7 selenium 模块
selenium 模块
一.简介
1.Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作。
2.自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器。
二.下载
mac系统: 然后将解压后的chromedriver移动到/usr/local/bin目录下
windows系统:下载chromdriver.exe放到python安装路径的scripts目录
2.安装pip 包
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
注意:selenium3默认支持的webdriver是Firfox,而Firefox需要安装geckodriver
三.selenium模块的使用
1.简单使用
from selenium import webdriver
from time import sleep # 后面是你的浏览器驱动位置,记得前面加r'','r'是防止字符转义的
driver = webdriver.Chrome()
# 用get打开百度页面
driver.get("http://www.baidu.com")
# 查找页面的“设置”选项,并进行点击
driver.find_elements_by_link_text('设置')[0].click()
sleep(2)
# # 打开设置后找到“搜索设置”选项,设置为每页显示50条
driver.find_elements_by_link_text('搜索设置')[0].click()
sleep(2) # 选中每页显示50条
m = driver.find_element_by_id('nr')
sleep(2)
m.find_element_by_xpath('//*[@id="nr"]/option[3]').click()
m.find_element_by_xpath('.//option[3]').click()
sleep(2) # 点击保存设置
driver.find_elements_by_class_name("prefpanelgo")[0].click()
sleep(2) # 处理弹出的警告页面 确定accept() 和 取消dismiss()
driver.switch_to.alert().accept()
sleep(2)
# 找到百度的输入框,并输入 美女
driver.find_element_by_id('kw').send_keys('美女')
sleep(2)
# 点击搜索按钮
driver.find_element_by_id('su').click()
sleep(2)
# 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面
driver.find_elements_by_link_text('美女_百度图片')[0].click()
sleep(3) # 关闭浏览器
driver.quit()
Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS。
from selenium import webdriver browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
2.元素定位
webdriver提供了大致8种,元素定位的方法:
1. id =====> find_element_by_id() 2. name=====>find_element_by_name() 3.class name==>find_element_by_calss_name() 4.tag name====>find_element_by_tag_name() 5.link text=====>find_element_by_link_text() 6.partial link text ==>find_element_by_partial_link_text() 7.xpath========> find_element_by_xpath() 8.css selector ===> find_element_by_css_selector()
注意:
1. find_element_by_xxx 找到第一个符合条件的标签
2.find_elements_by_xxx 所有符合条件标签
3. find_element(查询方式,值)
find_element_by_id(id) ==> find_element(By.ID,id)
3.节点交互
1. tag.send_keys("内容") # 输入内容
2. tag .clear() # 清空输入内容
3. tag.click() # 点击
from selenium import webdriver
import time # 节点交互
browser=webdriver.Chrome() # 实例化一个浏览器对象 browser.get("https://www.taobao.com") # 让浏览器 去访问淘宝 input = browser.find_element_by_id("q") # 找到 输入搜索框 input.send_keys("python") # 在输入框中输入内容 time.sleep(1) input.clear() # 将上次输入的内容清空 input.send_keys("鞋子") search =browser.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button') # 找到搜索按钮 search.click() # 点击搜索按钮 time.sleep(2)
4.动作链
from selenium import webdriver
from selenium.webdriver import ActionChains
import time browser =webdriver.Chrome()# 获取一个浏览器对象
browser.get("http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable") # 让该浏览器去访问该地址 browser.switch_to_frame('iframeResult') # 找到id 为 'iframeResult' iframe 中嵌套着另一个html 文档
source=browser.find_element_by_css_selector('#draggable')
target=browser.find_element_by_css_selector('#droppable') action=ActionChains(browser)
# action.drag_and_drop(source,target) # 拖到目标
action.click_and_hold(source).perform() # 点击不放
time.sleep(1)
action.move_to_element(target).perform() # 移动到目标
