Spring AOP实现Mysql数据库主从切换(一主多从)
设置数据库主从切换的原因:数据库中经常发生的是“读多写少”,这样读操作对数据库压力比较大,通过采用数据库集群方案,
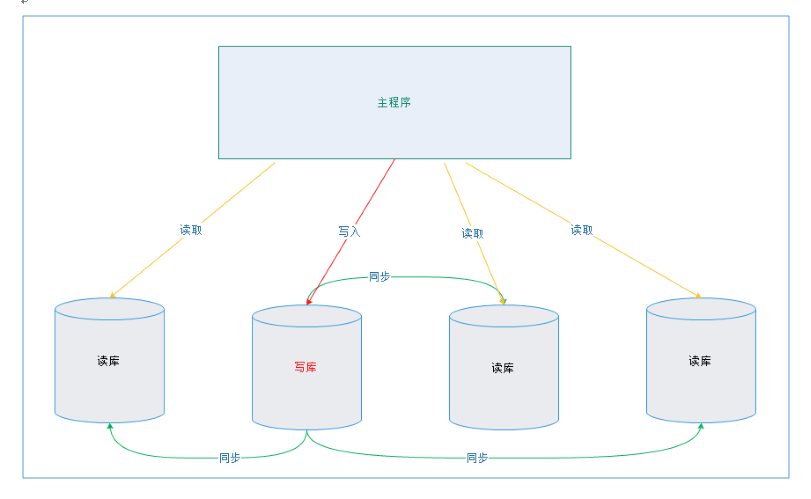
一个数据库是主库,负责写;其他为从库,负责读,从而实现读写分离增大数据库的容错率。
那么,对数据库的要求是:
1. 读库和写库的数据一致;
2. 写数据必须写到写库;
3. 读数据必须到读库;
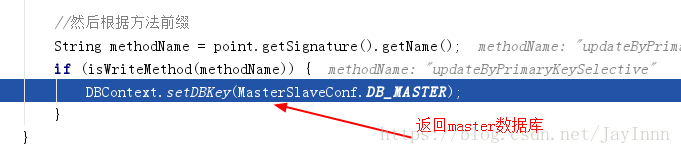
Spring AOP实现Mysql数据库主从切换的过程:在进入Service之前,使用AOP来做出判断,是使用写库还是读库,判断依据可以根据方法名判断,比如说以"update", "insert", "delete", "save"开头的就走写库,其他的走读库。

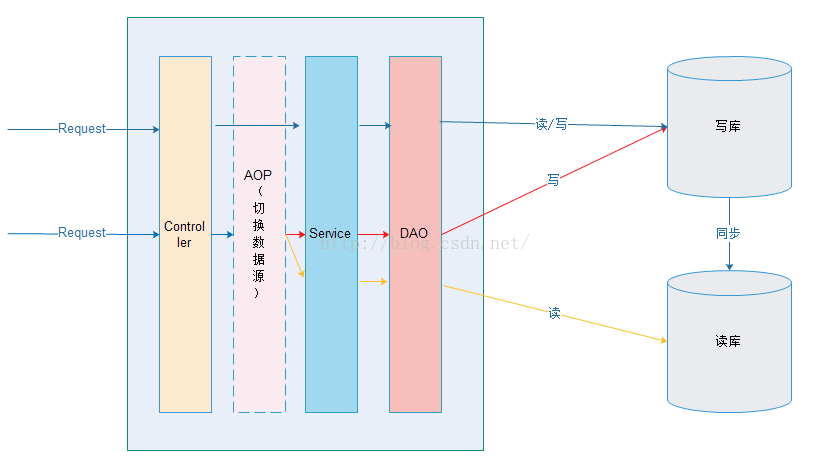
实现主从(一主多从)分离:
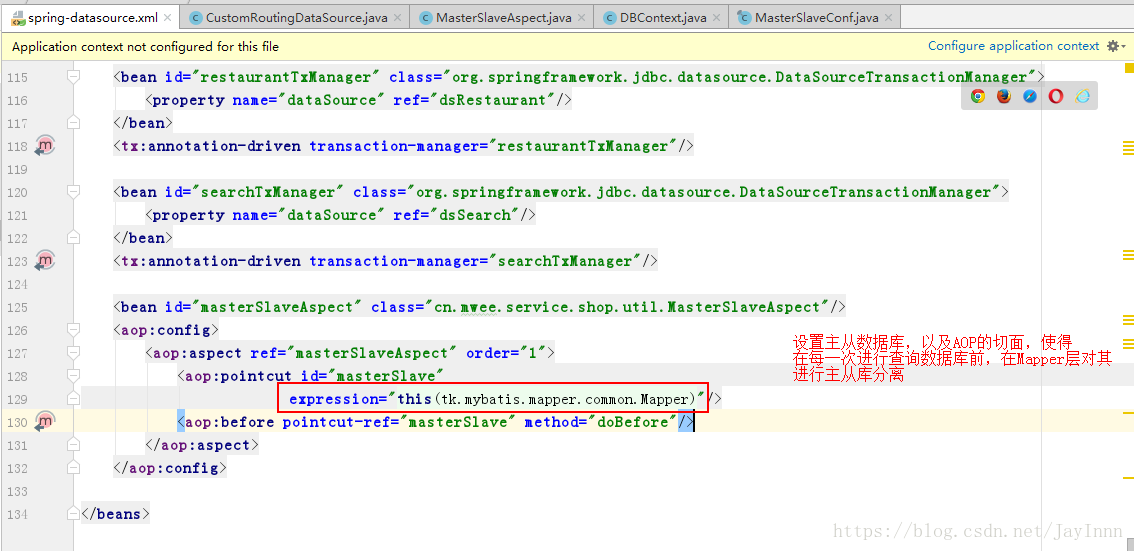
首先配置主从数据库
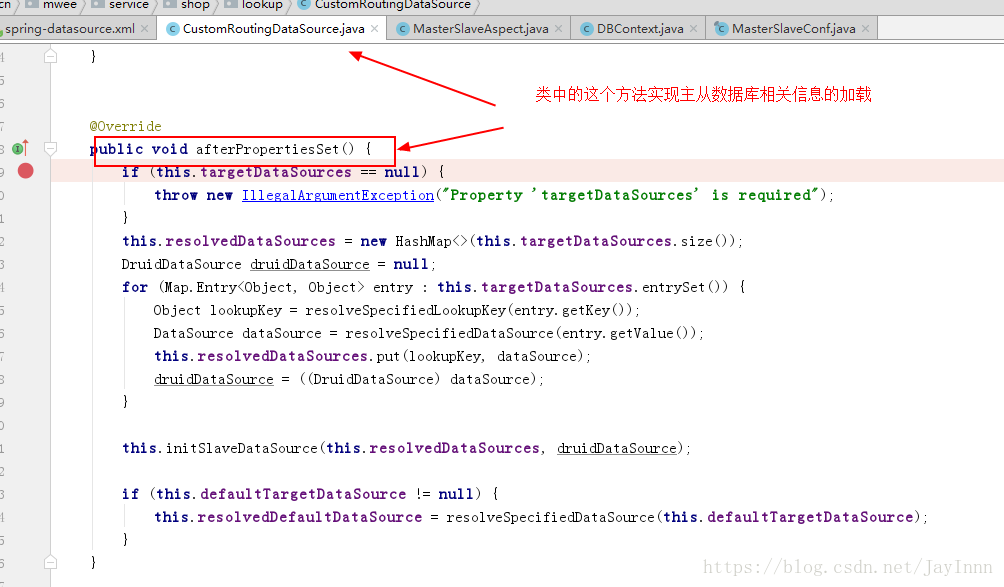
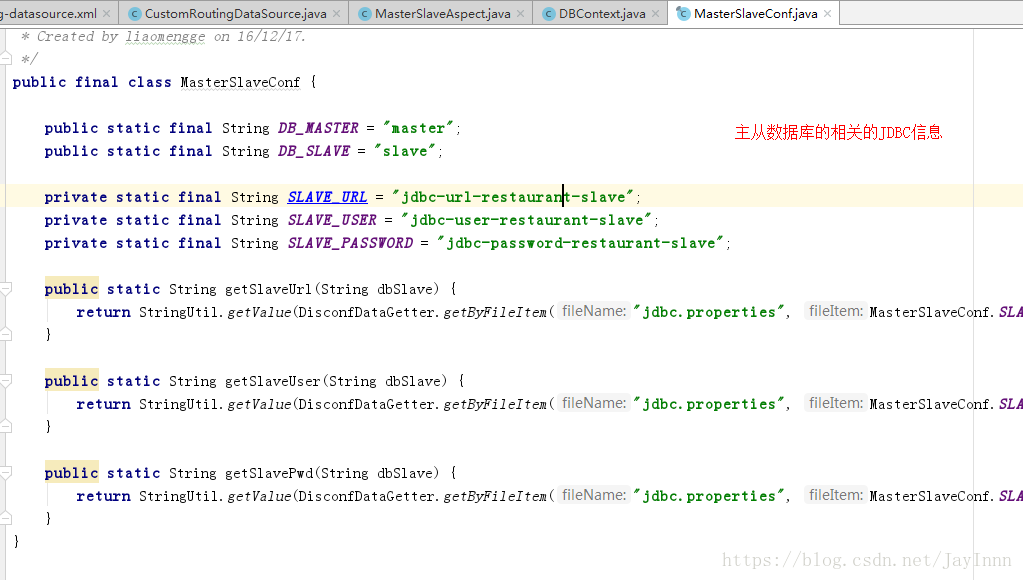
主程序启动过程中,通过配置文件将主从数据库的URL以及用户名密码加载到内存中:
AOP切入点的实现:
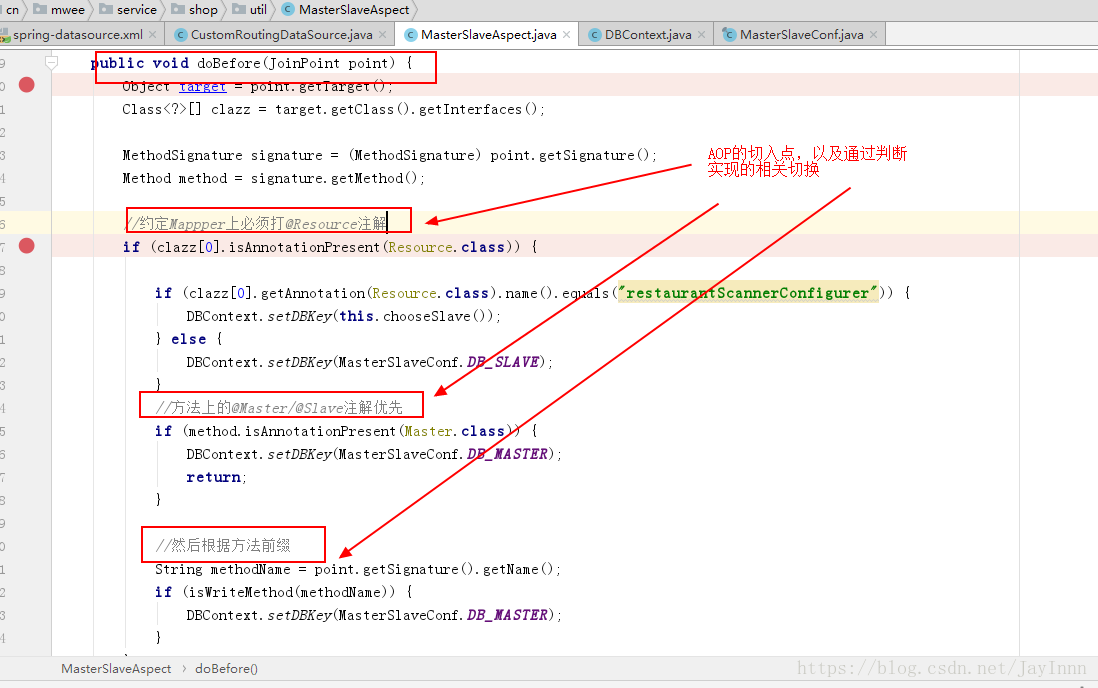
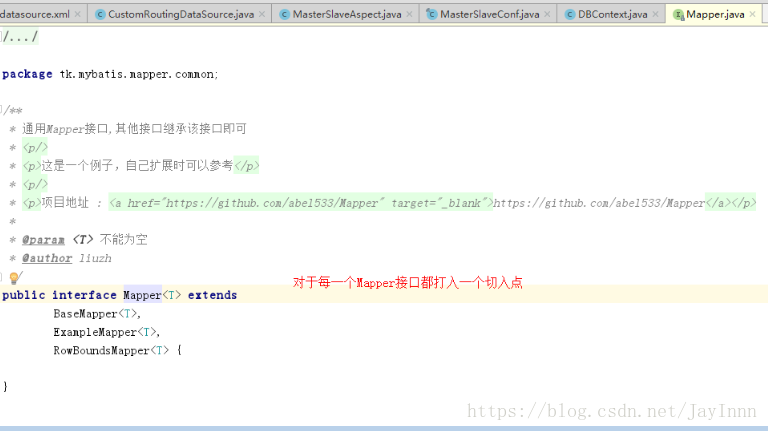
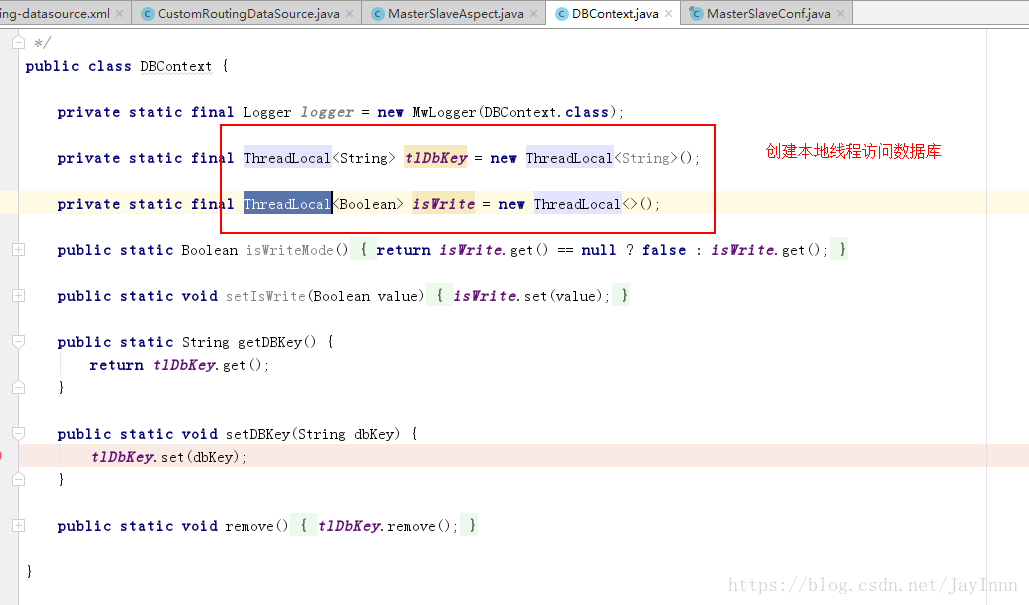
保证每个线程用到的是自己的数据源,使用ThreadLocal来防止并发带来的问题:
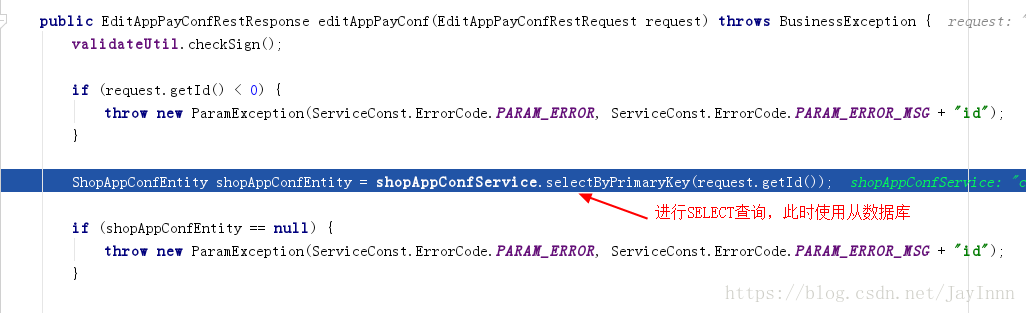
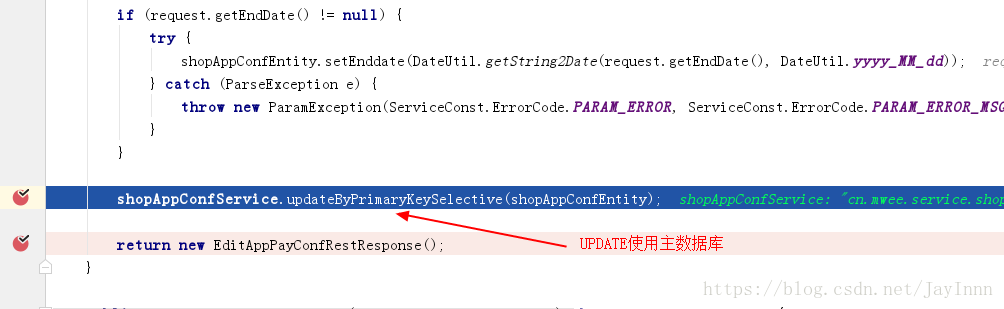
对数据库的主从切换进行调试,最好是分别使用SELECT,UPDATE来调试:
