mcase_frequency = {mcase[k]: k for k in mcase}
print(mcase_frequency)
执行输出:
{10: 'a', 34: 'b'}
相当于
mcase = {'a': 10, 'b': 34}
mcase_frequency = {}
for k in mcase:
mcase_frequency[k]=mcase[k]
print(mcase_frequency)
执行效果同上!
如果Key和value是一样的,不适合上面的代码
集合推导式
计算列表中每个值的平方,自带去重功能
squared = {x**2 for x in [1, -1, 2]}
print(squared)
# Output: set([1, 4])
执行输出:
{1, 4}
a = {1,1,4}
print(type(a))
执行输出:
<class 'set'>
结果是一个集合,它也是用{}表示的。
集合和字典是有区别的:
有键值对的,是字典,比如{'k1':1,'k1':2}
没有键值对的,是集合,比如{1,2,3,4}
二、生成器表达式
l_obj = ('python%s期' % i for i in range(1,12))
print(l_obj)
执行输出:
<generator object <genexpr> at 0x000002DDBEBADE60>
结果是一个生成器对象
如何取值呢?使用__next__方法
l_obj = ('python%s期' % i for i in range(1,12))
#print(l_obj)
print(l_obj.__next__())
print(l_obj.__next__())
print(l_obj.__next__())
执行输出:
python1期
python2期
python3期
列表推导式:一目了然,占内存
生成器表达式: 不便看出,节省内存。
三、内置函数
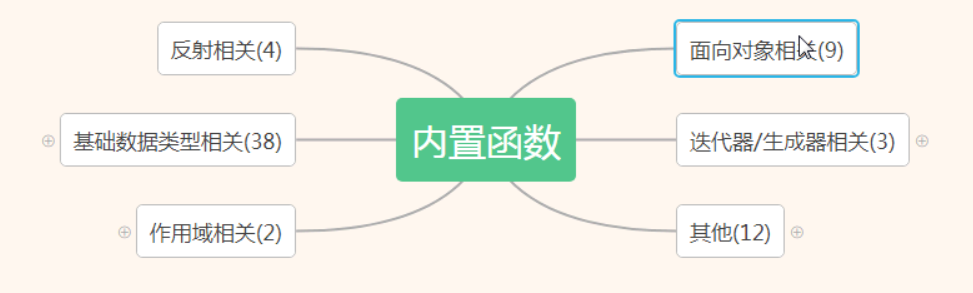
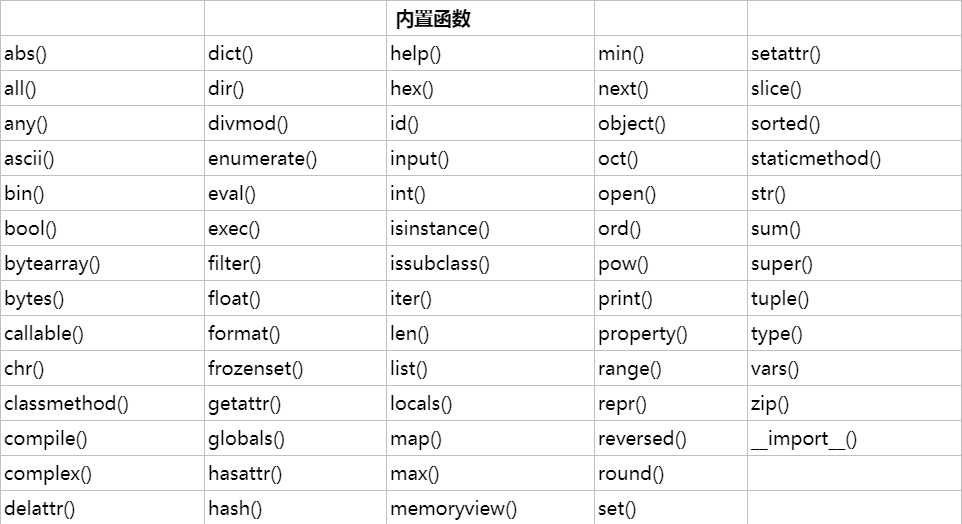
什么是内置函数?就是Python给你提供的,拿来直接用的函数,比如print,input等等。截止到python版本3.6.2,现在python一共为我们提供了68个内置函数。它们就是python提供给你直接可以拿来使用的所有函数。
✴✴✴ 表示很重要
✴ 表示一般
作用域相关
locals :函数会以字典的类型返回当前位置的全部局部变量。
globals:函数以字典的类型返回全部全局变量。
其他相关
字符串类型代码的执行 eval,exec,complie
✴✴✴eval:执行字符串类型的代码,并返回最终结果。
print(eval('3+4'))
执行输出: 7
ret = eval('{"name":"老司机"}')
print(ret)
执行输出: {'name': '老司机'}
eval的作用相当于拨开字符串2边的引号,执行里面的代码
✴✴✴exec:执行字符串类型的代码,流程语句
print(exec('3+4'))
执行输出:None
ret1 = '''
li = [1,2,3]
for i in li:
print(i)
'''
print(exec(ret1))
执行输出:
1
2
3
None
eval和exec 功能是类似的
区别:
1.eval有返回值,exec没有没有值
2.exec适用于有流程控制的,比如for循环。eval只能做一些简单的。
compile:将字符串类型的代码编译。代码对象能够通过exec语句来执行或者eval()进行求值。
code1 = 'for i in range(0,3): print (i)'
compile1 = compile(code1,'','exec')
exec (compile1)
执行输出:
0
1
2
compile这个函数很少用,未来几年都不会用得到
输入输出相关 input,print
✴✴✴input:函数接受一个标准输入数据,返回为 string 类型。
✴✴✴print:打印输出。
#print(self, *args, sep=' ', end='\n', file=None)
print(333,end='')
print(666,)
执行输出:
333666
print(333,end='**')
print(666,)
执行输出:
333**666
默认是用空格拼接
print(11, 22, 33)
执行输出:
11 22 33
sep 将每一个字符串拼接起来,这里指定使用|
print(11, 22, 33, sep = '|')
执行输出:
11|22|33
写入文件
with open('log.txt',encoding='utf-8',mode='w') as f1:
print('5555',file=f1)
执行程序,查看log.txt文件内容为: 555
内存相关 hash id
✴✴✴id:用于获取对象的内存地址。
a = 123
print(id(a))
执行输出:
1500668512
✴✴✴hash:获取一个对象(可哈希对象:int,str,Bool,tuple)的哈希值。
print(hash(123)) #数字不变
print(hash('123'))
执行输出:
123
4876937547014958447
true和False的哈希值对应1和0
print(hash(True))
print(hash(False))
执行输出:
1
0
模块相关__import__
__import__:函数用于动态加载类和函数 。
✴help:函数用于查看函数或模块用途的详细说明。
调用相关
✴✴✴callable:函数用于检查一个对象是否是可调用的。如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。
判断对象是否可调用的,就判断它是不是一个函数名
函数名返回True,其他,返回False
def func1():
print(555)
a = 3
f = func1
print(callable(f))
print(callable(a))
执行输出:
True
False
callable其实就是判断一个对象是否是函数,是就返回True,其他类型直接返回False
查看内置属性
✴✴✴dir:函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息。
print(dir(list))
执行输出:
['__add__', '__class__', '__contains__'...]