time.sleep(1)
action.move_by_offset(xoffset=50,yoffset=50).perform() # 在右移20 ,下移10
time.sleep(3)
action.release() # 解除动作 browser.close()
5.执行js代码
用途:爬取动态页面等,下拉才不断显示新数据的动态页面
from selenium import webdriver
import time
browser =webdriver.Chrome()
browser.get("https://www.jd.com/")
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')# 从上到下一直拉到浏览器底部 browser.execute_script("alert('123')") browser.close() # 关闭浏览器
6.获取节点信息
from selenium import webdriver
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome() browser.get('https://www.amazon.cn/') wait=WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'cc-lm-tcgShowImgContainer'))) tag=browser.find_element(By.CSS_SELECTOR,'#cc-lm-tcgShowImgContainer img') #获取标签属性,
print(tag.get_attribute('src'))
#获取标签ID,位置,名称,大小(了解)
print(tag.id)
print(tag.location)
print(tag.tag_name)
print(tag.size) browser.close()
7.延时等待
在Selenium中,get()方法会在网页框架加载结束后结束执行,此时如果获取page_source,可能并不是浏览器完全加载完成的页面,如果某些页面有额外的Ajax请求,我们在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来。这里等待的方式有两种:一种是隐式等待,一种是显式等待。
隐式等待:
当使用隐式等待执行测试的时候,如果Selenium没有在DOM中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找DOM,默认的时间是0。示例如下:
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome() #隐式等待:在查找所有元素时,如果尚未被加载,则等10秒
browser.implicitly_wait(10) browser.get('https://www.baidu.com')
input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER) contents=browser.find_element_by_id('content_left') #没有等待环节而直接查找,找不到则会报错
print(contents) browser.close()
显示等待:
隐式等待的效果其实并没有那么好,因为我们只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。这里还有一种更合适的显式等待方法,它指定要查找的节点,然后指定一个最长等待时间。如果在规定时间内加载出来了这个节点,就返回查找的节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome()
browser.get('https://www.baidu.com') input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER) #显式等待:显式地等待某个元素被加载
wait=WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'content_left'))) contents=browser.find_element(By.CSS_SELECTOR,'#content_left')
print(contents) browser.close()
8.cookies
# 对Cookies进行操作,例如获取、添加、删除Cookies等。 from selenium import webdriver browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
9.异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException try:
browser=webdriver.Chrome()
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframssseResult') except TimeoutException as e:
print(e)
except NoSuchFrameException as e:
print(e)
finally:
browser.close()
四 phantomJs
PhantomJS是一款无界面的浏览器,其自动化操作流程和上述操作谷歌浏览器是一致的。
能够展示自动化操作流程,PhantomJS提供了一个截屏的功能,使用save_screenshot函数实现。
from selenium import webdriver
import time # phantomjs路径
path = r'PhantomJS驱动路径'
browser = webdriver.PhantomJS(path) # 打开百度
url = 'http://www.baidu.com/'
browser.get(url) time.sleep(3) browser.save_screenshot(r'phantomjs\baidu.png') # 查找input输入框
my_input = browser.find_element_by_id('kw')
# 往框里面写文字
my_input.send_keys('美女')
time.sleep(3)
#截屏
browser.save_screenshot(r'phantomjs\meinv.png') # 查找搜索按钮
button = browser.find_elements_by_class_name('s_btn')[0]
button.click() time.sleep(3) browser.save_screenshot(r'phantomjs\show.png') time.sleep(3) browser.quit()
selenium+phantomjs 就是爬虫终极解决方案:
有些网站上的内容信息是通过动态加载js形成的,所以使用普通爬虫程序无法回去动态加载的js内容。