下面的代码是一主多从配置文件的详细解释,而与一主一从的区别在于,一主一从的配置都在数据源配置中完成:
参考链接:https://blog.csdn.net/zbw18297786698/article/details/54343188
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd"> <!--声明:各DataSource的name 及 MapperScannerConfigurer的name,不要随意更改,否则会影响AOP的读写分离正常使用--> <bean id="parentDataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init"
destroy-method="close">
<property name="driverClassName" value="${jdbc-driver}"/>
<property name="url" value="${jdbc-url-restaurant}"/>
<property name="username" value="${jdbc-user-restaurant}"/>
<property name="password" value="${jdbc-password-restaurant}"/>
<property name="filters" value="stat"/>
<!-- 连接池最大数量 -->
<property name="maxActive" value="20"/>
<!-- 初始化连接大小 -->
<property name="initialSize" value="1"/>
<!-- 获取连接最大等待时间 -->
<property name="maxWait" value="5000"/>
<!-- 连接池最小空闲 -->
<property name="minIdle" value="1"/>
<property name="timeBetweenEvictionRunsMillis" value="3000"/>
<property name="minEvictableIdleTimeMillis" value="180000"/>
<property name="validationQuery" value="SELECT 'x' FROM DUAL"/>
<property name="testWhileIdle" value="true"/>
<property name="testOnBorrow" value="false"/>
<property name="testOnReturn" value="false"/>
<property name="poolPreparedStatements" value="false"/>
<property name="maxPoolPreparedStatementPerConnectionSize" value="20"/>
<!-- 超过时间限制是否回收 -->
<property name="removeAbandoned" value="true"/>
<!-- 超时时间;单位为秒。300秒=5分钟 -->
<property name="removeAbandonedTimeout" value="300"/>
<!-- 关闭abanded连接时输出错误日志 -->
<property name="logAbandoned" value="true"/>
<!--<property name="connectionInitSqls" value="set names utf8mb4;"/>-->
</bean> <!--动态获取数据库-->
<bean id="dsRestaurant_master" parent="parentDataSource">
<property name="url" value="${jdbc-url-restaurant}"/>
<property name="username" value="${jdbc-user-restaurant}"/>