迭代器生成器相关
✴✴✴range:函数可创建一个整数对象,一般用在 for 循环中。
✴next:内部实际使用了__next__方法,返回迭代器的下一个项目。
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it) #next内部封装了__next__方法,都是求下一个值
print(x)
except StopIteration:
# 遇到StopIteration就退出循环
break
执行输出:
1
2
3
4
5
✴iter:函数用来生成迭代器(讲一个可迭代对象,生成迭代器)。
from collections import Iterable
from collections import Iterator
l = [1,2,3]
print(isinstance(l,Iterable)) # 判断是否可迭代
print(isinstance(l,Iterator)) # 判断是否为迭代器
执行输出:
True
False
from collections import Iterable
from collections import Iterator
l = [1,2,3]
l1 = iter(l) #生成迭代器
print(isinstance(l1,Iterable))
print(isinstance(l1,Iterator))
执行输出:
True
True
数字相关
数据类型:
✴✴✴bool :用于将给定参数转换为布尔类型,如果没有参数,返回 False。
✴✴✴int:函数用于将一个字符串或数字转换为整型。经常用
print(int())
print(int('12'))
print(int(3.6))
print(int('0100',base=2)) # 将2进制的 0100 转化成十进制。结果为 4
执行输出:
0
12
3
4
float:函数用于将整数和字符串转换成浮点数。
complex:函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数
将数字转换为浮点型,默认保留小数点1位
print(type(3.14))
print(float(3))
执行输出:
<class 'float'>
3.0
进制转换:
✴bin:将十进制转换成二进制并返回。
✴oct:将十进制转化成八进制字符串并返回。
✴hex:将十进制转化成十六进制字符串并返回。
print(bin(5))
print(oct(7))
print(hex(10)) #10用a表示
执行输出:
0b101
0o7
0xa
数学运算:
✴abs:函数返回数字的绝对值。
✴divmod:计算除数与被除数的结果,返回一个包含商和余数的元组(a // b, a % b)。
round:保留浮点数的小数位数,默认保留整数。
pow:求x**y次幂。(三个参数为x**y的结果对z取余)
print(abs(-20)) #绝对值
执行输出: 20
print(divmod(10,3)) #计算除数与被除数的结果
执行输出:
(3, 1)
divmod 在分页功能中,会用用到此函数
print(round(3.1415)) #默认取整
执行输出: 3
print(pow(2,3,5)) #求x**y次幂(三个参数为x**y的结果对z取余
执行输出: 2
解释:这里为3个参数,2的3次方,结果为8。用8和5做除法,取余为3,最终输出3
✴✴✴sum:对可迭代对象进行求和计算(可设置初始值)。
✴✴✴min:返回可迭代对象的最小值(可加key,key为函数名,通过函数的规则,返回最小值)。
✴✴✴max:返回可迭代对象的最大值(可加key,key为函数名,通过函数的规则,返回最大值)。
print(sum([1,2,3,4]))
执行输出: 10
sum最多只有2个参数
print(max([1,2,3,4]))
执行输出: 4
ret = max([1,2,-5],key=abs) # 按照绝对值的大小,返回此序列最大值
print(ret)
执行输出: -5
key表示定义规则
和数据结构相关
列表和元祖
✴✴✴list:将一个可迭代对象转化成列表(如果是字典,默认将key作为列表的元素)。
✴✴✴tuple:将一个可迭代对象转化成元祖(如果是字典,默认将key作为元祖的元素)。
相关内置函数
✴✴✴reversed:将一个序列翻转,并返回此翻转序列的迭代器。
slice:构造一个切片对象,用于列表的切片。
ite = reversed(['a',2,3,'c',4,2])
for i in ite:
print(i)
执行输出:
2
4
c
3
2
a
li = ['a','b','c','d','e','f','g']
sli_obj = slice(3) #从0切到3
print(li[sli_obj])
执行输出:
['a', 'b', 'c']
如果有10个列表,统一切前3个,sli_obj可能有点用
slice几乎用不到
slice可以定义一个切片规则
字符串相关
✴✴✴str:将数据转化成字符串。
✴✴✴format:用于格式化输出。
字符串可以提供的参数,指定对齐方式,<是左对齐, >是右对齐,^是居中对齐
print(format('test', '<20'))
print(format('test', '>20'))
print(format('test', '^20'))
执行输出:
test
test
test
✴✴✴bytes:用于不同编码之间的转化。
编码转换,将unicode转换为utf-8
s1 = '老司机'
s2 = s1.encode('utf-8')
print(s2)
#print(s2.decode('utf-8')) #解码
执行输出:
b'\xe8\x80\x81\xe5\x8f\xb8\xe6\x9c\xba'
第二种方法:
s1 = '老司机'
print(bytes(s1,encoding='utf-8'))
执行输出:
b'\xe8\x80\x81\xe5\x8f\xb8\xe6\x9c\xba'
bytes:只能编码,将unicode ---> 非unicode bytes(s1,encoding='utf-8')。
它不能解码
bytearry:返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256。
bytearry很少用
ret = bytearray('alex',encoding='utf-8') #4个字母对应的ascii顺序[97,108,101,120]
print(id(ret))
print(ret)
print(ret[0]) #97 是ascii码的顺序
ret[0] = 65 #65是大写a的位置
print(ret)
print(id(ret))
执行输出:
2177653717736
bytearray(b'alex')
97
bytearray(b'Alex')
2177653717736
memoryview:本函数是返回对象obj的内存查看对象。所谓内存查看对象,就是对象符合缓冲区协议的对象,为了给别的代码使用缓冲区里的数据,而不必拷贝,就可以直接使用。
ret = memoryview(bytes('你好',encoding='utf-8'))
print(len(ret)) # utf-8的bytes类型,放在一个list中 [\xe4,\xbd,\xa0,\xe5,\xa5,\xbd]
print(ret)
print(bytes(ret[:3]).decode('utf-8'))
print(bytes(ret[3:]).decode('utf-8'))
print('你好'.encode('utf-8'))
执行输出:
6
<memory at 0x0000016FD6AC0108>
你
好
b'\xe4\xbd\xa0\xe5\xa5\xbd'
✴ord:输入字符找该字符编码的位置
✴chr:输入位置数字找出其对应的字符
ascii:是ascii码中的返回该值,不是就返回\u...