例如:豆瓣电影中的电影信息是通过下拉操作动态加载更多的电影信息。
需求 :尽可能多的爬取豆瓣网中的电影信息
from selenium import webdriver
from time import sleep
import time if __name__ == '__main__':
url = 'https://movie.douban.com/typerank?type_name=%E6%81%90%E6%80%96&type=20&interval_id=100:90&action='
# 发起请求前,可以让url表示的页面动态加载出更多的数据
path = r'D:\phantomjs\bin\phantomjs.exe'
# 创建无界面的浏览器对象
bro = webdriver.PhantomJS(path)
# 发起url请求
bro.get(url)
time.sleep(3)
# 截图
bro.save_screenshot('1.png') # 执行js代码(让滚动条向下偏移n个像素(作用:动态加载了更多的电影信息))
js = 'window.scrollTo(0,document.body.scrollHeight)'
bro.execute_script(js) # 该函数可以执行一组字符串形式的js代码
time.sleep(2) bro.execute_script(js) # 该函数可以执行一组字符串形式的js代码
time.sleep(2)
bro.save_screenshot('2.png')
time.sleep(2)
# 使用爬虫程序爬去当前url中的内容
html_source = bro.page_source # 该属性可以获取当前浏览器的当前页的源码(html)
with open('./source.html', 'w', encoding='utf-8') as fp:
fp.write(html_source)
bro.quit()
破解滑动验证码:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait # 等待元素加载的
from selenium.webdriver.common.action_chains import ActionChains #拖拽
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException
from selenium.webdriver.common.by import By
from PIL import Image
import requests
import re
import random
from io import BytesIO
import time def merge_image(image_file,location_list):
"""
拼接图片
"""
im = Image.open(image_file)
im.save('code.jpg')
new_im = Image.new('RGB',(260,116))
# 把无序的图片 切成52张小图片
im_list_upper = []
im_list_down = []
# print(location_list)
for location in location_list:
# print(location['y'])
if location['y'] == -58: # 上半边
im_list_upper.append(im.crop((abs(location['x']),58,abs(location['x'])+10,116)))
if location['y'] == 0: # 下半边
im_list_down.append(im.crop((abs(location['x']),0,abs(location['x'])+10,58))) x_offset = 0
for im in im_list_upper:
new_im.paste(im,(x_offset,0)) # 把小图片放到 新的空白图片上
x_offset += im.size[0] x_offset = 0
for im in im_list_down:
new_im.paste(im,(x_offset,58))
x_offset += im.size[0]
#new_im.show()
return new_im def get_image(driver,div_path):
'''
下载无序的图片 然后进行拼接 获得完整的图片
:param driver:
:param div_path:
:return:
'''
background_images = driver.find_elements_by_xpath(div_path)
location_list = []
for background_image in background_images:
location = {}
result = re.findall('background-image: url\("(.*?)"\); background-position: (.*?)px (.*?)px;',background_image.get_attribute('style'))
# print(result)
location['x'] = int(result[0][1])
location['y'] = int(result[0][2]) image_url = result[0][0]
location_list.append(location)
image_url = image_url.replace('webp','jpg')
# '替换url http://static.geetest.com/pictures/gt/579066de6/579066de6.webp'
image_result = requests.get(image_url).content
image_file = BytesIO(image_result) # 是一张无序的图片
image = merge_image(image_file,location_list) return image def get_track(distance): # 初速度
v=0
# 单位时间为0.2s来统计轨迹,轨迹即0.2内的位移
t=0.2
# 位移/轨迹列表,列表内的一个元素代表0.2s的位移
tracks=[]
tracks_back=[]
# 当前的位移
current=0
# 到达mid值开始减速
mid=distance * 7/8
print("distance",distance)
global random_int
random_int=8
distance += random_int # 先滑过一点,最后再反着滑动回来 while current < distance:
if current < mid:
# 加速度越小,单位时间的位移越小,模拟的轨迹就越多越详细
a = random.randint(2,5) # 加速运动
else:
a = -random.randint(2,5) # 减速运动
# 初速度
v0 = v
# 0.2秒时间内的位移
s = v0*t+0.5*a*(t**2)
# 当前的位置
current += s
# 添加到轨迹列表
if round(s)>0:
tracks.append(round(s))
else:
tracks_back.append(round(s)) # 速度已经达到v,该速度作为下次的初速度
v= v0+a*t print("tracks:",tracks)
print("tracks_back:",tracks_back)
print("current:",current) # 反着滑动到大概准确位置 tracks_back.append(distance-current)
tracks_back.extend([-2,-5,-8,]) return tracks,tracks_back def get_distance(image1,image2):
'''
拿到滑动验证码需要移动的距离
:param image1:没有缺口的图片对象
:param image2:带缺口的图片对象
:return:需要移动的距离
'''
# print('size', image1.size) threshold = 50
for i in range(0,image1.size[0]): #
for j in range(0,image1.size[1]): #
pixel1 = image1.getpixel((i,j))
pixel2 = image2.getpixel((i,j))
res_R = abs(pixel1[0]-pixel2[0]) # 计算RGB差
res_G = abs(pixel1[1] - pixel2[1]) # 计算RGB差
res_B = abs(pixel1[2] - pixel2[2]) # 计算RGB差
if res_R > threshold and res_G > threshold and res_B > threshold:
return i # 需要移动的距离 def main_check_code(driver,element):
"""
拖动识别验证码
:param driver:
:param element:
:return:
""" login_btn = driver.find_element_by_class_name('js-login')
login_btn.click() element = WebDriverWait(driver, 30, 0.5).until(EC.element_to_be_clickable((By.CLASS_NAME, 'gt_guide_tip')))
slide_btn = driver.find_element_by_class_name('gt_guide_tip')
slide_btn.click() image1 = get_image(driver, '//div[@class="gt_cut_bg gt_show"]/div')
image2 = get_image(driver, '//div[@class="gt_cut_fullbg gt_show"]/div')
# 图片上 缺口的位置的x坐标 # 2 对比两张图片的所有RBG像素点,得到不一样像素点的x值,即要移动的距离
l = get_distance(image1, image2)
print('l=',l) # 3 获得移动轨迹
track_list = get_track(l)
print('第一步,点击滑动按钮')
element = WebDriverWait(driver, 30, 0.5).until(EC.element_to_be_clickable((By.CLASS_NAME, 'gt_slider_knob')))
ActionChains(driver).click_and_hold(on_element=element).perform() # 点击鼠标左键,按住不放
import time
time.sleep(0.4)
print('第二步,拖动元素')
for track in track_list[0]:
ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
#time.sleep(0.4)
for track in track_list[1]:
ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
time.sleep(0.1)
import time
time.sleep(0.6)
# ActionChains(driver).move_by_offset(xoffset=2, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
# ActionChains(driver).move_by_offset(xoffset=8, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
# ActionChains(driver).move_by_offset(xoffset=2, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
print('第三步,释放鼠标')
ActionChains(driver).release(on_element=element).perform()
time.sleep(1) def main_check_slider(driver):
"""
检查滑动按钮是否加载
:param driver:
:return:
"""
while True:
try :
driver.get('https://www.huxiu.com/')
element = WebDriverWait(driver, 30, 0.5).until(EC.element_to_be_clickable((By.CLASS_NAME, 'js-login')))
if element:
return element
except TimeoutException as e:
print('超时错误,继续')
time.sleep(5) if __name__ == '__main__': try:
count = 3 # 最多识别3次
driver = webdriver.Chrome()
while count > 0:
# 等待滑动按钮加载完成
element = main_check_slider(driver)
main_check_code(driver,element)
try:
success_element = (By.CSS_SELECTOR, '.gt_success')
# 得到成功标志
success_images = WebDriverWait(driver,3).until(EC.presence_of_element_located(success_element))
if success_images:
print('成功识别!!!!!!')