<property name="password" value="${jdbc-password-restaurant}"/>
</bean> <!--restaurant数据源-->
<bean id="dsRestaurant" class="cn.mwee.service.shop.lookup.CustomRoutingDataSource">
<property name="targetDataSources">
<map key-type="java.lang.String">
<!--写库-->
<entry key="master" value-ref="dsRestaurant_master"/>
</map>
</property>
<property name="defaultTargetDataSource" ref="dsRestaurant_master"/>
</bean> <!--restaurant库--><!-- spring和MyBatis完美整合,不需要mybatis的配置映射文件 -->
<bean id="sqlSessionFactoryRestaurant" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="configLocation" value="classpath:mybatis-config.xml"></property>
<property name="dataSource" ref="dsRestaurant"/>
<!-- 自动扫描mapping.xml文件 -->
<property name="mapperLocations">
<array>
<value>classpath:mybatis/restaurant/*.xml</value>
</array>
</property>
</bean> <!-- Mapper接口所在包名,Spring会自动查找其下的类 -->
<bean id="restaurantScannerConfigurer" class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.mwee.service.shop.mapper.restaurant"/>
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactoryRestaurant"/>
</bean> <!--事务管理-->
<bean id="restaurantTxManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dsRestaurant"/>
</bean>
<tx:annotation-driven transaction-manager="restaurantTxManager"/> <!--AOP切面设置 -->
<bean id="masterSlaveAspect" class="cn.mwee.service.shop.util.MasterSlaveAspect"/>
<aop:config>
<aop:aspect ref="masterSlaveAspect" order="1">
<aop:pointcut id="masterSlave"
expression="this(tk.mybatis.mapper.common.Mapper)"/>
<aop:before pointcut-ref="masterSlave" method="doBefore"/>
</aop:aspect>
</aop:config> </beans>
Spring AOP实现Mysql数据库主从切换(一主多从)的更多相关文章
- 170301、使用Spring AOP实现MySQL数据库读写分离案例分析
使用Spring AOP实现MySQL数据库读写分离案例分析 原创 2016-12-29 徐刘根 Java后端技术 一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案 ...