print(ord('a')) #ascii码的位置
print(chr(98)) #98对应a
print(ord('中')) #按照unicode查找
print(ascii('中')) #不是ascii码就返回\u...
执行输出:
97
b
20013
'\u4e2d'
✴✴✴repr:返回一个对象的string形式(原形毕露)。
#%r 原封不动的写出来
name = 'taibai'
print('我叫%r' % name) #repr 原形毕露
print(repr('{"name":"alex"}'))
print('{"name":"alex"}')
执行输出:
我叫'taibai'
'{"name":"alex"}'
{"name":"alex"}
repr在面向对象中会用到
数据集合
✴✴✴dict:创建一个字典。
✴✴✴set:创建一个集合。
frozenset:返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
相关内置函数
✴✴✴len:返回一个对象中元素的个数。
✴✴✴sorted:对所有可迭代的对象进行排序操作。
li = [1,2,7,8,5,4,3]
print(sorted(li)) #默认升序
执行输出:
[1, 2, 3, 4, 5, 7, 8]
按照绝对值排序
li = [1,-2,-7,8,5,-4,3]
print(sorted(li,reverse=True,key=abs))
执行输出:
[8, -7, 5, -4, 3, -2, 1]
✴✴✴enumerate:枚举,返回一个枚举对象。 (0, seq[0]), (1, seq[1]), (2, seq[2])
li = ['jack', 'rose', 'wusir', '嫂子', '老司机']
print(enumerate(li))
print('__iter__' in dir(enumerate(li)))
print('__next__' in dir(enumerate(li)))
执行输出:
<enumerate object at 0x00000223DD887828>
True
True
enumerate是一个迭代器
li = ['jack', 'rose', 'wusir', '嫂子', '老司机']
for i in enumerate(li):
print(i)
执行输出:
(0, 'jack')
(1, 'rose')
(2, 'wusir')
(3, '嫂子')
(4, '老司机')
返回结果为:列表元素的索引以及对应的值
li = ['jack', 'rose', 'wusir', '嫂子', '老司机']
for k,v in enumerate(li):
print(k,v)
执行输出:
0 jack
1 rose
2 wusir
3 嫂子
4 老司机
enumerate的第2个参数,表示从多少开始。默认从1开始
li = ['jack', 'rose', 'wusir', '嫂子', '老司机']
for k,v in enumerate(li,10):
print(k,v)
执行输出:
10 jack
11 rose
12 wusir
13 嫂子
14 老司机
✴all:可迭代对象中,全都是True才是True
✴any:可迭代对象中,有一个True 就是True
print(all([1,2,True,0]))
print(any([1,'',0]))
执行输出:
False
True
✴✴✴zip:函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
print('__iter__' in dir(zip(l1,l2,l3,l4)))
print('__next__' in dir(zip(l1,l2,l3,l4)))
执行输出:
True
True
zip也是一个迭代器
zip 拉链方法 形成元组的个数与最短的可迭代对象的长度一样
l1 = [1, 2, 3, 4]
l2 = ['a', 'b', 'c', 5]
l3 = ('*', '**', (1,2,3), 777)
z = zip(l1,l2,l3)
for i in z:
print(i)
执行输出:
(1, 'a', '*')
(2, 'b', '**')
(3, 'c', (1, 2, 3))
(4, 5, 777)
我们把list当做列向量来看就很好理解了,zip就是拉链,把一件挂着的衣服拉起来。这就是zip的功能。所以
当做列向量看,就是拉起来的拉链了。
而转置的z就是把拉链放水平,多形象!