count = 0
import sys
sys.exit()
except Exception as e:
print('识别错误,继续')
count -= 1
time.sleep(1)
else:
print('too many attempt check code ')
exit('退出程序')
finally:
driver.close()
破解滑动验证码
iframe 页面的selenium如何定位
1、iframe有id属性
browser =webdriver.Chrome()# 获取一个浏览器对象
browser.get("http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable") # 让该浏览器去访问该地址 browser.switch_to_frame('iframeResult') # 找到id 为 'iframeResult' iframe 中嵌套着另一个html 文档
source=browser.find_element_by_css_selector('#draggable')
2. iframe 没有id ,或其id属性时变化的
下面为豆瓣的没id情况的定位:
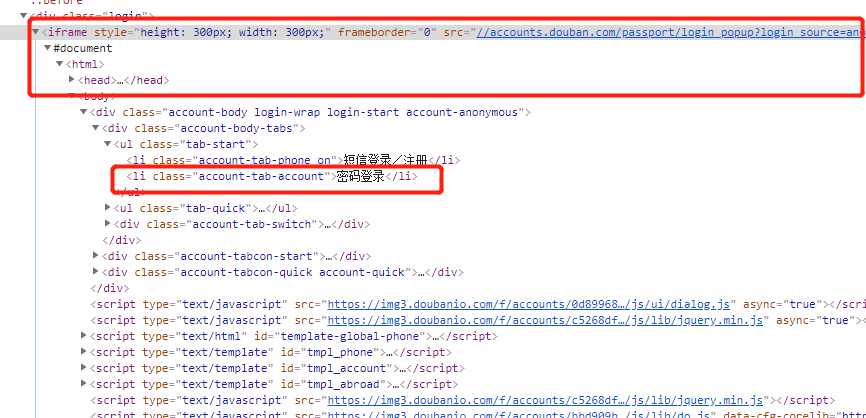
id属性值时变化的:https://mail.126.com/
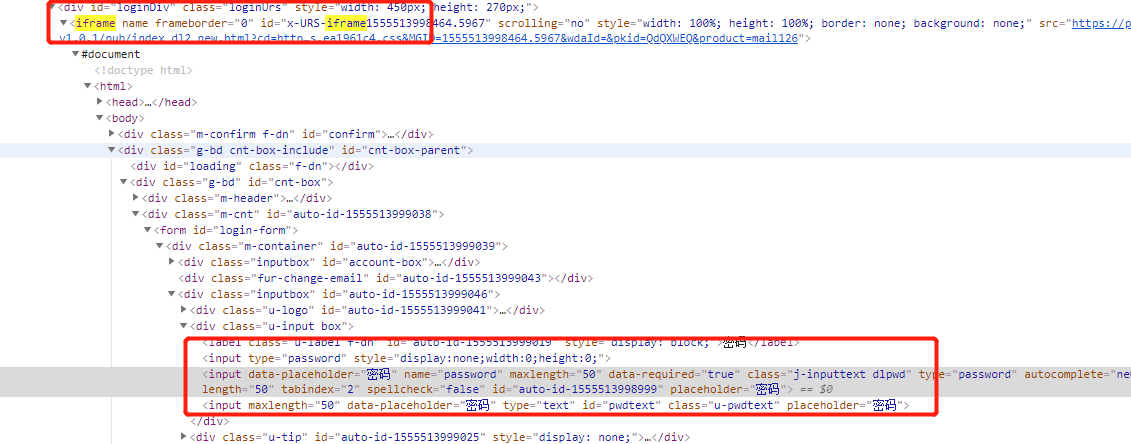
下面为豆瓣的没id情况的定位代码(126定位也用类似的方法):
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.douban.com/')
# iframe 没有id 属性时
iframe=driver.find_elements_by_tag_name('iframe')[0]
driver.switch_to_frame(iframe)
password_login = driver.find_element_by_xpath("//li[@class='account-tab-account']") # element xpath 找一个元素
password_login.click()
7 selenium 模块的更多相关文章
- 爬虫基础(三)-----selenium模块应用程序
摆脱穷人思维 <三> : 培养"目标导向"的思维: 好项目永远比钱少,只要目标正确,钱总有办法解决. 一 selenium模块 什么是selenium?seleni ...