- MySQL数据库主从切换脚本自动化
MySQL数据库主从切换脚本自动化 本文转载自:https://blog.csdn.net/weixin_36135773/article/details/79514507 在一些实际环境中,如何实现 ...
- 161220、使用Spring AOP实现MySQL数据库读写分离案例分析
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库 ...
- 使用Spring AOP实现MySQL数据库读写分离案例分析
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库 ...
- 使用Spring AOP实现MySQL读写分离
spring aop , mysql 主从配置 实现读写分离,下来把自己的配置过程,以及遇到的问题记录下来,方便下次操作,也希望给一些朋友带来帮助.mysql主从配置参看:http://blog.cs ...
- (转)Mysql数据库主从心得整理
Mysql数据库主从心得整理 原文:http://blog.sae.sina.com.cn/archives/4666 管理mysql主从有2年多了,管理过200多组mysql主从,几乎涉及到各个版本 ...
- mysql数据库主从同步
环境: Mater: CentOS7.1 5.5.52-MariaDB 192.168.108.133 Slave: CentOS7.1 5.5.52-MariaDB 192.168. ...
- mysql数据库主从同步读写分离(一)主从同步
1.mysql数据库主从同步读写分离 1.1.主要解决的生产问题 1.2.原理 a.为什么需要读写分离? 一台服务器满足不了访问需要.数据的访问基本都是2-8原则. b.怎么做? 不往从服务器去写了 ...
- MySQL数据库主从同步延迟分析及解决方案
一.MySQL的数据库主从复制原理 MySQL主从复制实际上基于二进制日志,原理可以用一张图来表示: 分为四步走: 1. 主库对所有DDL和DML产生的日志写进binlog: 2. 主库生成一个 lo ...
随机推荐
- Spring Security原理与应用
Spring Security是什么 Spring Security是一个能够为基于Spring的企业应用系统提供声明式的安全访问控制解决方案的安全框架.它提供了一组可以在Spring应用上下文中配置 ...
- 论文笔记:Semantic Segmentation using Adversarial Networks
Semantic Segmentation using Adversarial Networks 2018-04-27 09:36:48 Abstract: 对于产生式图像建模来说,对抗训练已经取得了 ...
- 【Hadoop 分布式部署 十:配置HDFS 的HA、启动HA中的各个守护进程】
官方参考 配置 地址 :http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabili ...
- Python打印矩形、直角三角形、等腰三角形、菱形
思路如下: (1)先打印一个星号并换行 print("*") (2)打印一行6个星号 for i in range(6): print("*", end=&qu ...
- 5、web站点架构模式简介及Nginx
LB Cluster: 提升系统容量的方式: scale up:向上扩展 scale out:向外扩展 LVS工作在内核中,本身的数量不受套接字数量限制,利用LVS做调度器,优化得当的话,并发数量可以 ...
- JAVA之经典算法
package Set.Java.algorithm; import java.util.Scanner; public class algorithm { /** * [程序1] 题目:古典问题:有 ...
- async函数对比Generator函数
首先定义一个读取文件的异步函数 var readFile = function(fileName){ return new Promise((resolve,reject)=>{ fs.read ...
- HTML元素 绑定href属性
给<li>标签绑定href属性 <ul class="honor-list clearfix"> <li style="cursor:poi ...
- Program type already present:okio.AsyncTimeout$Watchdog Message{kind=ERROR, text=Program type :okio
在app中的build.gradle中加入如下代码, configurations { all*.exclude group: 'com.google.code.gson' all*.exclude ...
- Django中ORM简介与单表数据操作
一. ORM简介 概念:.ORM框架是用于实现面向对象编程语言种不同类型系统的数据之间的转换 构建模型的步骤:重点 (1).配置目标数据库信息,在seting.py中设置数据库信息 DATABASE ...