zip结果取决于最短的一个,返回的数据是元组
面试题,必考zip
✴✴✴filter:过滤·。
filter 过滤 通过你的函数,过滤一个可迭代对象,返回的是True
类似于[i for i in range(10) if i > 3]
取列表中的偶数
def func(x):
return x % 2 == 0
ret = filter(func,[1,2,3,4,5,6,7])
print(ret)
for i in ret:
print(i)
执行输出:
<filter object at 0x0000021325A4B6D8>
2
4
6
使用列表生成式完成上面的功能
li = [i for i in [1,2,3,4,5,6,7] if i % 2 == 0]
print(li)
执行输出,效果同上
✴✴✴map:会根据提供的函数对指定序列做映射。
map相当于列表生成式循环模式
def square(x): #计算平方数
return x ** 2
ret = map(square,[1,2,3,4,5]) #计算列表各个元素的平方
for i in ret:
print(i)
执行输出:
1
4
9
16
25
map也是迭代器
匿名函数
匿名函数:为了解决那些功能很简单的需求而设计的一句话函数。
返回一个数的平方
使用函数方式
def func1(x):
return x ** 2
使用匿名函数一行搞定
func = lambda x:x ** 2
print(func(5))
执行输出: 25
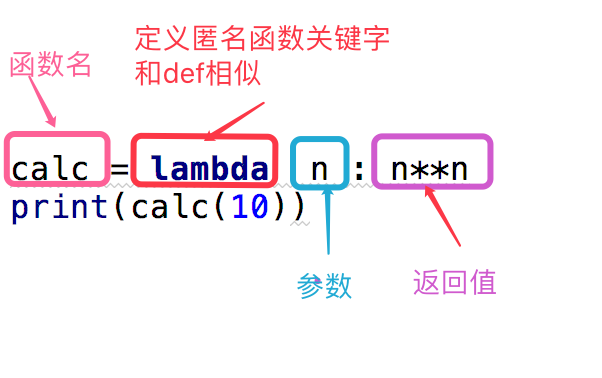
上面是我们对calc这个匿名函数的分析,下面给出了一个关于匿名函数格式的说明
函数名 = lambda 参数 :返回值 #参数可以有多个,用逗号隔开
#匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值
#返回值和正常的函数一样可以是任意数据类型
def func2(x,y):
return x + y
改成匿名函数
fun = lambda x,y:x+y
print(fun(1,3))
执行输出: 4
lambda单独拿出来,没有啥意义
主要是和内置函数结合使用
lambda 函数与内置函数的结合。
sorted,map,fiter,max,min,reversed
比较字典值的大小,并输出key的值
dic={'k1': 10, 'k2': 100, 'k3': 30}
print(max(dic, key=lambda x: dic[x]))
执行输出: k2
x表示dic的key,返回值就是dic[x] 也就是dic的value
lambda就是字典的value
def func(x):
return x**2
res = map(func,[1,5,7,4,8])
for i in res:
print(i)
改成lambda lambda可以不要函数名
res = map(lambda x:x**2,[1,5,7,4,8])
#print(res)
for i in res:
print(i)
执行输出:
1
25
49
16
64
打印出大于10的元素
l1 = [1,2,3,11,12,40,20,50,79]
ret = filter(lambda x:x > 10,l1)
#print(ret)
for i in ret:
print(i)
执行输出:
11
12
40
20
50
79
如果l1列表的数据,有上百万,不能使用列表推导式,非常占用内存
建议使用lamdba,它只占用一行
作业:
下面题都是用内置函数或者和匿名函数结合做出:
1,用map来处理字符串列表,把列表中所有人都变成sb,比方alex_sb
name=['oldboy','alex','wusir'] 2,用map来处理下述l,然后用list得到一个新的列表,列表中每个人的名字都是sb结尾
l=[{'name':'alex'},{'name':'y'}] 3,用filter来处理,得到股票价格大于20的股票名字
shares={
'IBM':36.6,
'Lenovo':23.2,
'oldboy':21.2,
'ocean':10.2,
} 4,有下面字典,得到购买每只股票的总价格,并放在一个迭代器中。
结果:list一下[9110.0, 27161.0,......]