- 爬虫之selenium模块
Selenium 简介 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟 ...
- 使用Selenium模块报错的解决办法 (FileNotFound,WebDriverException)
添加Chrome浏览器程序的目录到系统Path变量中: C:\Users\%USERNAME%\AppData\Local\Google\Chrome\Application ,使用pip3 inst ...
- Python爬虫——selenium模块
selenium模块介绍 selenium最初是一个测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览 ...
- python 全栈开发,Day136(爬虫系列之第3章-Selenium模块)
一.Selenium 简介 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全 ...
- 三: 爬虫之selenium模块
一 selenium模块 什么是selenium?selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作. selenium最初是一个自动化测试工具, ...
- 03 爬虫之selenium模块
selenium模块 1.概念,了解selenium 什么是selenium?selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作. seleniu ...
- 浏览器行为模拟之requests、selenium模块
requests模块 前言: 通常我们利用Python写一些WEB程序.webAPI部署在服务端,让客户端request,我们作为服务器端response数据: 但也可以反主为客利用Python的re ...
- 爬虫模块之selenium模块
一 模块的介绍 selenium模块最开始是一个自动化测试的工具,驱动浏览器完全模拟浏览器自动测试. from selenium import webdriver # 驱动浏览器 browser=we ...
随机推荐
- 关于linux下自定义的 alias文件和自定义函数库的通用写法(只适合自己的)
使用alias和自定义的function的必要性和重要性就不说了 , 自己的通用做法是: 可以创建: ~/bin/my.alias 文件 作为自定义的 alias专门文件 创建: ~/libsh/my ...
- P2042 [NOI2005]维护数列
思路 超级恶心的pushdown 昏天黑地的调 让我想起了我那前几个月的线段树2 错误 这恶心的一道题终于过了 太多错误,简直说不过来 pushup pushdown 主要就是这俩不太清晰,乱push ...
- Python SSH爆破以及Python3线程池控制线程数
源自一个朋友的要求,他的要求是只爆破一个ip,结果出来后就停止,如果是爆破多个,完全没必要停止,等他跑完就好 #!usr/bin/env python #!coding=utf-8 __author_ ...
- size_t和unsigned int区别
size_t和unsigned int有所不同,size_t的取值range是目标平台下最大可能的数组尺寸,一些平台下size_t的范围小于int的正数范围,又或者大于unsigned int.最典型 ...
- Unity3D代码动态修改材质球的颜色
代码动态修改材质球的颜色: gameObject.GetComponent<Renderer>().material.color=Color.red;//当材质球的Shader为标准时,可 ...
- Netty Reactor 线程模型笔记
引用: https://www.cnblogs.com/TomSnail/p/6158249.html https://www.cnblogs.com/heavenhome/articles/6554 ...
- 【C#】委托中的匿名函数与lambda
将方法作为方法的参数 委托是一个类,它定义了方法的类型,使得可以将方法当作另一个方法的参数来进行传递,这种将方法动态地赋给参数的做法,可以避免在程序中大量使用If-Else(Switch)语句,同时使 ...
- 【.NET开发之美】使用ComponentOne提高.NET DataMap中的加载速度
概述 FlexGrid for WinForm 采用了最新的数据绑定技术,并与Microsoft .NET Framework无缝集成. 因此,您可以获得易于使用的灵活网格控件,用于创建用户友好界面, ...
- UVA12558 埃及分数
#include<iostream> #include<cstdio> #include<set> #include<memory.h> using n ...
- ImgNoGoodWindow
using System;using System.Collections.Generic;using System.Linq;using System.Text;using UnityEditor; ...