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}] 5,还是上面的字典,用filter过滤出单价大于100的股票。 6,有下列三种数据类型,
l1 = [1,2,3,4,5,6]
l2 = ['oldboy','alex','wusir','太白','日天']
tu = ('**','***','****','*******')
写代码,最终得到的是(每个元祖第一个元素>2,第三个*至少是4个。)
[(3, 'wusir', '****'), (4, '太白', '*******')]这样的数据。 7,有如下数据类型:
l1 = [{'sales_volumn': 0},
{'sales_volumn': 108},
{'sales_volumn': 337},
{'sales_volumn': 475},
{'sales_volumn': 396},
{'sales_volumn': 172},
{'sales_volumn': 9},
{'sales_volumn': 58},
{'sales_volumn': 272},
{'sales_volumn': 456},
{'sales_volumn': 440},
{'sales_volumn': 239}]
将l1按照列表中的每个字典的values大小进行排序,形成一个新的列表。
答案:
1.
name=['oldboy','alex','wusir']
a = map(lambda x:x+'_sb',name)
for i in a:
print(i)
执行输出:
oldboy_sb
alex_sb
wusir_sb
2.
l=[{'name':'alex'},{'name':'y'}]
a = map(lambda x:x['name'] + '_sb',l)
li = []
for i in a:
li.append(i)
print(li)
执行输出:
['alex_sb', 'y_sb']
3.
shares={
'IBM':36.6,
'Lenovo':23.2,
'oldboy':21.2,
'ocean':10.2,
}
a = filter(lambda x:shares[x] > 20,shares)
for i in a:
print(i)
执行输出:
oldboy
Lenovo
IBM
4.
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}] a = map(lambda x:x['shares']*x['price'],portfolio)
li = []
for i in a:
#print(i)
li.append(i)
print(li)
执行输出:
[9110.0, 27161.0, 4218.0, 1111.25, 735.7500000000001, 8673.75]
5.
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}] a = filter(lambda x:x['price'] > 100,portfolio)
for i in a:
print(i)
执行输出:
{'price': 543.22, 'name': 'AAPL', 'shares': 50}
{'price': 115.65, 'name': 'ACME', 'shares': 75}
6.
l1 = [1,2,3,4,5,6]
l2 = ['oldboy','alex','wusir','太白','日天']
tu = ('**','***','****','*******')
a = zip(l1,l2,tu)
li = []
for i in a:
#print(i)
li.append(i)
print(li)
执行输出:
[(1, 'oldboy', '**'), (2, 'alex', '***'), (3, 'wusir', '****'), (4, '太白', '*******')]
7.
l1 = [{'sales_volumn': 0},
{'sales_volumn': 108},
{'sales_volumn': 337},
{'sales_volumn': 475},
{'sales_volumn': 396},
{'sales_volumn': 172},
{'sales_volumn': 9},
{'sales_volumn': 58},
{'sales_volumn': 272},
{'sales_volumn': 456},
{'sales_volumn': 440},
{'sales_volumn': 239}]
a = sorted(l1,reverse=False,key=lambda x:x['sales_volumn'])
print(a)
执行输出:
[{'sales_volumn': 0}, {'sales_volumn': 9}, {'sales_volumn': 58}, {'sales_volumn': 108}, {'sales_volumn': 172}, {'sales_volumn': 239}, {'sales_volumn': 272}, {'sales_volumn': 337}, {'sales_volumn': 396}, {'sales_volumn': 440}, {'sales_volumn': 456}, {'sales_volumn': 475}]
python 全栈开发,Day14(列表推导式,生成器表达式,内置函数)的更多相关文章
- python全栈开发- day14列表推导式、生成器表达式、模块基础
一.列表推导式 #1.示例 数据量小 egg_list=[] for i in range(10): egg_list.append('鸡蛋%s' %i) egg_list=['鸡蛋%s' %i fo ...
- Python入门之三元表达式\列表推导式\生成器表达式\递归匿名函数\内置函数
本章目录: 一.三元表达式.列表推导式.生成器表达式 二.递归调用和二分法 三.匿名函数 四.内置函数 ================================================ ...
- python全栈开发day13-迭代器、生成器、列表推导式等
昨日内容:函数的有用信息.带参数的装饰器.多个装饰器修饰一个函数 迭代器 可迭代对象:内部含有__iter__方法 迭代器 定义:可迭代对象.__iter__()就是迭代器,含有__iter__且__ ...
- Python的高级特性2:列表推导式,生成器与迭代器
一.列表推导式 1.列表推导式是颇具python风格的一种写法.这种写法除了高效,也更简短. In [23]: {i:el for i,el in enumerate(["one" ...
- python之生成器(~函数,列表推导式,生成器表达式)
一.生成器 概念:生成器的是实质就是迭代器 1.生成器的贴点和迭代器一样,取值方式也和迭代器一样. 2.生成器一般由生成器函数或者声称其表达式来创建,生成器其实就是手写的迭代器. 3.在python中 ...
- Python全栈开发记录_第四篇(集合、函数等知识点)
知识点1:深拷贝和浅拷贝 非拷贝(=赋值:数据完全共享,内存地址一样,修改一个另一个也变化) 浅拷贝:数据半共享(复制其数据独立内存存放,但是只拷贝成功第一层)像[[1,2],3,4]如果修改列表中列 ...
- python全栈开发_day14_常见语法糖,递归和匿名函数
一:常见语法糖 1)三元函数(三目函数) a=1 if 3>2 else 2 print(a) #得到返回值:1 2)列表字典推导式 lis=[("a",1),(" ...
- python基础-三元表达式/列表推导式/生成器表达式
1.三元表达式:如果成立返回if前的内容,如果不成立返回else的内容 name=input('姓名>>: ') res='SB' if name == 'alex' else 'NB' ...
- day14 十四、三元运算符,推导式,匿名内置函数
一.三元(目)运算符 1.就是if...else...语法糖 前提:if和else只有一条语句 # 原来的做法 cmd = input('cmd:>>>') if cmd.isdig ...
随机推荐
- python---基于memcache的自定义session类
import config import hashlib import time import memcache import json conn = memcache.Client(["1 ...
- Kanboard简单的可视化任务板,项目管理
采用docker安装 简单快捷 下载 docker pull kanboard/kanboard:latest 运行 docker run -d --name kanboard -p 10080:80 ...
- elasticsearch-head连接不上es
修改elasticsearch.yml,增加如下字段 http.cors.enabled: true http.cors.allow-origin: "*" cros为: Cros ...
- Frame size of 257 MB larger than max allowed 100 MB
ActiveMQ有时会报类似Frame size of 257 MB larger than max allowed 100 MB的错误,意思是单条消息超过了预设的最大值,在配置文件中 <tra ...
- Centos7更改yum镜像源
1. 备份本地yum源 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo_bak 2.获取阿里yum源配置文 ...
- 简述get与post区别
get和post在HTTP中都代表着请求数据,其中get请求相对来说更简单.快速,效率高些. get对于请求数据和静态资源(HTML页面和图片),在低版本浏览器下都会缓存.高版本浏览器只缓存静态资源, ...
- Prezento – 轻量、简单的 jQuery 幻灯片插件
Prezento 是一个超级简单的 jQuery 幻灯片插件.可以让你网页以新颖的交互方式呈现.另外,Prezento 支持响应式设计,配置项也很灵活,可以根据你需要的效果配置. 您可能感兴趣的相关文 ...
- js针对数组的操作
链接:http://www.w3school.com.cn/jsref/jsref_obj_array.asp Array 对象方法 方法 描述 concat() 连接两个或更多的数组,并返回结果. ...
- Toy Train(贪心)
题目链接:http://codeforces.com/contest/1130/problem/D1 题目大意:给你n个点,然后m条运输任务,然后问你从每个点作为起点是,完成这些运输任务的最小花费?每 ...
- Androidstudio中jar包重复或jar包里的类重复问题
https://www.jianshu.com/p/dd5d4fda1df8 http://blog.csdn.net/hqb112233/article/details/51514208